csv和excel文件基本操作(topn)
最近做了一个实验,实验得到的结果是一个个的表格,我们需要通过表格做一个topn,然后进行分析。
首选我们先阐述一下我们做topn的基本过程:
概况:我们总共词向量个数为4个,神经网络模型是5个,一共有20种组合,对于每种组合我们做5遍,对于每一种组合的每一遍我们都会经过test.py文件获得三个表格,分别是
[str(number)+“prob”+model_name+"_id.csv",str(number)+“prob”+model_name+"_label.csv",str(number)+“prob”+model_name+"_data_no_weight.csv"]
合计一共会产生:455*3 = 300 个表格
我们对于产生的每3个文件可以做一个topn的统计,所以要做100张表
数量还是不小的,所以我们想着用代码实现做topn的工作
目录
1.代码实现
1.1实现环境
1.2topn基本过程
1.3opera_csv.py
1.4范围扩展
1.4.1 代码实现
2.知识总结
2.1在python中创建excel文件并写入数据
2.2csv文件粘贴到xls文件当中
2.2.1 Pandas中处理Csv和Excel数据详解
2.2.2 Pandas读取与导出Excel、CSV文件
2.2.3 追加行
2.2.4 追加列
2.3 排序
2.3.1 法一
2.3.2 法二
2.4 对表格的内容读取
2.4.1python将列表数据写入已有的excel文件的指定单元格
2.4.2写入多个sheet
2.4.3Python模块xlwt对excel进行特别的写入操作
2.4.4Python 读写excel、csv文件的操作办法
代码实现:
实现环境
一开始我要进行实验,所以我找到一个实验的最小单位,就是一种词向量和一种神经网络进行组合运行5轮后一共会产生15个表格存在一种组合下对应的csv当中,我们首先对一种组合的五轮结果做topn,所以运行文件放在和得到的15个结果表格的同级目录,如图:
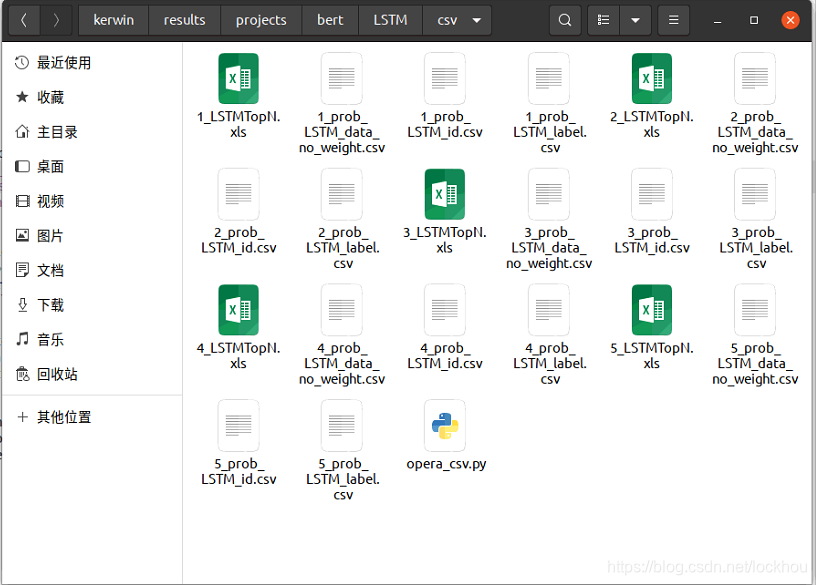
topn的基本过程
1.首先建立一个表格,由三列构成分别为“id” “label” “weight”
2.将每中组合的每论文产生的三个文件中的str(number)+“prob”+model_name+"_id.csv"文件中的数据拷到top文件中的id列,str(number)+“prob”+model_name+"_label.csv"拷到top文件中的label列,str(number)+“prob”+model_name+"_data_no_weight.csv"拷到top文件中的weight列
3.将所有内容以weight为比较基准,将所有数据从大到小排序
4.最后列一个表格如图:
topn即是n条数据当中文件标签即label为以的个数,因为标签非0即1所以对前n条数据的label求和即可,按上述规则填完该表即可

opera_csv.py
#opera_csv.py
import xlwt,xlrd
from xlrd import open_workbook
from xlutils.copy import copy
import pandas as pd
import openpyxl
from openpyxl import load_workbook
model_name = "LSTM"
#建立topn文件并将数据从得到三个csv表格文件填充到topn文件当中
def write_xls(number,excel_path):
#根据模型不同和序号确定出每种组合每一轮所产生的三个文件
file_list = [str(number)+"_prob_"+model_name+"_id.csv",str(number)+"_prob_"+model_name+"_label.csv",str(number)+"_prob_"+model_name+"_data_no_weight.csv"]
#根据对应的表格该填入的类对应构建一个表头列表
type_list = ["id","label","weight"]
print(file_list)
#依次处理三个文件和对应三列
for i in range(3):
#依次确定文件地址,由于在同一目录下直接"./"+加文件名即可
file_path = "./"+file_list[i]
#依次打开三个得到的csv表格
f = open(file_path, encoding='utf-8')
#将依次打开的表格中的数据取出来
data = pd.read_csv(f) #打开待复制的表
#由于得到的每一个csv表的第一行都是0,是无用数据,我们可以作为表头,并打印csv中以0打头的列
print(data['0'])
#打开topn文件(为.xls文件)
data1 = pd.read_excel(excel_path)
#依次将topn文件中的每一列,都赋值为打开对应文件中的数据都是以0为表头
data1[type_list[i]] = data['0']
#将每修改一列后的topn对象转化为xls文件,并且不要索引
data1.to_excel(excel_path,index=False)
#对将填充的topn文件中的所有内容按照weight列的数据从大到小排序
def sort_xls(excel_path):
#读取topn文件
stexcel=pd.read_excel(excel_path)
#让文件按weight列的数据大小从大到小排序
stexcel.sort_values('weight',inplace=True,ascending=False)
#将排序好的文件对象存储成xls文件
stexcel.to_excel(excel_path,index=False)
print(stexcel)
#对已经排好序的topn文件,做topn表格
def topn(excel_path):
#向xls文件当中写入
#打开排序好的topn文件
rb = open_workbook(excel_path)
#复制一份对象
wb = copy(rb)
#选择对工作表1进行操作
#构造表格的行和列,构造两个表格一个横向,一个竖向
sht1 = wb.get_sheet(0)
sht1.write(4,4,"TopN")
sht1.write(4,4,"TopN")
sht1.write(4,5,"Vul_Project")
sht1.write(5,4,"Top10")
sht1.write(6,4,"Top20")
sht1.write(7,4,"Top30")
sht1.write(8,4,"Top40")
sht1.write(9,4,"Top50")
sht1.write(10,4,"Top60")
sht1.write(11,4,"Top70")
sht1.write(12,4,"Top80")
sht1.write(13,4,"Top90")
sht1.write(14,4,"Top100")
sht1.write(15,4,"Top150")
sht1.write(16,4,"Top200")
sht1.write(0,4,"TopN")
sht1.write(1,4,"Vul_Project")
sht1.write(0,5,"Top10")
sht1.write(0,6,"Top20")
sht1.write(0,7,"Top30")
sht1.write(0,8,"Top40")
sht1.write(0,9,"Top50")
sht1.write(0,10,"Top60")
sht1.write(0,11,"Top70")
sht1.write(0,12,"Top80")
sht1.write(0,13,"Top90")
sht1.write(0,14,"Top100")
sht1.write(0,15,"Top150")
sht1.write(0,16,"Top200")
#从xls文件当中读取
sheet=rb.sheet_by_name("Sheet1")
#设置对前n项label数量的计数器,由于非1即0,转化为对label列中前n个单元格中的数值进行求和
sum = 0
