
消息队列MQ和Kafka庖丁解牛实践教学
先来一道开胃菜:阿里技术官整合的四大主流中间件
话不多说,今天对不同的MQ做个庖丁解牛,并带领大家深度部署应用实践一番:(部分图文素材来自互联网,版权归原作者所有)
几种常用的MQ(RabbitMQ、RocketMQ、ActiveMQ、Kafka)优缺点对比分析
RabbitMQ:
优点:轻量,迅捷,容易部署和使用,拥有灵活的路由配置
缺点:性能和吞吐量较差,不易进行二次开发
RocketMQ:
优点:性能好,稳定可靠,有活跃的中文社区,特点响应快
缺点:兼容性较差,但随意影响力的扩大,该问题会有改善
ActiveMQ:
目前,消息队列在各大互联网平台,尤其是电商平台如京东、淘宝、去哪儿等网站有着深入的应用,主要作用是高并发访问高峰,通过异步消息模式减少网站响应时间,提高系统吞吐量。ActiveMQ作为众多MQ中的一员,而且也是最老牌的一员,有其优势:1)多编程语言多协议支持。2)完全支持JMS1.1和J2EE 1.4规范 3)对Spring的支持,ActiveMQ可以很容易内嵌到使用Spring的系统里面去 4)从设计上保证了高性能的集群。
Kafka:
优点:拥有强大的性能及吞吐量,兼容性很好
缺点:由于“攒一波再处理”导致延迟比较高,有可能消息重复消费
作为一个有着丰富经验的微服务架构师,经常有人问我:“应该选择 MQ 还是 Kafka ?”。基于某些原因,许多开发者会把这两种技术当作等价的来看待。的确,有些案例场景下选择 RabbitMQ 还是 Kafka 没什么差别,但是这两种技术在底层实现方面是有许多差异的。不同场景需要不同的解决方案,选错一个方案能够严重的影响你对软件的设计,开发和维护的能力。
小编这期的专题总结市面上不常见到的技术点拉满的四大主流消息中间件学习笔记,归类整理了MQ(
ActiveMQ/RabbitMQ/RocketMQ)+Kafka等的纯手写的实战+原理整合笔记,有需要的同学文末自取!
第一份资料:Kafka实战笔记
关于这四份消息中间件笔记,我只能在文章中展示部分的章节内容和核心截图,如果你有需要完整版源码+笔记的朋友,可以帮忙三连支持一下,点击下方传送门即可入手~

- Kafka入门
- 为什么选择Kafka
- Karka的安装、管理和配置
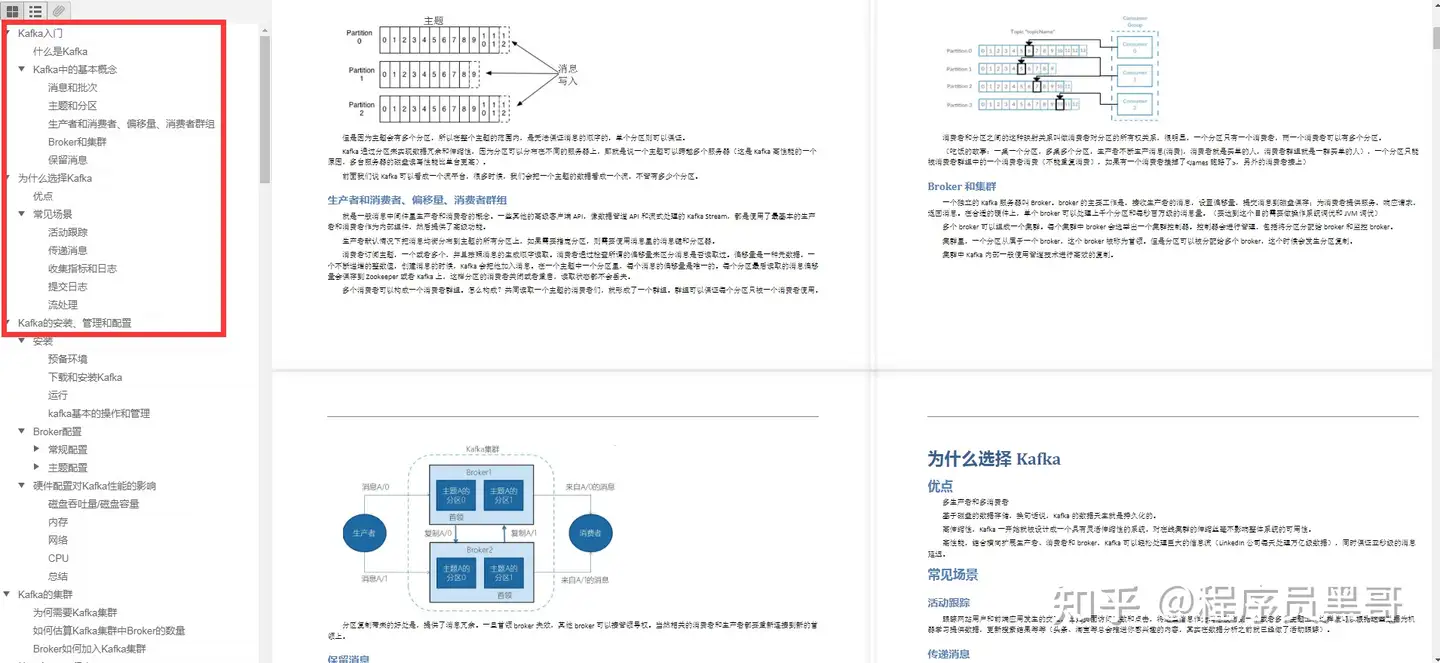
- Kafka的集群
- 第一个Kafka程序
- Kafka的生产者


- Kafka的消费者
- 深入理解Kafka
- 可靠的数据传递


- Spring和Kalka的整合
- Sprinboot和Kafka的整合
- Kafka实战之削峰填谷
- 数据管道和流式处理(了解即可)

Kafka实战之削峰填谷

第二份资料:ActiveMQ实战笔记

- ActiveMQ入门
- ActiveMQ的安装


- 原生JMS API操作ActiveMQ
- Spring与ActiveMQ整合
- SpringBoot与ActiveMQ整合
- ActiveMQ消息组成与高级特性
- ActiveMQ企业面试经典问题

第三份资料:RabbitMQ实战笔记

- 1.消息中间件概述
- 2.安装及配置RabbitMQ
- 3. RabbitMQ入门
- 4. AMQP
- 5. RabbitMQ工作模式
- 6. Spring Boot整合RabbitMQ


- 7. RabbitMQ高级
- 8. RabbitMQ集群
- 9. RabbitMQ高可用集群[扩展]
- 10. RabbitMQ应用与面试

第四份资料:RocketMQ实战笔记

- RocketMQ介绍
- RocketMq中消息的发送
- RocketMQ消息消费

- 深入消息发送
- 深入消息模式
- 顺序消息

- 延时消息
- 死信队列
- 消费幂等

- 消息过滤
- RocketMQ存储概要设计
- RocketMQ中的事务消息

- RocketMQ主从同步(HA)机制
- 限时订单实战
- RocketMQ源码分析


消息队列重要机制讲解以及MQ设计思路(kafka、rabbitmq、rocketmq)
目录
- 《Kafka篇》
- 简述kafka的架构设计原理(入口点)
- 消息队列有哪些作用(简单)
- 消息队列的优缺点,使用场景(基础)
- 消息队列如何保证消息可靠传输
- 死信队列是什么?延时队列是什么?(经典)
- 简述kafka的rebalance机制(比较深入)
- 简述kafka的副本同步机制(比较深入)
- kafka中zookeeper的作用
- kafka中的pull、push的优劣势分析
- kafka中高读写性能原因分析
- kafka高性能高吞吐的原因
- kafka消息丢失的场景以及解决方案(重点)
- kafka为什么比RocketMQ的吞吐量高
- kafka、ActiveMQ、RabbitMQ、RocketMQ对比
- 《RabbitMQ篇》
- RabbitMQ架构设计
- RabbitMQ的交换器类型
- RabbitMQ的普通集群模式
- RabbitMQ的镜像队列原理
- RabbitMQ持久化机制
- RabbitMQ事务消息
- RabbitMQ如何保证消息的可靠性传输
- RabbitMQ的死信队列原理
- RabbitMQ是否可以直连队列
- 《RocketMQ篇》
- 简述RocketMQ架构设计
- 简述RocketMQ持久化机制
- RocketMQ怎么实现顺序消息
- RocketMQ的底层实现原理
- RocketMQ如何保证不丢失消息
- 《MQ总结篇》
- 如何设计一个MQ
- 如何进行产品选型
- 如何保证消息的顺序
《Kafka篇》
简述kafka的架构设计原理(入口点)
无论是那种MQ都会存在三个:producer、MQ的cluster、consumer的group
kafka中还多出了zookeeper,用来维护集群的。
注意分区是将一个整体分割到不同的分区上,主从则是都保留数据整体,不过是主与副本的关系。
Broker:单独的机器
Consumer Group:消费者组,消费者组内每个消费者负责消费不同分区的数据,提高消费能力。逻辑上的一个订阅者
Topic:可以理解为一个队列,Topic将消息分类,生产者和消费者面向的是同一个Topic,它是可以分区的,存在不同的Broker中
Partition:为了实现扩展性,提高并发能力。一个Topic以多个Partition的方式分布到多个Broker上,每个Partition是一个有序的队列。一个Topic的每个Partition都有若干个副本,一个Leader和若干个Follower。生产者发送数据的对象以及消费者消费的数据对象都是Leader。(这一点可以从图中看出,红色的虚线便是如此)Follower负责实时从Leader中同步数据,保持和Leader数据同步。Leader发生故障时,某个Follower会被重新选举为新的Leader。
一个Topic是一个消息主题,是一个逻辑概念。Partition也是逻辑概念。Topic1内部有两个分区:P1、P2,P1有主从、P2也有主从,都是可以设置的。
如果某个Partition设置的主从数小于Broker数,那么不会是每个Broker机子上都有副本。
如果设置的主从数大于Broker数,那么多余的Partition会冗余再Broker中。

接下来看消费者组。组1里面有C1 C2,组2里面有C3 C4。
组1只消费Topic1,组2只消费Topic2
C1消费Topic1的P0。C2消费Topic1的P1,消费的都是Leader节点。这是正常模式。
下面是非正常模式:
C3 C4都消费的是Topic2的P0,此时C3 与C4会形成互斥。当业务高峰期时,MQ中消息堆积过多,可以增加group中的消费者实例,加速消费。
zookeeper则时负责维护broker,与broker维持心跳,哪个broker宕机了,zookeeper都是可以感知到的。
并且生产者与消费者需要锁定分区的Leader,这个信息可以到zookeeper中去取。
消息队列有哪些作用(简单)
1、解耦:使用消息队列来作为两个系统直接的通讯方式,两个系统不需要相互依赖了
2、异步:系统A给消费队列发送完消息之后,就可以继续做其他事情了
3、流量削峰:如果使用消息队列的方式来调用某个系统,那么消息将在队列中排队,由消费者自己控制消费速度。将流量从高峰期引入到低谷期进行处理,起到缓冲作用
消息队列的优缺点,使用场景(基础)
优点:
1、解耦:使用消息队列来作为两个系统直接的通讯方式,两个系统不需要相互依赖了
2、异步:系统A给消费队列发送完消息之后,就可以继续做其他事情了
3、流量削峰:如果使用消息队列的方式来调用某个系统,那么消息将在队列中排队,由消费者自己控制消费速度
缺点:
1、增加了系统复杂度,加上了与MQ交互的逻辑,带入了幂等、重复消费、消息丢失等问题
2、系统可用性降低,MQ的故障会影响系统可用
3、一致性,消费端可能失败。A端将消息送入MQ后就不知道B端对消息处理是否成功。
使用场景:
日志采集:日志量较大时不希望影响到正常的业务,使用MQ异步传送出去,允许小部分的重复记录、记录消失
发布订阅:类似与监听,对感兴趣的消费MQ中的消息
消息队列如何保证消息可靠传输
消息可靠传输代表两层意思:不多也不少
1、为了保证消息不多,也就是消息不能重复,也就是生产者不能重复生产消息,或者消费者不能重复消费消息:
- 要确保消息不多发,这个不容易出现,难以控制
- 从MQ本身来看,尽管有ack或offset的机制,在网络不好或者消费者宕机时,这些标志上传会失败。所以MQ也不能保证正确感知消息是否被消费
- 要避免不重复消费,最保险机制就是消费者实现幂等性,保证就算是重复消费,也不会出现问题。具体来讲,就是不管是MQ push消息还是消费者pull消息都要保证。幂等的概念就是用相同的参数请求C端,处理结果不会因为次数的增加而改变。这边提供三个方案:
1、如果是写redis,就没问题,每次都是set,天然幂等性。但是键值对的超时时间会随着刷set而往后延。
2、生产者发送消息的时候带上一个全局唯一的id,消费者拿到消息后,先根据这个id去redis里查一下,之前有没有被消费过,没有消费过就处理,并且写入这个id到redis。如果消费国了,则不处理
3、基于数据库的唯一键,主键唯一的话,重复的记录就不会被插入
2、消息不能少,也就是消息不能丢失,生产者发送的消息,消费者一定要能消费到:
- 生产者发送消息时,要确认broker确实收到并持久化了这条消息,比如RabbitMQ的confirm机制,Kafka的ack机制都可以保证生产者能正确的将消息发送给broker
- broker要等待消费者真正确认消费到了消息时才删除掉消息,这里通常就是消费端ack机制,消费者接收到一条消息后,如果确认没问题了,就可以给broker发送一个ack,broker接收到ack后才会删除消息
死信队列是什么?延时队列是什么?(经典)
1、死信队列也是一个消费队列,用来存放那些没有成功消费的消息,(重试之后还是失败则进入死信队列),可以用来作为消息重试
2、进入到这个队列中的消息,需要等待设置的时间之后才能被消费者消费到,延时队列就是用来存放需要在指定时间被处理的元素的队列,通常可以用来处理一些具有过期性操作的业务,如十分钟内未支付就取消订单
简述kafka的rebalance机制(比较深入)
该机制会影响kafka的读写性能,在rebalance时,读写会进入阻塞,直到rebalance完成,所以需要尽量避免rebalance。
rebalance指的是consumer group(消费者组)中的消费者和topic下的partion(分区)重新匹配的过程
假设组里面有3个消费者,topic将C1 C2 C3其分区到P1 P2 P3中,进行对应消费

