

终身机器学习(Lifelong Machine Learning)综述
终身机器学习(Lifelong Machine Learning)综述
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
大概有十几天了没有回来更新博客了吧,这期间遇到了大大小小各种事情,最悲伤的事应该是跟我关系最好的一个哥们的父亲去世了,被酒驾的人撞了,希望叔叔在天国安好!再次告诫各位开车一定不能喝酒,不只是对自己负责,也是对他人生命的尊重,在这里谢过大家了!
下面说一说我这些天积累的一点东西,是关于终身机器学习(Lifelong Machine Learning)的一些知识。所谓终身机器学习,就是这个模型自从创立那一天开始,就一直不断的运行下去。说起终身机器学习,相信很多人都不理解也没有了解过这个方向,因为确实很偏,但是在现在的大数据背景下,我相信总有一天,终身机器学习会大放异彩。虽然现在的应用可能不是很广泛,但是我相信终身机器学习也可以对我们现在正在做的一些工作有着启发式的作用。
终身机器学习出现的背景可以概括为以下两个方面:第一,随着信息技术的进步,各种数据呈爆炸式增长。第二,传统机器学习算法对大数据环境下的应用问题很多已不再适用,这是因为传统的机器学习算法大多只是关注于小样本范围内的分类等工作,对大数据环境缺乏适应能力。在这样的背景下,终身机器学习应运而生。
上面说过,这个方向现在有些偏,做这个方向的人也很少,下面列举三位大牛并附上他们的个人主页链接。
1. Daniel L.Sliver:此人是先驱级的人物,早期理论的奠基人
http://plato.acadiau.ca/courses/comp/dsilver/DLSWebSIte/Welcome.html
2. 杨强:此人曾在华为诺亚方舟研究所工作,从事这个方向的研究,现在在香港执教
http://www.cs.ust.hk/~qyang/
3. Eric Eaton: 新秀,提出的ELLA算法效率极高(1000倍左右的提升)
http://www.seas.upenn.edu/~eeaton/
下面先粗略介绍一下人类的学习过程,终身机器学习就是模仿人类学习过程提出的。首先人类对外界环境保持感知,从而对感兴趣的信息保持关注;之后,在大脑的海马系统上,新的知识在以往知识的基础上被快速建立起来;之后经过长时间的处理,在大脑皮质区形成较难遗忘的长时记忆。
关于终身机器学习的定义,学术界尚未形成统一的结论,但经过我的总结发现,一般都遵循以下四个要点:
1. 维护可增长的知识库 2.按照一定顺序学习 3.多个任务 4.知识的正向迁移
从上面的四点还有之前的人类学习过程我们可以看出,这里面最重要的一点就是知识的迁移,也就是旧知识如何帮助新知识的学习,知识迁移或者说迁移学习(Transfer Learning)正是终身机器学习的基础。
下面介绍一下终身机器学习的框架:
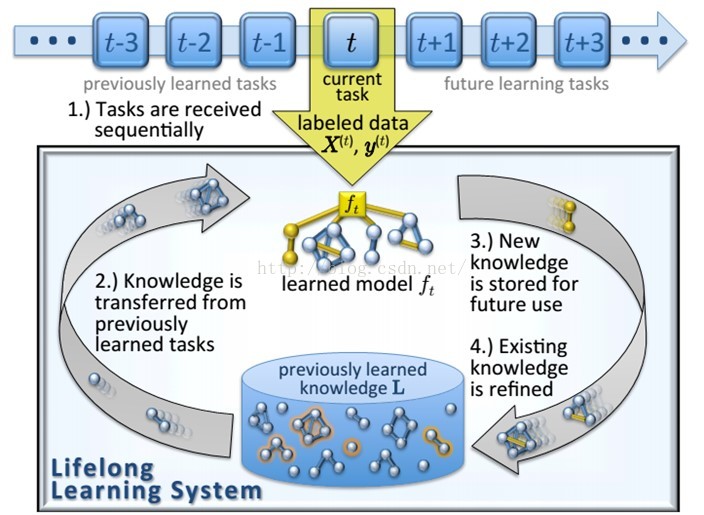
如图所示,终身机器学习的框架较为清晰,经过我个人的总结和参考一位博士学姐的文章,我将终身机器学习分为以下几个部分:
1. 迁移知识
作用是从知识仓库中选择对新模型学习有用的知识进行迁移,帮助新模型的学习。
2. 知识仓库
作用是存储学习到的有必要长期存储的知识同时对存储数据有效的检索和再现能力
3. 模型学习
4. 与知识仓库进行交互,利用迁移知识使新任务完成快速学习过程,并将新任务中学习到的新知识整合进原有的知识中
5. 整合知识
6. 保证知识仓库能得到不断地更新,以使得在学习新任务时,这些知识可以得到有效的迁移