#设置一个记录topn的列表,一共记录十二个数据数据分别从top10,20……,100,150,200,之后填写到表格中
top_list=[]
#遍历表格中前200行数据
for i in range(1,201):
#将表格中前200行数据中的label值进行求和
sum = sum + sheet.row_values(i)[1]
#如果是我们要的指定topn我们就添加到列表当中,并打印出来
if(i%10==0 and i<=100) :
top_list.append(sum)
print(sum)
if(i==150 or i==200):
top_list.append(sum)
print(sum)
#将我们统计得到前200个数据中我们要的topn并写入topn文件中,写入的需要使用我们建立的写入对象sht1,若要读取则用sheet对象
for i in range(1,13):
sht1.write(4+i,5,str(top_list[i-1]))
for i in range(1,13):
sht1.write(1,4+i,str(top_list[i-1]))
#保存做完topn表格的topn文件
wb.save(excel_path)
if __name__ == "__main__":
#对于一种词向量和神经网络模型的五轮结果需要建立五个topn文件来存储
for i in range(5):
#建立topn文件
xls = xlwt.Workbook()
sht1 = xls.add_sheet('Sheet1')
#为topn文件添加列头
sht1.write(0,0,'id')
sht1.write(0,1,'label')
sht1.write(0,2,'weight')
#按序并添加模型名为topn表命名
file_name = './'+str(i+1)+'_'+model_name+'TopN'+'.xls'
#保存topn文件
xls.save(file_name)
#输入xls表,并将该表的三列用从三个文件粘贴的数据填充,同时输入序号从而找到对应的三个表进行填充
write_xls(i+1,file_name)
#输入xls表,并按weight列的大小从大到小对所有内容排序
sort_xls(file_name)
#建立topn表格
topn(file_name)
范围扩展
上面的代码只是对于词向量和神经网络的一种组合的五轮实验做了五个topn,那我们我现在想对词向量和神经网络一共20种组合每个组合都进行同样的操作,所以我们就要遍历每一个词向量下的每一个神经网络中的每一个csv文件夹下进行相同的操作即可。所以我们要把该运行文件放在和词向量文件的同级目录当中




代码实现:
所以代码和上面相比无过多的变化,只不过是在主函数中多套两层循环,从而遍历词向量和神将网络的每一种组合
import os
import xlwt,xlrd
from xlrd import open_workbook
from xlutils.copy import copy
import pandas as pd
import openpyxl
from openpyxl import load_workbook
model_name = "LSTM"
#和上面的代码相比我们增加了一个参数,我们不仅需要传递topn文件,
#还需传递topn文件所在目录的地址,用于可以确定每一次结果对应的三个
#csv表格文件,原来是运行文件直接和所有csv文件同一个目录,直接使用
#“./”+三个csv文件名即可找到文件,而这里我们运行文件放在和词向量文件夹同
#一个目录下,所有我们要在遍历过程中扩充文件地址,并传入到该函数中,从而
#确定三个csv表格文件的位置
def write_xls(number,excel_path,excel_location):
file_list = [str(number)+"_prob_"+model_name+"_id.csv",str(number)+"_prob_"+model_na
me+"_label.csv",str(number)+"_prob_"+model_name+"_data_no_weight.csv"]
type_list = ["id","label","weight"]
print(file_list)
for i in range(3):
file_path = excel_location + file_list[i]
f = open(file_path, encoding='utf-8')
data = pd.read_csv(f) #打开待复制的表
print(data['0'])
print(type(data))
data1 = pd.read_excel(excel_path)
data1[type_list[i]] = data['0']
data1.to_excel(excel_path,index=False)
def sort_xls(excel_path):
stexcel=pd.read_excel(excel_path)
stexcel.sort_values('weight',inplace=True,ascending=False)
stexcel.to_excel(excel_path,index=False)
print(stexcel)
def topn(excel_path):
rb = open_workbook(excel_path)
wb = copy(rb)
sht1 = wb.get_sheet(0)
sht1.write(4,4,"TopN")
sht1.write(4,4,"TopN")
sht1.write(4,5,"Vul_Project")
sht1.write(5,4,"Top10")
sht1.write(6,4,"Top20")
sht1.write(7,4,"Top30")
sht1.write(8,4,"Top40")
sht1.write(9,4,"Top50")
sht1.write(10,4,"Top60")
sht1.write(11,4,"Top70")
sht1.write(12,4,"Top80")
sht1.write(13,4,"Top90")
sht1.write(14,4,"Top100")
sht1.write(15,4,"Top150")
sht1.write(16,4,"Top200")
sht1.write(0,4,"TopN")
sht1.write(1,4,"Vul_Project")
sht1.write(0,5,"Top10")
sht1.write(0,6,"Top20")
sht1.write(0,7,"Top30")
sht1.write(0,8,"Top40")
sht1.write(0,9,"Top50")
sht1.write(0,10,"Top60")
sht1.write(0,11,"Top70")
sht1.write(0,12,"Top80")
sht1.write(0,13,"Top90")
sht1.write(0,14,"Top100")
sht1.write(0,15,"Top150")
sht1.write(0,16,"Top200")
sheet=rb.sheet_by_name("Sheet1")
sum = 0
top_list=[]
for i in range(1,201):
sum = sum + sheet.row_values(i)[1]
if(i%10==0 and i<=100) :
top_list.append(sum)
print(sum)
if(i==150 or i==200):
top_list.append(sum)
print(sum)
for i in range(1,13):
sht1.write(4+i,5,str(top_list[i-1]))
for i in range(1,13):
sht1.write(1,4+i,str(top_list[i-1]))
wb.save(excel_path)
if __name__ == "__main__":
#列出同级的所有词向量文件夹
FileList = os.listdir(".")
