elasticsearch自动补全详解

一、参考
二、基本介绍
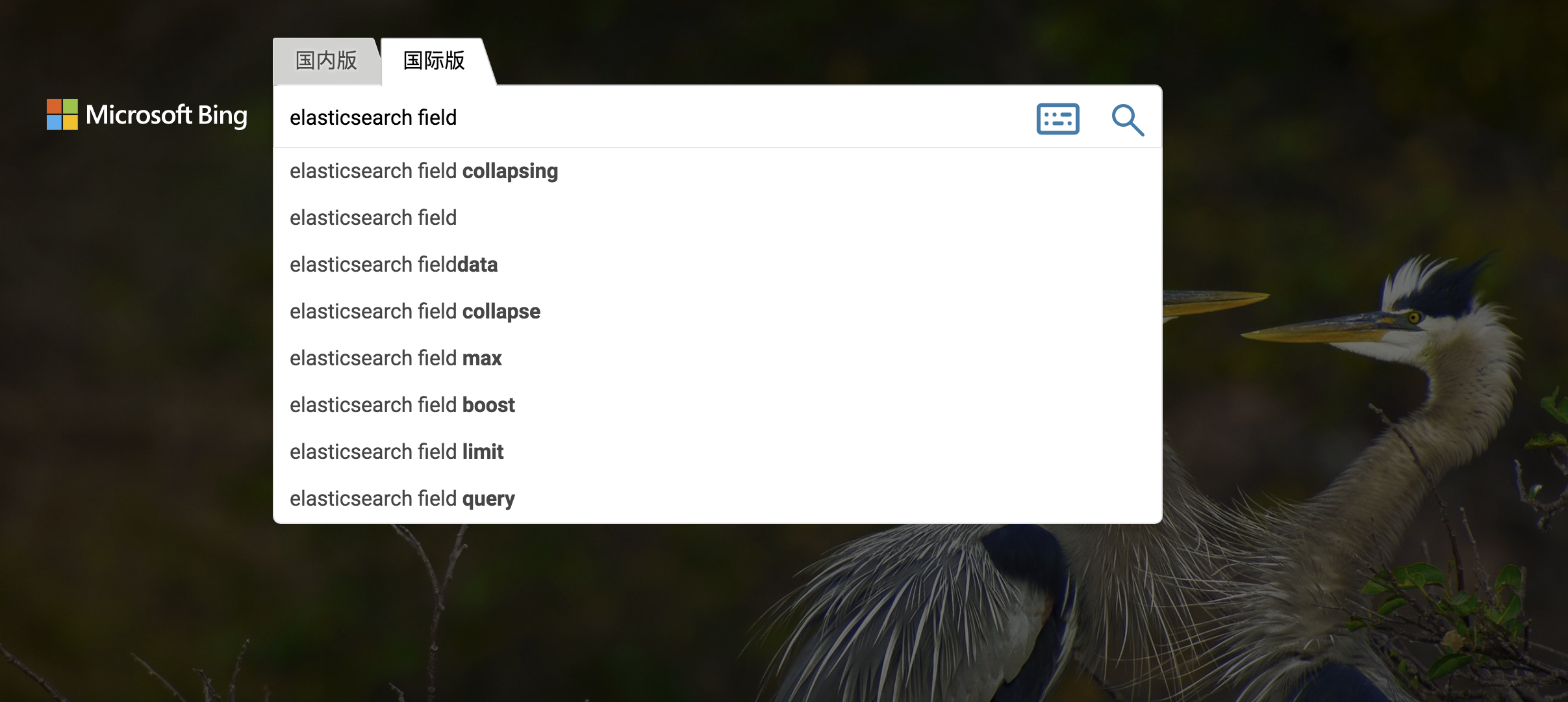
2.1 bing 示例
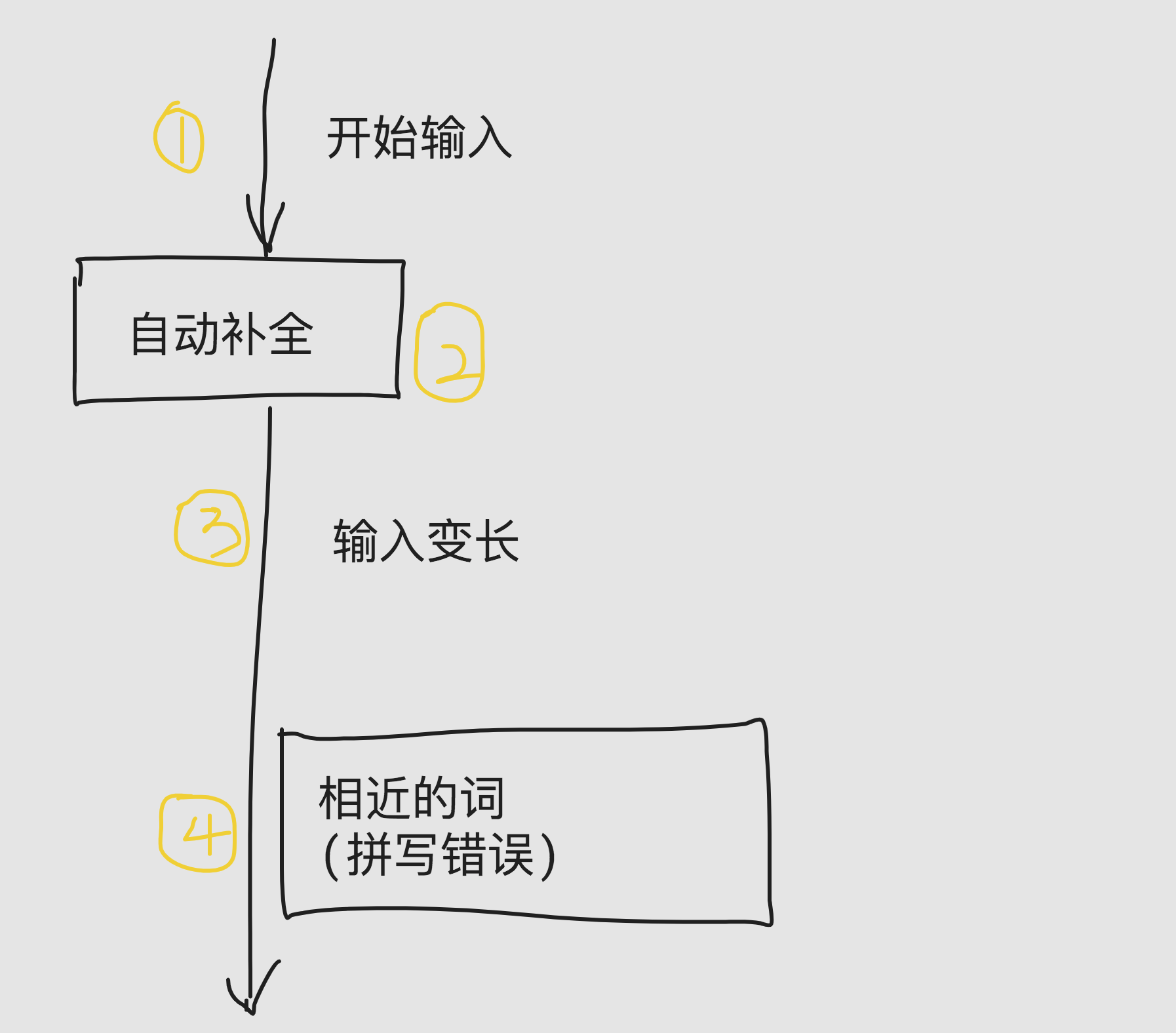
2.2 suggest 过程
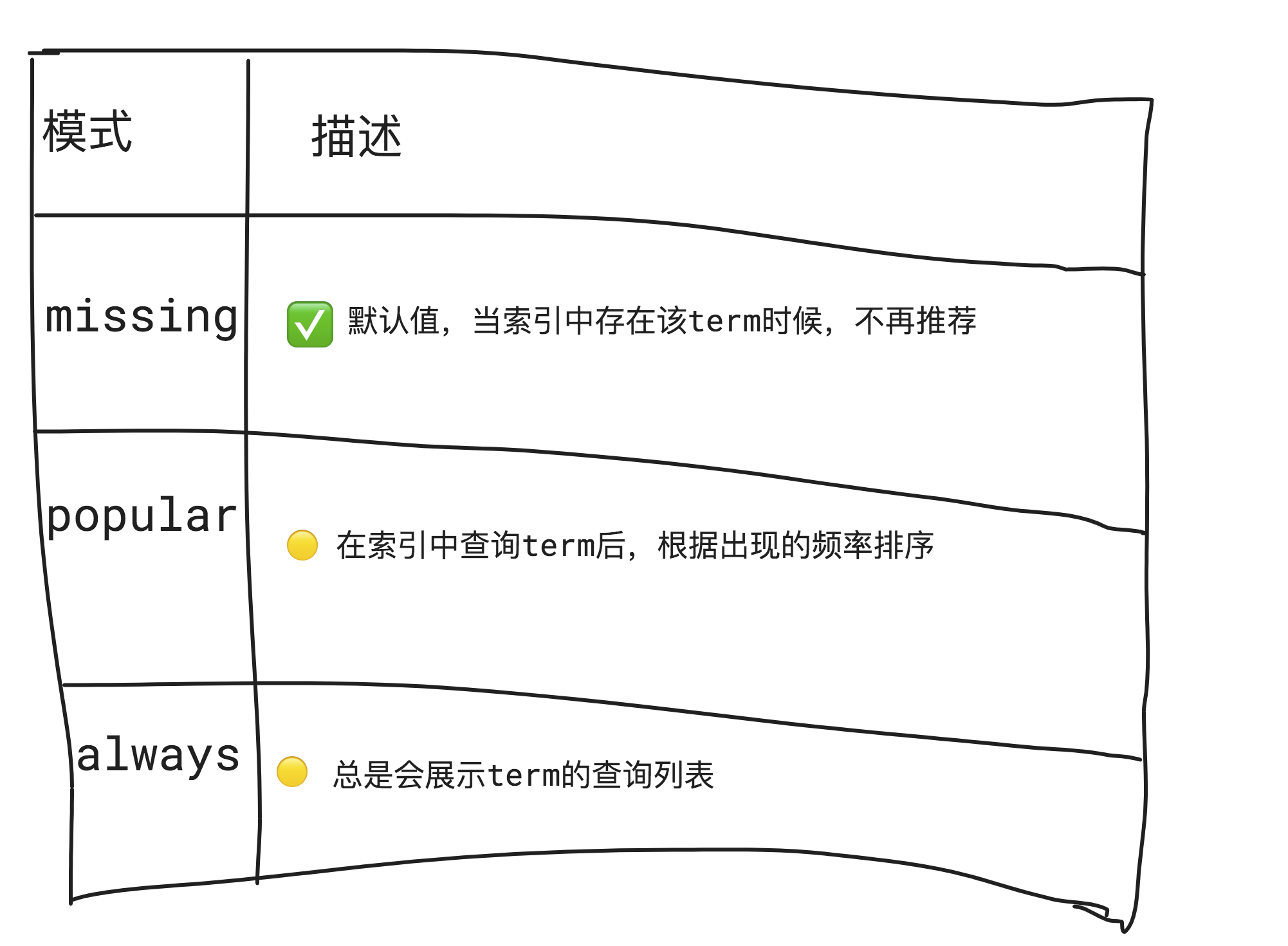
三、ES 的 suggester
3.1 实现原理
将输入的文本分解为token, 然后在索引的字典中查找相似的 term 并且返回
3.2 4 种 suggester
(1) term suggester
(2) phrase suggester
(3) completion suggester
(4) context suggester
四、term suggester
(1) 创建索引,写入文档
# 创建索引
PUT yztest/
{
"mappings": {
"properties": {
"message": {
"type": "text"
}
}
}
}
# 添加文档1
POST yztest/_doc/1
{
"message": "The goal of Apache Lucene is to provide world class search capabilities"
}
# 添加文档2
POST yztest/_doc/2
{
"message": "Lucene is the search core of both Apache Solr and Elasticsearch."
