Hadoop之MapReduce学习(二)
现有需求如下:
荆州市洪湖市万全镇张当村共有300户居民 因疫情原因隔离在家 现在要求代购下面的商品
(随机构造一些商品 数量随机)
1.洗漱用品 脸盆、杯子、牙刷和牙膏、毛巾、肥皂(洗衣服的)以及皂盒、洗发水和护发素、沐浴液...
2.床上用品 比如枕头、枕套、枕巾、被子、被套、棉被、毯子、床垫、凉席等。
3.家用电器 比如电磁炉、电饭煲、吹风机、电水壶、豆浆机、台灯等。
4.厨房用品 比如锅、碗、瓢、盆、灶、所有的厨具,柴、米、油、盐、酱、醋
代购员需要到超市购买 以下的商品 但是统计问题非常困难 需要我们的的帮助
项目 1.生成模拟的数据 (项目名:bestbill)
项目 2.MapReduce去统计 (项目名:countbill)
一.生成模拟的数据
编写程序生成一定量的数据供我们计算使用:
package com.blb.core;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.FileWriter;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
/**
* 300户 每户都会有一个清单文件
* 商品是随机 数量也是随机
* 洗漱用品 脸盆、杯子、牙刷和牙膏、毛巾、肥皂(洗衣服的)以及皂盒、洗发水和护发素、沐浴液 [1-5之间]
* 床上用品 比如枕头、枕套、枕巾、被子、被套、棉被、毯子、床垫、凉席 [0 1之间]
* 家用电器 比如电磁炉、电饭煲、吹风机、电水壶、豆浆机、台灯等 [1-3之间]
* 厨房用品 比如锅、碗、瓢、盆、灶 [1-2 之间]
* 柴、米、油、盐、酱、醋 [1-6之间]
* 要生成300个文件 命名规则 1-300来表示
* @author Administrator
*
*/
public class BuildBill {
private static Random random=new Random(); //要还是不要
private static List<String> washList=new ArrayList<>();
private static List<String> bedList=new ArrayList<>();
private static List<String> homeList=new ArrayList<>();
private static List<String> kitchenList=new ArrayList<>();
private static List<String> useList=new ArrayList<>();
static{
washList.add("脸盆");
washList.add("杯子");
washList.add("牙刷");
washList.add("牙膏");
washList.add("毛巾");
washList.add("肥皂");
washList.add("皂盒");
washList.add("洗发水");
washList.add("护发素");
washList.add("沐浴液");
///////////////////////////////
bedList.add("枕头");