#遍历所有词向量文件夹
for File in FileList:
#如果是文件夹则继续操作,如果不判断,则因为运行文件和其同目录无法遍历从而报错
if os.path.isdir(File):
#扩充文件路径用于确定表格路径
Files = os.listdir("./"+File)
#遍历词向量中的每一个模型
for file in Files:
#根据遍历模型文件夹的名字修改模型名字,从而确定不同的csv表格
model_name = file
#扩充地址到每一种词向量和神经网络模型运行结果的csv文件当中
file_path = "./"+File+'/'+file+'/'+"csv/"
#每一种组合的五次运行结果共15个csv文件,需要建立五个对应的topn文件
for i in range(5):
xls = xlwt.Workbook()
sht1 = xls.add_sheet('Sheet1')
#添加字段
sht1.write(0,0,'id')
sht1.write(0,1,'label')
sht1.write(0,2,'weight')
file_name = file_path +str(i+1)+'_'+model_name+'TopN'+'.xls'
xls.save(file_name)
write_xls(i+1,file_name,file_path)
sort_xls(file_name)
topn(file_name)
知识总结
在python中创建excel文件并写入数据
python的包xlwt和xlsxwriter都是比较方便创建excel文件并写入数的。
工具:python3.0+
首先,需要安装好相应的包。pip install xlwt 或pip install xlsxwriter
xlwt中:
通过xlwt.Workbook()来新建工作簿;
通过.add_sheet(“Sheet名”)来新建sheet;
通过.write(行号,列号,值)来一个单元格一个单元格地写入数据,注意,行号和列号均从0开始;
最后,通过.save(‘文件名’)来保存。
import xlwt
xls = xlwt.Workbook()
sht1 = xls.add_sheet('Sheet1')
#添加字段
sht1.write(0,0,'字段1')
sht1.write(0,1,'字段2')
sht1.write(0,2,'字段3')
sht1.write(0,3,'字段4')
#给字段中加值 考虑使用循环
sht1.write(1,0,'值1')
sht1.write(1,1,'值2')
sht1.write(1,2,'值3')
sht1.write(1,3,'值4')
xls.save('./mydata.xls')
xlsxwriter中:
通过xlsxwriter.Workbook(‘新建的文件名’)来新建工作簿;
通过.add_worksheet()来新建sheet;
通过.write(行号,列号,值)来一个单元格一个单元格地写入数据,注意,行号和列号均从0开始;
最后,通过.close()来保存。
import xlsmwriter
xls2 = xlsmwriter.Workbook('./mydata.xls')
sht1 = xls2.add_worksheet()
#添加字段
sht1.write(0,0,'字段1')
sht1.write(0,1,'字段2')
sht1.write(0,2,'字段3')
sht1.write(0,3,'字段4')
#给字段中加值 考虑使用循环
sht1.write(1,0,'值1')
sht1.write(1,1,'值2')
sht1.write(1,2,'值3')
sht1.write(1,3,'值4')
xls2.close()
csv文件粘贴到xls文件当中
Pandas中处理Csv和Excel数据详解
典型的处理是read_csv,read_excel,to_csv,to_excel前两个是读取csv和xls文件形成对象,后两者对与读出的对象转转化为csv和xls文件。我我们读取文件后的对象可以被修改某个单元格的值,修改某行或某列的元素,但是必须要to_csv,to_xls方法到相同位置也就是打开的文件,这样我们修改才会生效,我们打开我们要修改的文件,就可以发现我我们对表格文件进行操作(pandas读取csv文件数据的方法及注意点)
Pandas读取与导出Excel、CSV文件
在使用Pandas处理数据时,常见的读取数据的方式时从Excel或CSV文件中获取,另外有时也会需要将处理完的数据输出为Excel或CSV文件。今天就一起来学习下Pandas常见的文件读取与导出的方法。在Pandas中,并且读取得到的是一种Dframe的对象。
Excel文件读取
方法是:pd.read_excel()。具体可传参数为:
pandas.read_excel(io, sheet_name=0, header=0, names=None, index_col=None,
usecols=None, squeeze=False, dtype=None, engine=None, converters=None,
true_values=None, false_values=None, skiprows=None, nrows=None,
na_values=None, parse_dates=False, date_parser=None, thousands=None,
comment=None, skipfooter=0, convert_float=True, **kwds)
其中:
io:excel文件,可以是文件路径、文件网址、file-like对象、xlrd workbook
sheetname:返回指定的sheet,参数可以是字符串(sheet名)、整型(sheet索引)、list(元素为字符串和整型,返回字{‘key’:’sheet’})、none(返回字典,全部sheet)
header:指定数据表的表头,参数可以是int、list of ints,即为索引行数为表头
names:返回指定name的列,参数为array-like对象。
index_col:设定索引的列,参数可以是int、list of ints
usecol:设定需要解析的列,默认为None,代表解析素有,如果直传一个int,代表解析到最后的那个列,如果传的是list则返回的是限定的列,比如:“A:E”或“A,C,E:F”