如果C1宕掉了,意味着P1没有消费者来消费了,此时就会进行rebalance 。
又或者,此时group中多了C4 C5 C6,那么此时最好是将它们均分三个Partion,也就是说P1的消息只会发往C1 或者C4,此时也需要进行rebalance。也就是说,新加入节点,需要将分区数与消费者数目进行重新计算匹配。
总结一下何时会产生rebalance
- 1、consumer group 中的成员个数发生变化
- 2、consumer 消费超时,一直没有提交offset
- 3、group订阅的topic个数发生变化
- 4、group订阅的topic的分区数发生变化
所以对应减少rebalance的方法有:
1、超时阈值调大
2、在业务低峰期的时候人工增加topic和partion
那么rebalance具体是什么样的操作呢,下面介绍coordinator发现 group 中的成员个数发生变化主动进行rebalance的操作过程:
coordinator:通常是partion的leader节点(一个partion是有多个副本的,存在leader与follower节点)所在的broker,负责监控group中的consumer的存活,consumer维持到coordinator的心跳(消费者定时向协调者上报心跳),判断consumer是否消费超时
- coordinator通过心跳返回通知consumer进行rebalance。举例,一个group中有C1 C2 C3,此时C1挂了,要进行rebalance,协调者也需要通知C1 C2不能进行消费,由于消费者与协调者之间是通过心跳通信,协调者通过回复心跳,通知消费者进入rebalance状态
- consumer请求coordinator加入group,coordinator会知道有哪些消费者请求它加入group,也就知道了group中有哪些消费者是存活的,coordinator就会选举产生leader consumer
- leader consumer从coordinator获取所有的consumer,然后将partion与所有的consumer进行分配,然后将分配结果封装成syncGroup,发送syncGroup(分配信息)到coordinato
- coordinator拿到分配信息后,通过心跳机制将分配信息下发给consumer,consumer拿到分配信息后就知道它该去消费哪个partion了
- 至此,完成rebalance
还有一种情况,就是leader consumer 监控topic or partion的变化,通知coordinator触发rebalance,之后的流程与上述一致。
rebalance存在的问题:如果C1消费消息超时(并没有提交offset),触发了rebalance,重新分配后,该消息极有可能会被其他消费者C2拿去消费,此时C1消费完成提交offset(表示该消息已经处理完了),那么C2消费完之后也会提交一个offset,导致错误
解决方案如下:coordinator每次rebalance,会标记一个Generation(表示rebalance的周期数)给到consumer,每次rebalance该Generation会+1,consumer提交offset的时候,coordinator会比对Generation,不一致则拒绝提交
简述kafka的副本同步机制(比较深入)
之前有提到partion有leader与follower机制的存在,follower节点可能存在多份。
leader负责处理读写请求,follower不处理客户端请求,只负责从leader那边拉取数据,可以理解为主备模式。当leader挂掉之后,由follower进行选举,follower唯一的功能就只是数据同步。
先看看日志在partition中是如何存储的:
kafka的消息是基于append的顺序追加,所以partition中消息也是有顺序的,可以通过offset来确定消息在partition中的具体位置
下面是消息队列的组成结构:
顺序是从下往上开始
LEO:下一条待写入位置
firstUnstableOffset:第一条未提交数据
LastStableOffset:最后一条已提交数据
LogStartOffset:起始位置
当 isolation.level = read_committed,意思是只能够都已提交数据:只能消费到 LastStableOffset
当 isolation.level = read_uncommitted,意思是能够读到已提交和未提交数据,即可以消费到HW的上一条消息
正常情况下HW应该和 LEO位置重合,如果是read_uncommitted的话。但是由于存在ISR机制。
举例partition中有1个Leader和6个followers(f1 ~ f2),ISR只维护6个副本中与Leader中一致的信息,若follower中只有f2 ~ f3与leader消息一致,那么ISR中只保存(f2、f3、Leader)的HW。消费者来消费时,不取决于f2、f3、Leader的HW,而是取决于其中最小的HW,即分区的HW = min(follower.HW, Leader.HW)
一个partition对应的ISR中最小的 LEO作为分区的HW,consumer最多只能消费到HW所在的位置
leader收消息后(offset肯定要移动)会更新本地的 LEO,leader还会维护follower的 LEO即 remote_LEO。follower会发出一个fetch同步数据的请求(携带自身的 LEO)给leader,leader就知道了ISR列表中所有follower的 remote_LEO,然后比较得出最小的 remote_LEO,然后作为分区的HW,然后进行更新,再把HW数据响应给follower ,follower拿到HW之后更新自身的HW(取响应的HW和自身 LEO中的较小值),然后进行数据落盘,然后 LEO+1。所以总的来说follower是异步的形式进行更新HW
ISR:如果一个follower落后leader不超过某个时间阈值,那么则在ISR,否则放在OSR中。
在同步副本的时候,follower获取leader的 LEO和 LogStartOffset,与本地对比。如果本地的 LogStartOffset超出了leader的值,则超过这个值的数据删除,再进行同步,如果本地的小于leader的,那么直接同步。
注意,同步的时候可能会导致消息丢失,leader接受到消息更新完本地后,LEO还没相应给follower的时候,leader自己就挂掉了。然后重启之后原leader就变成follower了(重新选举了),那么它再去向新leader同步的时候就会把原本本地没有同步出去的消息给删除,也代表着这个消息就丢失了。
kafka中zookeeper的作用
zookeeper负责的是集群的管理功能,后面的迭代中zk已经不再了。
看看zk在kafka中存储了哪些节点信息吧:
/brokers/ids:临时节点,kafka连接到zk后创建的节点,保存所有broker节点信息,存储broker的物理地址、版本信息、启动时间等,节点名称为 brokerID,broker定时发送心跳到zk,如果断开则该brokerID节点就会被删除。
/brokers/topics:临时节点,节点保存broker节点下所有的topic信息,每一个topic节点下包含了一个固定的partitions节点(/brokers/topics/partitions),partitions的子节点就是topic的分区,每个分区下保存一个state节点,保存着当前leader分区和ISR(可靠的从节点列表)的brokerID,state节点由leader创建,若leader宕机该节点会被删除,直到有新的leader选举产生、重新生成state节点
/consumer/[group_id]/owners/[topic]/[broker_id-partition_id]:维护消费者和分区的注册关系(哪个消费者消费哪个分区)
/consumer/[group_id]/offsets/[topic]/[broker_id-partition_id]:分区消息的消息进度offset
cilent通过topic找到topic树下的state节点,获取leader的brokerID,到broker树中找到brokerID的物理地址,但是cilent不会直接连着zk,而是通过配置的broker获取到zk中的信息。
kafka中的pull、push的优劣势分析
pull模式:
- 根据consumer的消费能力进行数据拉取,可以控制速率
- 可以批量拉取,也可以单条拉取
- 可以设置不同的提交方式,实现不同的传输语义
缺点:如果kafka没有数据,会导致consumer空循环,消耗资源
解决:通过参数设置,consumer拉取数据为空或者没有达到一定数量时进行阻塞
push模式:
不会导致consumer循环等待。
缺点:速率固定,忽略了consumer的消费能力,可能导致拒绝服务或者网络拥塞等情况
kafka中高读写性能原因分析
原因两点:顺序写 + 零拷贝
kafka是一个文件系统,不基于内存,而是直接硬盘存储,因此消息堆积能力能强。
顺序写:利用磁盘的顺序访问速度可以接近内存,kafka的消息都是append操作,partition是有序的,节省了磁盘的寻道时间,同时通过批量操作节省了写入次数,partition(逻辑概念)物理上分为多个segment文件存储,方便删除
传统:
- 读取磁盘文件数据到内核缓冲区
- 将内核缓冲区的数据copy到用户缓冲区
- 将用户缓冲区的数据copy到socket的发送缓冲区
- 将socket发送缓冲区中的数据发送到网卡、进行传输
零拷贝: - 直接将内核缓冲区的数据发送到网卡传输,节省了数据在内核态与用户态直接的传递
- 使用的是操作系统的指令支持
kafka不太依赖jvm,主要是用的操作系统的pageCache(页存,之后会刷新到磁盘中),如果生产消费速率相当,则直接用pageCache交换数据,不需要经过磁盘IO
kafka高性能高吞吐的原因
1、磁盘顺序读写:保证了消息的堆积
- 顺序读写:磁盘会预读,即在读取的起始地址连续读取多个页面,主要时间花费在了传输时间,而这个时间两种读写可以认为是一样的
- 随机读写,因为数据没有在一起,预读将会浪费时间,需要多次寻道和旋转延迟,而这个时间可能是传输时间的许多倍
2、零拷贝:避免CPU将数据从一块存储拷贝到另外一块存储 - 传统的数据拷贝:
1、读取磁盘文件数据到内核缓冲区
2、将内核缓冲区的数据copy到用户缓冲区
3、将用户缓冲区的数据copy到socket的发送缓冲区
4、将socket发送缓冲区的数据发送到网卡,进行传输 - 零拷贝:
磁盘文件->内核空间读取缓冲区->网卡接口->消费者进程
3、分区分段 + 索引
kafka的message消息实际上是分布式存储在一个一个小的segment中的,每次文件操作也是直接操作的segment。为了进一步的查询优化,kafka又默认为分段后的数据文件建立了索引文件,就是文件系统上的,index文件。这种分区分段 + 索引的设计,不仅提升了数据读取的效率,同时也提高了数据操作的并行度(有点类似与分段锁)
4、批量压缩:存储不是直接存储原文,而是多条消息一起压缩,降低带宽。消费端收到消息后再解压
5、批量读写
6、直接操作的是pageCache,而不是JVM,避免GC耗时及对象创建耗时,且读写速度更高。进程重启缓存也不会丢失
kafka消息丢失的场景以及解决方案(重点)
1)消息发送时出现丢失的场景以及解决
1、ack = 0 ,不重试
生产者发送消息完不管结果了,如果发送失败,消息也就丢失了2、ack = 1, leader 宕机了
生产者发送消息完,只等待leader写入成功就返回了,但是leader之后宕机了,自此follower还没来得及同步,消息丢失3、unclean.leader.election.enable 配置true
允许选举ISR以外的副本作为leader,也会导致数据丢失,默认为false。生产者发送异步消息之后,只等待leader写入成功就返回了,然后leader宕机了,这时ISR中没有follower,leader会从OSR中选举,因为OSR中的follower节点本身就落后与leader,就会造成消息丢失解决方案:
1、配置:ack = all / -1, tries > 1, unclear.leader.election.enable : false
生产者发送消息完,等待follower同步完再返回,如果异常则重试,副本的数量此时可能会影响吞吐量
不允许选举ISR以外的副本作为leader
2、配置:min.insync.replicas > 1,设置越大表示越可靠
副本指定必须确认写操作成功的最小同步副本数量,如果不能满足这个最小值,则生产者将引发一个异常(要么是NotEnoughReplicas,要么是NotEnoughReplicasAfterAppend)
min.insync.replicas和ack是有区别的,
min.insync.replicas(同步副本数量)指的是ISR中的数量必须要大于1
ack = all / -1,表示ISR中的所有节点全部要确认
此间还存在一个隐性的逻辑关系,只有ack = all / -1,那么min.insync.replicas才会生效。
所以这两个参数要搭配着来使用,这样就可以确保如果大多数副本没有收到写操作,则生产者将引起异常。
3、失败的offset单独记录
生产者发送消息,会自动重试,遇到不可恢复异常会抛出,这时可以捕获异常记录到数据库或缓存,进行单独处理
2)消费端
1、先commit offset再处理消息,如果再处理消息的时候出现异常了,但是offset已经提交了,这条消息对于该消费者来说就是丢失的,再也不会消费到了.
2、先处理消息,处理完了再commit,有可能存在重复消费的情况。在处理完这条消息之后,还没来得及commit,就宕机了,重启之后还回去消费这条消息。
解决方案:
先做业务处理,再去commit,如果出现重复消费,就只需要保证接口的幂等性就行了
3)broker端的刷盘
从生产者发送出来的消息实际上是缓存在broker的pageCache上的,然后linux保证pageCache上的数据被刷入硬盘中。如果linux此时宕机了,那么就会有部分pageCache上的数据丢失了。
于是可以通过配置参数,减少系统刷盘间隔
kafka为什么比RocketMQ的吞吐量高
kafka的生产者采用的是异步发送消息机制,当发送一条消息时,消息并没有发送到broker节点上,而是先缓存起来,然后直接向业务返回成功,当缓存的消息积累到一定数量时再批量发送给broker。这种做法减少了网络io,从而提高了消息发送的吞吐量,但是如果消息生产者产生了宕机,会导致消息丢失,业务出错,所以理论上来说kafka利用此机制提高了性能却降低了可靠性。
kafka、ActiveMQ、RabbitMQ、RocketMQ对比
站在应用的角度来看:
ActiveMQ:JMS规范,支持事务、支持XA协议,没有生产大规模支撑场景、官方维护越来越少
RabbitMQ:erlang语言开发、性能好、高并发,支持多种语言,社区、文档方面有优势,erlang语言不利于java二次开发,依赖开源社区的维护和升级,需要学习AMP协议,学习成本相对较高
以上吞吐量单机都在万级
kafka:高性能、高可用,生产环境有大规模使用场景,单机容量有限(超过64个分区响应明显变长)、社区更新慢
吞吐量单机百万
RocketMQ:java实现,方便二次开发,设计参考了kafka,高可用、高可靠,社区活跃度一般,支持语言较少。
吞吐量单机十万
《RabbitMQ篇》
RabbitMQ架构设计

connection:与MQ交互是通过connection,需要建立一个TCP连接,一个connection里面可以开多个信道(channel),这些信道会复用这个TCP连接 。
Broker:rabbitmq的服务节点
Queue:队列,是RabbitMQ的内部对象,用于存储消息。RabbitMQ中消息只能存储在队列中,生产者投递消息到队列,消费者从队列中获取消息并消费。多个消费者可以订阅同一个队列,这时队列中的消息会被平均分摊(轮询)给多个消费者进行消费,而不是每个消费者都收到所有的消息进行消费。(注意,RabbitMQ不支持队列层面的广播消费,如果需要广播消费,可以采用一个交换器通过路由Key绑定到多个队列,由多个消费者来订阅这些队列)
Exchange:交换器,生产者将消息发送到Exchange,由交换器将消息路由到一个或多个队列中。交换器与不同的队列通过绑定键绑定
RoutingKey:路由Key,生产者将消息发送给交换器的时候,一般会指定一个RoutingKey,用来指定这个消息的路由规则。这个路由Key需要与交换器类型和绑定键(BindingKey)联合使用才能最终生效(生产者指定的的RoutingKey会与BindingKey进行匹配,匹配规则与交换器类型有关)。在交换器类型和绑定键固定的情况下,生产者可以在发送消息给交换器时通过指定RoutingKey来决定消息流向哪里。
消息发送流程:
生产者将routeKey、exchangeName、body通过信道传递到broker里面,根据exchangeName找到交换机,用该交换机的匹配规则将routeKey匹配到现有的BindingKey,如果匹配上了,将消息投放到对应的queue里面。
消费流程:由Pull和Push两种方式
多个消费者消费同一个queue的话,queue里面的一条消息只会被一个消费者消费到
如果要发布订阅功能 ,生产者想要让多个消费者收到同一个消息,只需要通过交换器分发到多个queue上去即可。
vhost:虚拟主机的概念。一个broker其实就是一个物理主机,vhost其实就是虚拟主机,可以在一个broker上建立多个vhost。每个vhost都包含着自己的Exchange和Queue。应用可以指定其中一个虚拟机,所以一个rabbitmq可以给多个不同的应用使用,同时也是应用隔离的
RabbitMQ的交换器类型
交换器分发会先找出绑定的队列,然后再判断 routekey,来决定是否将消息分发到某一个队列中

