
Hadoop之Hive架构与设计
Hadoop之Hive架构与设计
Hadoop是一个能够对大量数据进行分布式处理的软件框架。具有可靠、高效、可伸缩的特点。
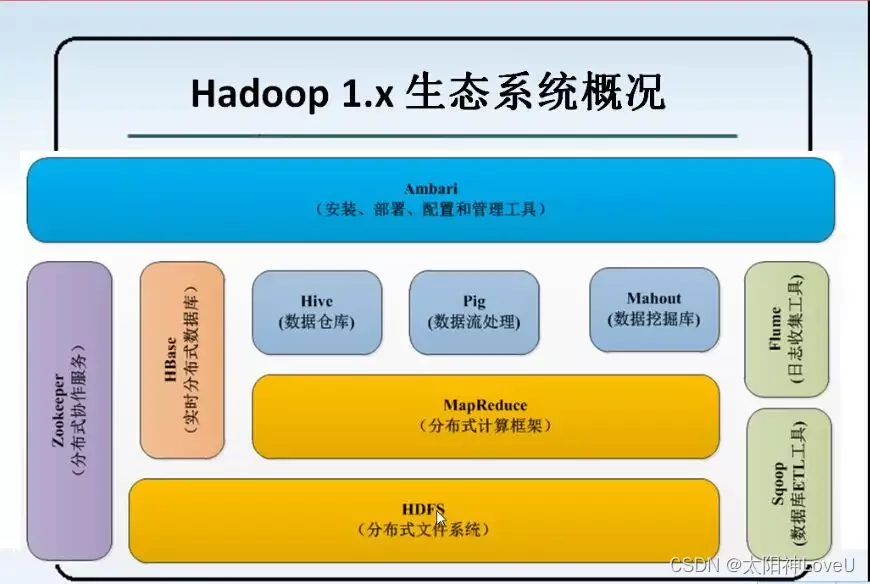
-
HDFS:全称为Hadoop分布式文件系统(Hadoop Distributed File System),提供了高吞吐量的访问应用程序数据。
-
Hadoop YARN:Hadoop集群资源管理框架(Yet Another Resource Negotiator),用于作业调度和集群资源管理。
-
Hadoop MapReduce:基于YARN的大数据集的并行处理系统。
-
Hadoop Common:支持其他Hadoop模块的通用功能,包括序列化、Java RPC和持久化数据结构等。
-
Ambari:是一个部署、管理和监视Apache Hadoop集群的开源框架。
-
Hbase:可扩展的分布式列式数据库,支持大表的结构化存储。
-
Hive:分布式数据仓库系统,提供基于类SQL的查询语言。
-
Mathout:机器学习和数据挖掘领域经典算法的实现。
-
Pig:一个高级数据流语言和执行环境,用来检索海量数据集。
-
Spark:一个快速和通用的计算引擎。Spark提供了一个简单而富有表现力的编程模型,支持多种应用,包括ETL、机器学习、数据流处理和图形计算。
-
Sqoop:在关系型数据库与Hadoop系统之间进行数据传输的工具。
-
Tez:是从MapReduce计算框架演化而来的通用DAG计算框架,可作为MapReduce/Pig/Hive等系统的底层数据处理引擎,它天生融入Hadoop2.0的资源管理平台YARN。
-
Zookeeper:提供Hadoop集群高性能的分布式的协调服务。
以下就Hive展开进行详解。
一、Hive简介
Hive是Apache Hadoop的正式子项目,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Hive是建立在Hadoop上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以在Hadoop中对大规模数据进行存储、查询和分析的机制。Hive定义了简单的类SQL查询语言,称为HQL,它允许熟悉SQL的用户方便地查询数据。同时,这个语言也允许熟悉MapReduce的开发者定制自定义的Mapper和Reducer,以便处理内建Mapper/Reducer无法完成的复杂分析工作。
二、Hive体系架构
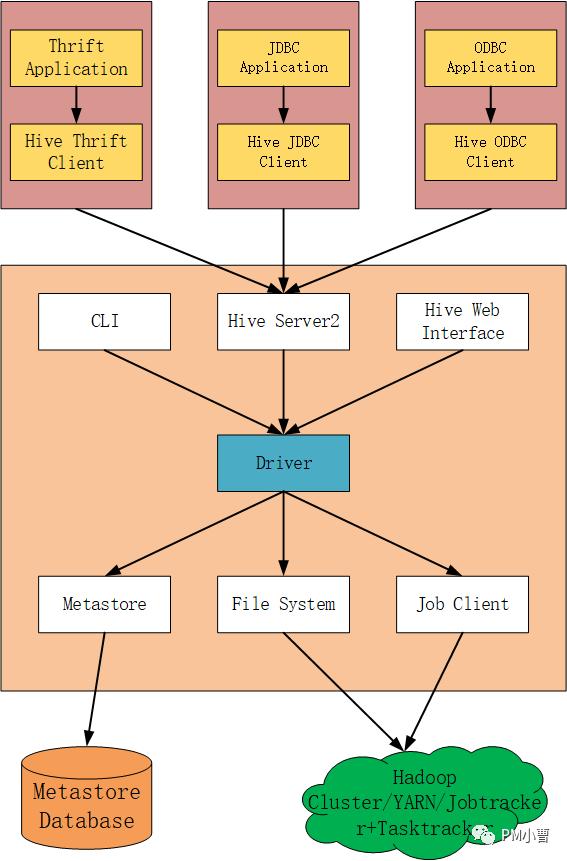
Hive系统总体上分为以下几个部分。
UI:用户提交查询请求与获得查询结果。其包括三个接口:命令行(CLI)、Web GUI和客户端;
Driver:接受查询请求,经过处理后返回查询结果。核心组件,整个Hive的核心,该组件包括Complier(编译器)、Optimizer(优化器)和Executor(执行器),它们的作用是对Hive SQL语句进行解析、编译优化,生成执行计划,然后调用底层的MapReduce计算框架;
Compiler:编译器,分析查询SQL语句,在不同的查询块和查询表达式上进行语义分析,并最终通过从Metastore中查找表与分区的元信息生成执行计划;
Execution Engine:执行引擎,执行由Compiler创建的执行计划,执行引擎管理不同阶段的依赖关系,通过MapReuce执行这些阶段;
