

各类机器学习问题的最优结果合集!附论文及实现地址索引
各类机器学习问题的最优结果合集!附论文及实现地址索引
该 GitHub 库提供了所有机器学习问题的当前最优结果,并尽最大努力保证该库是最新的。如果你发现某个问题的当前最优结果已过时或丢失,请作为问题提出来(附带:论文名称、数据集、指标、源代码、年份),我们会立即更正。
这是为所有类型的机器学习问题寻找当前最优结果的一次尝试。我们都无法独自完成,因此希望每一位读者参与进来。如果你发现了一个数据集的当前最优结果,请提交并更新该 GitHub 项目。
监督学习
一、NLP
1、语言建模
以下展示了语言建模方面当前顶尖的研究成果及它们在不同数据集上的性能。
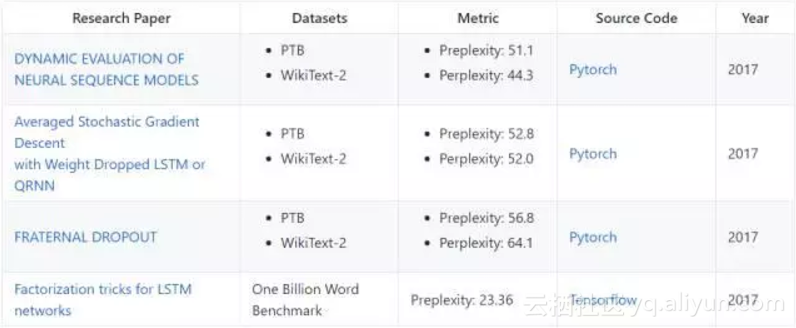
论文:DYNAMIC EVALUATION OF NEURAL SEQUENCE MODELS
论文地址:https://arxiv.org/pdf/1709.07432.pdf
实现地址:https://github.com/benkrause/dynamic-evaluation
论文:Regularizing and Optimizing LSTM Language Models
论文地址:https://arxiv.org/pdf/1708.02182.pdf
实现地址:https://github.com/salesforce/awd-lstm-lm
论文:FRATERNAL DROPOUT
论文地址:https://arxiv.org/pdf/1711.00066.pdf
实现地址:https://github.com/kondiz/fraternal-dropout
论文:Factorization tricks for LSTM networks
论文地址:https://arxiv.org/pdf/1703.10722.pdf
实现地址:https://github.com/okuchaiev/f-lm
在语言建模(Language Modelling)的四个顶尖研究成果中,我们看到 Yoshua Bengio 等人的研究 FRATERNAL DROPOUT 在 PTB 和 WikiText-2 数据集上都实现了当前最好的结果。在该篇论文中,Bengio 等人提出了一项叫做 fraternal dropout 的技术,他们首先用不同的 dropout mask 对两个一样的 RNN(参数共享)进行训练,并最小化它们 (pre-softmax) 预测的差异。这样正则项会促进 RNN 的表征对 dropout mask 具有不变性。Bengio 等人证明了他们的正则项上界为线性期望的 droupout 目标,即可以解决 droupout 因训练和推断阶段上出现的差异而导致的 Gap。
此外,Ben Krause 等人提出使用动态评估来提升神经序列模型的性能。Salesforce 的 Stephen Merity 等人提交的论文 LSTM 语言模型中的正则化和最优化从词层面的语言建模和调查基于 LSTM 模型中的正则化和最优化等具体问题出发研究更高效的语言建模方法。英伟达的 Oleksii Kuchaiev 等人提出了两个带映射的 LSTM 修正单元(LSTMP),并借此减少参数的数量和提升训练的速度。
2、机器翻译

论文地址:https://arxiv.org/abs/1706.03762
实现地址:https://github.com/jadore801120/attention-is-all-you-need-pytorch、https://github.com/tensorflow/tensor2tensor
论文:NON-AUTOREGRESSIVE NEURAL MACHINE TRANSLATION
论文地址:https://einstein.ai/static/images/pages/research/non-autoregressive-neural-mt.pdf
实现地址:未公布
在机器翻译上,我们比较熟悉的就是谷歌大脑 Ashish Vaswani 等人关于注意力机制的研究,该模型在 WMT 2014 英法和英德数据集上都有十分不错的表现。该研究表明在编码器-解码器配置中,显性序列显性转导模型(dominant sequence transduction model)基于复杂的 RNN 或 CNN。表现最佳的模型也需通过注意力机制(attention mechanism)连接编码器和解码器。因此谷歌在该篇论文中提出了一种新型的简单网络架构——Transformer,它完全基于注意力机制,彻底放弃了循环和卷积。上图两项机器翻译任务的实验也表明这些模型的翻译质量不仅十分优秀,同时它们更能并行处理,因此这种模型所需的训练时间也能大大减少。这篇论文表明 Transformer 在其他任务上也泛化很好,能成功应用到有大量训练数据和有限训练数据的英语组别分析任务上。
除了这篇论文,Salesforce 和香港大学等研究者提出了能避免自回归(autoregressive)属性和并行产生输出的模型,这种模型在推断时能减少数个量级的延迟。该论文通过三个层面的训练策略展示了在 IWSLT 2016 英语-德语数据集上产生的大量性能提升,并且在 WMT2016 英语-罗马尼亚语上获得了当前顶尖的效果。
3、文本分类