RabbitMQ的交换器类型决定了routeKey与BindingKey如何匹配,是精准匹配还是模糊匹配
有下面几种匹配规则:
fanout:扇形交换器,不再判断routekey,直接将消息分发到所有绑定的队列
direct:判断routekey的规则是完全匹配模式,即发送消息时指定的routekey要等于绑定的routekey
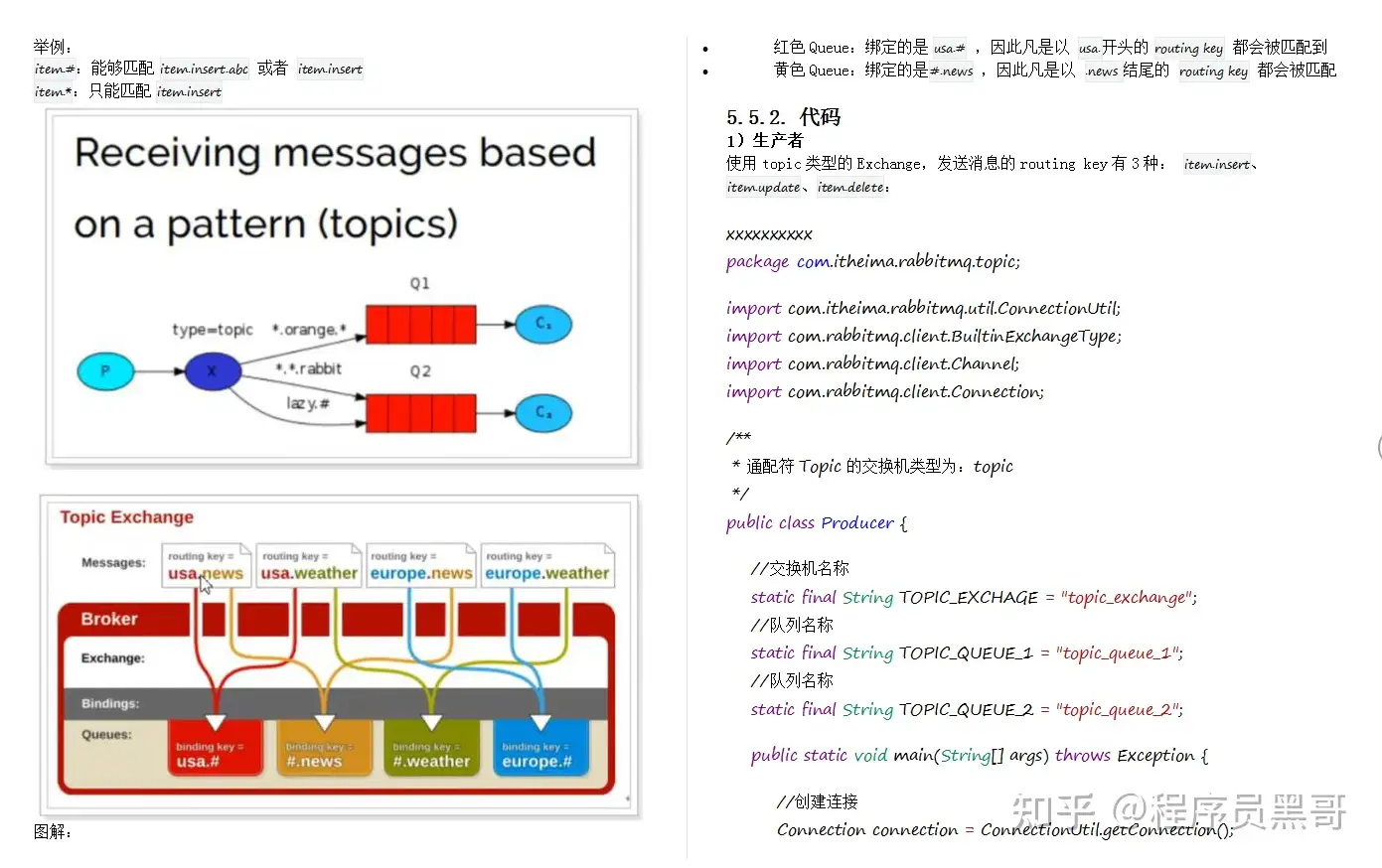
topic:判断routekey的规则是模糊匹配模式
header:绑定队列与交换器的时候指定一个键值对,当交换器在分发消息的时候胡先解开消息体里面的 headers数据,然后判断里面是否有所设置的键值对,如果发现匹配成功,才将消息分发到队列中。性能较差
RabbitMQ的普通集群模式
RabbitMQ中单个节点broker中存在着三个信息:
exchange:交换机,就是一张表,维护了路由键到queue的关系
queue:存放消息的容器
msg:消息内容
这里我们模拟集群中有3个节点,普通集群模式下,每个节点上存储的元数据是一样的。
元数据
- 队列元数据:队列名称和它的属性
- 交换器元数据:交换器名称、类型和属性
- 绑定元数据:一张简单的表展示了如何将消息路由到队列
- vhost元数据:就是一个broker,为vhost内的队列、交换器和绑定提供命名空间和安全属性
元数据每个节点都存了一份,是冗余的。消息的内容并没有每个节点都存,例如client1连节点1,那么queue1的消息内容只会存在节点1,不会同步到其他节点。所以某个节点宕机,就保证不了高可用。
同步元数据,这样每个节点都可以对外服务,想去消费其他queue时可以通过路由表去转发对应的请求。
为什么只同步元数据: - 存储空间考虑,每一个节点都保存全量数据会影响消息堆积能力
- 性能考虑,消息的发布者需要将消息复制到每一个集群节点
客户端连接的是非队列数据所在节点:则该节点会进行路由转发,包括发送和消费
集群节点类型: - 磁盘节点:将配置信息和元信息存储在磁盘上
- 内存节点:将配置信息和元信息存储在内存上,性能优于磁盘节点,依赖磁盘节点进行持久化
RabbitMQ要求集群中至少有一个磁盘节点,当节点加入和离开集群时,必须通知磁盘节点(如果集群中唯一的磁盘节点崩溃,则不能进行创建队列、创建交换器、创建绑定、添加用户、更改权限、添加和删除集群节点)。如果唯一磁盘的磁盘节点崩溃,集群是可以保持运行的,但是不能更改任何东西。因此建议在集群中设置两个磁盘节点,只要一个正常,系统就能正常工作。
RabbitMQ的镜像队列原理
基于集群模式才能设置镜像队列,要想实现高可用的话就必须使用集群+镜像队列的模式
整个队列,称为AMQPQueue包含四个部分:Queue、mirror_queue_master/slave、blockingQueue、GM

mirror_queue_master/slave负责消息的处理的进程,操作 blockingQueue。blockingQueue是真正用来储存消息的
Queue负责AMQP协议(commit、rollback、ack等)
master负责处理读写,slave只做备份
GM负责消息的广播,所有的GM组成 gm_group,形成链表结构,负责监听相邻节点的状态,以及传递消息到相邻节点(传给下一个节点,直到发送该消息的节点收到该消息,说明整个环路都走完了),master的GM收到消息时代表消息同步完成。
当master挂掉了,整个GM里面存在时间最长的slave(也意味着与master同步最多)将晋升为master。
GM不负责操作 blockingQueue,所以在接收到同步过来的消息时,会交由slave进程操作
RabbitMQ持久化机制
RabbitMQ持久化分为三个方面:
1、交换器持久化:exchange_declare创建交换器的时候通过参数指定
2、队列持久化:queue_declare创建队列时通过参数指定
3、消息持久化:new AMQPMessage创建消息时通过参数指定
持久化的时候是按照append的方式去写文件,会根据大小自动生成新的文件(例如一个log是16M,满了之后就会写新的log文件)。rabbitmq在启动的时候会创建两个进程,一个负责持久化消息的存储,另一个负责非持久化消息的存储(内存不够时)
消息存储时会在ets表中记录消息在文件中的映射以及相关信息(包括id、偏移量、有效数据、左边文件、右边文件),消息读取时根据该信息到文件中读取,同时更新信息。
消息删除时只从ets删除,变为垃圾数据,当垃圾数据超出比例(默认为50%),并且文件数达到3个,触发垃圾回收,锁定左右两个文件,整理左边文件有效数据,将右边文件有效数据写入左边,更新文件信息,删除右边,完成合并。当一个文件的有用数据等于0时,删除该文件。
写入文件前先写buffer缓冲区,如果buffer已经满了,则写入文件(此时知识操作系统的页存)。每隔25ms刷一次磁盘,不管buffer满没满都将buffer和页存的数据落盘。每次消息写入后,如果没有后续写入请求,则直接刷盘。
RabbitMQ事务消息
通过对channel的设置实现
1、channel.txSelect():通知服务器开启事务模式,服务端会返回 Tx.Select.Ok
2、channel.basicPublish:发送消息,可以是多条可以是消费消息提交ack
3、channel.txCommit():提交事务
4、channel.txRollback():回滚事务
消费者使用事务:
1、autoAck = false,手动提交ack,以事务提交或回滚为准
2、autoAck = true,不支持事务,即使再收到消息后再回滚事务也是于事无补的,队列已经把消息移除了
如果其中任意一个环节出现问题,就会抛出 IoException异常,用户可以拦截异常进行事务回滚,或决定要不要重复消息
事务消息会降低RabbitMQ的性能,因为每一条消息都意味着好几次连接
RabbitMQ如何保证消息的可靠性传输
1、使用事务消息
2、使用消息的确认机制(即ack)
发送方确认发送出去:
- 将channel设置为confirm模式,则从该channel上发出的每条消息都会被分配一个唯一id
- 消息投递成功后,channel会发送ack给生产者,包含了id,回调
ConfirmCallback接口(该接口是异步的) - 如果发生错误导致消息丢失,发送nack给生产者,回调
ReturnCallback接口 - ack和nack只有一个触发,且只有一次,异步触发,可以继续发送消息
发送到MQ之后,做了持久化之后数据才会可靠。
接收方确认消费完了:
- 声明队列时,指定
noack = false,broker会等待消费者手动返回ack,才会从磁盘或者内存中删除消息,否则立刻删除 - broker的ack没有超时机制,只会判断链接是否断开,如果断开,消息会被重新发送
- 如果ack没有提交,那么broker中的该消息就不会被删除,所以消费者接受每一条消息后都必须进行确认
- 如果消费者返回ack之前断开了连接MQ的broker会重新分发给下一个订阅的消费者(可能存在消息重复消费的隐患)
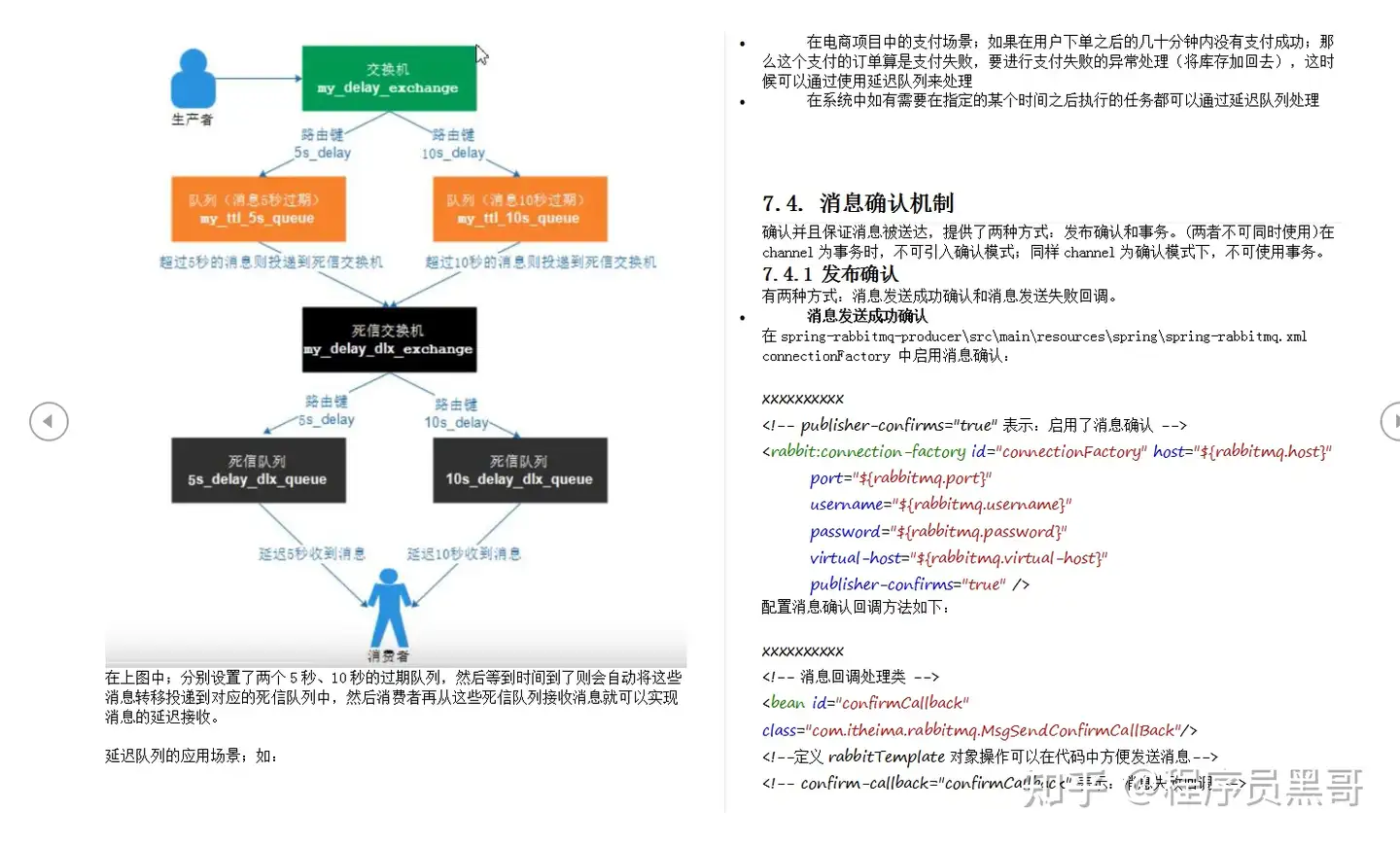
RabbitMQ的死信队列原理
死信队列里面放的是死信消息,下面是死信消息产生的原因:
1、消息被消费方否定确认,使用 channel.basicNack或 channel.basicReject,并且此时 requeue属性被设置为 false,表示直接丢弃(requeue为 true的话会重复投递)
2、消息在队列的存活时间超过设置的TTL时间
3、消息队列的消息数量已经超过最大队列长度
如果满足上面条件,那么该消息将成为死信消息,如果配置了死信队列信息,那么该消息将会被丢入死信队列中,如果没有配置,则该消息将会被丢弃
为每个需要使用死信队列的业务队列配置一个死信交换机,同一个项目的死信交换机可以共用一个,然后为每个业务队列分配一个单独的 routeKey,死信队列只不过是绑定在死信交换机上的队列。
TTL:一条消息或者该该队列中所有消息的最大存活时间
如果一条消息设置了TTL属性或者进入设置TTL属性的队列,那么这条消息在TTL设置的时间内没有被消费,则会成为死信,如果同时配置了队列的TTL和消息的TTL,那么较小的那个值将会被使用
RabbitMQ是否可以直连队列
从之前的架构设计来看,生产者先把消息发到交换器,然后交换器根据匹配规则将消息发送给队列,实际上生产者也是可以直接把消息发给队列的,但是正常不这样做,会丧失灵活性(一对一与一对多都可),直连的话只能是一对一了。
下面是实现方式以及参数说明

