

准确率99.9%!如何用深度学习最快找出放倒的那张X光胸片(代码+数据)
准确率99.9%!如何用深度学习最快找出放倒的那张X光胸片(代码+数据)
医学图像数据的质量一直是个老大难题。难以清理的数据制约着许多深度学习的应用。
而实际上,深度学习本身就是清洗医疗数据的好帮手。
今天,我们就来讲一个案例,展示如何用深度学习迅速清洗一个杂乱的医疗图像数据集。
案例的主角是胸部X光图像。
由于设备制造商的不同,胸部X光的图像有可能是水平的,也可能是垂直翻转的。他们可能会倒置像素值,也可能会旋转。问题在于,当你处理一个庞大的数据集(比如说50到100万张图像)的时候,如何在没有医生查看的情况下发现畸变?
你可以试图编写一些看似优雅高效的解决方案,例如:
在许多胸部X射线图像的两侧有黑色边框(因为大多数图像的高度大于宽度),所以如果当底部有超过50个黑色像素行的时候,这幅图像可能被旋转了90度。
这个规则看起来非常靠谱,但在实际运用中却经常犯错。
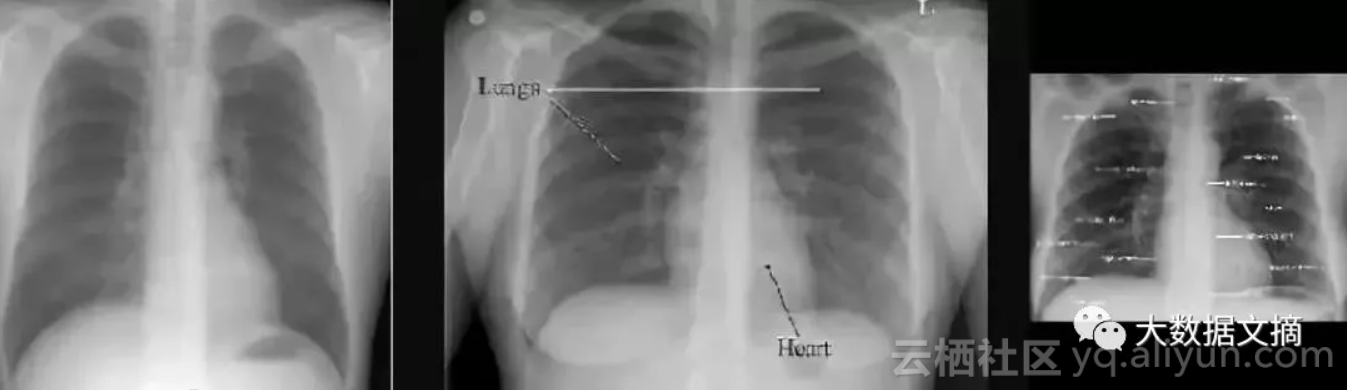
上面三幅图中,只有中间的图像存在“黑色边框在两侧”的情况,因而上面这一方案并不实用。
这些人为制定的规则并不能解决我们的问题。
那么,我们是不是可以利用机器学习来构建我们无法手写代码的解决方案呢?实际上,找出像图片旋转之类问题对机器来说是其实非常简单的。像人类一样,机器可以很容易、并且几乎完美地解决这些问题。
所以,使用深度学习来修复我们的数据集是显而易见的解决方案。
下面,我将向你展示这些技术的工作原理,以及如何用最少的时间和精力完成这些工作,并介绍一些正在使用的方法实例。
在这个案例中,我将使用CXR14数据集,这个数据集经过非常精心的策划管理,但仍然包含了一些“坏图”。所以我还会给你新的包括430种标签的数据集,这样你就不用担心其中暗藏的异常图像了!
数据集链接:
https://nihcc.app.box.com/v/ChestXray-NIHCC
机器学习真的能解决这个问题么?
开始之前,让我们先想一想,这个问题对于机器学习来说真的很简单么?
考虑到大多数图片都是正常的,你需要非常高的精度来防止排除过多正常的图片。我们的目标准确率是99.9%。
这难不难处理呢?我们不妨问问自己:你能否想出一个简单的可视化规则来解决这一问题?
显然,区分猫狗这个问题就很难用一个简单的可视化规则处理,这也是为什么我们需要ImageNet数据集了。由于图像之间的区别可能非常大,区分猫狗的问题有太多复杂的因素需要考虑。

但是在医疗数据中,问题就简单得多。医疗图片是非常相像的,解剖学中角度,照明,距离和背景都非常稳定。
为了说明这一点,我们来看一个来自CXR14的简单例子。在数据集中的正常胸部X射线中,有一些图像经过旋转(这些旋转并未标识在标签中,因此我们不知道哪些是旋转过的)。它们有可能被左右旋转了90度,或180度(颠倒)。
这对机器学习来说难不难呢?