bedList.add("枕套");
bedList.add("枕巾");
bedList.add("被子");
bedList.add("被套");
bedList.add("棉被");
bedList.add("毯子");
bedList.add("床垫");
bedList.add("凉席");
//////////////////////////////
homeList.add("电磁炉");
homeList.add("电饭煲");
homeList.add("吹风机");
homeList.add("电水壶");
homeList.add("豆浆机");
homeList.add("电磁炉");
homeList.add("台灯");
//////////////////////////
kitchenList.add("锅");
kitchenList.add("碗");
kitchenList.add("瓢");
kitchenList.add("盆");
kitchenList.add("灶 ");
////////////////////////
useList.add("米");
useList.add("油");
useList.add("盐");
useList.add("酱");
useList.add("醋");
}
//确定要还是不要 1/2
private static boolean iswant()
{
int num=random.nextInt(1000);
if(num%2==0)
{
return true;
}
else
{
return false;
}
}
/**
* 表示我要几个
* @param sum
* @return
*/
private static int wantNum(int sum)
{
return random.nextInt(sum);
}
//生成300个清单文件 格式如下
//输出的文件的格式 一定要是UTF-8
//油 2
public static void main(String[] args) {
for(int i=1;i<=300;i++)
{
try {
//字节流
FileOutputStream out=new FileOutputStream(new File("E:\\tmp\\"+i+".txt")); //生成的文件存放的地址
//转换流 可以将字节流转换字符流 设定编码格式
//字符流
BufferedWriter writer=new BufferedWriter(new OutputStreamWriter(out,"UTF-8"));
//随机一下 我要不要 随机一下 要几个 再从我们的清单里面 随机拿出几个来 数量
boolean iswant1=iswant();
if(iswant1)
{
//我要几个 不能超过该类商品的总数目
int wantNum = wantNum(washList.size()+1);
//3
for(int j=0;j<wantNum;j++)
{
String product=washList.get(random.nextInt(washList.size()));