声明Queue的参数说明



《RocketMQ篇》
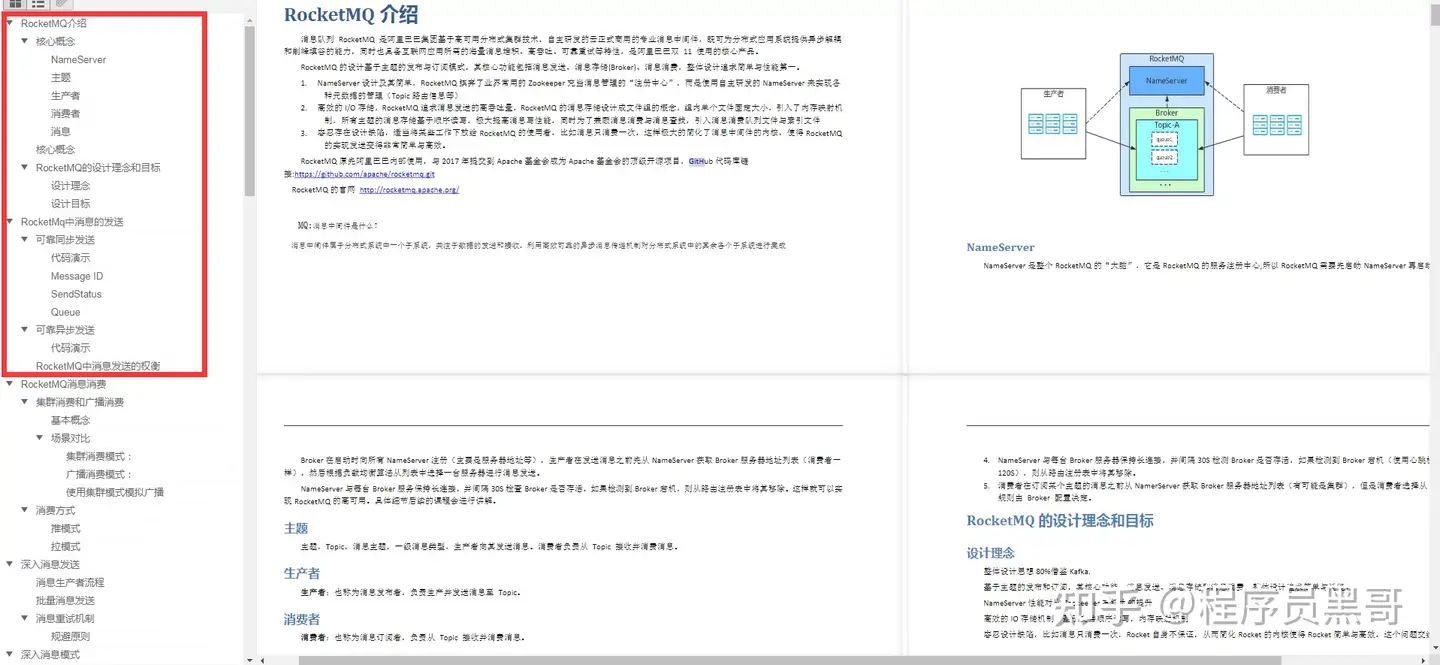
简述RocketMQ架构设计

该架构参考了kafka,NameServer类似于kafka中的zookeeper,queue类似于kafka中的partition。
kafka中,zk本身存在主从,主从之间也会有数据同步。NameServer则是一个去中心化的结构,每个NameServer之间互相独立,不进行互相通信。只要NameServer存在一个可用节点,那么NameServer就是可用的,它的作用主要就是为了维护路由信息,发送者是谁->发给哪个topic的哪个queue、broker是哪一个->消费者是谁。
注意这里的queue是不存在主从的,而kafka的partition是存在主从的。所以RocketMQ里面的queue是冗余的,有n个broker,就会冗余n-1个数据。这样的好处体现在负载均衡上,如果broker1宕机了,生产者queue1连不上,之前可能会去连queue2,但是此时它会直接去连接broker2的queue1,提高成功率,
每一个Broker要和每一个NameServer建立长连接,底层是由netty维护通信,broker会定期地将自己地topic信息注册到NameServer里。
生产者首先需要连接NameServer,去拉取topic所属地broker,然后直连broker,发送消息到topic的dqueue里面去。
消费者也是需要连接NameServer,去拉取topic所属地broker,然后直连broker,从topic的queue里面获取消息进行消费。
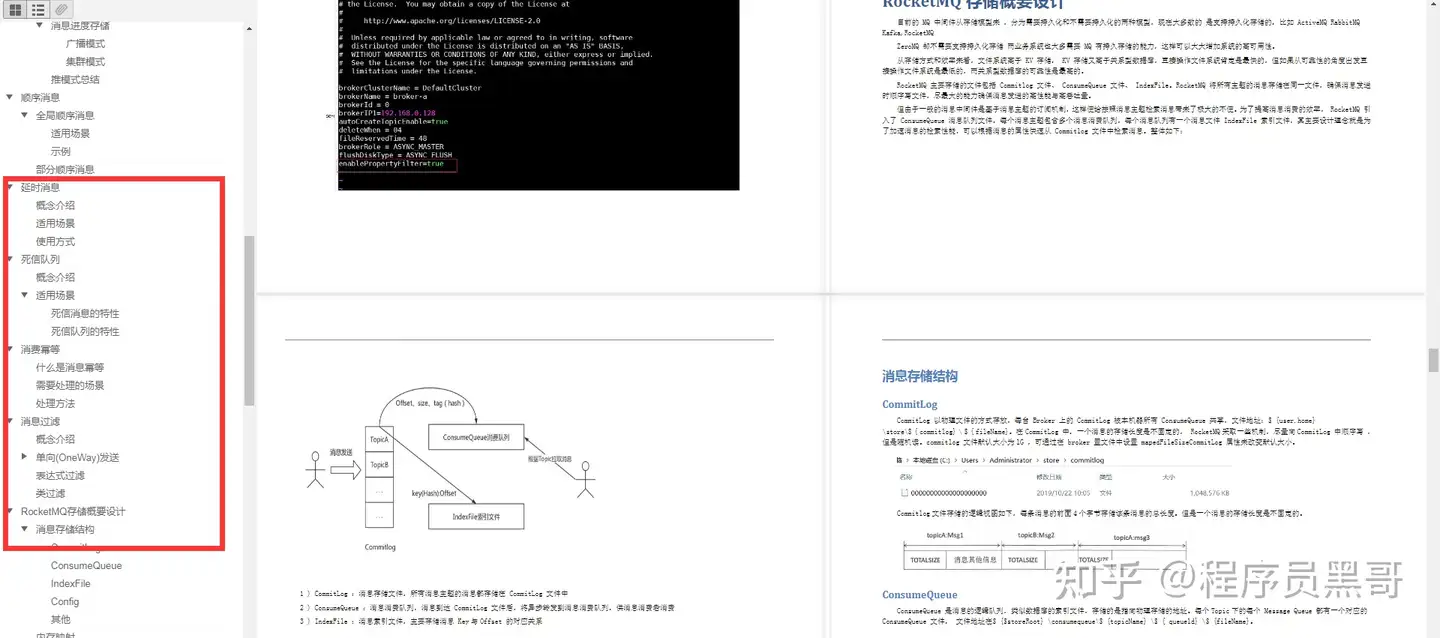
与broker的持久化相关的涉及到三个日志文件:
CommitLog:存储的具体的消息内容,但是不区分topic,是顺序读写
ConsumeQueue:是commitlog基于topic的索引文件,所以是先根据topic到这个文件里面找索引,然后拿着索引去CommitLog里面找具体内容,顺序存储
IndexFile:通过key或时间区间来建立索引,也是commitlog的索引文件
简述RocketMQ持久化机制
- commitlog:日志数据文件,被所有的queue共享,1G,写满之后重新生成,顺序写
- consumeQueue:逻辑queue,消息先到到commitlog,然后异步转发到consumeQueue,包含queue在commitlog种的物理位置偏移量offset,消息实体内容的大小和Message Tag的hash值。大小约为600W个字节,写满之后重新生成,顺序写
- indexFile:通过key或者时间区间来查找commitlog种的消息,文件名以创建的时间戳命名,固定的单个indexFile大小为400M,可以保存2000W个索引
所有队列共用一个日志数据文件,避免了kafka分区数过多、日志文件过多导致磁盘IO读写压力较大造成性能瓶颈。rocketmq的queue只存储少量数据、更加轻量化,对于磁盘的访问时串行化避免磁盘竞争,缺点在于:写入是顺序写,读是随机读,先读consumeQueue,再读commitlog会降低消息读的效率。
消息发送到broker之后,会被写入commitlog,写之前加锁,保证顺序写入,然后转发到consumeQueue。
消息消费时先从consumeQueue读取消息在Commitlog中的起始物理偏移量offset,消息大小和消息Tag的HashCode值,在从commitlog读取消息内容
- 同步刷盘,消息持久化到磁盘才会给生产者返回ack,可以保证消息可靠、但是回影响性能
- 异步刷盘,消息写入pagecache就返回ack给生产者,刷盘采用异步线程,降低读写延迟提高性能和吞吐
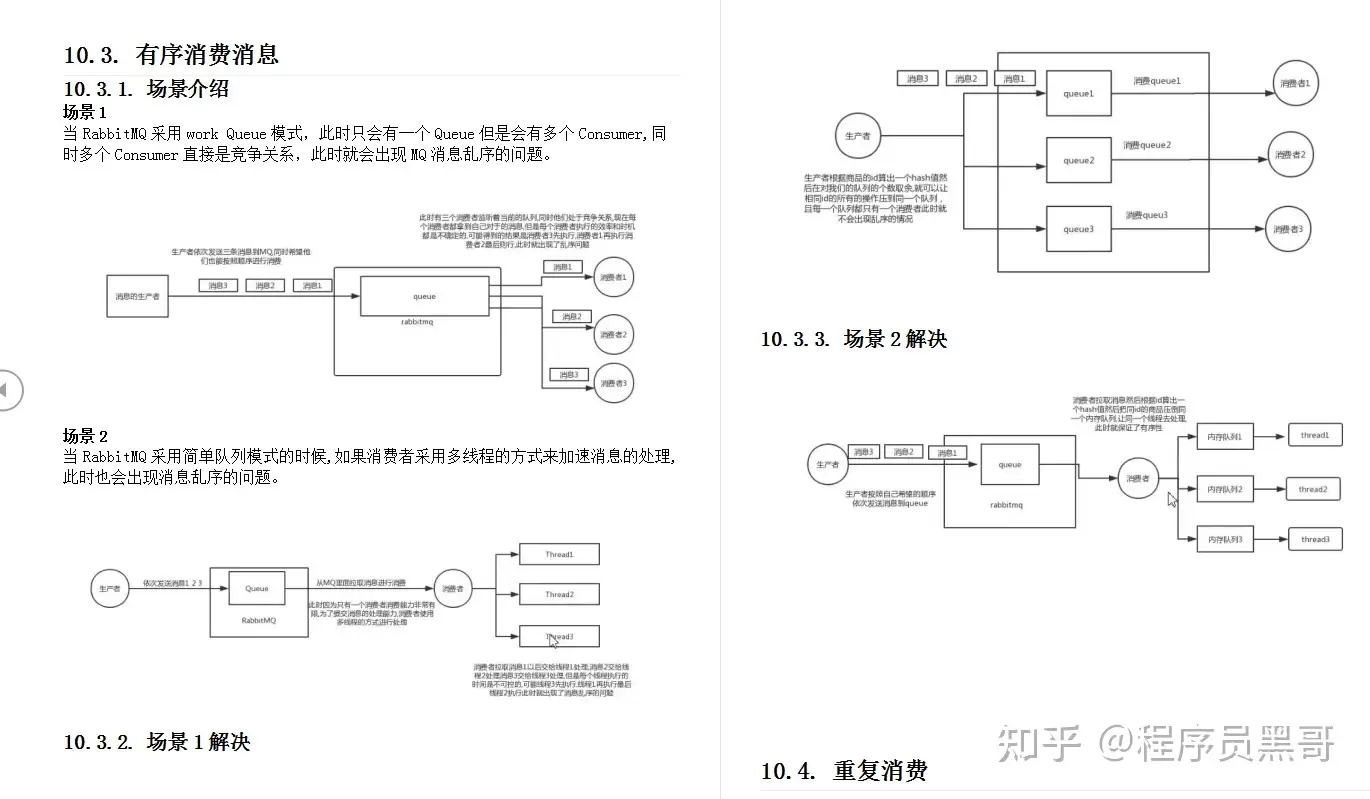
RocketMQ怎么实现顺序消息
默认是不能保证的,需要程序保证发送和消费的是同一个queue,多线程消费也无法保证
发送顺序:发送端自己的业务逻辑保证先后,发往一个固定的queue,生产者可以在消息体上设置消息顺序
发送者实现MessageQueueSelector接口,选择一个queue进行发送,也可以使用rocketmq提供的默认实现:
- SelectMessageQueueByHash:按参数的hashcode与可选队列进行求余选择
- SelectMessageQueueByRandom:随机选择
mq:queue本身就是顺序追加写,只需要保证一个队列同一时间只有一个consumer消费,通过加锁实现,consumer上的顺序消费有一个定时任务、每隔一定时间向broker发送请求延长锁定
消费端:
pull模式:消费者需要自己维护需要拉取的queue,一次拉取的消息都是顺序的,需要消费端自己保证顺序消费
push模式:消费实例实现自己的MQPushConsumer接口,提供注册监听的方法消费消息,registerMessageListener、重载方法。
- MessageListenerConcurrently:并行消费
- MessageListenerOrderly:串行消费,consumer会把消息放入本地队列并加锁,定时任务保证锁的同步
RocketMQ的底层实现原理
RocketMQ由NameServer集群、Producer集群、Consumer集群、Broker集群组成,消息生产和消费的大致原理如下:
1、Broker在启动的时候向所有的NameServer注册,并保持长连接,每30s发送一次心跳
2、Producer在发送消息的时候从NameServer获取Broker服务器地址,根据负载均衡算法选择一台服务器来发送消息
3、Consumer消费消息的时候同样从NameServer获取Broker地址,然后主动拉取消息来消费
RocketMQ如何保证不丢失消息
生产者:
- 同步阻塞的方式发送消息,加上失败重试机制,可能broker存储失败,可以通过查询确认
- 异步发送需要重写回调方法,检查发送结果
- ack机制,可能存储commitlog,存储consumerQueue失败,此时对消费者不可见
broker:同步刷盘、集群模式下采用同步复制、会等待slave复制完成才会返回确认
消费者:
- offset手动提交,消息消费保证幂等
《MQ总结篇》
如何设计一个MQ
好的方式:
1、从整体到细节,从业务场景到技术实现
2、以现有产品为基础
实现:
1、先实现一个单机的先进先出的数据结构,对message设计封装。要高效、可扩展以及收缩
2、将单机队列扩展成为分布式队列,涉及到分布式集群管理,如zookeeper、NameServer
3、基于Topic定制路由策略(从生产者到消费者的完整链路): 发送者路由策略、消费者与队列对应关系、消费者路由策略
4、实现高效的网络通信。-> Netty、Http
5、规划日志文件,实现文件高效读写(零拷贝+顺序写)服务重启后,快速还原运行现场
6、定制高级功能,死信队列、延迟队列、事务消息等等。(需要贴合业务实际)
参考:
如何设计一个MQ
如何进行产品选型
kafka:
优点:吞吐量非常大,性能非常好,集群高可用
缺点:会丢失数据,功能单一。不具备死信队列等高级功能
使用场景:数据量大,频繁,且允许丢失数据:日志分析、大数据采集
RabbitMQ:
优点:消息可靠性高,功能全面
缺点:吞吐量比较低,并发性不高,消息积累会严重影响性能。适合在消息来了立马消费的场景使用。erlang开发,语言不好定制
使用场景:小规模场景
RocketMQ:
优点:高吞吐,高性能,高可用,功能全面的
缺点:开源版本功能不如云上商业版本。官方文档和周边生态不成熟。客户端只支持java
使用场景:几乎是全场景
如何保证消息的顺序
参考链接:https://rocketmq.apache.org/docs/order-example/
这个知识点是有一个背景的,在rocketmq里面,有一个完善的机制,在产品层面上对消息进行顺序的保证,而kafka与rabbitmq是没有这样的设计的。
消息顺序分为全局有序和局部有序,MQ只需要保证局部有序,不需要保证全局有序。保证一个窗口内的消息是有序的,多个窗口之间的消息有序没有业务意义。例如一个订单,有许多处理步骤,这些步骤是不能乱的 ,消息必须是从上往下进行消费。订单与订单之间消息可以不是有序的,没有必要等到1号订单发完再发2号订单。

一文揭秘RabbitMQ、RocketMQ、Kafka 的核心架构(建议收藏)
大家好,我是飘渺。
今天我们通过一篇文章来认识一下常见消息队列RabbitMQ、RocketMQ、Kafka。
RabbitMQ
RabbitMQ各组件的功能
- Broker :一个RabbitMQ实例就是一个Broker
- Virtual Host :虚拟主机。相当于MySQL的DataBase,一个Broker上可以存在多个vhost,vhost之间相互隔离。每个vhost都拥有自己的队列、交换机、绑定和权限机制。vhost必须在连接时指定,默认的vhost是/。
- Exchange :交换机,用来接收生产者发送的消息并将这些消息路由给服务器中的队列。
- Queue :消息队列,用来保存消息直到发送给消费者。它是消息的容器。一个消息可投入一个或多个队列。
- Banding :绑定关系,用于消息队列和交换机之间的关联。通过路由键(Routing Key)将交换机和消息队列关联起来。
- Channel :管道,一条双向数据流通道。不管是发布消息、订阅队列还是接收消息,这些动作都是通过管道完成。因为对于操作系统来说,建立和销毁TCP都是非常昂贵的开销,所以引入了管道的概念,以复用一条TCP连接。
- Connection :生产者/消费者 与broker之间的TCP连接。
- Publisher :消息的生产者。
- Consumer :消息的消费者。
- Message :消息,它是由消息头和消息体组成。消息头则包括Routing-Key、Priority(优先级)等。

RabbitMQ的多种交换机类型
Exchange 分发消息给 Queue 时, Exchange 的类型对应不同的分发策略,有3种类型的 Exchange :Direct、Fanout、Topic。
- Direct:消息中的 Routing Key 如果和 Binding 中的 Routing Key 完全一致, Exchange 就会将消息分发到对应的队列中。
- Fanout:每个发到 Fanout 类型交换机的消息都会分发到所有绑定的队列上去。Fanout交换机没有 Routing Key 。它在三种类型的交换机中转发消息是最快的。
- Topic:Topic交换机通过模式匹配分配消息,将 Routing Key 和某个模式进行匹配。它只能识别两个通配符:"#"和"*"。# 匹配0个或多个单词, * 匹配1个单词。
TTL
TTL(Time To Live):生存时间。RabbitMQ支持消息的过期时间,一共2种。
- 在消息发送时进行指定。通过配置消息体的 Properties ,可以指定当前消息的过期时间。
- 在创建Exchange时指定。从进入消息队列开始计算,只要超过了队列的超时时间配置,那么消息会自动清除。
生产者的消息确认机制
Confirm机制:
- 消息的确认,是指生产者投递消息后,如果Broker收到消息,则会给我们生产者一个应答。
- 生产者进行接受应答,用来确认这条消息是否正常的发送到了Broker,这种方式也是消息的可靠性投递的核心保障!
如何实现Confirm确认消息?