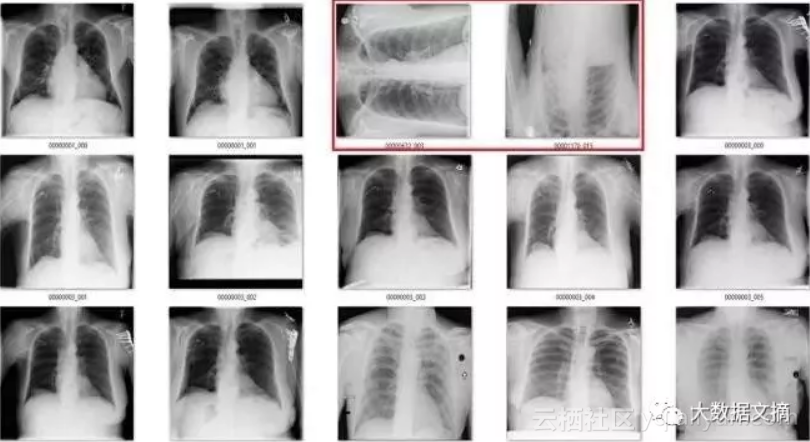
在旋转和竖直胸部X射线之间的差异真的是令人尴尬的简单。
答案是:不难!在视觉上,异常图片与正常图片完全不同。你可以使用一个简单的可视规则,比如说“肩膀应该高于心脏”,然后你就会得到所有正确的结果。鉴于解剖学非常稳定,所有人都有肩膀和心脏,这应该是卷积网络的可以学习的规则。
数据够不够呢?
我们接下来要问的问题是:我们有充分的训练数据吗?
对于旋转图像这个问题,我们当然可以获取足够的数据!我们需要的只是几千个正常的胸部X光片,并且随机旋转它们。例如,如果你使用numpy数组作为你的图像,你可能会使用这样的函数:
def rotate(image):
rotated_image = np.rot90(image, k = np.random.choice(range(1,4)), axes = (1,2))
return rotated_image
这个函数可以将图像按顺时针方向旋转90度,180度或270度。在这种情况下,我们围绕第二个和第三个轴旋转。在这一数据集中,第一个轴表示通道(如RGB)。
注意:在这种情况下,CXR14数据集中的旋转图像非常少,因此意外“校正”已旋转图像的几率非常小。我们可以假设数据中没有任何需要旋转过的图像,并且模型会学习得很好。
如果有更多的异常图像,那么你可能需要手动选取正常和异常的图像达到更好的结果。
由于像旋转这样的问题是非常易于识别的,我发现我可以在一个小时内标出几千个。
由于这些问题非常简单,我只需要几百个例子来“解决”这个问题。
我们建立一个正常图像的数据集,旋转其中的一半,并相应地标记它们。
在我的例子中,我选择了4000个训练数据,其中2000个是经过旋转的,此外,我还选择了2000个作为交叉验证数据,其中1000个是经过旋转的。
这是一个不错的数据集大小,它能够被储存在计算机的内存中,所以很容易在计算机上进行训练。
我在一般的机器学习流程上做了一个有意思的改动:不需要单独的测试集。实践是检验真理的唯一标准——我总归要在整个数据集上运行模型,所以把这个结果作为测试集的结果即可。
一般来说,对于这种工作,我会尽可能简化任务。
我首先将图像缩小为256x256像素(因为旋转检测似乎不需要高分辨率的图像),并且我使用预训练过的resnet50作为基础网络,并且使用keras建立基础框架。