squeeze:如果解析的数据只包含一列数据,则返回一个Series,默认返回为DataFrame
dtype:可以制定每列的类型,示例:{‘a’: np.float64, ‘b’: np.int32}
engine:如果 io 不是缓冲区或路径,则必须设置 io。 可接受的值是 None 或 xlrd
converters:自定形式,设定对应的列要用的转换函数。
true_values:设定安歇为True值,不常用
false_values:设定哪些为False值,不常用
shiprows:需要跳过的行,list-like类型
nrows:要分析的行数
na_values:N/A值列表
parse_dates:传入的是list,将指定的类解析为date格式
date_parser:指定将输入的字符串转换为可变的时间数据。Pandas默认的数据读取格式是‘YYYY-MM-DD HH:MM:SS’。如需要读取的数据没有默认的格式,就要人工定义。
thousands:千位分格数字的解析
comment:设定注释标识,在注释内的内容不解析
skipfooter:跳过末尾行
convert_float:将小数位为0的float类型转为int
**kwds:不清楚
该函数返回pandas中的DataFrame或dict of DataFrame对象,利用DataFrame的相关操作即可读取相应的数据。
import pandas as pd
excel_path = 'example.xlsx'
df = pd.read_excel(excel_path, sheetname=None)
print(df['sheet1'].example_column_name)
该函数主要的参数为io、sheetname、header、names、encoding。encoding在上面的参数说明中没有介绍到,其主要功能是指定用何种编码(codecs 包中的标准字符集)读取数据。
例如读取文件时报如下错误:
UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0x84 in position 36: invalid
start byte
解决办法为设置encoding=”utf_8_sig” 或 encoding=”cp500″ 或 encoding=”gbk”,需要自行进行尝试。
加载CSV文件
在Pandas中,Excel文件读取方法是:pd.read_csv()。具体可传参数为:
pandas.read_csv(filepath_or_buffer, sep=', ', delimiter=None, header='infer',
names=None, index_col=None, usecols=None, squeeze=False, prefix=None,
mangle_dupe_cols=True, dtype=None, engine=None, converters=None,
true_values=None, false_values=None, skipinitialspace=False, skiprows=None,
nrows=None, na_values=None, keep_default_na=True, na_filter=True,
verbose=False, skip_blank_lines=True, parse_dates=False,
infer_datetime_format=False, keep_date_col=False, date_parser=None,
dayfirst=False, iterator=False, chunksize=None, compression='infer',
thousands=None, decimal=b'.', lineterminator=None, quotechar='"', quoting=0,
escapechar=None, comment=None, encoding=None, dialect=None,
tupleize_cols=None, error_bad_lines=True, warn_bad_lines=True, skipfooter=0,
doublequote=True, delim_whitespace=False, low_memory=True,
memory_map=False, float_precision=None)
与read_excel不同的参数有:
filepath_or_buffer:这里可以接受一个文件名,或者一个URL,也可以接受一个打开的文件句柄,或者其他任何提供了read方法的对象。
sep和delimiter:这两个参数是一个意思,delimiter是sep的别名;如果指定为\t(制表符)的话,就可以实现read_table的默认功能;支持使用正则表达式来匹配某些不标准的CSV文件
mangle_dupe_cols:将冲虚的列X,指定为1,X.2,…
skipinitialspace:在分隔符后跳过空格。
keep_default_na:在解析数据时是否要包含默认的 NaN 值。
na_filter:检测丢失的值标记(空字符串和 na 值的值)。 在没有 NAs 的数据中,通过过滤器 False 可以提高读取大文件的性能
verbose:指示放置在非数字列中的 NA 值的数目
skip_blank_lines:如果是真的,跳过空白行,而不是将其解释为 NaN 值。
infer_datetime_format:如果启用 True 和 parse_dates,Pandas将尝试推断列中的差异的时间字符串的格式,如果可以推断出来,则切换到更快的分析方法。 在某些情况下,这可以使解析速度提高5-10倍。
keep_date_col:解析出日期序列后,是否保留原来的列
dayfirst:日期格式,DD/MM哪个在前
iterator:返回 TextFileReader 对象用于迭代或 get chunk ()。
chunksize:返回 TextFileReader 对象进行迭代。 有关iterator和chunksize的更多信息,请参见 IO 工具文档。
compression:用于磁盘数据的实时解压
decimal:识别有小数点的字符
lineterminator:字符将文件分隔程行,只有C解析器才有效
quotechar:用于表示引用项的开始和结束的字符。 引用的项可以包括分隔符,它将被忽略。
quoting:控制字段引用行为
escapechar:跳过的字符?