论文:Learning Structured Text Representations
论文地址:https://arxiv.org/abs/1705.09207
实现地址:未公布
论文:Attentive Convolution
论文地址:https://arxiv.org/pdf/1710.00519.pdf
实现地址:未公布
爱丁堡大学的 Yang Liu 等人提出了学习结构化的文本表征,在这篇论文中,他们关注于在没有语篇解析或额外的标注资源下从数据中学习结构化的文本表征。虽然目前暂时还没有相应的实现代码,不过他们在 Yelp 数据集上准确度能达到 68.6。而另一篇带注意力的卷积提出了了一种 AttentiveConvNet,它通过卷积操作扩展了文本处理的视野。
4、自然语言推理

论文:DiSAN: Directional Self-Attention Network for RNN/CNN-free Language Understanding
论文地址:https://arxiv.org/pdf/1709.04696.pdf
实现地址:未公布
悉尼科技大学和华盛顿大学的研究者提出了 DiSAN,即一种为 RNN/CNN-free 语言理解的定向自注意力网络。该研究提出了一种新颖的注意力机制,即输入序列中每个元素之间的注意力是定向和多维的,这是一种对应特征相连接的注意力。该研究在斯坦福自然语言推理(SNLI)数据集上获得了 51.72% 的准确度。
5、问答

论文:Interactive AoA Reader+ (ensemble)
数据集地址:https://rajpurkar.github.io/SQuAD-explorer/
实现地址:未公布
斯坦福问答数据集(SQuAD)是一个新型阅读理解数据集,该数据集中的问答是基于维基百科并由众包的方式完成的。小编并没有找到该论文,如下 GitHub 地址给出的是该数据集和评估该数据集的模型。

6、命名实体识别

论文:Named Entity Recognition in Twitter using Images and Text
论文地址:https://arxiv.org/pdf/1710.11027.pdf
实现地址:未公布
波恩大学 Diego Esteves 等研究者在推特上使用图像和文本进行命名实体识别,在该论文中,他们提出了一种新颖的多层级架构,该架构并不依赖于任何具体语言学的资源或解码规则。他们的新型模型在 Ritter 数据集上 F-measure 实现了 0.59 的优秀表现。
二、计算机视觉
- 分类
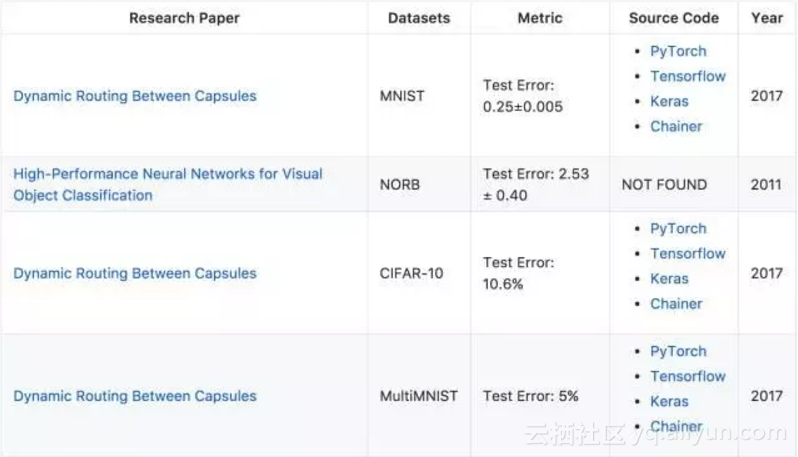
论文地址:https://arxiv.org/pdf/1710.09829.pdf
实现地址:https://github.com/gram-ai/capsule-networks、https://github.com/naturomics/CapsNet-Tensorflow、https://github.com/XifengGuo/CapsNet-Keras、https://github.com/soskek/dynamic_routing_between_capsules
论文:High-Performance Neural Networks for Visual Object Classification
论文地址:https://arxiv.org/pdf/1102.0183.pdf
实现地址:未公布
在计算机视觉领域中,最近比较流行的论文就是 Geoffrey Hinton 等人提出的 Capsule 动态路由方法,。在论文中,Geoffrey Hinton 介绍 Capsule 为:「Capsule 是一组神经元,其输入输出向量表示特定实体类型的实例化参数(即特定物体、概念实体等出现的概率与某些属性)。我们使用输入输出向量的长度表征实体存在的概率,向量的方向表示实例化参数(即实体的某些图形属性)。同一层级的 capsule 通过变换矩阵对更高级别的 capsule 的实例化参数进行预测。当多个预测一致时(本论文使用动态路由使预测一致),更高级别的 capsule 将变得活跃。」
此外,Jurgen Schmidhuber 等人提出了一种视觉目标分类的高性能神经网络,在该论文中他们提出了一种卷积神经网络变体的快速全可参数化的 GPU 实现。虽然该论文是在 2011 年提出的,不过它在 NORB 数据集上还是有非常不错的效果。
三、语音
- ASR