我们并不需要使用预训练网络,因为在这么简单的任务上,几乎所有神经网络都可以收敛。但使用预训练网络也很容易,并且不会减慢速度(无论如何,训练时间都很快)。我使用了模型的默认参数。
你可以使用任何卷积神经网络。一个VGG-Net可以,一个DenseNet可以。说真的,几乎任何神经网络都可以。
经过几十次迭代之后,我得到了这样的结果(结果是在交叉验证数据集上):
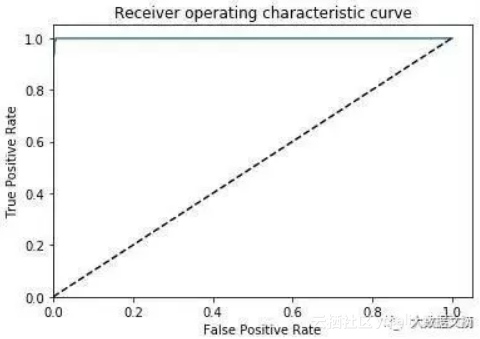
AUC=0.999,ACC=0.996,PREC=0.998,REC=0.994
太棒了,对于这么简单的一个任务,这就是我想要得到的结果。
检查结果
正如我之前所说的,在医学图像分析中,我们总是需要检查我们的结果。看看图像,确保模型做到了你想要做的任务。
所以,我们的最后一步是在整个数据集上运行模型,进行预测,然后根据预测结果排除那些旋转的图像。由于数据中被旋转过的图像很少,所以我可以一张张检查那些被预测为异常的图像。
相反,如果这是一个有很多异常图像的问题(比如说超过5%的数据),你无法一张张检测,那么收集几百个随机案例,并手工标记出测试集会更有效率。然后,你可以通过适当的指标跟踪模型的准确度。
我特别关心那些被错误标记为旋转的正常图像(误报),因为我不想失去珍贵的训练数据。
这实际上是一个比你想象的更加严重的问题,因为这个模型可能会过度调用某种特定类型的病例(也许病例中的病人身体倾斜了),如果我们将排除这些作为一个规则,我们会引入误差,并且进入我们模型的数据不再是来自于“真实世界”的有代表性的数据集。
这显然对医疗数据有很大影响,因为我们的整体目标是制造出一套能够在实际医院中使用的系统。
该模型一共标记出了171个“旋转”的图像。有趣的是,它实际上作为一个“异常”检测器,识别出许多在非胸部X光的图像。这也不难理解,因为这个模型可能是在学习解剖学的标志。任何异常的东西,如旋转的图像或者是其他身体部位的X射线图像,都不具有正常图片应有的特征。真是意外收获!
在171个被标记为“旋转“的图像中,有51个是实际上旋转过的正面胸部X射线图像。鉴于图片旋转发生的概率非常低(120,000个案例中有51个),这已经是极低的假阳性率。
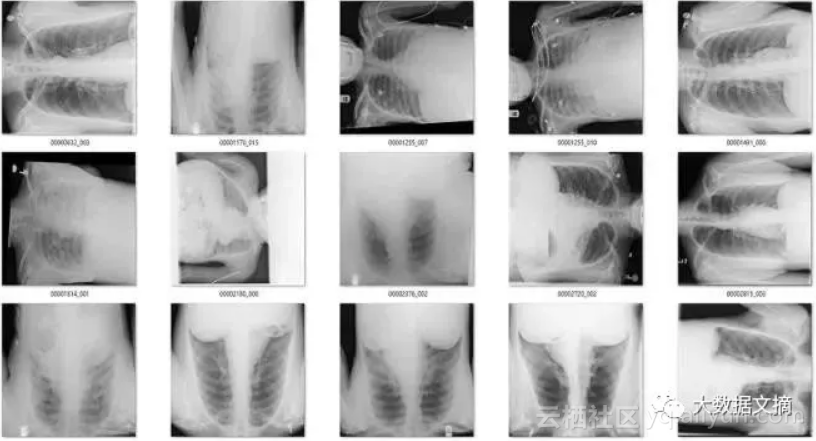