}
(2) 查看分词 token
# 分析分词器结果
GET yztest/_analyze
{
"field": "message",
"text": [
"The goal of Apache Lucene is to provide world class search capabilities",
"Lucene is the search core of both Apache Solr and Elasticsearch."
]
}
(3) 不同的查询结果
a) 当输入单词拼写错误时候,会推荐正确的拼写单词列表
# 查询
POST yztest/_search
{
"suggest": {
"suggest_message": { # 自定义的suggester名称
"text": "lucenl", # 查询的字符串,即用户输入的内容
"term": { # suggester类型为term suggester
"field": "message", # 待匹配字段
"suggest_mode": "missing" # 推荐结果模式,missing表示如果存在了term和用户输入的文本相同,则不再推荐
}
}
}
}
# 返回结果
{
"took" : 7,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"suggest" : {
"suggest_message" : [
{
"text" : "lucenl",
"offset" : 0,
"length" : 6,
"options" : [ # options为一个数组,里面的值为具体的推荐值
{
"text" : "lucene",
"score" : 0.8333333,
"freq" : 2
}
]
}
]
}
}
b) 当输入为多个单词组成的字符串时
# 查询
POST yztest/_search
{
"suggest": {
"suggest_message": {
"text": "lucene search",
"term": {
"field": "message",
"suggest_mode": "always"
}
}
}
}
# 查询结果
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"suggest" : {
"suggest_message" : [
{
"text" : "lucene",
"offset" : 0,
"length" : 6,
"options" : [ ]
},
{
"text" : "search",
"offset" : 7,
"length" : 6,
"options" : [ ]
}
]
}
}
五、phrase suggester
# 词组查询
POST yztest/_search
{
"suggest": {
"YOUR_SUGGESTION": {
"text": "Solr and Elasticearc", # 用户输入的字符串
"phrase": { # 指定suggest类型为phrase suggester
"field": "message", # 待匹配的字段
"highlight": { # 可以设置高亮
"pre_tag": "<em>",
"post_tag": "</em>"
}
}
}
}
}
# 返回结果
{
"took" : 9,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"suggest" : {
"YOUR_SUGGESTION" : [
{
"text" : "Solr and Elasticearc",
"offset" : 0,
"length" : 20,
"options" : [
{
"text" : "solr and elasticsearch",
"highlighted" : "solr and <em>elasticsearch</em>", # 高亮部分
"score" : 0.017689342
}
]
}
]
}
}

六、completion suggester
自动补全功能
6.1 创建 mapping 指定 suggest 字段
# 创建索引
PUT yztest/
{
"mappings": {
"properties": {
"message": { # 通过字段的type,指定是否使用suggest
"type": "completion"
}
}
}
}
6.2 查询
(1) 索引文档
POST yztest/_doc/1
{
"message": "The goal of Apache Lucene is to provide world class search capabilities"
}
POST yztest/_doc/2
{
"message": "Lucene is the search core of both Apache Solr and Elasticsearch."
}
POST yztest/_doc/3
{
"message": "Lucene is the search core of Elasticsearch."
}
POST yztest/_doc/4
{
"message": "Lucene is the search core of Apache Solr."
}
(2) 前缀查询
# 查询
POST yztest/_search
{
"suggest": {
"message_suggest": { # 自定义suggester名称
"prefix": "lucene is the", # 前缀字符串,即用户输入的文本
"completion": { # 指定suggester的类型为 completion suggester
"field": "message" # 待匹配的字段
}
}
}
}
# 查询结果
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"suggest" : {
"message_suggest" : [
{
"text" : "lucene is the",
"offset" : 0,
"length" : 13,
"options" : [
{
"text" : "Lucene is the search core of Apache Solr.",
"_index" : "yztest",
"_type" : "_doc",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"message" : "Lucene is the search core of Apache Solr."
}
},
{
"text" : "Lucene is the search core of Elasticsearch.",
"_index" : "yztest",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"message" : "Lucene is the search core of Elasticsearch."
