

学界 | 杜克大学NIPS 2017 Oral论文:分布式深度学习训练算法TernGrad
学界 | 杜克大学NIPS 2017 Oral论文:分布式深度学习训练算法TernGrad
机器之心报道
作者:吴欣
为了提高分布式深度学习的速度和效率,杜克大学「进化智能研究中心」陈怡然和李海教授的博士生温伟提出了 TernGrad 分布式训练算法,并与 Hewlett Packard Labs(慧与研究院)徐聪和内华达大学的颜枫教授合作,在大规模分布式深度学习中进行了有效的验证。该工作可以将浮点型的学习梯度(gradients)随机量化到三元值(0 和±1)。理论上,可以把梯度通信量至少减少为原来的 1/20。
日前 NIPS 2017 放出了接收论文,杜克大学的此项工作(TernGrad: Ternary Gradients to Reduce Communication in Distributed Deep Learning)被该顶会接收为今年的口头演讲(oral)。据统计,今年 NIPS 投稿 3240 篇,仅 40 篇接收为口头演讲。
目前,论文已经可以从 arXiv 下载,源代码也在温伟的个人 GitHub 上公开。
-
论文链接:https://arxiv.org/pdf/1705.07878.pdf
-
代码地址:https://github.com/wenwei202/terngrad
背景介绍
随着深度学习神经网络规模越来越大,训练一个深度神经网络(Deep Neural Networks, DNNs)往往需要几天甚至几周的时间。为了加快学习速度,经常需要分布式的 CPU/GPU 集群来完成整个训练。如图 1,在主流的基于数据并行(data parallelism)的分布式深度学习中,各个计算单元(worker)并发地训练同一个 DNN,只不过各个单元用到的训练数据不一样,每一次迭代结束后,各个计算单元里的 DNN 参数或梯度会通过网络(如以太网,InfiniBand 等)发送到参数服务器(Parameter Server)进行同步再下发。训练时间主要包括计算时间(computation time)和通信时间(communication time)。计算时间可以通过增加 workers 线性地减少,然而,通信时间却随着 workers 的增加而增加。因此,在大规模分布式训练中,通信时间成为了新的瓶颈,如何降低通信时间成为很重要的研究课题。理论上,TernGrad 可以把通信量至少减少到 1/20;实际应用中,即使对 0 和±1 采用简单的 2 比特编码(浪费掉一个可用值),相对于传统的 32 比特的浮点型梯度,通信量也可以减少到 1/16。这可以大大克服通信瓶颈的约束,提升分布式训练的可扩展性。