dialect:如果提供了这个参数,这个参数将覆盖以下参数的值(默认或不是) : 分隔符、双引号、 escapechar、 skipinitialspace、 quotechar 和引号。 如果需要重写值,将发布一个 ParserWarning。 详情请参阅 csv 方言文档。
tupleize_cols:在列上留下一个元组列表(默认情况是在列上转换为多索引)
error_bad_lines:有太多字段的行(例如 csv 行,有太多逗号)将默认引发异常,并且不会返回 DataFrame。 如果错误,那么这些”bad lines”将从返回的 DataFrame 中删除。
warn_bad_lines:如果错误错误行为是 False,并警告错误行是 True,那么对于每个”坏行”的警告将是输出。
doublequote:指定 quotechar 时,引用不是QUOTE_NONE,指示是否将两个连续的 quotechar 元素解释为一个单独的 quotechar 元素。
delim_whitespace:设定是否使用空白做字段区隔
low_memory:内部处理文件的块,导致较低的内存使用同时分析,但可能混合类型推理。 为了确保没有混合类型设置 False,或指定具有 dtype 参数的类型。 请注意,整个文件被读入一个单一的 DataFrame,使用 chunksize 或 iterator 参数将数据以块的形式返回。 (只有 c 解析器有效)
memory_map:如果为文件或缓冲区提供一个文件程序,将文件对象直接映射到内存中,并直接从内存访问数据。 使用此选项可以提高性能,因为不再有任何 i / o 开销。
float_precision:指定 c 引擎应用于浮点值的转换器。
加载CSV文件的方法同加载Excel类似。但是从性能上导入csv要比导入Excel快很多,收益推荐使用csv导入。但是如果 导入的csv的格式存在一些问题,则可能出现错行的问题。
另外,除了导入CSV、Excel外,Pandas还支持如下方式导入:
read_sql(query, connection_object):从SQL表/库导入数据
read_json(json_string):从JSON格式的字符串导入数据
DataFrame(dict):从字典对象导入数据,Key是列名,Value是数据
read_html(url):解析URL、字符串或者HTML文件,抽取其中的tables表格
read_clipboard():从你的粘贴板获取内容,并传给read_table()
read_table(filename):从限定分隔符的文本文件导入数据
这里有必要重点学习的是pd.read_sql(query, connection_object),规划将在后面的学习中分享。
导出到Excel文件
导出到Excel的方法非常的简单:
import pandas as pd
excel_path = 'example.xlsx'
df = pd.read_excel(excel_path, sheetname=None)
df.to_excel('output.xlsx')
具体导出方法还有众多参数:
DataFrame.to_excel(excel_writer, sheet_name='Sheet1', na_rep='',
float_format=None, columns=None, header=True, index=True, index_label=None,
startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None,
inf_rep='inf', verbose=True, freeze_panes=None)
参数含义为:
excel_writer:写入的目标excel文件,可以是文件路径、ExcelWriter对象;
sheet_name:被写入的sheet名称,string类型,默认为’sheet1′;
na_rep:缺失值表示,string类型;
float_format:浮点数的格式
columns:要写入的列
header:是否写表头信息,布尔或list of string类型,默认为True;
index:是否写行号,布尔类型,默认为True;
index_label:索引标签
startrow:开始行,其余会被舍弃
startcol:开始列,其余会被舍弃
engine:写入的引擎,可以是:excel.xlsx.writer, io.excel.xls.writer, io.excel.xlsm.writer
merge_cells:合并单元格配置
encoding:指定写入编码,string类型。
inf_rep:指定数学符号无穷在Excel的表示
verbose:未知
freeze_panes:冻结窗格
导出到CSV文件
导出方法同Excel类型,具体方法参数为:
DataFrame.to_csv(path_or_buf=None, sep=', ', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, mode='w', encoding=None, compression=None, quoting=None, quotechar='"', line_terminator='\n', chunksize=None, tupleize_cols=None, date_format=None, doublequote=True, escapechar=None, decimal='.')
具体参数含义为(与“导入CSV文件”、“导出为Excel文件”重复的内容不再单独说明):
path_or_buf:写入的文件名或文件路径
mode:写入文件的模式,默认为w,改为a为追加。
date_format:时间格式设定
Pandas还支持的导出方式有:
to_sql(table_name, connection_object):导出数据到SQL表
to_json(filename):以Json格式导出数据到文本文件
