

深度学习入门----EfficientNet解读
深度学习入门----EfficientNet解读
EfficientNet是谷歌最新的论文:EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks ICML 2019
这篇论文主要讲述了如何利用复合系数统一缩放模型的所有维度,达到精度最高效率最高,符合系数包括w,d,r,其中,w表示卷积核大小,决定了感受野大小;d表示神经网络的深度;r表示分辨率大小;
这篇论文谷歌给出了对应的tf源码,地址为:EfficientNet
本人理解的笔记如下:
1,文中总结 了我们常用的三种网络调节方式:增大感受野w,增大网络深度d,增大分辨率大小r,三种方式示意图如下:

其中,(a)为基线网络,也可以理解为小网络;(b)为增大感受野的方式扩展网络;(c)为增大网络深度d的方式扩展网络;(d)为增大分辨率r的方式扩展网络;(e)为本文所提出的混合参数扩展方式;
2,文中试验测试,调查了w/r/d在各种情况下的准确率和效率的相互关系曲线,如下图所示:
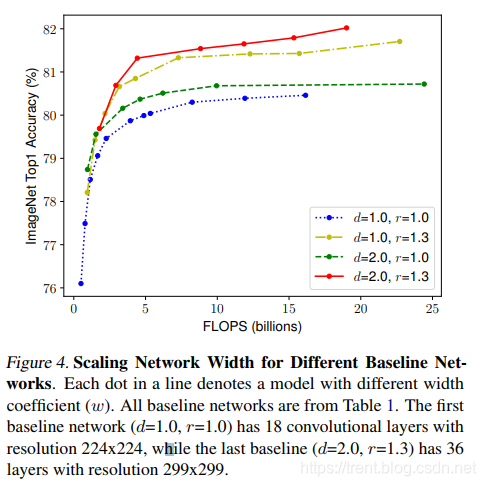
个人总结规律如下:
2.1,在r和w大小不变的情况下,随着d的增大,准确率没有太大的差异;
2.2,在d和w不变的情况下,随着r的增大,准确率有较大提升;
2.3,r和d不变的情况下,随着w的增大,准确率先有较大提升,然后趋于平缓,往后在无太大提升;
3,复合系数的数学模型
文中给出了一般卷积的数学模型如下:
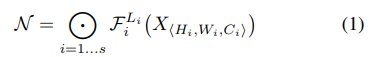
其中H,W为卷积核大小,C为通道数,X为输入tensor;
则复合系数的确定转为如下的优化问题:
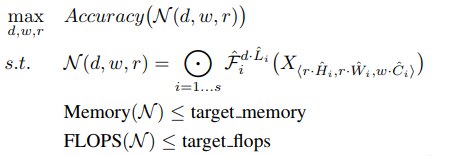
调节d,w,r使得满足内存Memory和浮点数量都小于阈值要求;
为了达到这个目标,文中提出了如下的方法:
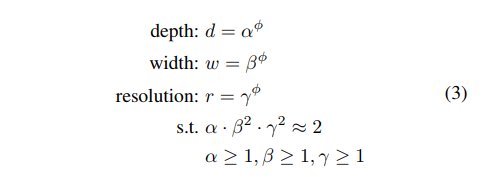
对于这个方法,我们可以通过一下两步来确定d,w,r参数:

第一步我们可以通过基线网络来调节确定最佳的,然后,用这个参数将基准网络扩展或放大到大的网络,这样就可以使大网络也具有较高的准确率和效率。同样,我们也可以将基线网络扩展到其他网络,使用同样的方法来放大;
论文中基线模型使用的是 mobile inverted bottleneck convolution(MBConv),类似于 MobileNetV2 和 MnasNet,但是由于 FLOP 预算增加,该模型较大。于是,研究人员缩放该基线模型,得到了EfficientNets模型,它的网络示意图如下:
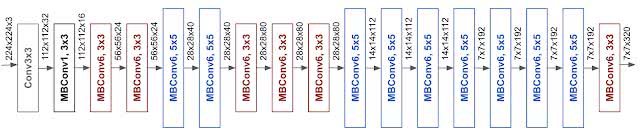
最后,研究人员对EfficientNets的效率进行了测试,结果如下:
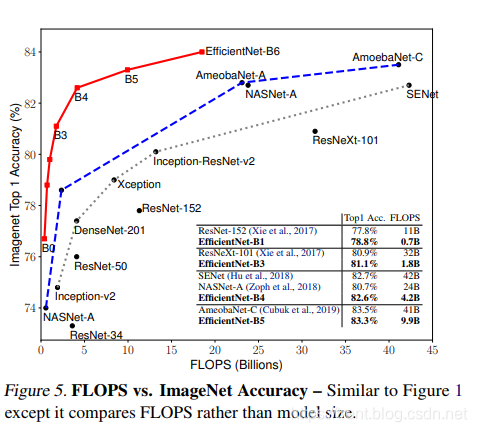
对比EfficientNets和已有的CNN模型,EfficientNet 模型要比已有 CNN 模型准确率更高、效率更高,其参数量和 FLOPS 都下降了一个数量级,EfficientNet-B7 在 ImageNet 上获得了当前最优的 84.4% top-1 / 97.1% top-5 准确率,而且CPU 推断速度是 Gpipe 的 6.1 倍,但是模型大小方面,EfficientNet-B7却比其他模型要小得多,同时,还对比了ResNet-50,准确率也是胜出一筹(ResNet-50 76.3%,EfficientNet-B4 82.6%)。
EffieicntNet在最近几天掀起了一股小旋风,开源代码点赞数大增,大家可以一起学习一下!
附上在文地址:https://arxiv.org/pdf/1905.11946.pdf
github地址:https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet

 浙公网安备 33010602011771号
浙公网安备 33010602011771号