- 在channel上开启确认模式:channel.confirmSelect()
- 在channel上开启监听:addConfirmListener ,监听成功和失败的处理结果,根据具体的结果对消息进行重新发送或记录日志处理等后续操作。
Return消息机制:
Return Listener用于处理一些不可路由的消息。
我们的消息生产者,通过指定一个Exchange和Routing,把消息送达到某一个队列中去,然后我们的消费者监听队列进行消息的消费处理操作。
但是在某些情况下,如果我们在发送消息的时候,当前的exchange不存在或者指定的路由key路由不到,这个时候我们需要监听这种不可达消息,就需要使用到Returrn Listener。
基础API中有个关键的配置项 Mandatory :如果为true,监听器会收到路由不可达的消息,然后进行处理。如果为false,broker端会自动删除该消息。
同样,通过监听的方式, chennel.addReturnListener(ReturnListener rl) 传入已经重写过handleReturn方法的ReturnListener。
消费端ACK与NACK
消费端进行消费的时候,如果由于业务异常可以进行日志的记录,然后进行补偿。但是对于服务器宕机等严重问题,我们需要手动ACK保障消费端消费成功。
PHP
// deliveryTag:消息在mq中的唯一标识
// multiple:是否批量(和qos设置类似的参数)
// requeue:是否需要重回队列。或者丢弃或者重回队首再次消费。
public void basicNack(long deliveryTag, boolean multiple, boolean requeue)
如上代码,消息在消费端重回队列是为了对没有成功处理消息,把消息重新返回到Broker。一般来说,实际应用中都会关闭重回队列(避免进入死循环),也就是设置为false。
死信队列DLX
死信队列(DLX Dead-Letter-Exchange):当消息在一个队列中变成死信之后,它会被重新推送到另一个队列,这个队列就是死信队列。
DLX也是一个正常的Exchange,和一般的Exchange没有区别,它能在任何的队列上被指定,实际上就是设置某个队列的属性。
当这个队列中有死信时,RabbitMQ就会自动的将这个消息重新发布到设置的Exchange上去,进而被路由到另一个队列。
RocketMQ
阿里巴巴双十一官方指定消息产品,支撑阿里巴巴集团所有的消息服务,历经十余年高可用与高可靠的严苛考验,是阿里巴巴交易链路的核心产品。
Rocket:火箭的意思。

RocketMQ的核心概念
他有以下核心概念:Broker 、 Topic 、 Tag 、 MessageQueue 、 NameServer 、 Group 、 Offset 、 Producer 以及 Consumer 。
下面来详细介绍。
-
Broker:消息中转角色,负责存储消息,转发消息。
Broker是具体提供业务的服务器,单个Broker节点与所有的NameServer节点保持长连接及心跳,并会定时将Topic信息注册到NameServer,顺带一提底层的通信和连接都是基于Netty实现的。
Broker负责消息存储,以Topic为纬度支持轻量级的队列,单机可以支撑上万队列规模,支持消息推拉模型。官网上有数据显示:具有上亿级消息堆积能力,同时可严格保证消息的有序性。 -
Topic:主题!它是消息的第一级类型。
比如一个电商系统可以分为:交易消息、物流消息等,一条消息必须有一个 Topic 。Topic与生产者和消费者的关系非常松散,一个 Topic 可以有0个、1个、多个生产者向其发送消息,一个生产者也可以同时向不同的 Topic 发送消息。一个 Topic 也可以被 0个、1个、多个消费者订阅。 -
Tag:标签!可以看作子主题,它是消息的第二级类型,用于为用户提供额外的灵活性。
使用标签,同一业务模块不同目的的消息就可以用相同Topic而不同的Tag来标识。比如交易消息又可以分为:交易创建消息、交易完成消息等,一条消息可以没有Tag。标签有助于保持您的代码干净和连贯,并且还可以为RabbitMQ提供的查询系统提供帮助。 -
MessageQueue:一个Topic下可以设置多个消息队列,发送消息时执行该消息的Topic,RocketMQ会轮询该Topic下的所有队列将消息发出去。消息的物理管理单位。一个Topic下可以有多个Queue,Queue的引入使得消息的存储可以分布式集群化,具有了水平扩展能力。
-
NameServer:类似Kafka中的ZooKeeper,但NameServer集群之间是没有通信的,相对ZK来说更加轻量。
它主要负责对于源数据的管理,包括了对于Topic和路由信息的管理。每个Broker在启动的时候会到NameServer注册,Producer在发送消息前会根据Topic去NameServer获取对应Broker的路由信息,Consumer也会定时获取 Topic 的路由信息。 -
Producer:生产者,支持三种方式发送消息:同步、异步和单向。
单向发送 :消息发出去后,可以继续发送下一条消息或执行业务代码,不等待服务器回应,且没有回调函数。
异步发送 :消息发出去后,可以继续发送下一条消息或执行业务代码,不等待服务器回应,有回调函数。
同步发送 :消息发出去后,等待服务器响应成功或失败,才能继续后面的操作。 -
Consumer:消费者,支持 PUSH 和 PULL 两种消费模式,支持集群消费和**广播消费
集群消费 :该模式下一个消费者集群共同消费一个主题的多个队列,一个队列只会被一个消费者消费,如果某个消费者挂掉,分组内其它消费者会接替挂掉的消费者继续消费。
广播消费 :会发给消费者组中的每一个消费者进行消费。相当于RabbitMQ**的发布订阅模式。 -
Group:分组,一个组可以订阅多个Topic。
分为ProducerGroup,ConsumerGroup,代表某一类的生产者和消费者,一般来说同一个服务可以作为Group,同一个Group一般来说发送和消费的消息都是一样的 -
Offset:在RocketMQ中,所有消息队列都是持久化,长度无限的数据结构,所谓长度无限是指队列中的每个存储单元都是定长,访问其中的存储单元使用Offset来访问,Offset为Java Long类型,64位,理论上在 100年内不会溢出,所以认为是长度无限。也可以认为Message Queue是一个长度无限的数组,Offset就是下标。
延时消息
开源版的RocketMQ不支持任意时间精度,仅支持特定的level,例如定时5s,10s,1min等。其中,level=0级表示不延时,level=1表示1级延时,level=2表示2级延时,以此类推。
延时等级如下:
PHP
messageDelayLevel=1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h
顺序消息
消息有序指的是可以按照消息的发送顺序来消费(FIFO)。RocketMQ可以严格的保证消息有序,可以分为 分区有序 或者 全局有序 。
事务消息

消息队列MQ提供类似X/Open XA的分布式事务功能,通过消息队列MQ事务消息能达到分布式事务的最终一致。上图说明了事务消息的大致流程:正常事务消息的发送和提交、事务消息的补偿流程。
事务消息发送及提交:
- 发送half消息
- 服务端响应消息写入结果
- 根据发送结果执行本地事务(如果写入失败,此时half消息对业务不可见,本地逻辑不执行);
- 根据本地事务状态执行Commit或Rollback(Commit操作生成消息索引,消息对消费者可见)。
事务消息的补偿流程:
- 对没有Commit/Rollback的事务消息(pending状态的消息),从服务端发起一次“回查”;
- Producer收到回查消息,检查回查消息对应的本地事务的状态。
- 根据本地事务状态,重新Commit或RollBack
其中,补偿阶段用于解决消息Commit或Rollback发生超时或者失败的情况。
事务消息状态:
事务消息共有三种状态:提交状态、回滚状态、中间状态:
- TransactionStatus.CommitTransaction:提交事务,它允许消费者消费此消息。
- TransactionStatus.RollbackTransaction:回滚事务,它代表该消息将被删除,不允许被消费。
- TransactionStatus.Unkonwn:中间状态,它代表需要检查消息队列来确定消息状态。
RocketMQ的高可用机制
RocketMQ是天生支持分布式的,可以配置主从以及水平扩展。
Master角色的Broker支持读和写,Slave角色的Broker仅支持读,也就是 Producer只能和Master角色的Broker连接写入消息;Consumer可以连接 Master角色的Broker,也可以连接Slave角色的Broker来读取消息。
消息消费的高可用(主从):
在Consumer的配置文件中,并不需要设置是从Master读还是从Slave读,当Master不可用或者繁忙的时候,Consumer会被自动切换到从Slave读。有了自动切换Consumer这种机制,当一个Master角色的机器出现故障后,Consumer仍然可以从Slave读取消息,不影响Consumer程序。
在4.5版本之前如果Master节点挂了,Slave节点是不能自动切换成master节点的这个时候需要手动停止Slave角色的Broker,更改配置文件,用新的配置文件启动Broker。但是在4.5之后,RocketMQ引入了Dledger同步机制,这个时候如果Master节点挂了,Dledger会通过Raft协议选举出新的master节点,不需要手动修改配置。
消息发送高可用(配置多个主节点):
在创建Topic的时候,把Topic的多个Message Queue创建在多个Broker组上(相同Broker名称,不同 brokerId的机器组成一个Broker组),这样当一个Broker组的Master不可用后,其他组的Master仍然可用,Producer仍然可以发送消息。
主从复制:
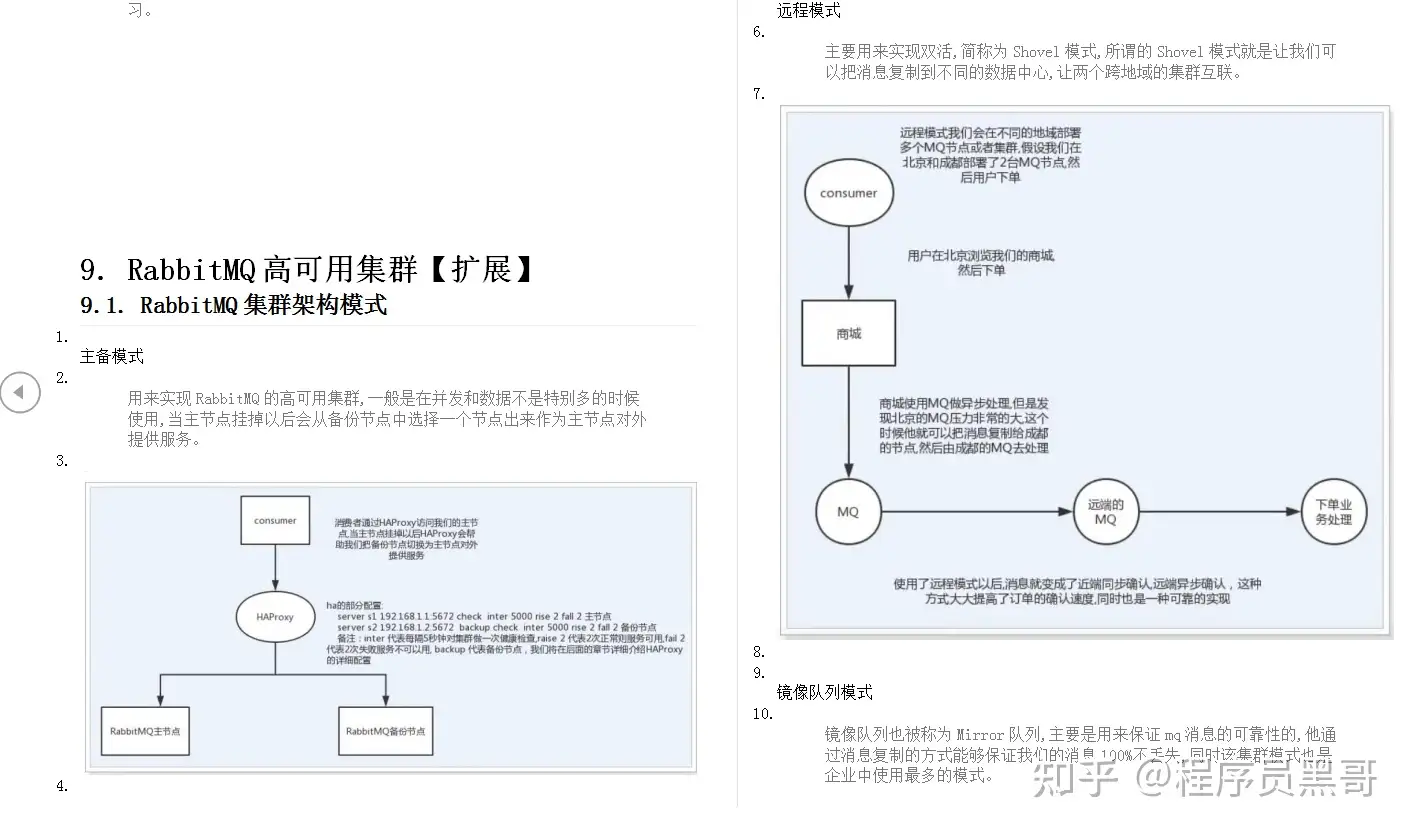
如果一个Broker组有Master和Slave,消息需要从Master复制到Slave 上,有同步和异步两种复制方式。
- 同步复制:同步复制方式是等Master和Slave均写成功后才反馈给客户端写成功状态。如果Master出故障, Slave上有全部的备份数据,容易恢复同步复制会增大数据写入延迟,降低系统吞吐量。
- 异步复制:异步复制方式是只要Master写成功 即可反馈给客户端写成功状态。在异步复制方式下,系统拥有较低的延迟和较高的吞吐量,但是如果Master出了故障,有些数据因为没有被写 入Slave,有可能会丢失
通常情况下,应该把Master和Slave配置成同步刷盘方式,主从之间配置成异步的复制方式,这样即使有一台机器出故障,仍然能保证数据不丢,是个不错的选择。
负载均衡
Producer负载均衡:
Producer端,每个实例在发消息的时候,默认会轮询所有的Message Queue发送,以达到让消息平均落在不同的Queue上。而由于Queue可以散落在不同的Broker,所以消息就发送到不同的Broker下,如下图:

Consumer负载均衡:
如果Consumer实例的数量比Message Queue的总数量还多的话,多出来的Consumer实例将无法分到Queue,也就无法消费到消息,也就无法起到分摊负载的作用了。所以需要控制让Queue的总数量大于等于Consumer的数量。
- 消费者的集群模式:启动多个消费者就可以保证消费者的负载均衡(均摊队列)
- 默认使用的是均摊队列:会按照Queue的数量和实例的数量平均分配Queue给每个实例,这样每个消费者可以均摊消费的队列,如下图所示6个队列和三个生产者。
- 另外一种平均的算法环状轮流分Queue的形式,每个消费者,均摊不同主节点的一个消息队列,如下图所示:
对于广播模式并不是负载均衡的,要求一条消息需要投递到一个消费组下面所有的消费者实例,所以也就没有消息被分摊消费的说法。
死信队列
当一条消息消费失败,RocketMQ就会自动进行消息重试。而如果消息超过最大重试次数,RocketMQ就会认为这个消息有问题。但是此时,RocketMQ不会立刻将这个有问题的消息丢弃,而会将其发送到这个消费者组对应的一种特殊队列:死信队列。死信队列的名称是 %DLQ%+ConsumGroup 。
死信队列具有以下特性:
- 一个死信队列对应一个Group ID, 而不是对应单个消费者实例。
- 如果一个Group ID未产生死信消息,消息队列RocketMQ不会为其创建相应的死信队列。
- 一个死信队列包含了对应Group ID产生的所有死信消息,不论该消息属于哪个Topic。
Kafka
Kafka是一个分布式、支持分区的、多副本的,基于ZooKeeper协调的分布式消息系统。
新版Kafka已经不再需要ZooKeeper。
它最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于Hadoop的批处理系统、低延迟的实时系统、Storm/Spark流式处理引擎,Web/Nginx日志、访问日志,消息服务等等,用Scala语言编写。属于Apache基金会的顶级开源项目。
先看一下Kafka的架构图 :