writer.write(product+"\t"+(random.nextInt(5)+1));
writer.newLine();
}
}
boolean iswant2=iswant();
if(iswant2)
{
//我要几个 不能超过该类商品的总数目
int wantNum = wantNum(bedList.size()+1);
//3
for(int j=0;j<wantNum;j++)
{
String product=bedList.get(random.nextInt(bedList.size()));
writer.write(product+"\t"+(random.nextInt(1)+1));
writer.newLine();
}
}
boolean iswant3=iswant();
if(iswant3)
{
//我要几个 不能超过该类商品的总数目
int wantNum = wantNum(homeList.size()+1);
//3
for(int j=0;j<wantNum;j++)
{
String product=homeList.get(random.nextInt(homeList.size()));
writer.write(product+"\t"+(random.nextInt(3)+1));
writer.newLine();
}
}
boolean iswant4=iswant();
if(iswant4)
{
//我要几个 不能超过该类商品的总数目
int wantNum = wantNum(kitchenList.size()+1);
//3
for(int j=0;j<wantNum;j++)
{
String product=kitchenList.get(random.nextInt(kitchenList.size()));
writer.write(product+"\t"+(random.nextInt(2)+1));
writer.newLine();
}
}
boolean iswant5=iswant();
if(iswant5)
{
//我要几个 不能超过该类商品的总数目
int wantNum = wantNum(useList.size()+1);
//3
for(int j=0;j<wantNum;j++)
{
String product=useList.get(random.nextInt(useList.size()));
writer.write(product+"\t"+(random.nextInt(6)+1));
writer.newLine();
}
}
writer.flush();
writer.close();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
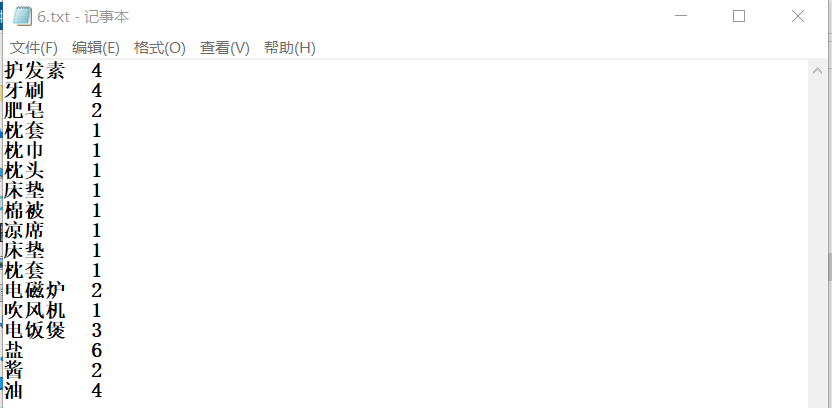
在E盘tmp目录下,其中生成的一个文本数据:
二、MapReduce去统计
1.下载Eclipse插件
链接:https://pan.baidu.com/s/18w8t45O8_XU_7ePWWsX6sw
提取码:gfei
下载完成后将插件放在Eclipse安装目录plugins下