Metastore:元数据储存,元数据存储在MySQL或derby等数据库中。元数据包括Hive各种表与分区的结构化信息,列与列类型信息,序列化器与反序列化器等,从而能够读写HDFS中的数据。
三、Hive数据模型
Hive的数据模型包括database、table、partition和bucket。
(1)Database:相当于关系数据库里的命名空间(NameSpace),它的作用是将用户和数据库的应用隔离到不同的数据库或模式中,Hive提供了createdatabase dbname、use dbname以及drop database dbname这样的语句。
(2)表(table):Hive的表逻辑上由存储的数据和描述表格中的数据形式的相关元数据组成。表存储的数据存放在分布式文件系统里,例如HDFS,元数据存储在关系数据库里,当我们创建一张Hive的表,还没有为表加载数据的时候,该表在分布式文件系统,例如HDFS上就是一个文件夹(文件目录)。Hive里的表有两种类型,一种叫托管表,这种表的数据文件存储在Hive的数据仓库里;一种叫外部表,这种表的数据文件可以存放在Hive数据仓库外部的分布式文件系统上,也可以放到Hive数据仓库里(注意:Hive的数据仓库就是hdfs上的一个目录,这个目录是Hive数据文件存储的默认路径,它可以在Hive的配置文件里进行配置,最终也会存放到元数据库里)。
(3)桶(bucket):分桶是将数据集分解成更容易管理的若干部分的另一个技术,上面的table和partition都是目录级别的拆分数据,bucket则是对数据源数据文件本身来拆分数据。使用桶的表会将源数据文件按一定规律拆分成多个文件。
四、Hive优缺点
-
优点
-
操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)。
-
避免了去写MapReduce,减少开发人员的学习成本。
-
Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合。
-
Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。
-
Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
-
缺点
-
Hive的HQL表达能力有限
(1)迭代式算法无法表达,表达能力有限(复杂的逻辑算法不好封装)
(2)数据挖掘方面不擅长,由于MapReduce数据处理流程的限制(比较慢,因为底层的缺点也都还在),效率更高的算法却无法实现。 -
Hive的效率比较低
(1)Hive自动生成的MapReduce作业,通常情况下不够智能化(机器翻译比较死板,可能不是最优解,但是一定可以实现)
(2)Hive调优比较困难,粒度较粗(只能在框架的基础上优化,不能深入底层MR程序优化)
五、Hive应用场景
Hive提供数据提取、转换、加载功能,并可用类似于SQL的语法,对HDFS海量数据库中的数据进行查询、统计等操作。形象地说,Hive更像一个数据仓库管理工具,适用于结构化数据的应用,读多写少的应用,响应时间要求不高的场合。Hive常用于以下几个方面:
(1)数据汇总(每天/每周用户点击数,点击排行);
(2)非实时分析(日志分析,统计分析);
(3)数据挖掘(用户行为分析,兴趣分区,区域展示)。

