

从loss处理图像分割中类别极度不均衡的状况---keras
从loss处理图像分割中类别极度不均衡的状况---keras
前言
最近在做小目标图像分割任务(医疗方向),往往一幅图像中只有一个或者两个目标,而且目标的像素比例比较小,使网络训练较为困难,一般可能有三种的解决方式:
- 选择合适的loss function,对网络进行合理的优化,关注较小的目标。
- 改变网络结构,使用attention机制(类别判断作为辅助)。
- 与2的根本原理一致,类属attention,即:先检测目标区域,裁剪之后进行分割训练。
通过使用设计合理的loss function,相比于另两种方式更加简单易行,能够保留图像所有信息的情况下进行网络优化,达到对小目标精确分割的目的。
场景
- 使用U-Net作为基准网络。
- 实现使用keras
- 小目标图像分割场景,如下图举例。
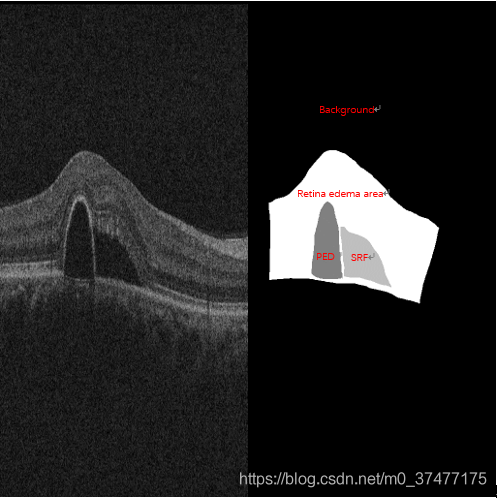
AI Challenger眼底水肿病变区域自动分割,背景占据了很大的一部分![在这里插入图片描述]()
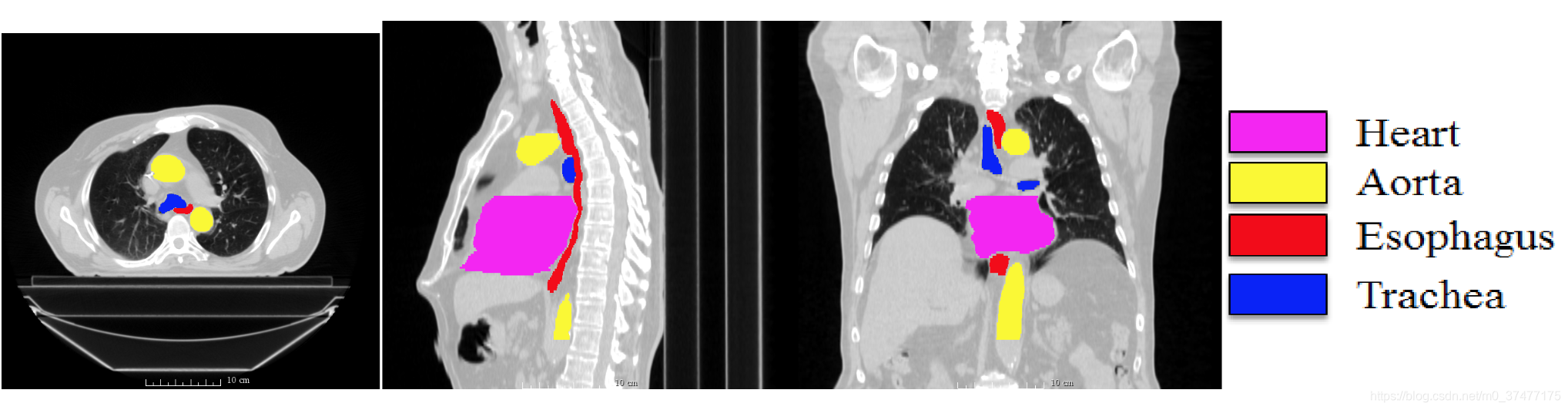
segthor医疗影像器官分割![在这里插入图片描述]()
loss function
一、Log loss
对于二分类而言,对数损失函数如下公式所示:−1N∑Ni=1(yilogpi+(1−yi)log(1−pi))-\frac{1}{N}\sum_{i=1}^{N}(y_i\log p_i + (1-y_i)\log (1-p_i))−N1i=1∑N(yilogpi+(1−yi)log(1−pi))
其中,yiy_iyi为输入实例xix_ixi的真实类别, pip_ipi为预测输入实例 xix_ixi 属于类别 1 的概率. 对所有样本的对数损失表示对每个样本的对数损失的平均值, 对于完美的分类器, 对数损失为 0。
此loss function每一次梯度的回传对每一个类别具有相同的关注度!所以极易受到类别不平衡的影响,在图像分割领域尤其如此。
例如目标在整幅图像当中占比也就仅仅千分之一,那么在一副图像中,正样本(像素点)与父样本的比例约为1~1000,如果训练图像中还包含大量的背景图,即图像当中不包含任何的疾病像素,那么不平衡的比例将扩大到>10000,那么训练的后果将会是,网络倾向于什么也不预测!生成的mask几乎没有病灶像素区域!
此处的案例可以参考airbus-ship-detection。
二、WBE Loss
带权重的交叉熵loss — Weighted cross-entropy (WCE)[6]
R为标准的分割图,其中rnr_nrn为label 分割图中的某一个像素的GT。P为预测的概率图,pnp_npn为像素的预测概率值,背景像素图的概率值就为1-P。
只有两个类别的带权重的交叉熵为:
WCE=−1N∑Nn=1wrnlog(pn)+(1−rn)log(1−pn)WCE = - \frac{1}{N}\sum_{n=1}^{N}wr_nlog(p_n) + (1 - r_n)log(1 - p_n)WCE=−N1n=1∑Nwrnlog(pn)+(1−rn)log(1−pn)
www为权重,w=N−∑npn∑npnw=\frac{N-\sum_np_n}{\sum_np_n}w=∑np