图 1. 基于数据并行的分布式训练
温伟表示,「大大降低梯度的精度,会严重影响 DNN 训练效果。在基于量化的深度模型压缩算法中,即使可以将网络权重量化到低精度,但是训练过程仍然需要浮点精度的梯度,以保证训练的收敛性。那么我们是怎么将梯度量化到只有三个值,却不影响最后识别率的呢?我们的方法其实很简单,在普遍采样的随机梯度下降(Stochastic Gradient Descent,SGD)训练方法中,梯度是随机的,而且这种随机性甚至可以有助于 DNNs 跳出很差的局部最小值。既然梯度本来就是随机的,那为什么我们不把它们进一步随机地量化到 0 和±1 呢?在随机量化时,我们只需要保证新梯度的均值还跟原来一样即可。
在训练过程中,因为学习率往往较小,在梯度形成的优化路径上,即使 TernGrad 偶尔偏离了原来的路径,由于均值是一样的,后续的随机过程能够将偏离弥补回来。我们基于伯努利分布,类似于扔硬币的形式,把梯度随机量化到 0 或±1。在合理假设下,我们理论上证明了 TernGrad 以趋近于 1 的概率收敛到最优点。相对于标准 SGD 对梯度的上界约束,TernGrad 对梯度有更强的上界约束,但是我们提出了逐层三元化(layer-wise ternarizing)和梯度修剪(gradient clipping)技术,使得 TernGrad 的梯度上界约束接近标准 SGD 的上界约束,从而大大改善了 TernGrad 的收敛性。实验结果表明,在分布式训练 AlexNet 时,TernGrad 有时甚至会提高最后的识别率;在 GoogleNet 上,识别率损失也小于 2%。(图 2 为分布式训练 AlexNet 的结果,相对于标准 SGD 基线,TernGrad 具有同样的收敛速度和最终识别率。)」
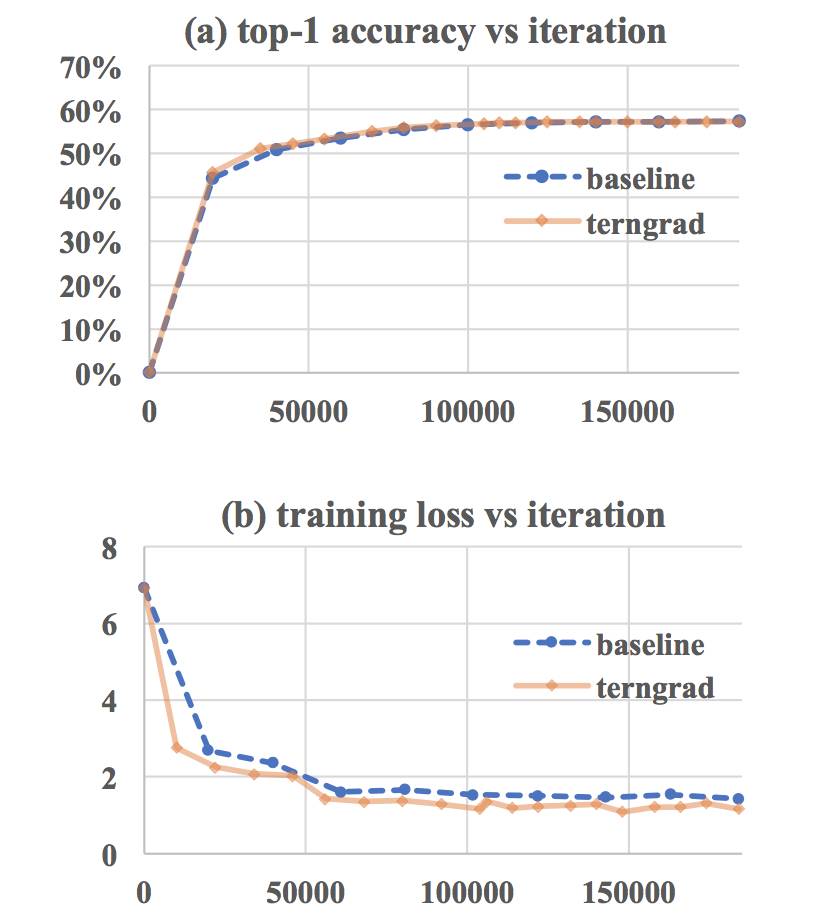
图 2:基于 TernGrad 训练 AlexNet 的收敛性
来自 Hewlett Packard Labs 的徐聪从研究院与公司的角度,谈到此项工作的意义。
「提高分布式深度学习的速度和可扩展性对于工业界有着非常实际的意义。从我们研究院的角度出发,能够快速的根据每次的训练结果迭代改进神经网络的设计对于每个研究员的科研效率的提升有很大的帮助。从更实际的产品角度出发,我们公司有的客户购买了带有八块 NVIDIA GPU 的 HPE Apollo 6500 服务器以后,在使用某些原生态的深度学习框架训练部分神经网络的时候,观察到在八卡上的训练速度甚至不如四卡,对这些神经网络来说,无法有效的利用其中一半的 GPU,是资源上的很大浪费。
在我们帮助这些客户进行性能分析以后,发现通信确实是最重要的瓶颈之一。因此他们希望我们提供一个有效的解决方案,比如提供针对通信瓶颈进行优化的深度学习框架。在这方面,微软将 1-bit SGD 集成在它们的深度学习框架 CNTK 中,在某些语音应用上的训练速度获得了显著提升。然而 1-bit SGD 需要初期采用浮点精度的 SGD 进行预训练,为后续 1-bit SGD 提供较好的初始值。另外,其收敛性尚未理论证明,能否广泛应用尚未知道。TernGrad 能够从头开始训练,并在理论上保证收敛。这使得 TernGrad 可适用于更广泛的 SGD 深度学习应用场景。」
内华达大学的颜枫教授说分布式深度学习可以通过计算集群来提高训练的速度和精度(在相同的时间内采用更复杂的模型和/或更多的训练数据)。但是由于近年来通信性能的发展速度远落后于计算性能的发展速度,因此通信速度和效率常常成为分布式深度学习中的瓶颈所在。为了改进通信的速度和效率,近年来也有很多这方面的工作,但此类工作往往只针对于某种特定的应用场景(比如语音)或者以牺牲较大的训练精度为代价,所以在实际使用中有着很多的局限性。
所以颜枫教授认为,「我们这次的工作充分考虑了通用性和透明性(几乎不影响训练的精度),使得 TernGrad 得以更广泛更简便的应用。TernGrad 通过提升通信速度和效率让分布式深度学习能更有效地利用计算资源。这样不但可以让最新的硬件(比如 GPU,TPU 等)更好地发挥计算潜能,也能让老的计算集群大大提高性能(比如用低速以太网连接的集群),节省资源和成本。更重要的是对于网络带宽有限但计算资源几乎可以无限扩展的云计算,TernGrad 可以大大提高分布式深度学习的延展性。
此外,基于我们之前对分布式深度学习系统性能的建模和分析,我们还设计了一套强化通信性能分析的性能模型,支持各种计算架构和通信模式。这个性能模型利用单个机器性能的分析和计算模型的结合,可以迅速预测出计算集群的性能和瓶颈,从而快速判断我们的 TernGrad 可以带来多大的性能提升,亦可帮助用户在搭建系统和升级系统的时候分析和优化方案。目前我们正在完善和改进 TernGrad 的源代码,并计划在超大规模的硬件平台上做更加详尽的测试和优化。TernGrad 的核心方法还可以延伸到其他具有类似性质的应用中去,因此这个工作具有深远的影响和意义。」

 浙公网安备 33010602011771号
浙公网安备 33010602011771号