7. 引导学习
求解出合理的任务学习顺序从而提升系统的学习性能和效率
以上的内容对有迁移学习基础的朋友可能会更容易理解一些,如果有朋友不是很理解,可以在下面评论,我会一一解答的。
相信各位也看出来了,在这个系统里面比较重要的是两个部分,迁移知识和整合知识。下面我介绍以下关于终身机器学习四种经典的算法,按照时间先后排序,这几个算法里面知识的迁移和整合往往是最重要的部分:
1. 基于解释的神经网络模型EBNN
目标:解决了纯粹的归纳学习在训练数据不足时通常会失败的问题
解决问题的角度:将归纳学习和分析学习相结合
算法思想:将归纳学习和分析学习相结合并增加了给定训练导数与神经网络函数实际导数之间的一致性约束,且进一步提出采用已经学习过任务的信息给出对训练数据的解释,实现不同任务间知识的迁移
贡献点:开创了利用根据先验知识进行演绎推导来进行终身学习的先河
2. 多任务人工神经网络MTLNN
目标:解决当学习新问题时,学习过的任务知识的滞留和回想问题
解决问题的角度:将学习过的任务进行重演
算法思想:将新任务样本输入已学习过模型中,并将对应的输出结果作为虚拟样本加入新任务学习的ηMTL 网络中进行训练,使得旧任务在学习新任务的同时也得到了巩固
贡献点:引入了任务重演对以前学习的任务进行巩固
3. 相关多任务学习csMTL
目标:克服MTL网络的局限性
解决问题的角度:增加任务上下文输入集
算法思想:增加输入节点,每一个增加的输入节点分别标记一个任务,但只设立一个输出节点;直接共享任务的表示
贡献点:避免了一次任务训练中必须对其他任务进行任务重演的操作,同时不需要计算任务相关性。
4. 高效终身机器学习ELLA
目标:提高终身学习的效率
解决问题的角度:设立潜在任务
算法思想:将一组潜在任务作为共享知识保存起来,新任务到来的时候,通过这些潜在任务迁移已经学习到的知识帮助学习新任务,又通过学习到的新任务知识精炼潜在任务,可以使得先前学习的任务模型性能同样得到提升.
贡献点:在与MTL几乎同样的性能下,节省大量时间(超过1000倍),极度高效
如果各位朋友想深入了解这些算法的话,可以和我联系,我把论文发给大家。
说过了知识的迁移和整合,我们再来看看知识仓库。我们可能会想,知识仓库到底应该存储怎样的知识呢?根据相关研究,任务间的迁移随任务所共有的认知要素程度而变化,通过在更高的抽象层面上表征问题可以提高迁移能力。同时Weitheimer的实验说明,理解性学习的知识更容易迁移到新问题上。所以我们得出结论,知识仓库应存储知识的表示,相当于对存储经总结压缩后的原始信息。
说了这么久,我们来举两个应用实例吧:
1. 永不停止的语言学习机,它的目的是创造一个计算机系统可以持续不断地学习阅读和理解网页。
2. 永不停止的图像学习机,它的目的是在最少人工参与的情况下,建立世界上最大的结构化视觉知识库
最后,现有的终身机器学习方法还有很多不足之处,对未来的展望主要体现在以下三个方面:
1. 可迁移知识表示的研究,尤其是适用于任务类别数大且不一定完全相关的情况的知识表示
2. 如何处理数据多源异构问题,这里指的是针对来自不同的数据采集源,分布不同的
异构数据
3. 结合其他先进技术,如深度学习、知识图谱等,旨在提高特征学习性能和隐含因素捕捉能力以及对知识的组织和利用能力
由于最近心情都不怎么阳光,所以写出的东西可能有些凌乱,希望大家多多批评指教。最后希望大家能够向周围的家人朋友多多宣传一下千万不要酒驾,我在这里谢过大家了,谢谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号