论文:THE MICROSOFT 2017 CONVERSATIONAL SPEECH RECOGNITION SYSTEM
论文地址:https://arxiv.org/pdf/1708.06073.pdf
实现地址:未公布
本文介绍了微软对话语音识别系统的 2017 版本。它在原有的模型架构设置中添加了一个 CNN-BLSTM 声学模型,并且在系统结合之后还添加了一个混合网络再打分的步骤。结果这一系统在数据集 Switchboard Hub5'00 上取得了 5.1% 的词错率。
半监督学习
计算机视觉
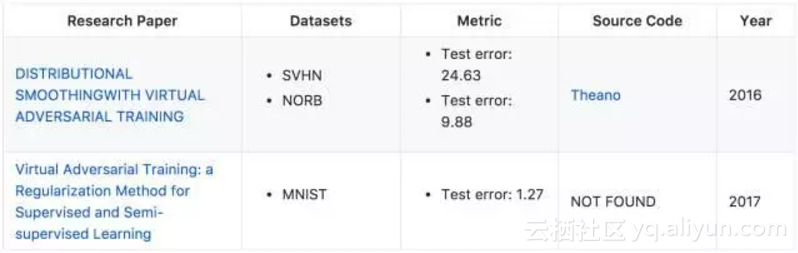
论文:DISTRIBUTIONAL SMOOTHING WITH VIRTUAL ADVERSARIAL TRAINING
论文地址:https://arxiv.org/pdf/1507.00677.pdf
实现地址:https://github.com/takerum/vat
论文:Virtual Adversarial Training: a Regularization Method for Supervised and Semi-supervised Learning
论文地址:https://arxiv.org/pdf/1704.03976.pdf
实现地址:未公布
第一篇论文中,日本京都大学提出了局部分布式平滑度(LDS),一个关于统计模型平滑度的新理念。它可被用作正则化从而提升模型分布的平滑度。该方法不仅在 MNIST 数据集上解决有监督和半监督学习任务时表现优异,而且在 SVHN 和 NORB 数据上,Test Error 分别取得了 24.63 和 9.88 的分值。以上证明了该方法在半监督学习任务上的表现明显优于当前最佳结果。
第二篇论文提出了一种基于虚拟对抗损失的新正则化方法:输出分布的局部平滑度的新测量手段。由于平滑度模型的指示是虚拟对抗的,所以这一方法又被称为虚拟对抗训练(VAT)。VAT 的计算成本相对较低。本文实验在多个基准数据集上把 VAT 应用到监督和半监督学习,并在 MNIST 数据上取得了 Test Error 1.27 的优异表现。
无监督学习
计算机视觉
生成模型
论文:PROGRESSIVE GROWING OF GANS FOR IMPROVED QUALITY, STABILITY, AND VARIATION
论文地址:http://research.nvidia.com/sites/default/files/publications/karras2017gan-paper-v2.pdf
实现地址:https://github.com/tkarras/progressive_growing_of_gans
英伟达在本文中描述了一种新的 GAN 训练方法,其核心思想是同时逐渐地增加生成器与鉴别器的能力:从低分辨率开始,添加持续建模精细细节的新层作为训练过程。这不仅加速了训练,而且更加稳定,获得质量超出预想的图像。本文同时提出了一种增加生成图像变体的简便方法,并在 CIFAR10 上取得了 8.80 的得分。另外的一个额外贡献是创建 CELEBA 数据集的更高质量版本。
项目地址:https://github.com//RedditSota/state-of-the-art-result-for-machine-learning-problems

 浙公网安备 33010602011771号
浙公网安备 33010602011771号