df.to_sql将在后面的学习中再做分享。
追加列
现在我们已经学会了如何从文件中读取数据并转化为对象的形式,并且把我们改变好的对象,再转化为表格文件,所以如何对我们的对象进行操作就变得至关重要。我们做topn的时候是把三个表格文件中的每一类都添加到我我们的topn文件当中,但是再网上并未寻求到明确的答案,我从文章中下列代码得到启发,并且改篇文章也提到了追加行的写法
from pandas import DataFrame
# Load each file into a pandas dataframe, this is based on a numpy array
data1 = DataFrame.from_csv('csv1.csv',sep=',',parse_dates=False)
data2 = DataFrame.from_csv('csv2.csv',sep=',',parse_dates=False)
#Now add 'header5' from data1 to data2
data2['header5'] = data1['header5']
#Save it back to csv
data2.to_csv('output.csv')
追加行
同为excel文件
import xlwt,xlrd
from xlutils.copy import copy
wb_temp=xlrd.open_workbook(excel_path) #打开待复制的表
sheet1=wb_temp.sheet_by_index(0) #根据索引获取第一个sheet
row=sheet1.row_values(1)#获取第二行的内容,w为一个list
wb_all=xlrd.open_workbook('./report/vertigo_data.xls')#打开待粘贴的表
sheets = wb_all.sheet_names() # 获取工作簿中的所有表格
sheet2 = wb_all.sheet_by_name(sheets[0]) # 获取工作簿中所有表格中的的第一个sheet
k=sheet2.nrows #获取表中已经有的数据行数
new_wb =copy(wb_all) #将xlrd对象拷贝转化为xlwt对象,要用到xlutils模块
new_sheet = new_wb.get_sheet(0)#获取转化后工作簿中的第一个sheet
print(k)
for i,content in enumerate(row):
new_sheet.write(k,i,content)
new_wb.save('./report/vertigo_data.xls') # 保存工作簿
同为csv文件
import csv
filetoread=open('filenametoread','r')
filetowrite=open('filenametowrite','a')
reader=csv.reader(filetoread)
writer=csv.writer(filetowrite)
for line in reader:
writer.writerow(line)
print(line)
filetoread.close()
filetowriter.close()
排序
法一:
EXCEL的数值排序功能还是挺强大的,升序、降序,尤其自定义排序,能够对多个字段进行排序工作。
那么,在Python大法中,有没有这样强大的排序功能呢?答案是有的,而且本人觉得Python的排序功能,一点不比EXCEL的差。
同样,我们依然用到的是强大的pandas这个三方库。我们先将numpy和pandas导入进来:
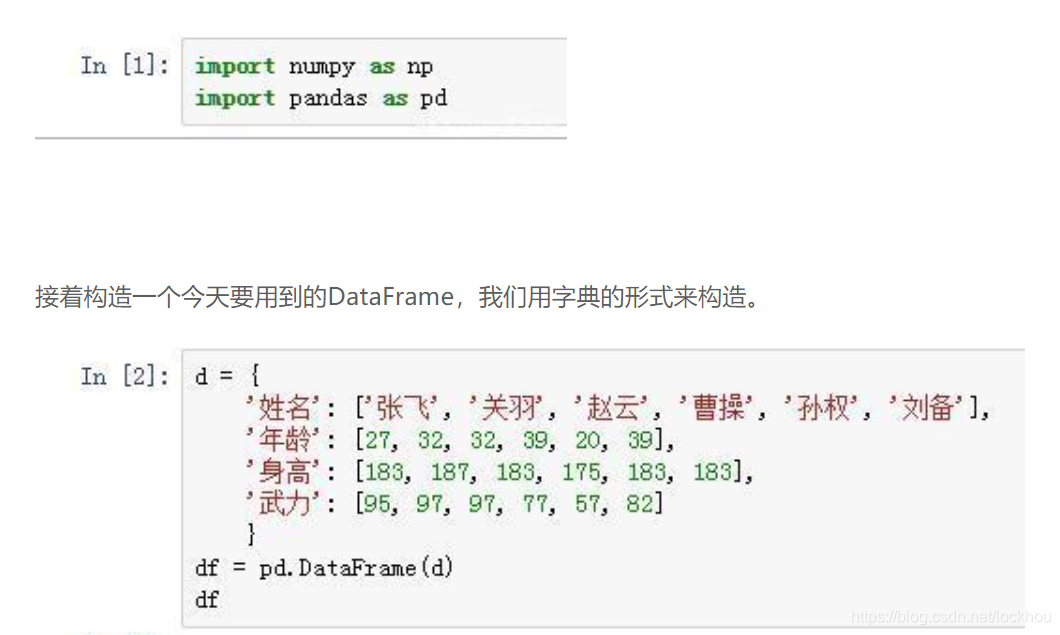

都是随意构造的,内容别较真。我们先来个简单点的热热身,按照身高的降序来排列一下

我们用到的是df.sort_values()这个函数。第一个参数为by,传入你要排序的列的标签名即可,后面的ascending参数指示排序方法为升序还是降序,True为升序,False为降序。由于存在相同的身高,pandas会自动的比较两个相同身高所对应的index,按照index的升序来排列。
假如我有这样一个需求:先按照身高降序排序,若存在相同的身高,则再按照武力来降序排序,可以做到吗?
当然可以,我们只需要在by参数里传入列标签组成的列表即可。
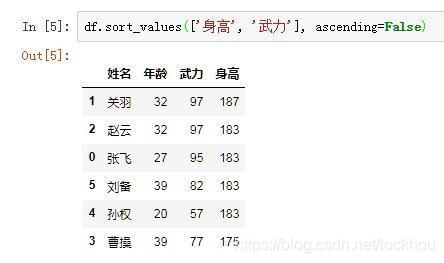
通过这个例子我们可以看到,by参数不但可以传入字符串,还可以传入字符串组成的列表,来实现对多个列进行排序。
接着,我的要求再高一点。身高我依然需要降序,但是武力我需要升序,可以吗?
我们直接上结果:
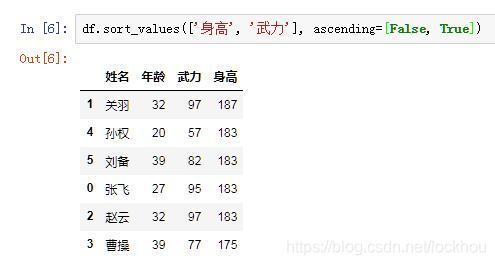
跟by参数类似,我们只需要在ascending参数中也传入布尔值组成的列表就可以了,意思就是告诉pandas,这两列我各自需要的排序方式,就跟后面ascending参数里指定的一样。因此,这两个参数的列表内的元素个数需要是一致的,否则就会报错了,因为没法一一对应。
关于sort_values这个强大的排序函数就介绍到这了。除了这些参数之外,它还有inplace、kind和na_position等参数来应对不同的排序需求。可以参考官网文档进行学习
法2
excel表数据如下
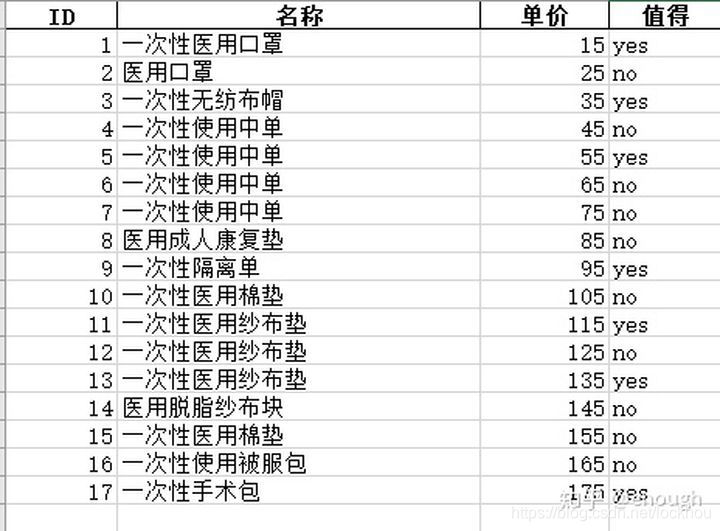
要求实现:商品单价按降序排列,不值得买商品中哪件是最贵的
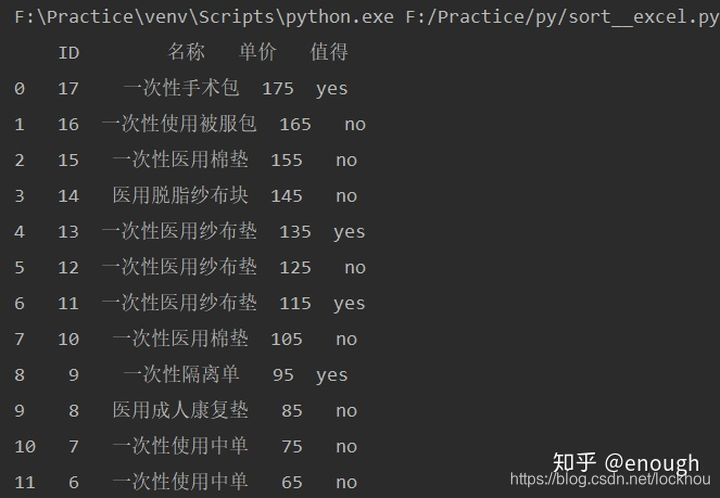
1、商品单价按降序排列
会用到pandas中的排序方法sort_values(),表示根据某一列排序。
pd.sort_values(by="A",inplace=True)
表示pd按照A这个字段排序,inplace默认为False,如果该值为True,那么就会在当前的dataframe上操作。