Kafka的核心概念
在Kafka中有几个核心概念:
- Broker:消息中间件处理节点,一个Kafka节点就是一个Broker,一个或者多个Broker可以组成一个Kafka集群
- Topic:Kafka根据topic对消息进行归类,发布到Kafka集群的每条消息都需要指定一个topic
- Producer:消息生产者,向Broker发送消息的客户端
- Consumer:消息消费者,从Broker读取消息的客户端
- ConsumerGroup:每个Consumer属于一个特定的ConsumerGroup,一条消息可以被多个不同的ConsumerGroup消费,但是一个ConsumerGroup中只能有一个Consumer能够消费该消息
- Partition:物理上的概念,一个topic可以分为多个partition,每个partition内部消息是有序的
- Leader:每个Partition有多个副本,其中有且仅有一个作为Leader,Leader是负责数据读写的Partition。
- Follower:Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步。如果Leader失效,则从Follower中选举出一个新的Leader。当Follower与Leader挂掉、卡住或者同步太慢,Leader会把这个Follower从 ISR列表 中删除,重新创建一个Follower。
- Offset:偏移量。Kafka的存储文件都是按照offset.kafka来命名,用Offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。
可以这么来理解Topic,Partition和Broker:
一个Topic,代表逻辑上的一个业务数据集,比如订单相关操作消息放入订单Topic,用户相关操作消息放入用户Topic,对于大型网站来说,后端数据都是海量的,订单消息很可能是非常巨量的,比如有几百个G甚至达到TB级别,如果把这么多数据都放在一台机器上可定会有容量限制问题,那么就可以在Topic内部划分多个Partition来分片存储数据,不同的Partition可以位于不同的机器上,相当于分布式存储。每台机器上都运行一个Kafka的进程Broker。
Kafka核心总控制器Controller
在Kafka集群中会有一个或者多个Broker,其中有一个Broker会被选举为控制器(Kafka Controller),可以理解为 Broker-Leader ,它负责管理整个 集群中所有分区和副本的状态。
PHP
Partition-Leader
Controller选举机制
在Kafka集群启动的时候,选举的过程是集群中每个Broker都会尝试在ZooKeeper上创建一个 /controller临时节点,ZooKeeper会保证有且仅有一个Broker能创建成功,这个Broker就会成为集群的总控器Controller。
当这个Controller角色的Broker宕机了,此时ZooKeeper临时节点会消失,集群里其他Broker会一直监听这个临时节 点,发现临时节点消失了,就竞争再次创建临时节点,就是我们上面说的选举机制,ZooKeeper又会保证有一个Broker成为新的Controller。具备控制器身份的Broker需要比其他普通的Broker多一份职责,具体细节如下:
- 监听Broker相关的变化。为ZooKeeper中的/brokers/ids/节点添加BrokerChangeListener,用来处理Broker增减的变化。
- 监听Topic相关的变化。为ZooKeeper中的/brokers/topics节点添加TopicChangeListener,用来处理Topic增减的变化;为ZooKeeper中的/admin/delete_topics节点添加TopicDeletionListener,用来处理删除Topic的动作。
- 从ZooKeeper中读取获取当前所有与Topic、Partition以及Broker有关的信息并进行相应的管理 。对于所有Topic所对应的ZooKeeper中的/brokers/topics/节点添加PartitionModificationsListener,用来监听Topic中的分区分配变化。
- 更新集群的元数据信息,同步到其他普通的Broker节点中
Partition副本选举Leader机制
Controller感知到分区Leader所在的Broker挂了,Controller会从ISR列表(参数 unclean.leader.election.enable=false的前提下)里挑第一个Broker作为Leader(第一个Broker最先放进ISR列表,可能是同步数据最多的副本),如果参数unclean.leader.election.enable为true,代表在ISR列表里所有副本都挂了的时候可以在ISR列表以外的副本中选Leader,这种设置,可以提高可用性,但是选出的新Leader有可能数据少很多。副本进入ISR列表有两个条件:
- 副本节点不能产生分区,必须能与ZooKeeper保持会话以及跟Leader副本网络连通
- 副本能复制Leader上的所有写操作,并且不能落后太多。(与Leader副本同步滞后的副本,是由replica.lag.time.max.ms配置决定的,超过这个时间都没有跟Leader同步过的一次的副本会被移出ISR列表)
消费者消费消息的Offset记录机制
每个Consumer会定期将自己消费分区的Offset提交给Kafka内部Topic:consumer_offsets,提交过去的时候,key是consumerGroupId+topic+分区号,value就是当前Offset的值,Kafka会定期清理Topic里的消息,最后就保留最新的那条数据。
因为__consumer_offsets可能会接收高并发的请求,Kafka默认给其分配50个分区(可以通过 offsets.topic.num.partitions设置),这样可以通过加机器的方式抗大并发。
消费者Rebalance机制
Rebalance就是说 如果消费组里的消费者数量有变化或消费的分区数有变化,Kafka会重新分配消费者与消费分区的关系 。比如consumer group中某个消费者挂了,此时会自动把分配给他的分区交给其他的消费者,如果他又重启了,那么又会把一些分区重新交还给他。
注意:Rebalance只针对subscribe这种不指定分区消费的情况,如果通过assign这种消费方式指定了分区,Kafka不会进行Rebalance。
如下情况可能会触发消费者Rebalance:
- 消费组里的Consumer增加或减少了
- 动态给Topic增加了分区
- 消费组订阅了更多的Topic
Rebalance过程中,消费者无法从Kafka消费消息,这对Kafka的TPS会有影响,如果Kafka集群内节点较多,比如数百 个,那重平衡可能会耗时极多,所以应尽量避免在系统高峰期的重平衡发生。
Rebalance过程如下
当有消费者加入消费组时,消费者、消费组及组协调器之间会经历以下几个阶段:

第一阶段:选择组协调器
组协调器GroupCoordinator:每个consumer group都会选择一个Broker作为自己的组协调器coordinator,负责监控这个消费组里的所有消费者的心跳,以及判断是否宕机,然后开启消费者Rebalance。consumer group中的每个consumer启动时会向Kafka集群中的某个节点发送FindCoordinatorRequest请求来查找对应的组协调器GroupCoordinator,并跟其建立网络连接。组协调器选择方式:通过如下公式可以选出consumer消费的Offset要提交到__consumer_offsets的哪个分区,这个分区Leader对应的Broker就是这个consumer group的coordinator公式:
hash(consumer group id) % 对应主题的分区数
第二阶段:加入消费组JOIN GROUP
在成功找到消费组所对应的GroupCoordinator之后就进入加入消费组的阶段,在此阶段的消费者会向GroupCoordinator发送JoinGroupRequest请求,并处理响应。然后GroupCoordinator从一个consumer group中选择第一个加入group的consumer作为Leader(消费组协调器),把consumer group情况发送给这个Leader,接着这个Leader会负责制定分区方案。
第三阶段(SYNC GROUP)
consumer leader通过给GroupCoordinator发送SyncGroupRequest,接着GroupCoordinator就把分区方案下发给各个consumer,他们会根据指定分区的Leader Broker进行网络连接以及消息消费。
消费者Rebalance分区分配策略
主要有三种Rebalance的策略:range 、 round-robin 、 sticky 。默认情况为range分配策略。
假设一个主题有10个分区(0-9),现在有三个consumer消费:
range策略:按照分区序号排序分配 ,假设n=分区数/消费者数量 = 3, m=分区数%消费者数量 = 1,那么前 m 个消 费者每个分配 n+1 个分区,后面的(消费者数量-m )个消费者每个分配 n 个分区。比如分区0~ 3给一个consumer,分区4~ 6给一个consumer,分区7~9给一个consumer。
round-robin策略:轮询分配 ,比如分区0、3、6、9给一个consumer,分区1、4、7给一个consumer,分区2、5、 8给一个consumer
sticky策略:初始时分配策略与round-robin类似,但是在rebalance的时候,需要保证如下两个原则:
- 分区的分配要尽可能均匀 。
- 分区的分配尽可能与上次分配的保持相同。
当两者发生冲突时,第一个目标优先于第二个目标 。这样可以最大程度维持原来的分区分配的策略。比如对于第一种range情况的分配,如果第三个consumer挂了,那么重新用sticky策略分配的结果如下:consumer1除了原有的0~ 3,会再分配一个7 consumer2除了原有的4~ 6,会再分配8和9。
Producer发布消息机制剖析
1、写入方式
producer采用push模式将消息发布到broker,每条消息都被append到patition中,属于顺序写磁盘(顺序写磁盘 比 随机写 效率要高,保障 kafka 吞吐率)。
2、消息路由
producer发送消息到broker时,会根据分区算法选择将其存储到哪一个partition。其路由机制为:
PHP
hash(key)%分区数
3、写入流程

- producer先从ZooKeeper的 "/brokers/…/state" 节点找到该partition的leader
- producer将消息发送给该leader
- leader将消息写入本地log
- followers从leader pull消息,写入本地log后向leader发送ACK
- leader收到所有ISR中的replica的ACK后,增加HW(high watermark,最后commit的offset)并向producer发送ACK
HW与LEO
HW俗称高水位 ,HighWatermark的缩写,取一个partition对应的ISR中最小的LEO(log-end-offset)作为HW, consumer最多只能消费到HW所在的位置。另外每个replica都有HW,leader和follower各自负责更新自己的HW的状 态。对于leader新写入的消息,consumer不能立刻消费,leader会等待该消息被所有ISR中的replicas同步后更新HW, 此时消息才能被consumer消费。这样就保证了如果leader所在的broker失效,该消息仍然可以从新选举的leader中获取。对于来自内部broker的读取请求,没有HW的限制。
日志分段存储
Kafka一个分区的消息数据对应存储在一个文件夹下,以topic名称+分区号命名,消息在分区内是分段存储的, 每个段的消息都存储在不一样的log文件里,Kafka规定了一个段位的log文件最大为1G,做这个限制目的是为了方便把log文件加载到内存去操作:
PHP
1 ### 部分消息的offset索引文件,kafka每次往分区发4K(可配置)消息就会记录一条当前消息的offset到index文件,
2 ### 如果要定位消息的offset会先在这个文件里快速定位,再去log文件里找具体消息
3 00000000000000000000.index
4 ### 消息存储文件,主要存offset和消息体
5 00000000000000000000.log
6 ### 消息的发送时间索引文件,kafka每次往分区发4K(可配置)消息就会记录一条当前消息的发送时间戳与对应的offset到timeindex文件,
7 ### 如果需要按照时间来定位消息的offset,会先在这个文件里查找
8 00000000000000000000.timeindex
9
10 00000000000005367851.index
11 00000000000005367851.log
12 00000000000005367851.timeindex
13
14 00000000000009936472.index
15 00000000000009936472.log
16 00000000000009936472.timeindex
这个9936472之类的数字,就是代表了这个日志段文件里包含的起始 Offset,也就说明这个分区里至少都写入了接近1000万条数据了。Kafka Broker有一个参数,log.segment.bytes,限定了每个日志段文件的大小,最大就是1GB。一个日志段文件满了,就自动开一个新的日志段文件来写入,避免单个文件过大,影响文件的读写性能,这个过程叫做log rolling,正在被写入的那个日志段文件,叫做active log segment。
最后附一张ZooKeeper节点数据图

MQ带来的一些问题、及解决方案
如何保证顺序消费?
- RabbitMQ:一个Queue对应一个Consumer即可解决。
- RocketMQ:hash(key)%队列数
- Kafka:hash(key)%分区数
如何实现延迟消费?
- RabbitMQ:两种方案 死信队列 + TTL引入RabbitMQ的延迟插件
- RocketMQ:天生支持延时消息。
- Kafka:步骤如下 专门为要延迟的消息创建一个Topic新建一个消费者去消费这个Topic消息持久化再开一个线程定时去拉取持久化的消息,放入实际要消费的Topic实际消费的消费者从实际要消费的Topic拉取消息。

如何保证消息的可靠性投递
RabbitMQ:
- Broker-->消费者:手动ACK
- 生产者-->Broker:两种方案
数据库持久化:
PHP
1.将业务订单数据和生成的Message进行持久化操作(一般情况下插入数据库,这里如果分库的话可能涉及到分布式事务)
2.将Message发送到Broker服务器中
3.通过RabbitMQ的Confirm机制,在producer端,监听服务器是否ACK。
4.如果ACK了,就将Message这条数据状态更新为已发送。如果失败,修改为失败状态。
5.分布式定时任务查询数据库3分钟(这个具体时间应该根据的时效性来定)之前的发送失败的消息
6.重新发送消息,记录发送次数
7.如果发送次数过多仍然失败,那么就需要人工排查之类的操作。

优点:能够保证消息百分百不丢失。
缺点:第一步会涉及到分布式事务问题。
消息的延迟投递:
PHP
流程图中,颜色不同的代表不同的message
1.将业务订单持久化
2.发送一条Message到broker(称之为主Message),再发送相同的一条到不同的队列或者交换机(这条称为确认Message)中。
3.主Message由实际业务处理端消费后,生成一条响应Message。之前的确认Message由Message Service应用处理入库。
4~6.实际业务处理端发送的确认Message由Message Service接收后,将原Message状态修改。
7.如果该条Message没有被确认,则通过rpc调用重新由producer进行全过程。

优点:相对于持久化方案来说响应速度有所提升
缺点:系统复杂性有点高,万一两条消息都失败了,消息存在丢失情况,仍需Confirm机制做补偿。
RocketMQ
生产者弄丢数据:
Producer在把Message发送Broker的过程中,因为网络问题等发生丢失,或者Message到了Broker,但是出了问题,没有保存下来。针对这个问题,RocketMQ对Producer发送消息设置了3种方式:
PHP
同步发送
异步发送
单向发送
Broker弄丢数据:
Broker接收到Message暂存到内存,Consumer还没来得及消费,Broker挂掉了。
可以通过 持久化 设置去解决:
- 创建Queue的时候设置持久化,保证Broker持久化Queue的元数据,但是不会持久化Queue里面的消息
- 将Message的deliveryMode设置为2,可以将消息持久化到磁盘,这样只有Message支持化到磁盘之后才会发送通知Producer ack
这两步过后,即使Broker挂了,Producer肯定收不到ack的,就可以进行重发。
消费者弄丢数据:
Consumer有消费到Message,但是内部出现问题,Message还没处理,Broker以为Consumer处理完了,只会把后续的消息发送。这时候,就要 关闭autoack,消息处理过后,进行手动ack , 多次消费失败的消息,会进入 死信队列 ,这时候需要人工干预。
Kafka
生产者弄丢数据
设置了 acks=all ,一定不会丢,要求是,你的 leader 接收到消息,所有的 follower 都同步到了消息之后,才认为本次写成功了。如果没满足这个条件,生产者会自动不断的重试,重试无限次。
Broker弄丢数据
Kafka 某个 broker 宕机,然后重新选举 partition 的 leader。大家想想,要是此时其他的 follower 刚好还有些数据没有同步,结果此时 leader 挂了,然后选举某个 follower 成 leader 之后,不就少了一些数据?这就丢了一些数据啊。
此时一般是要求起码设置如下 4 个参数:
PHP
replication.factor
min.insync.replicas
acks=all
retries=MAX
我们生产环境就是按照上述要求配置的,这样配置之后,至少在 Kafka broker 端就可以保证在 leader 所在 broker 发生故障,进行 leader 切换时,数据不会丢失。
消费者弄丢数据
你消费到了这个消息,然后消费者那边自动提交了 offset,让 Kafka 以为你已经消费好了这个消息,但其实你才刚准备处理这个消息,你还没处理,你自己就挂了,此时这条消息就丢咯。
这不是跟 RabbitMQ 差不多吗,大家都知道 Kafka 会自动提交 offset,那么只要 关闭自动提交 offset,在处理完之后自己手动提交 offset,就可以保证数据不会丢。但是此时确实还是可能会有重复消费,比如你刚处理完,还没提交 offset,结果自己挂了,此时肯定会重复消费一次,自己保证幂等性就好了。
如何保证消息的幂等?
以 RocketMQ 为例,下面列出了消息重复的场景:
发送时消息重复
当一条消息已被成功发送到服务端并完成持久化,此时出现了网络闪断或者客户端宕机,导致服务端对客户端应答失败。如果此时生产者意识到消息发送失败并尝试再次发送消息,消费者后续会收到两条内容相同并且Message ID也相同的消息。
投递时消息重复
消息消费的场景下,消息已投递到消费者并完成业务处理,当客户端给服务端反馈应答的时候网络闪断。为了保证消息至少被消费一次,消息队列RocketMQ版的服务端将在网络恢复后再次尝试投递之前已被处理过的消息,消费者后续会收到两条内容相同并且Message ID也相同的消息。
负载均衡时消息重复(包括但不限于网络抖动、Broker重启以及消费者应用重启)
当消息队列RocketMQ版的Broker或客户端重启、扩容或缩容时,会触发Rebalance,此时消费者可能会收到重复消息。
那么,有什么解决方案呢?直接上图。

如何解决消息积压的问题?
关于这个问题,有几个点需要考虑:
如何快速让积压的消息被消费掉?
临时写一个消息分发的消费者,把积压队列里的消息均匀分发到N个队列中,同时一个队列对应一个消费者,相当于消费速度提高了N倍。
修改前:

