编译原理前端技术

一、参考
二、编译过程

编译器的“前端”技术分为词法分析、语法分析和语义分析三个部分
主要涉及自动机和形式语言方面的基础的计算理论
三、词法分析 Lexical Analysis
3.1 token
编译器的第一项工作叫做词法分析
文章是由一个个的中文单词组成的, 程序处理也一样,只不过这里不叫单词,而是叫做“词法记号”,英文叫 Token
如何写一个程序来识别 Token 呢?
可以通过制定一些规则来区分每个不同的 Token
这些规则可以通过手写程序来实现
如果嫌手写麻烦, 用词法分析器的生成工具来生成,比如 Lex(或其 GNU 版本,Flex)
3.2 词法分析器生成工具
“正则文法(Regular Grammar)
“有限自动机(Finite-state Automaton,FSA,or Finite Automaton)”
词法分析器生成工具是基于一些规则来工作的,
这些规则用“正则文法”表达,符合正则文法的表达式称为“正则表达式”
生成工具可以读入正则表达式,生成一种叫“有限自动机”的算法,来完成具体的词法分析工作。
词法分析器也是一样,它分析整个程序的字符串,当遇到不同的字符时,会驱使它迁移到不同的状态。
3.3 示例
词法分析程序在扫描 age 的时候,处于“标识符”状态,等它遇到一个 > 符号,就切换到“比较操作符”的状态。词法分析过程,就是这样一个个状态迁移的过程。

你也许熟悉正则表达式,因为我们在编程过程中经常用正则表达式来做用户输入的校验,例如是否输入了一个正确的电子邮件地址,这其实就是在做词法分析
3.4 小节
词法分析是把程序分割成一个个 Token 的过程,可以通过构造有限自动机来实现
四、语法分析
4.1 AST
抽象语法树(Abstract Syntax Tree,AST)
词法分析是识别一个个的单词,而语法分析就是在词法分析的基础上识别出程序的语法结构
这个结构是一个树状结构,是计算机容易理解和执行的。
程序也有定义良好的语法结构,它的语法分析过程,就是构造这么一棵树。一个程序就是一棵树,这棵树叫做抽象语法树(Abstract Syntax Tree,AST)
树的每个节点(子树)是一个语法单元,这个单元的构成规则就叫“语法”。每个节点还可以有下级节点
层层嵌套的树状结构,是我们对计算机程序的直观理解。计算机语言总是一个结构套着另一个结构,大的程序套着子程序,子程序又可以包含子程序
4.2 构造 AST
(1) 递归下降算法(Recursive Descent Parsing)
一种非常直观的构造思路是自上而下进行分析
首先构造根节点,代表整个程序,之后向下扫描 Token 串,构建它的子节点
一棵子树就扫描完毕了。程序退回到根节点,开始构建根节点的第二个子节点。这样递归地扫描,直到构建起一棵完整的树
这个算法就是非常常用的递归下降算法(Recursive Descent Parsing)
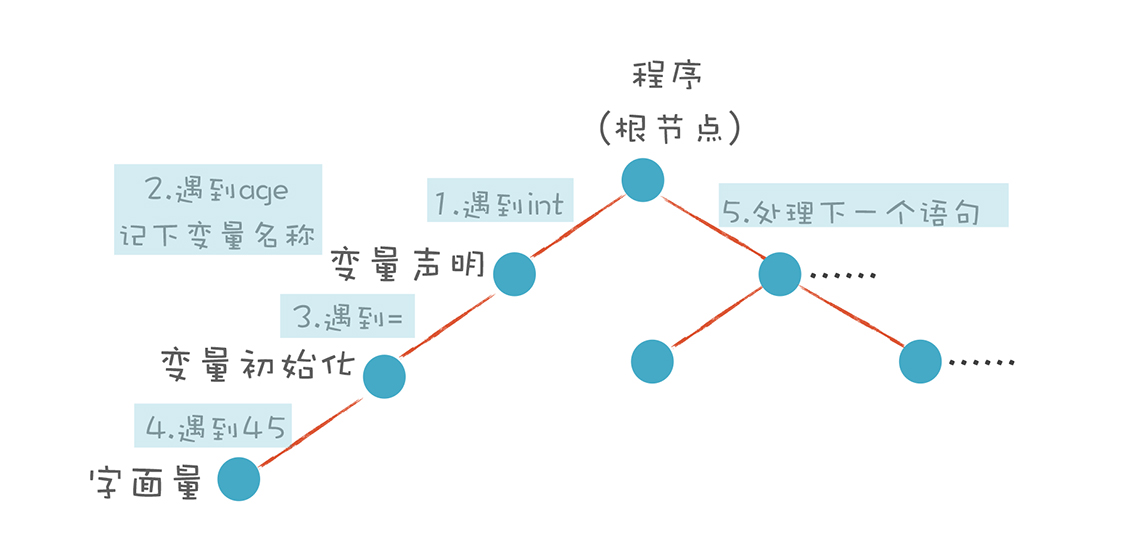
(2) 自底向上的算法。这个算法会先将最下面的叶子节点识别出来,然后再组装上一级节点。有点儿像搭积木,我们总是先构造出小的单元,然后再组装成更大的单元
除了手写,有没有偷懒的、更省事的方法呢?
4.3 Yacc
4.4 小节
语法分析是把程序的结构识别出来,并形成一棵便于由计算机处理的抽象语法树。可以用递归下降的算法来实现
五、语义分析 Semantic Analysis
5.1 概要
语义分析就是要让计算机理解我们的真实意图,把一些模棱两可的地方消除掉
你可能会觉得理解自然语言的含义已经很难了,所以计算机语言的语义分析也一定很难。其实语义分析没那么复杂,
因为计算机语言的语义一般可以表达为一些规则,你只要检查是否符合这些规则就行了
语义分析工作的某些成果,会作为属性标注在抽象语法树上,比如在 age 这个标识符节点和 45 这个字面量节点上,都会标识它的数据类型是 int 型的
在这个树上还可以标记很多属性,有些属性是在之前的两个阶段就被标注上了,比如所处的源代码行号,这一行的第几个字符。
做了这些属性标注以后,编译器在后面就可以依据这些信息生成目标代码了
5.2 小节
语义分析是消除语义模糊,生成一些属性信息,让计算机能够依据这些信息生成目标代码

 浙公网安备 33010602011771号
浙公网安备 33010602011771号