ascending 默认等于True,按从小到大排列,改为False 按从大到小排。
import pandas as pd
stexcel=pd.read_excel('F:/Practice/py/practise_06.xlsx')
stexcel.sort_values(by='单价',inplace=True,ascending=False)
print(stexcel)
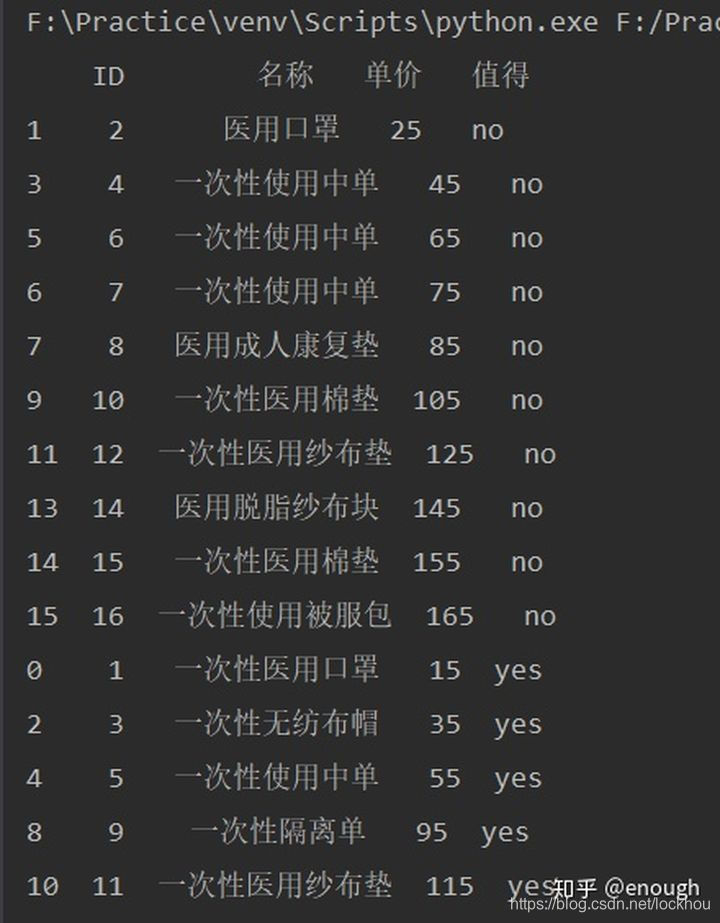
2、不值得买商品中哪件是最贵的
双重排序的话就要在by后边借一个list
import pandas as pd
stexcel=pd.read_excel('F:/Practice/py/practise_06.xlsx')
stexcel.sort_values(by=['值得','单价'],inplace=True)
print(stexcel)
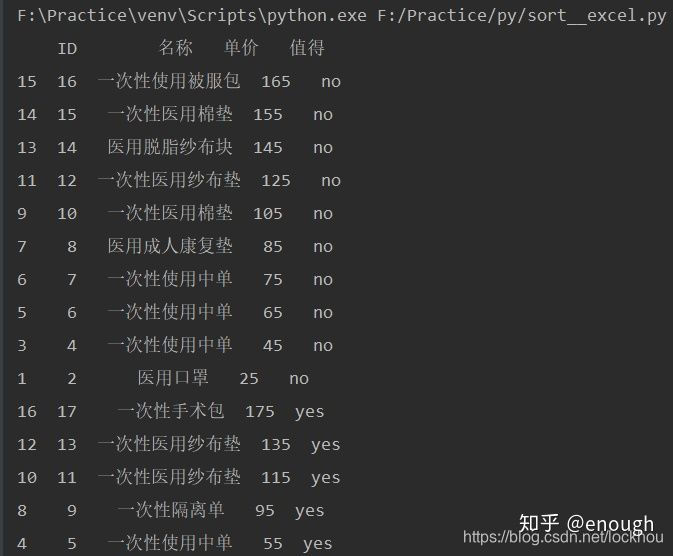
这样确定按照 是否值得排序的,但是单价没有按照降序的要求来排列。可以这样给ascending也加一个list 值得=True 单价=False,这样就得到了想要的数据。
import pandas as pd
stexcel=pd.read_excel('F:/Practice/py/practise_06.xlsx')
stexcel.sort_values(by=['值得','单价'],inplace=True,ascending=[True,False])
print(stexcel)
对表格的内容读取
最近在用包xlrd读取excel表格内容,自然就用到了open_workbook方法,先将其具体用法详解如下(注释已经写的很详细了),直接上代码如下:
import os
import getpathInfo
from xlrd import open_workbook
#拿到该项目所在的绝对路径
path=getpathInfo.get_path()
# print(path)
class readExcel():
def get_xls(self,xls_name,sheet_name):
cls=[]
xlsPath=os.path.join(path,'testFile','case',xls_name)
#打开excel用例文件;
file=open_workbook(xlsPath)
# print(file)
sheet=file.sheet_by_name(sheet_name)
#获取所有行数;
nrows=sheet.nrows
#打印一下共几行
print(nrows)
for i in range(nrows):
if sheet.row_values(i)[0]!=u'case_name':
cls.append(sheet.row_values(i))
return cls
if __name__=="__main__":
#打印一下共几行数据
print(readExcel().get_xls("userCase.xlsx","login"))
# 因其数据是一个列表形式,所以取值的时候要通过下标的来取值
print(readExcel().get_xls("userCase.xlsx", "login")[0][1])
# 因其数据是一个列表形式,所以取值的时候要通过下标的来取值
print(readExcel().get_xls("userCase.xlsx", "login")[1][2])
wb = xlrd.open_workbook(“file.xls”) #打开Excel文件
sheet = wb.sheet_by_name(“Sheet1”) #通过sheet名字获取工作sheet
sheet = wb.sheet_by_index(0) #通过索引号获取工作表sheet,从0开始
ncols=sheet.ncols #获取工作表中列数
nrows=sheet.nrows #获取工作表行数
raw_i=sheet.row_values(i):#获取工作表中某一行的值,结果为列表形式。从0开始:0–第一行
col_i=sheet.col_values(i):#获取工作表中某一列的值,结果为列表形式。从0开始:0–第一列
for i in range(ncols): #获取全部列的值(行亦如此)
print(sheet.col_values(i))
cell_value=sheet.cell(行,列).value #获取单元格的值
cell_value=sheet.row(i)[j].value #获取工作表中(i+1行,j+1列)的值
表格中写入内容
python将列表数据写入已有的excel文件的指定单元格
第一种方法要用到xlwt、xlutils、xlrd三个第三方库。
import xlwt as xw
from xlutils.copy import copy
import xlrd as xr
a=[5,6,7,8,9,10,11,12,1,2,3,4]
file="data1.xls"
style = xw.easyxf()#字体风格设置,此处为默认值
oldwb = xr.open_workbook(file)#打开工作簿
newwb = copy(oldwb)#复制出一份新工作簿
newws = newwb.get_sheet(0)#获取指定工作表,0表示实际第一张工作表
for i in range(len(a)):
newws.write(i+1, 0, a[i],style) #把列表a中的元素逐个写入第一列,0表示实际第1列,i+1表示实际第i+2行
newwb.save(file)#保存修改
需要注意的是,第一种方法操作的是97-2003版的excel文件,也就是后缀名是xls的,如果操作的是xlsx文件,则会出错。
第二种方法要用到openpyxl库。
原excel文件内容如下:

需要给“出力”这一列填充上列表数据,代码如下:
import openpyxl as op