}
},
{
"text" : "Lucene is the search core of both Apache Solr and ",
"_index" : "yztest",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"message" : "Lucene is the search core of both Apache Solr and Elasticsearch."
}
}
]
}
]
}
}
(3) skip_duplicates
删除重复匹配文档
# 查询中指定skip_duplicates, 默认值为false
POST yztest/_search
{
"suggest": {
"message_suggest": {
"prefix": "lucene is the",
"completion": {
"field": "message",
"skip_duplicates": true
}
}
}
}
(4) fuzzy query
# 查询中指定fuzzy属性,即不一定是prefix准确查询
POST yztest/_search
{
"suggest": {
"message_suggest": {
"prefix": "lucen is the",
"completion": {
"field": "message",
"fuzzy": {
"fuzziness": 2
}
}
}
}
}
(5) regex 查询,正则匹配
# 正则匹配
POST yztest/_search
{
"suggest": {
"message_suggest": {
"regex": ".*solr.*", # 正则表达式
"completion": {
"field": "message"
}
}
}
}
七、context suggester
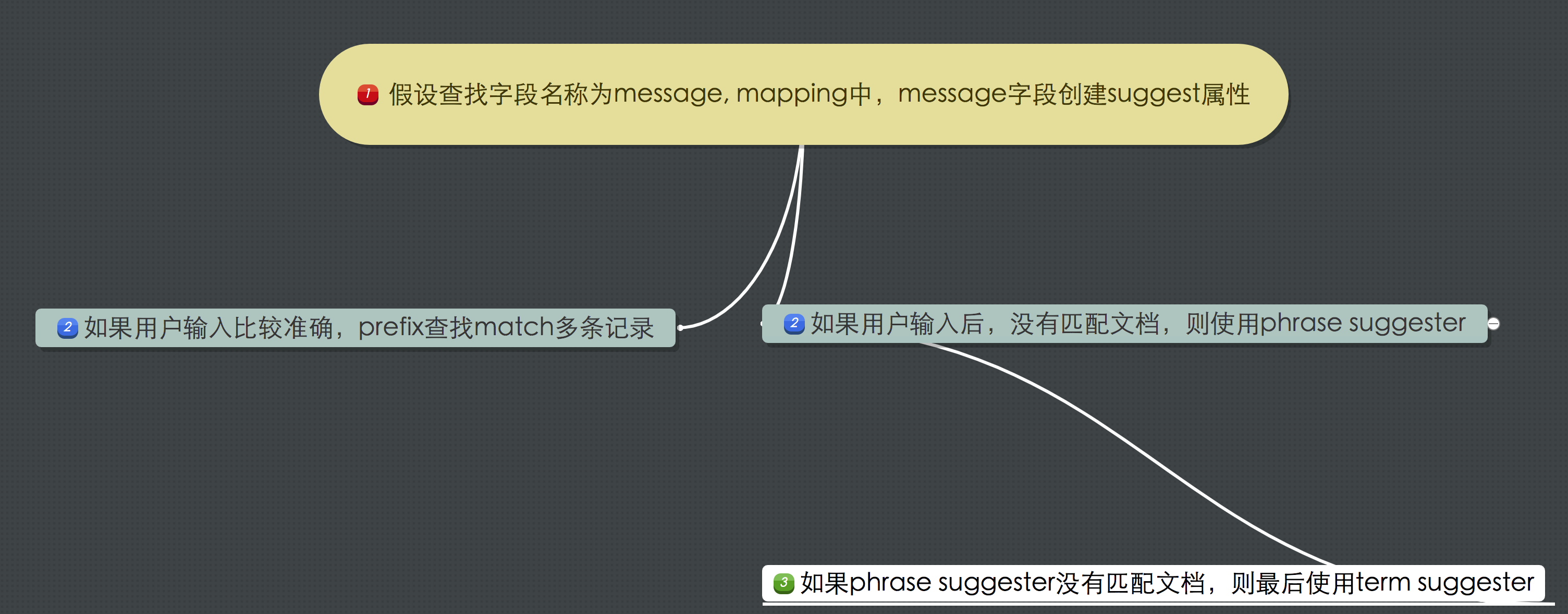
八、如何实现?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号