修改后:

积压时间太久,导致部分消息过期,怎么处理?
批量重导。在业务不繁忙的时候,比如凌晨,提前准备好程序,把丢失的那批消息查出来,重新导入到MQ中。
消息大量积压,MQ磁盘被写满了,导致新消息进不来了,丢掉了大量消息,怎么处理?
这个没办法。谁让【消息分发的消费者】写的太慢了,你临时写程序,接入数据来消费,消费一个丢弃一个,都不要了,快速消费掉所有的消息。然后走第二个方案,到了晚上再补数据吧。
=====================

Kafka是一种分布式流处理平台,最初由LinkedIn公司开发,现在是Apache软件基金会的顶级项目之一。它主要用于处理实时数据流,包括实时数据摄取、转换、处理和传输。Kafka设计为可扩展、持久化和高吞吐量的消息队列系统。

Kafka的核心概念包括topic、partition、producer、consumer和broker等。
● Topic是Kafka中的基本单元,用于对消息进行分类和组织。Producer将消息发送到topic,而consumer则从topic中读取消息。

● Partition是topic的物理划分,每个partition对应一个磁盘文件。每个partition可以分布在不同的broker上,以实现分布式存储和处理。

● Producer是向topic发送消息的客户端,可以将消息发送到特定的partition或让Kafka自动选择partition。

● Consumer是从topic中读取消息的客户端,可以订阅一个或多个topic,并从partition中读取消息。

● Broker是Kafka集群中的一台服务器,负责存储和处理partition中的消息。

在实际应用中,Kafka可以用于日志收集、数据流处理、消息系统和实时数据分析等场景。

Kafka的实战操作可以分为以下几个步骤:
安装启动Kafka
STEP 1: GET KAFKA
Download the latest Kafka release and extract it:
$ tar -xzf kafka_2.13-3.5.0.tgz
$ cd kafka_2.13-3.5.0
STEP 2: START THE KAFKA ENVIRONMENT
NOTE: Your local environment must have Java 8+ installed.
Apache Kafka can be started using ZooKeeper or KRaft. To get started with either configuration follow one the sections below but not both.
Kafka with ZooKeeper
Run the following commands in order to start all services in the correct order:
# Start the ZooKeeper service
$ bin/zookeeper-server-start.sh config/zookeeper.properties
Open another terminal session and run:
# Start the Kafka broker service
$ bin/kafka-server-start.sh config/server.properties
Once all services have successfully launched, you will have a basic Kafka environment running and ready to use.
Kafka with KRaft
Generate a Cluster UUID
$ KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"
Format Log Directories
$ bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties
Start the Kafka Server
$ bin/kafka-server-start.sh config/kraft/server.properties
Once the Kafka server has successfully launched, you will have a basic Kafka environment running and ready to use.
STEP 3: CREATE A TOPIC TO STORE YOUR EVENTS
Kafka is a distributed event streaming platform that lets you read, write, store, and process events (also called records or messages in the documentation) across many machines.
Example events are payment transactions, geolocation updates from mobile phones, shipping orders, sensor measurements from IoT devices or medical equipment, and much more. These events are organized and stored in topics. Very simplified, a topic is similar to a folder in a filesystem, and the events are the files in that folder.
So before you can write your first events, you must create a topic. Open another terminal session and run:
$ bin/kafka-topics.sh --create --topic quickstart-events --bootstrap-server localhost:9092
All of Kafka's command line tools have additional options: run the kafka-topics.sh command without any arguments to display usage information. For example, it can also show you details such as the partition count of the new topic:
$ bin/kafka-topics.sh --describe --topic quickstart-events --bootstrap-server localhost:9092
Topic: quickstart-events TopicId: NPmZHyhbR9y00wMglMH2sg PartitionCount: 1 ReplicationFactor: 1 Configs:
Topic: quickstart-events Partition: 0 Leader: 0 Replicas: 0 Isr: 0
STEP 4: WRITE SOME EVENTS INTO THE TOPIC
A Kafka client communicates with the Kafka brokers via the network for writing (or reading) events. Once received, the brokers will store the events in a durable and fault-tolerant manner for as long as you need—even forever.
Run the console producer client to write a few events into your topic. By default, each line you enter will result in a separate event being written to the topic.
$ bin/kafka-console-producer.sh --topic quickstart-events --bootstrap-server localhost:9092
This is my first event
This is my second event
You can stop the producer client with Ctrl-C at any time.
STEP 5: READ THE EVENTS
Open another terminal session and run the console consumer client to read the events you just created:
$ bin/kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server localhost:9092
This is my first event
This is my second event
You can stop the consumer client with Ctrl-C at any time.
Feel free to experiment: for example, switch back to your producer terminal (previous step) to write additional events, and see how the events immediately show up in your consumer terminal.
Because events are durably stored in Kafka, they can be read as many times and by as many consumers as you want. You can easily verify this by opening yet another terminal session and re-running the previous command again.
STEP 6: IMPORT/EXPORT YOUR DATA AS STREAMS OF EVENTS WITH KAFKA CONNECT
You probably have lots of data in existing systems like relational databases or traditional messaging systems, along with many applications that already use these systems. Kafka Connect allows you to continuously ingest data from external systems into Kafka, and vice versa. It is an extensible tool that runs connectors, which implement the custom logic for interacting with an external system. It is thus very easy to integrate existing systems with Kafka. To make this process even easier, there are hundreds of such connectors readily available.
In this quickstart we'll see how to run Kafka Connect with simple connectors that import data from a file to a Kafka topic and export data from a Kafka topic to a file.
First, make sure to add connect-file-3.5.0.jar to the plugin.path property in the Connect worker's configuration. For the purpose of this quickstart we'll use a relative path and consider the connectors' package as an uber jar, which works when the quickstart commands are run from the installation directory. However, it's worth noting that for production deployments using absolute paths is always preferable. See plugin.path for a detailed description of how to set this config.
Edit the config/connect-standalone.properties file, add or change the plugin.path configuration property match the following, and save the file:
> echo "plugin.path=libs/connect-file-3.5.0.jar"
Then, start by creating some seed data to test with:
> echo -e "foo\nbar" > test.txt
Or on Windows:
> echo foo> test.txt
> echo bar>> test.txt
Next, we'll start two connectors running in standalone mode, which means they run in a single, local, dedicated process. We provide three configuration files as parameters. The first is always the configuration for the Kafka Connect process, containing common configuration such as the Kafka brokers to connect to and the serialization format for data. The remaining configuration files each specify a connector to create. These files include a unique connector name, the connector class to instantiate, and any other configuration required by the connector.
> bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties config/connect-file-sink.properties
These sample configuration files, included with Kafka, use the default local cluster configuration you started earlier and create two connectors: the first is a source connector that reads lines from an input file and produces each to a Kafka topic and the second is a sink connector that reads messages from a Kafka topic and produces each as a line in an output file.
During startup you'll see a number of log messages, including some indicating that the connectors are being instantiated. Once the Kafka Connect process has started, the source connector should start reading lines from test.txt and producing them to the topic connect-test, and the sink connector should start reading messages from the topic connect-test and write them to the file test.sink.txt. We can verify the data has been delivered through the entire pipeline by examining the contents of the output file:
> more test.sink.txt
foo
bar
Note that the data is being stored in the Kafka topic connect-test, so we can also run a console consumer to see the data in the topic (or use custom consumer code to process it):
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic connect-test --from-beginning
{"schema":{"type":"string","optional":false},"payload":"foo"}
{"schema":{"type":"string","optional":false},"payload":"bar"}
...
The connectors continue to process data, so we can add data to the file and see it move through the pipeline:
> echo Another line>> test.txt
You should see the line appear in the console consumer output and in the sink file.
STEP 7: PROCESS YOUR EVENTS WITH KAFKA STREAMS
Once your data is stored in Kafka as events, you can process the data with the Kafka Streams client library for Java/Scala. It allows you to implement mission-critical real-time applications and microservices, where the input and/or output data is stored in Kafka topics. Kafka Streams combines the simplicity of writing and deploying standard Java and Scala applications on the client side with the benefits of Kafka's server-side cluster technology to make these applications highly scalable, elastic, fault-tolerant, and distributed. The library supports exactly-once processing, stateful operations and aggregations, windowing, joins, processing based on event-time, and much more.
To give you a first taste, here's how one would implement the popular WordCount algorithm:
KStream<String, String> textLines = builder.stream("quickstart-events");
KTable<String, Long> wordCounts = textLines
.flatMapValues(line -> Arrays.asList(line.toLowerCase().split(" ")))
.groupBy((keyIgnored, word) -> word)
.count();
wordCounts.toStream().to("output-topic", Produced.with(Serdes.String(), Serdes.Long()));
The Kafka Streams demo and the app development tutorial demonstrate how to code and run such a streaming application from start to finish.
STEP 8: TERMINATE THE KAFKA ENVIRONMENT
Now that you reached the end of the quickstart, feel free to tear down the Kafka environment—or continue playing around.
- Stop the producer and consumer clients with
Ctrl-C, if you haven't done so already. - Stop the Kafka broker with
Ctrl-C. - Lastly, if the Kafka with ZooKeeper section was followed, stop the ZooKeeper server with
Ctrl-C.
If you also want to delete any data of your local Kafka environment including any events you have created along the way, run the command:
$ rm -rf /tmp/kafka-logs /tmp/zookeeper /tmp/kraft-combined-logs
CONGRATULATIONS!
You have successfully finished the Apache Kafka quickstart.
To learn more, we suggest the following next steps:
- Read through the brief Introduction to learn how Kafka works at a high level, its main concepts, and how it compares to other technologies. To understand Kafka in more detail, head over to the Documentation.
- Browse through the Use Cases to learn how other users in our world-wide community are getting value out of Kafka.
- Join a local Kafka meetup group and watch talks from Kafka Summit, the main conference of the Kafka community.
- 安装和配置Kafka:可以从Apache官网下载Kafka安装包,并按照官方文档进行安装和配置。需要配置zookeeper、broker和topic等参数。

\2. 创建和管理topic:可以使用Kafka提供的命令行工具或API创建、删除和管理topic。
\3. 编写Producer和Consumer客户端程序:可以使用Java、Python、Go等编程语言编写Producer和Consumer客户端程序。在程序中需要指定要连接的broker、topic、partition等参数,并实现消息的发送和接收逻辑。

\4. 部署和监控Kafka集群:在实际应用中,Kafka集群通常需要部署在多台服务器上,需要进行监控和调优。可以使用第三方工具如Kafka Manager、Prometheus等进行集群管理和监控。

总之,Kafka是一款强大的分布式消息队列系统,可以实现高性能、可扩展和可靠的数据流处理。熟练掌握Kafka的原理和实战操作,对于实时数据处理和分析等领域有着重要的应用价值。