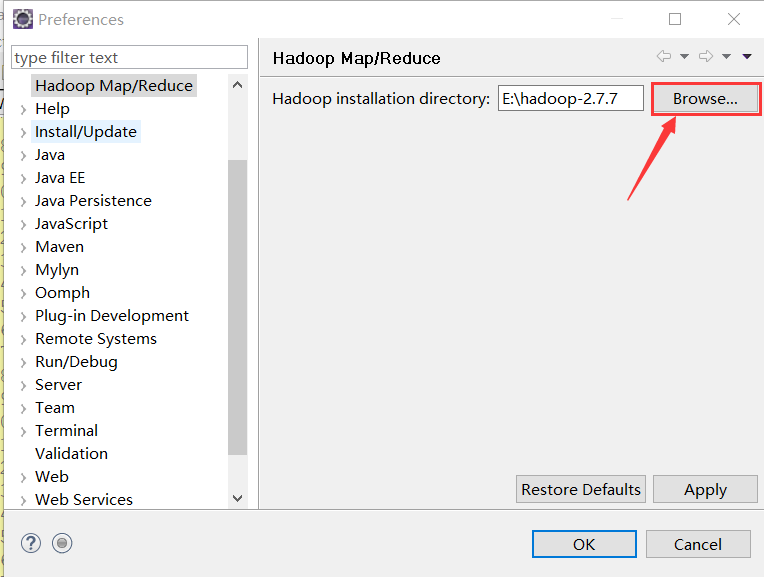
接下来重启Eclipse,点击Window->Preferences,加入hadoop安装路径
2.将Window编译后的hadoop文件放在hadoop安装目录bin目录下
Window编译后的hadoop文件链接:https://pan.baidu.com/s/1BgsCKxZyNIg2lvX4qQjPlA
提取码:mpnf
下载完成后将文件解压:

放在hadoop->bin目录下:

3.将hadoop的bin目录和sbin目录加入环境变量:


4.在hadoop根目录创建upload用来存放生成的数据文件并开放权限
hadoop fs -mkdir /upload
hadoop fs -chmod 777 /upload
5.使用Eclipse插件编写代码:
①将Eclipse视图改为项目视图:
Window->Show View
②链接hdfs

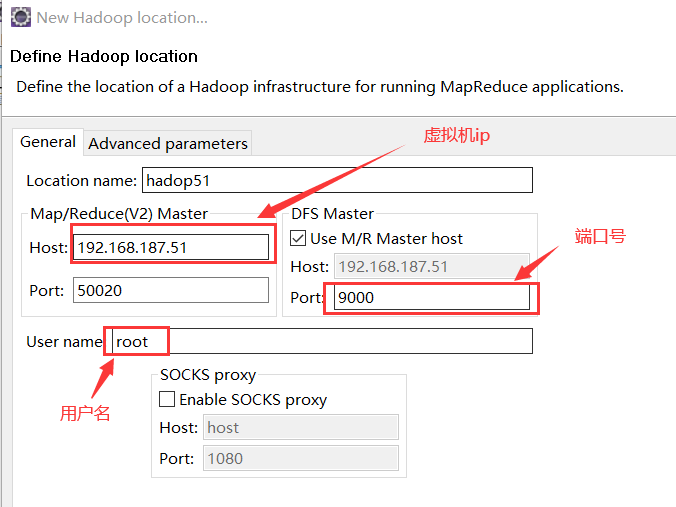
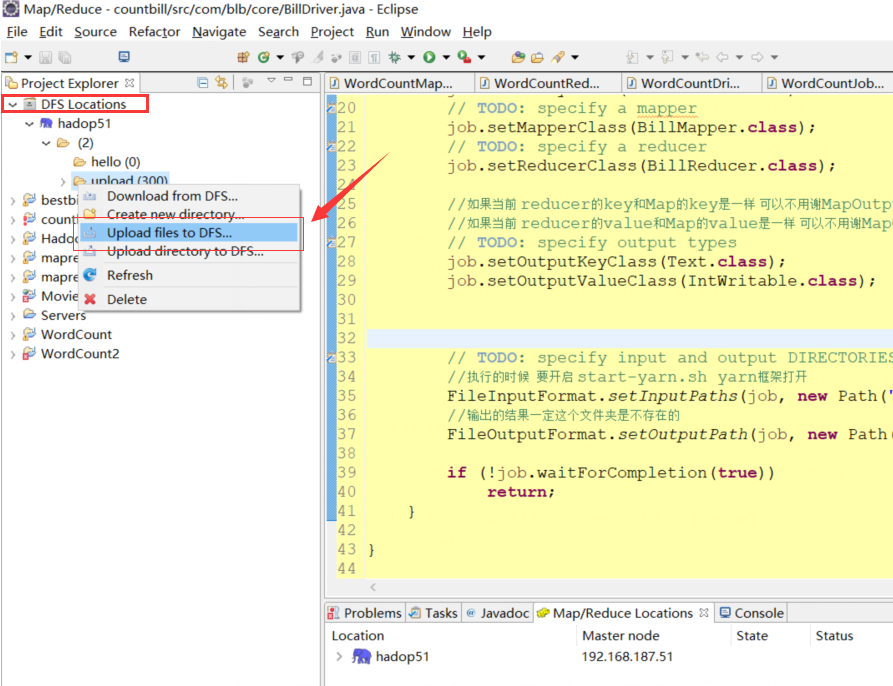
③点击完成后,将E盘tmp目录下所有文件上传到upload文件夹中:

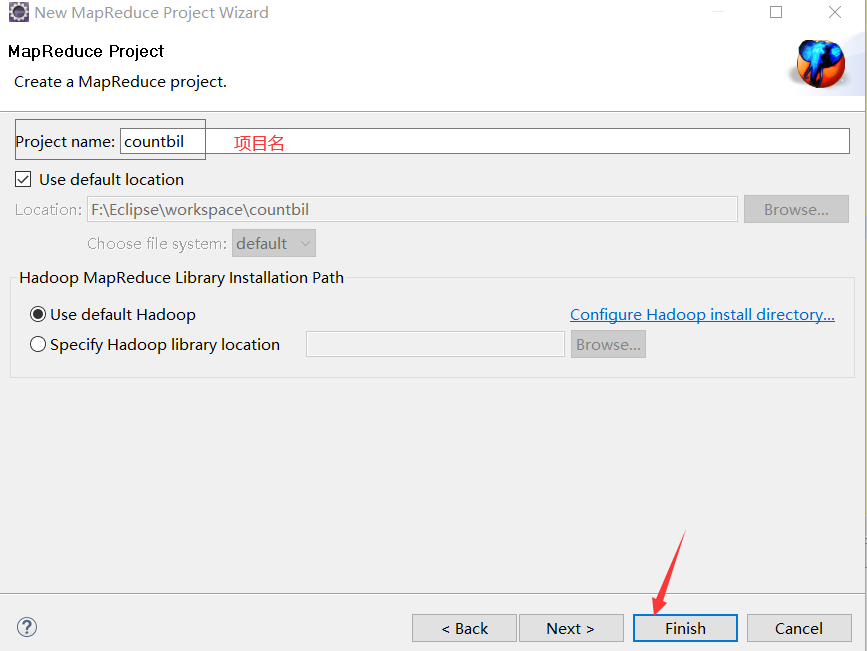
④新建一个MapReduce项目:
File->new->Project

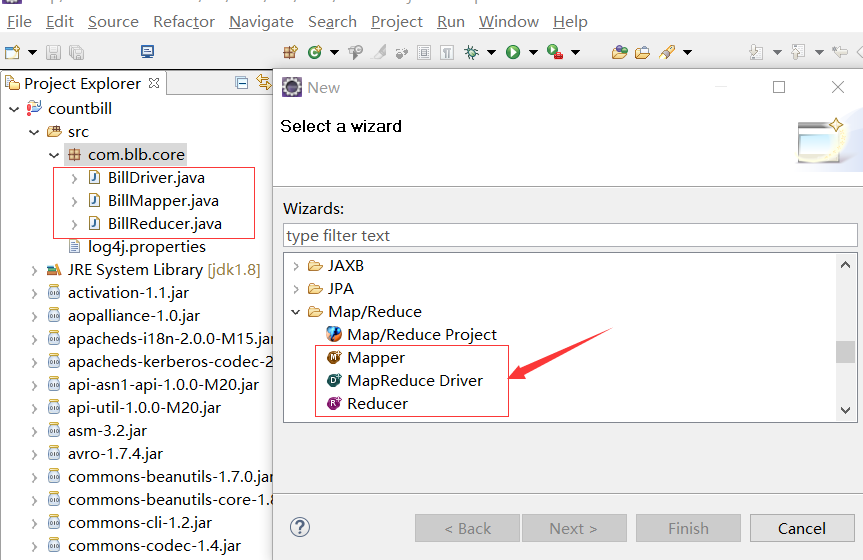
⑤分别创建Map类、Reduce类、Driver类:
Map类:
package com.blb.core;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class BillMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
public void map(LongWritable ikey, Text ivalue, Context context) throws IOException, InterruptedException {
//读取一行
String line = ivalue.toString();
String[] words=line.split("\t");
context.write(new Text(words[0]),new IntWritable(Integer.parseInt(words[1])));
}
}
Reduce类:
package com.blb.core;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class BillReducer extends Reducer<Text, IntWritable, Text,IntWritable> {
//盐 2
//油 2
//油 3
//油 [2,3]
//盐 [2]
public void reduce(Text _key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// process values
int sum=0;
for (IntWritable val : values) {
