读书笔记:《大型网站系统与Java中间件实践》
文章目录
大型网站演进
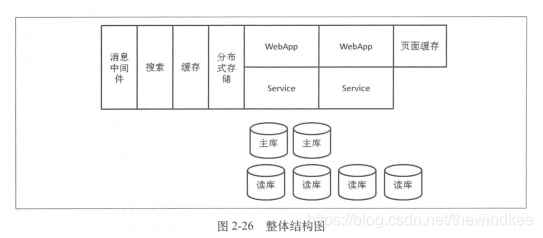
- 单机扛不住 , 上集群
- 集群session问题
1.hash(key)到固定的单机节点上,让其保持session
如果一台web服务器故障,则会话丢失。需要登录。
2.session复制
将session复制到其他节点上。
a.同步session增加网络带宽。
b.增加内存消耗。
3.session集中存储
redis存储。
好处:web之间没了session复制,也不保存在本机了。
坏处:
a.读写session引入了网络操作。
不过一般是Redis在内网, 还好。
b.存储session的机器有问题,则影响应用。
4.Cookie Based
相当于每次 都自带碗筷。
a.cookie长度。
b.安全性。
不能信赖前端传来的数据,所以有加密解密。但是仍不安全。
c.带宽消耗。
数据库
读问题
数据库压力变大,读写分离
1.数据库作为读库
2.搜索引擎作为读库
加速数据读取–缓存
1.数据缓存
2.页面缓存
考虑局部热点的问题。
扩容/缩容尽量平滑(一致性hash)
定时失效、变更时失效、变更时更新
写问题
读写分离不能解决写(主库)问题
1.专库专用,数据库垂直拆分
交易、商品、用户数据分开。
问题:引入了 分布式事务的问题。
2.水平拆分
数据水平拆分就是把同一个表的数据,拆分到多个数据库/表。
问题:
a.访问数据 引入路由(到不同库/表)
b.主键处理,不能简单自增。
c.分页出现问题。
应用应对的挑战
跟数据库拆分类似
a.从业务垂直拆分
订单、物流、商品、用户
b.也可以水平扩容
多台订单机器构建集群,抗下单压力
引入服务层(service)
引入消息中间件
引入服务层框架:
问题:网站规模扩大,开发人员增多,应用复杂、臃肿。
解决方案:应用拆小。
仍存在的问题:
数据库连接数压力还在。
系统之间存在重复代码。
引入服务层:应用存在的问题 ,就继续抽象一层。
将应用和底层数据库、缓存系统、文件系统等系统之间增加了服务层。可以理解成服务层处理简单、通用逻辑,并持久化到文件、数据库中。
服务层的代表:dubbo
应用直接调用有网络。
利用动态代理+反射生成代理对象,帮助序列化,网络发送数据调用远程应用,并反序列化结果。隐藏细节。
问题:
服务者集群、调用者集群,如何路由。
最初的路由寻址–找服务提供者
1.透明代理:lvs,eureka
2.从注册中心找地址,再直连
基于服务提供者、接口、方法、参数来路由
避免负载不均衡。
多机房问题
其他机房也被当做同一集群
解决:
1.根据调用者提供不同的服务者。
2.框架内部进行地址过滤,识别机房。
序列化与反序列化问题
尽量短小(节省带宽)
压缩与短小之间的平衡(cpu,网络)
异步调用
1.拆分没有前后依赖的服务,多线程异步调用。
2.不需要结果的,异步调用。
3.批量调用(类似mget)
4.fork/join
线程池隔离
避免某个接口阻塞后,影响应用内其他接口。
服务请求合并
服务提供者避免重复计算。
计算的时候加锁,其他线程再次访问则得到一个Future供之后获取结果。
数据访问层
数据拆分带来的影响:
ACID
路由
join
分页
自增ID
查询跨库
一致性的基础理论–CAP/BASE
希望强一致,但是代价太大,最终一致就好了。
p:分区容忍性,系统部分有问题仍能运行。
放弃C,保留AP。最终一致。
如果强一致,单机。
或者类似于ZK写入的时候,只要一半及以上同意就算写入成功。
类似于MongoDB写入的时候,一半及以上replication接收即可。
集群内数据一致性算法
W+R>N 能保证强一致性
W+R<=N可以保证最终一致性
分布式事务,考虑最终一致即可。
实现上来说通过补偿不断重试,而不是回滚。
或者TCC 应用层自行做抵消操作。
两者可以合并
TCC+人工补偿
多机的Sequence问题
水平分库后,自增ID还是要保证:
唯一性
连续性
唯一性:
uuid
连续性:
1.单独做一个id自增的管理器。
性能降低。
需要灾备保证稳定。
2.应用指定ID段
扩库join
1.多次查询。
2.数据冗余到单表上,避免join.
排序后分页
1.考虑到所有数据可能都来自 一个数据源,所以分页的时候在一个源中取足(size条)数据。
2.将所有数据源的数据组合排序,再取前size条。
消息中间件
功能
削峰削谷:
平滑处理消息。
异步:
快速返回。
解耦:
应用直接没有直接联系,方便接入
消息一致性
jms通过XA解决
分阶段-多次消息投递
业务先发送到消息中间件标记为待处理。
之后处理完业务后再发送到消息中间件,标记为成功。(消息投递)
不断补偿-最终一致
避免对消息中间件的强依赖
避免消息中间件挂掉后影响业务:
1.业务应用 将操作和需要入队的消息 作为一个事务,保证消息写到【本地消息表】中。–一个事务保证完成。
2. 消息中间件/应用 轮询 本地消息表去获取消息,投递到消息中间件中即可。–最终可靠
级联、嵌套topic/queue
消息发送到中间件的可靠性保证(发送可靠)
持久订阅、非持久订阅
消息中间件返回成功才认为 可靠消息到达中间件了,否则重发。
消息持久化到数据库、文件。
消息投递的可靠性保证(消费可靠)
得到消息,并处理成功才向 消息中间件 返回成功
业务没处理完不能去确认消息(ack)
可能业务处理成功,但ack发送失败,导致以为失败
业务继续补偿,但是幂等。直接ack,删除消息中间件的消息。
消息者重复消费
1.重复发送到消息中心。
消息标记ID,同一ID无法重复发送。
2.应用端重复接收消息中心的消息。
应用端进行幂等操作。
避免投递线程被阻塞
1.接受消息与处理消息分开。(类似于select+handler的boss线程与worker线程)
2.线程池。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号