在余下的120个图像中,56个并不是正面胸片。其中主要包括了侧面胸片和腹部X光片,这也是我想要清理出去的异常图片。
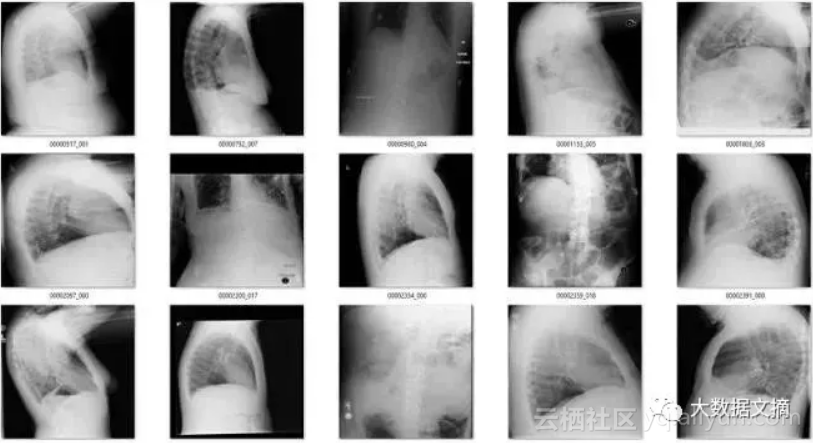
那么其余的呢?有一些是经过混合的缩小图像(它们有着黑色或白色的大边界),因为过度曝光而变淡的图像(其中有一些图像整体都是灰色的),还有像素颜色完全翻转的图像等等。
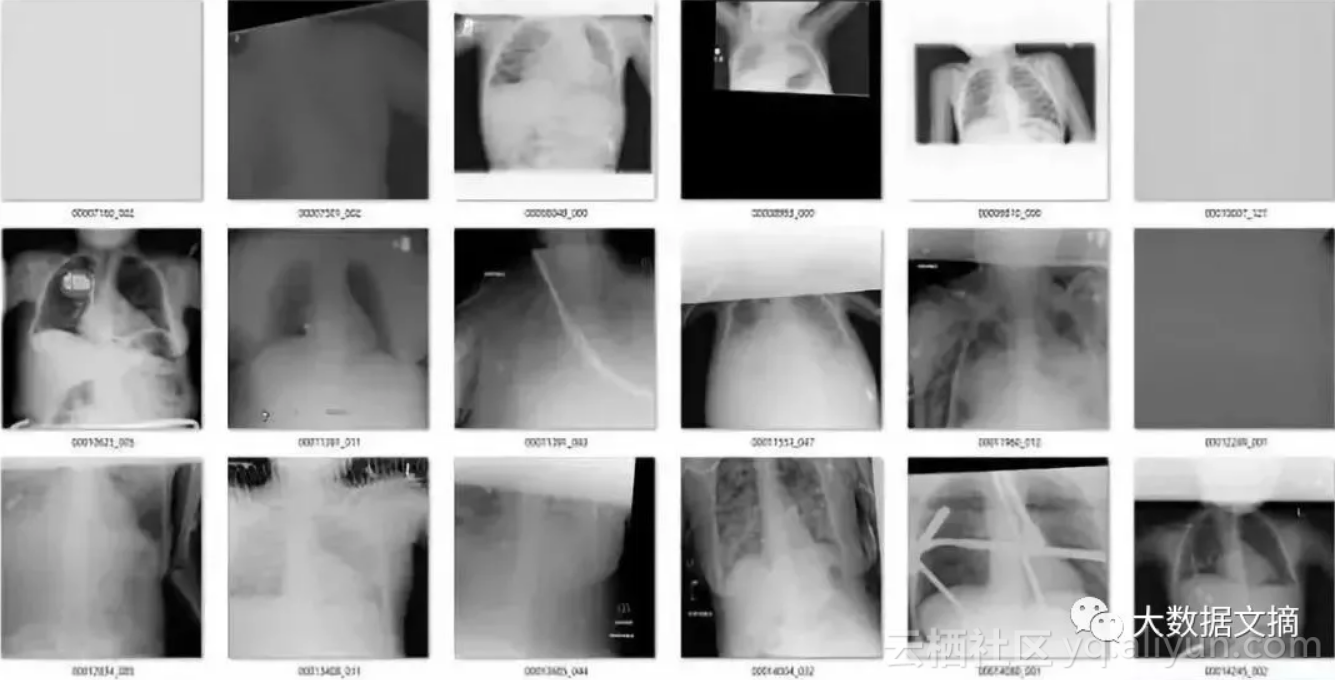
总而言之,大约有10张X光图我认为是“假阳性”(它们其实是我需要的正常的前胸正面X光图)。还有一点很幸运,我们的模型检测出“坏图”的数量只有171张,如果我们想要检查每张图并手动改正模型判断错误的图片,也很容易办到。
看起来我们的旋转检测器还部分地解决了一些其他问题(比如像素值反转问题)。
为了了解它检测像素值反转问题的能力,我们也可以认为制造一些像素值反转的图片(对于图像中的像素值x,x=max-x)。
我用同样的方法训练了一个“像素反转检测器”。结果依然很好。
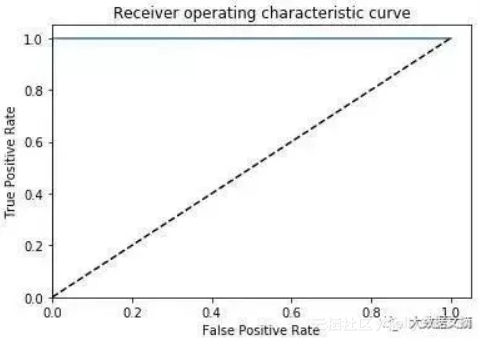
AUC=1.0,ACC=0.9995,PREC=0.999,REC=1.0
又是一个对机器学习非常简单的问题!我们的这个问题可能甚至有非机器学习的解法(频率分布图可能就有很好的区分效果),但是深度学习的方法也很简单。
话说回来,我们特意训练的反转检测器比旋转检测器检测到了更多像素反转的X光图吗?没错。旋转检测器在所有图片中找到4张像素反转图,而反转检测器找到了38张。
划重点:正确的打开方式是分别训练模型来解决不同的问题。
因此,对于其他清洗要求,我们也需要单独训练一个模型。
少量带标签数据也会有帮助
即使是很少量的带标签的数据都很有帮助。我用旋转检测器检测到的侧面和错误区域的X光图(n=56张)训练了一个新的模型。
由于训练数据太少,我决定放飞自我,把所有的数据用于训练,并不专门设置的验证数据集。这样做的原因是这些任务都很容易完成,当训练正确率接近100%的时候,把模型用在它未见过的数据集上,也应该能达到很好的效果。当然,我知道会有过拟合的风险。
结果很好!新的模型帮我找到了几百张侧面,腹部和骨盆X光图。
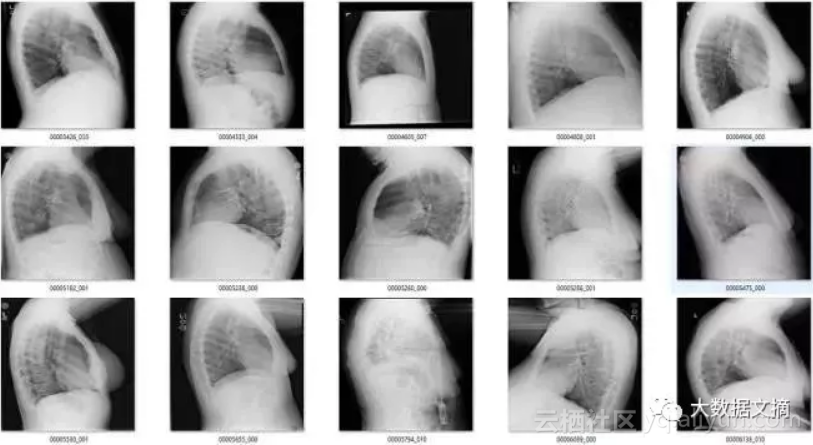