int i = val.get();
sum+=i;
}
context.write(_key,new IntWritable(sum));
}
}
Driver类:
package com.blb.core;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class BillDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.187.51:9000");
Job job = Job.getInstance(conf, "BillDriver");
job.setJarByClass(BillDriver.class);
// TODO: specify a mapper
job.setMapperClass(BillMapper.class);
// TODO: specify a reducer
job.setReducerClass(BillReducer.class);
//如果当前 reducer的key和Map的key是一样 可以不用谢MapOutputKeyClass
//如果当前 reducer的value和Map的value是一样 可以不用谢MapOutputValueClass
// TODO: specify output types
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// TODO: specify input and output DIRECTORIES (not files)
//执行的时候 要开启 start-yarn.sh yarn框架打开
FileInputFormat.setInputPaths(job, new Path("/upload"));
//输出的结果一定这个文件夹是不存在的
FileOutputFormat.setOutputPath(job, new Path("/out2/"));
if (!job.waitForCompletion(true))
return;
}
}
⑥加入日志方便我们查看运行情况:
在src目录中新建一个名为log4j.properties的日志文件,内容如下:
### \u8BBE\u7F6E###
log4j.rootLogger = debug,stdout
### \u8F93\u51FA\u4FE1\u606F\u5230\u63A7\u5236\u62AC ###
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = [%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n
三.运行
在driver类右键点击运行Run on Hadoop
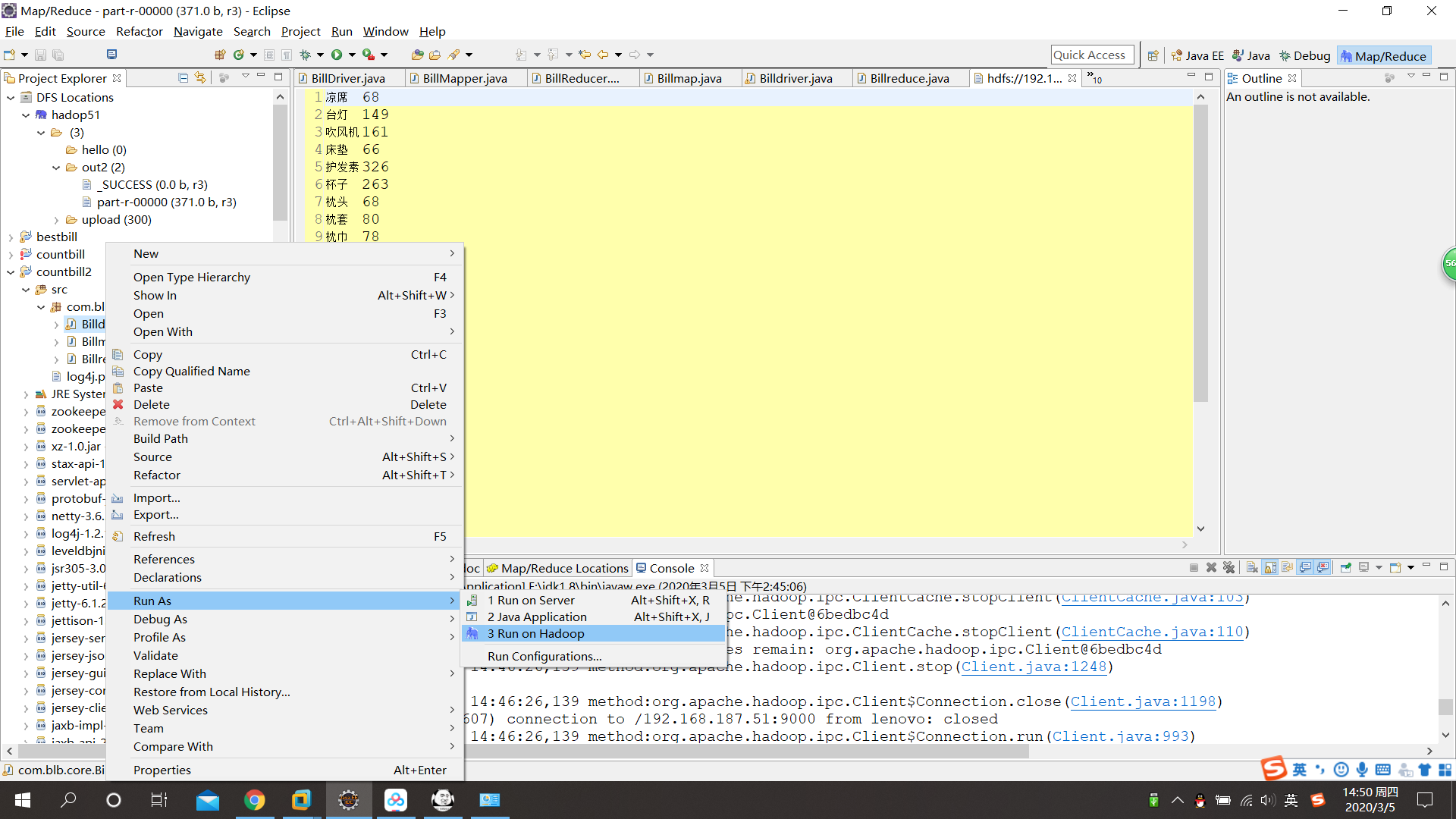
运行完毕后再out2目录中可以看到最终计算结果:

在本次运行成功之前,我出现了权限被拒绝的问题,用了很粗鲁的办法:hadoop fs -chmod 777 / 去解决的.....

 浙公网安备 33010602011771号
浙公网安备 33010602011771号