a=[150,170,240,270,260,200,130,90,80,86,100,110]
wb = op.load_workbook("data2.xlsx")
sh=wb["Sheet1"]
for i in range(1,13):
sh.cell(i+1,3,a[i-1])
wb.save("data2.xlsx")
代码运行结果如下图:
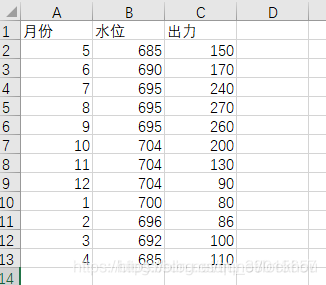
显然,第二种方法比第一种方法要方便得多。第二种方法对xlsx文件也是可以处理的。需要注意的是,sh.cell(i+1,3,a[i-1])这一行代码当中,索引号和实际工作表中的索引号是一样的,也就是说cell(1,2)就表示实际第1行第2列的单元格。
对与xls文件还可以采用下面方法:
#目标:在excel某表格的某位置插入数据,这里我想插入一列数据
import pandas as pd
import openpyxl
'''
distance_list是一个列表,我们的目标是将该列表作为一列插入表格
'''
# 先打开我们的目标表格,再打开我们的目标表单
wb=openpyxl.load_workbook(r'D:\working\FirstPaper\user_info.xlsx')
ws = wb['Sheet1']
# 取出distance_list列表中的每一个元素,openpyxl的行列号是从1开始取得,所以我这里i从1开始取
for i in range(1,len(distance_list)+1):
distance=distance_list[i-1]
# 写入位置的行列号可以任意改变,这里我是从第2行开始按行依次插入第11列
ws.cell(row = i+1, column = 11).value =distance
# 保存操作
wb.save(r'D:\working\FirstPaper\user_info_distance.xlsx')
写入多个sheet
多个数据需要写入多个excel的工作簿,这时需要调用通过ExcelWriter()方法打开一个已经存在的excel表格作为writer,然后通过to_excel()方法将需要保存的数据逐个写入excel,最后关闭writer。
示例代码如下:
# 创建一个空的excel文件
nan_excle = pd.DataFrame()
nan_excel.to_excel(path + filename)
# 打开excel
writer = pd.ExcelWriter(path + filename)
#sheets是要写入的excel工作簿名称列表
for sheet in sheets:
output.to_excel(writer, sheet_name=sheet)
# 保存writer中的数据至excel
# 如果省略该语句,则数据不会写入到上边创建的excel文件中
writer.save()
Python模块xlwt对excel进行特别的写入操作
Python 读写excel、csv文件的操作办法
1、excel 写入
#excel 写入
import xlwt
myWorkbook = xlwt.Workbook()
mySheet = myWorkbook.add_sheet('Record_List') # 添加活页博
#数据写入,写入标题
mySheet.write(0, 0, "机器人语音测试反馈记录表")
#数据循环写入
for i,contents in enumerate(content_list_all): #content_list_all为需写入的数组数据
for j,content in enumerate(contents):
mySheet.write(i+1,j,content)
myWorkbook.save('Debug' + '.xls') #保存excle数据表。
2、excel读取
#excel读取
import xlrd
data = xlrd.open_workbook('Debug.xls')#打开需要读取的excel表
table = data.sheets()[0] #提取第0个活页博,即excel中首个活页博
#取出数据
col_data = table.col_values(4) #取出第4列的数据,生成数组。
row_data =table.row_values(12) #取出第12行的数据,生成数组。
#获取行数和列数
nrows = table.nrows
ncols = table.ncols
#循环提取行列表数据
for i in range(nrows):
print(table.row_values(i))
#提取单元格
cell1 = table.cell(0,0).value
cell2 = table.cell(3,3).value
#使用行列索引
cell_3 = table.row(0)[0].value
cell_4 = table.col(1)[0].value
3、写入csv
#写入csv
import csv
with open('records.csv','a',newline='') as code:
m = csv.writer(code,dialect='excel')
if head !=[]:
m.writerow(head) #head 为标题栏信息,为数组。
head = []
m.writerow(the_content) #写入数据
4、读取csv
#读取csv
import csv
with open('records.csv', 'r') as f:
content = csv.reader(f) #读取csv数据
for row in content: #打印数据
print(row)
链接:https://www.jianshu.com/p/61d41c27e76b

 浙公网安备 33010602011771号
浙公网安备 33010602011771号