显然,如果我从头开始创建这个数据集,我需要找到很多非前胸X光图,其实也不难,这样的图片我有的是。
除了CXR14数据集本身的特点之外,我还注意到一件事,我的模型在幼儿的X光图上表现不佳。幼儿X光图本身和成年人X光图的区别很大,以致于它们被旋转检测器,反转检测器和错误身体位置检测器识别为“异常”。
因此,我认为我们的模型不应该考虑幼儿的X光图。好在患者年龄信息包含在X光图标签中,所以我们不需要借助深度学习来排除幼儿X光图。
鉴于在数据集中只有286个患者的年龄在5岁以下,除非要专门研究该年龄段的患者并且充分了解相关医学成像的信息,我会排除这些患者。我可能甚至会排除所有10岁以下的患者,因为10岁以上的孩子身体尺寸和病理特征才更接近于“成人”。数据集中大约有1400例患者年龄在10岁以下,占比约1%
长话短说,幼儿前胸X光图与成人不同。由于数据集中年龄低于10岁的只占1%,除非有特殊的情况,我们应该排除这些数据。
在一些研究任务中,位置不对和已经放大的X光图可能会带来问题,但是在这类问题上,我们很难找到一个合适的区分标准。
介绍得差不多了。总而言之,用深度学习来解决简单的数据清洗问题很有效。我用了大约1个小时的时间就把数据集中大部分旋转和反转的图片清理出去了,同时,我还找出了一些侧面和其他身体位置的X光图。
纵观CXR14数据集,其实图像错误非常之少。美国国家卫生研究院团队管理的数据质量很高。在医生数据集中,这种情况不常见。如果你想要创建表现更好的医生人工智能系统,高效的处理来自临床基础研究设施的噪音至关重要。
总结
通常,我们接受深度神经网络在有足够的数据支撑的情况下,解决视觉问题水平与人类不分伯仲。然而,有一个前提同样显而易见却鲜有讨论,“足够的数据”大部分取决于任务的艰难程度。
有一些我们在构建医疗图像数据集时很想解决的问题,实际上是很容易解决的,也很容易用少量的数据解决。如果采用深度学习的方法标记图像,通常不到一个小时就可以完成。相同的工作量可能花费医生数小时的时间。
目前构建医疗AI系统的主要障碍是收集和清洗数据的巨大成本,在这种情况下,用深度神经网络确实是再合适不过了。
原文发布时间为:2018-05-16
本文作者:文摘菌

 浙公网安备 33010602011771号
浙公网安备 33010602011771号