为大家推荐 Apache Kafka实战,写的非常好,很适合作为开发学习教程,希望对大家有所帮助!
代码实现-Kafka Consumer
需求:使用flink-connector-kafka_2.12中的FlinkKafkaConsumer消费Kafka中的数据做WordCount
需要设置如下参数:
1.订阅的主题
2.反序列化规则
3.消费者属性-集群地址
4.消费者属性-消费者组id(如果不设置,会有默认的,但是默认的不方便管理)
5.消费者属性-offset重置规则,如earliest/latest...
6.动态分区检测(当kafka的分区数变化/增加时,Flink能够检测到!)
7.如果没有设置Checkpoint,那么可以设置自动提交offset,后续学习了Checkpoint会把offset随着做Checkpoint的时候提交到Checkpoint和默认主题中
代码实现:
public class ConnectorsDemo_KafkaConsumer {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.Source
Properties props = new Properties();
props.setProperty("bootstrap.servers", "node01:9092");
props.setProperty("group.id", "flink");
props.setProperty("auto.offset.reset","latest");
props.setProperty("flink.partition-discovery.interval-millis","5000");//会开启一个后台线程每隔5s检测一下Kafka的分区情况
props.setProperty("enable.auto.commit", "true");
props.setProperty("auto.commit.interval.ms", "2000");
//kafkaSource就是KafkaConsumer
FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<>("flink_kafka", new SimpleStringSchema(), props);
kafkaSource.setStartFromGroupOffsets();//设置从记录的offset开始消费,如果没有记录从auto.offset.reset配置开始消费
//kafkaSource.setStartFromEarliest();//设置直接从Earliest消费,和auto.offset.reset配置无关
DataStreamSource<String> kafkaDS = env.addSource(kafkaSource);
//3.Transformation
//3.1切割并记为1
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOneDS = kafkaDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] words = value.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1));
}
}
});
//3.2分组
KeyedStream<Tuple2<String, Integer>, Tuple> groupedDS = wordAndOneDS.keyBy(0);
//3.3聚合
SingleOutputStreamOperator<Tuple2<String, Integer>> result = groupedDS.sum(1);
//4.Sink
result.print();
//5.execute
env.execute();
}
}
代码实现-Kafka Producer
需求:
将Flink集合中的数据通过自定义Sink保存到Kafka
代码实现
/**
* 使用自定义sink-官方提供的flink-connector-kafka_2.12-将数据保存到Kafka
*/
public class ConnectorsDemo_KafkaProducer {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.Source
DataStreamSource<Student> studentDS = env.fromElements(new Student(1, "tonyma", 18));
//3.Transformation
//注意:目前来说我们使用Kafka使用的序列化和反序列化都是直接使用最简单的字符串,所以先将Student转为字符串
//可以直接调用Student的toString,也可以转为JSON
SingleOutputStreamOperator<String> jsonDS = studentDS.map(new MapFunction<Student, String>() {
@Override
public String map(Student value) throws Exception {
//String str = value.toString();
String jsonStr = JSON.toJSONString(value);
return jsonStr;
}
});
//4.Sink
jsonDS.print();
//根据参数创建KafkaProducer/KafkaSink
Properties props = new Properties();
props.setProperty("bootstrap.servers", "node1:9092");
FlinkKafkaProducer<String> kafkaSink = new FlinkKafkaProducer<>("flink_kafka", new SimpleStringSchema(), props);
jsonDS.addSink(kafkaSink);
//5.execute
env.execute();
// /export/server/kafka/bin/kafka-console-consumer.sh --bootstrap-server node1:9092 --topic flink_kafka
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class Student {
private Integer id;
private String name;
private Integer age;
}
}
Kafka源码解析与实战
Kafka的架构
包括Kafka的基本组成,Kafka的拓扑结构以及Kafka的内部通信协议。Kafka内部的通信协议是建立在Kafka的拓扑结构之上,而Kafka的拓扑结构是由Kafka的基本模块所组成的。
AK RELEASE 2.5.0
APRIL 15, 2020
Kafka的基本组成
Kafka集群中生产者将消息发送给以Topic命名的消息队列Queue中,消费者订阅发往以某个Topic命名的消息队列Queue中的消息。其中Kafka集群由若干个Broker组成,Topic由若干个Partition组成,每个Partition里的消息通过Offset来获取。
基本组成包括:
- Broker:一台Kafka服务器就是一个Broker,一个集群由多个Broker组成,一个Broker可以容纳多个Topic,Broker和Broker之间没有Master和Standby的概念,他们之间地位是平等的
- Topic:每条发送到Kafka集群的消息都属于某个主题,这个主题就称为Topic。物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存在一个或多个Broker上,但是用户只需指定消息主题Topic即可生产或消费数据而不需要关心数据存放在何处。
- Partition:为了实现可扩展性,一个非常大的Topic可以被分为多个Partition,从而分布到多台Broker上。Partition中的每条消息都会被分配一个自增Id(Offset)。Kafka只保证按照一个Partition中的顺序将消息发送给消费者,但是不保证单个Topic中多个Partition之间的顺序。
- Offset:消息在Topic的Partition中的位置,同一个Partition中的消息随着消息的写入其对应的Offset也自增。
- Replica:副本,Topic的Partition有N个副本,N为副本因子。其中一个Replica为Leader,其他都为Follower,Leader处理Partition的所有读写请求,Follower定期同步Leader上的数据。
- Message:消息是通信的基本单位。每个Producer可以向一个Topic发布消息
- Producer:消息生产者,将消息发布到指定的Topic中,也能够决定消息所属的Partition:比如基于Round-Robin或者Hash算法
- Consumer:消息消费者,向指定的Topic获取消息,根据指定Topic的分区索引及其对应分区上的消息偏移量来获取消息
- Consumer Group:消费者组,每个消费者都属于一个组。当消费者具有相同组时,消息会在消费者之间负载均衡。一个Partition的消息只会被相同消费者组中的某个消费者消费。不同消费者组是相互独立的。
- Zookeeper:存放Kafka集群相关元数据的组件。Zookeeper集群中保存了Topic的状态信息,例如分区个数、分区组成、分区的分布情况等;保存Broker的状态信息;保存消费者的消费信息等。通过这些信息,Kafka很好地将消息生产、消息存储、消息消费的过程结合起来。
Kafka的拓扑结构
一个典型的Kafka集群中包含若干个Producer(可以是某个模块下发的Command,或者是Web前端产生的PageView,或者是服务器日志,系统CPU、Memory等),若干个Broker(Kafka集群支持水平扩展,一般Broker数量越多,整个Kafka集群的吞吐率也就越高),若干个Consumer Group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置。Producer使用Push模式将消息发布到Broker上,Consumer使用Pull模式从Broker上订阅并消费消息。
简单的消息发送流程如下:
- Producer根据指定的路由方法,将消息Push到Topic的某个Partition里
- Kafka集群接收到Producer发过来的消息并持久化到硬盘,并保留消息指定时长(可配置),不关注消息是否被消费。
- Consumer从Kafka集群Pull数据,并控制获取消息的Offset
Kafka内部的通信协议
Kafka内部各个Broker之间的角色并不是完全相等的,Broker内部负责管理分区和副本状态以及异常情况下分区的重新分片等这些功能的模块称为KafkaController。每个Kafka集群中有且只有一个Leader状态的KafkaController,当其出现异常时,其余Standby状态的KafkaController会通过Zookeeper选举出有一个Leader状态的KafkaController。
维度一:通信协议详情
- ProducerRequest:生产者发送消息的请求,生产者将消息发送至Kafka集群中的某个Broker,Broker接收到此请求后持久化此消息并更新相关元数据信息。
ProducerRequest.requiredAcks的取值为0时,生产者不关心Broker Server端持久化执行结果,但是高级消费者发送的提交偏移量的请求还是需要返回具体执行结果。为1则生产者消费者都需要将Broker Server端持久化的执行结果返回客户端。为-1时,不会立刻返回Broker Server端消息持久化的结果,而是需要等待Partition的ISR列表中的Replica完成数据同步,并且ISR列表的个数大于min.insync.replicas时才会将响应返回给对应客户端。这里采用的是称为Purgatory的策略。Broker Server上对应的Partition的HighWatermark发生改变才触发检查。 - TopicMetadataRequest:获取Topic元数据信息的请求,无论是生产者还是消费者都需要通过此请求来获取感兴趣的Topic的元数据。
- FetchRequest:消费者获取Topic的某个分区的消息的请求。分区状态为Follower的副本也需要利用此请求去同步分区状态为Leader的对应副本数据。
- OffsetRequest:消费者发送至Kafka集群来获取感兴趣Topic的分区偏移量的请求,通过此请求可以获知当前Topic所有分区在不同时间段的偏移量详情。
- OffsetCommitRequest:消费者提交Topic被消费的分区偏移量信息至Broker,Broker接收到此请求后持久化相关偏移量信息。
- OffsetFetchRequest:消费者发送获取提交至Kafka集群的相关Topic被消费详细信息,和OffsetCommitRequest相互对应。
- LeaderAndIsrRequest:当Topic的某个分区状态发送变化时,处于Leader状态的KafkaController发送至相关Broker通知其做出相应处理。
当某个Replica称为Leader:暂停Fetch→添加进Assigned Replica列表→添加进In-Sync Replica列表→删除已经不存在的Assigned Replica→初始化Leader Replica的HighWatermark
当某个Replica成为Follower:暂停旧的Fetch线程→截断数据至HighWatermark以下→开启新的Fetch线程→添加进Assigned Replica列表→删除已经不存在的Assigned Replica - StopReplicaRequest:当Topic的某个分区被删除或者下线的时候,处于Leader状态KafkaController发送至相关Broker通知其做出相应处理。
- UpdateMetadataRequest:当Topic的元数据信息发生变化时,处于Leader状态的KafkaController发送至相关Broker通知其做出相应处理。
- BrokerControllerShutdownRequest:当Broker正常下线时,发送此请求到处于Leader状态的KafkaController。
- ConsumerMetadataRequest:获取保存特定Consumer Group消费详情的分区信息
维度二:通信协议交互
- Producer和Kafka集群:Producer需要利用ProducerRequest和TopicMetadataRequest来完成Topic元数据的查询、消息的发送。
- Consumer和Kafka集群:Consumer需要利用TopicMetadataRequest请求、FetchRequest请求、OffsetRequest、OffsetCommitRequest、OffsetFetchRequest、ConsumerMetadataRequest来完成Topic元数据的查询、消息的订阅、历史偏移量的查询、偏移量的提交、当前偏移量的查询。
- KafkaController状态为Leader的Broker和KafkaController状态为Standby的Broker:Leader需要用LeaderAndIsrRequest、StopReplicaRequest、UpdateMetadataRequest来完成对Topic的管理。Standby需要利用BrokerControllerShutdownRequest来通知Leader自己的下线动作。
- Broker和Broker之间:Broker相互之间需要利用FetchRequest请求来同步Topic分区的副本数据,这样才能使Topic分区各副本数据保持一致。
Broker概述
Broker内部存在的功能模块包括SocketServer、KafkaRequestHandlerPool、LogManager、ReplicaManager、OffsetManager、KafkaScheduler、KafkaApis、KafkaHealthcheck和TopicConfigManager九大基本模块以及KafkaController集群控制管理模块。
- SocketServer:首先开启一个Acceptor线程,新的Socket连接成功建立时会将对应的SocketChannel以轮询方式转发给N个Processor线程中的某一个,由其处理接下来SocketChannel的请求,将请求放置在RequestChannel中的请求队列;当Processor线程监听到SocketChannel请求的响应时,会将响应从RequestChannel中的响应队列中取出来并发给客户端
- KafkaRequestHandlerPool:真正处理Socket请求的线程池,其个数默认为8个,由参数num.io.threads决定。该线程池里面的线程KafkaRequestHandler从RequestChannel的请求队列中获取Socket请求,然后调用KafkaApis完成真正业务逻辑最后将响应写回至RequestChannel中的响应队列,并交给SocketServer中对应的Processer线程发给客户端。
- LogManager:Kafka的日志管理模块,主要提供针删除任何过期数据和冗余数据,刷新脏数据,对日志文件进行Checkpoint以及日志合并的功能。
负责提供Broker Server上Topic的分区数据读取和写入功能,负责读取和写入位于Broker Server上的所有分区副本数据。如果Partition有多个Replica,则每个Broker Server不会存在相同Partition的Replica,如果存在一旦遇到Broker Server下线会丢失Partition的多份副本可用性降低。
LogManager中包含多个TopicAndPartition,每个TopicAndPartition对应一个Log,每个Log中包含多个LogSegment(每个LogSegment文件包括一个日志数据文件【.log】和两个索引文件(偏移量索引文件【.index】和消息时间戳索引文件【.timeindex】))。LogSegment的结构中log代表消息集合,每条消息都有一个Offset,这是针对Partition中的偏移量;index代表的是消息的索引信息,以KV对的形式记录,其中K为消息在log中的相对偏移量,V为消息在log中的绝对位置;baseOffset代表的是该LogSegment日志段的起始偏移量;indexIntervalByte代表的索引粒度,即写入多少字节之后生成一条索引。OffsetIndex不会保存每条消息的索引,因此其索引文件是一个稀疏索引文件(稀疏索引:索引项中只对应主文件中的部分记录,即不会给每条记录建立索引)。
后台还会维护一个日志合并线程,Kafka发送消息的时候需要携带3个参数(Topic,Key,Message),针对相同的Key值不同的Message只保留最后一个Key值对应的消息内容。
- ReplicaManager:Kafka副本管理模块。主要提供针对Topic分区副本数据的管理功能,包括有关副本的Leader和ISR的状态变化、副本的删除、副本的监测等。ISR全称是In-Syn Replicas,处于同步状态的副本。AR全称是Assign Replicas的缩写,代表分配给Partition的副本。
主要利用ReplicaFetcherThread(副本数据拉取线程)和High Watermark Mechanism(高水位线机制)来实现数据的同步管理。单个ReplicaFetcherThread线程负责某个Broker Server上部分TopicAndPartition的Replica数据同步。将拉取的消息写入log,更新当前Replica的HighWatermark,代表的是ISR中所有replicas的last commited message的最小起始偏移量。当某个Broker Server上被分配到Replica的时候会进入becomeLeaderOrFollower处理流程;当Replica被删除为进入stopReplicas处理流程;当Follower状态的Replica长时间没有同步Leader状态的Replica的时候会进入maybeShrinkIsr处理流程。 - OffsetManager:Kafka的偏移量管理模块,主要提供针对偏移量的保存读取的功能,两种方式保存:一种是把偏移量保存到Zookeeper上,另一种是Kafka,把偏移量提交至Kafka内部Topic为"__consumer_offsets"的日志里面,主要由offsets.storage参数决定。默认为Zookeeper。
- KafkaScheduler:Kafka的后台任务调度资源池。提供后台定时任务的调度,主要为LogManager、ReplicaManager、OffsetManager提供调度服务。
- KafkaApis:Kafka的业务逻辑实现层,根据不同的Request执行不同的操作,其中利用LogManager、ReplicaManager、OffsetManager来完成内部处理。
- KafkaHealthcheck:Broker Server在./brokers/ids上注册自己的ID,当Broker在线的时候,则对应的ID存在;当离线时对应ID不存在,从而达到集群状态监测的目的。
- TopicConfigManager:在/config/changes上注册自己的回调函数来监测Topic配置信息的变化
- KafkaController:Kafka集群控制管理模块。由于Zookeeper上保存了Kafka机器的元数据信息,因为KafkaController通过在不同目录注册不同的回调函数来达到监测集群状态的目的,以及响应集群状态的变化:
- /controller目录保存了Kafka集群中状态为Leader的KafkaController标识,通过监测这个目录的变化可以即使响应KafkaController状态的切换
- /admin/reassign_partitions目录保存了Topic重分区的信息,通过监测这个目录的变化可以及时响应Topic分区变化的请求
- /admin/preferred_replica_election目录保存了Topic分区副本的信息,通过监测这个目录的变化可以及时响应Topic分区副本变化的请求。
- /brokers/topics目录保存了Topic的信息,通过监测这个目录的变化可以及时响应Topic创建和删除的请求。
- /brokers/ids目录保存了Broker的状态,通过监测这个目录的变化可以及时响应Broker的上下线情况。
Broker的控制管理模块
每个Broker内部都会存在一个KafkaController模块,但是有且只有一个Broker内部的KafkaController模块对外提供控制管理Kafka集群的功能,例如负责Topic的创建、分区的重分配以及分区副本Leader的重新选举等。
KafkaController的选举策略
Leader和Follower的选举是基于Zookeeper实现的,尝试在Zookeeper的相同路径上创建瞬时节点(Ephemeral Node),只有一个KafkaController会创建成功。其中负责状态管理的类为ZookeeperLeaderElector,字面意思上就可以看出是基于Zookeeper的Leader选举权。其中包含了controllerContext当前Topic的元数据信息以及集群的元数据信息等;electionPath为多个KafkaController竞争写的路径,其值为/controller;onBecomingLeader为状态转化成Leader时候的回调函数;onResigningAsLeader为状态转化位Follower时候的回调函数;brokerId为当前Broker Server的Id。ZookeeperLeaderElector启动后负责观察数据节点状态,瞬时节点消失触发再次选举,尝试写入的节点内容就是brokerId。
KafkaController的初始化
当选举为Leader时分为下面几步:
- 初始化Kafka集群内部的时钟,存放在Zookeeper的/controller_epoch,Broker Server用这个值区分请求的时效性
- 注册各种监听函数,针对Zookeeper不同目录下Kafka存储的不同元数据进行监听。
- 通过initializeControllerContext()、replicaStateMachine.startup()和partitionStateMachine.startup()初始化Kafka集群内部元数据信息。建立和集群内其他状态为Follower的KafkaController的通信链路,处理集群启动前没有及时处理的用户请求,此时可能会变更Kafka集群内部的元数据信息,最后通过sendUpdateMetadataRequest()将Kafka集群内部的元数据信息同步给其他状态为Follower的KafkaController。
- 根据auto.leader.rebalance.enable配置项按需启动Kafka集群内部的负载均衡线程,默认开启
- 根据delete.topic.enable配置项按需启动Kafka集群内部的Topic删除线程,默认关闭
选举为Follower的时候分为下面几步,正好与Controller相反:
- 取消Zookeeper路径上的监听函数
- 根据delete.topic.enable配置项按需启动Kafka集群内部的Topic删除线程,默认关闭
- 关闭Kafka集群内部的负载均衡线程
- 断开和集群内其他状态为Follower的KafkaController的通信线路
- 重置集群内部时钟
Topic的分区状态转化机制
Topic的分区状态维护是由PartitionStateMachine模块负责的,通过在/brokers/topics 和 /admin/delete_topics目录上注册不同的监听函数,监听Topic的创建和删除事件触发Topic分区状态的转换。
PartitionStateMachine中分区状态由PartitionState用一个字节表示不同状态,分为四种:
- NonExistentPartition:代表分区从来没有被创建或者被创建之后又被删除呃状态
- NewPartition:分区刚创建包含AR,但是此时Leader或ISR还没有创建,处于非活动状态无法接收数据
- OnlinePartition:分区Leader已经被选举,产生来对应的ISR,处于活动状态可以接收数据
- OfflinePartition:代表分区Leader由于某种原因下线时导致分区暂时不可用
每个状态都是由一个合理的前置状态转换而来。
Topic分区的领导者副本选举策略
Topic分区的Leader Replica在不同场景下的选举策略是不一样的,不同选举策略都基础PartitionLeaderSelector。其根据Topic、Partition、当前Leader、当前的ISR选举出新的Leader,新的ISR和新的AR(在线状态),共有5种不同的策略:
- NoOpLeaderSelector:默认的选举策略
- ReassignedPartitionLeaderSelector:当分区AR重新分配时使用的策略
- PreferredReplicaPartitionLeaderSelector:集群内部自动平衡负载或者用户触发手动平衡负载时使用的策略
随着Topic的新建删除以及Broker Server的上下线,原本Topic分区的Leader Replica在集群中的分布越来越不均匀。 auto.leader.rebalance.enable为true,则会自动触发分区的Leader Replica选举,或者管理员下发分区Leader Replica选举指令。这会在Zookeeper的 /admin/preferred_replica_election指定具体的Topic和分区,此时Leader状态的KafkaController监测到这个路径的数据变化就会触发相应的回调函数,促使对应的Topic分区发生Leader Replica的选举。 - OfflinePartitionLeaderSelector:分区状态从OfflinePartition或者NewPartition切换为OnlinePartition时使用的策略
- 筛选出在线的ISR和AR
- 优先从在线的ISR中选择,如果列表不为空则选择列表中的第一个,选举结束
- 在线ISR为空,根据 unclean.leader.election.enable 决定是否从在线的AR中选举Leader,如果允许,则选择AR列表中的第一个,结束选举,如果AR列表为空选举失败。
- ControllerShutdownLeaderSelector:Leader状态的KafkaController处理其他Broker Server下线导致分区的Leader Replica发生切换时使用的策略。
- 筛选出在线的ISR
- 剔除离线的ISR形成新的ISR列表
- 如果新的ISR列表不为空,则选举第一个Replica作为新的Leader,否则选举失败
Topic分区的副本状态转换机制
Topic分区的副本状态维护是由ReplicaStateMachine模块负责的,Topic分区的副本状态伴随着Topic分区状态的变化而变化
分区副本状态只要有7种:
- NewReplica:分区刚被分配但是没有开始工作的状态
- OnlineReplica:分区副本开始工作时的状态,此时该副本时该分区的Leader或者Follower
- OfflineReplica:分区副本所在的Broker Server宕机时所导致的副本状态
- ReplicaDeletionStarted:分区副本下线之后准备开始删除的状态
- ReplicaDeletionSuccessful:相关Broker Server正确响应分区副本被删除请求之后的状态
- ReplicaDeletionIneligible:相关Broker Server错误响应分区副本被删除请求之后的状态
- NonExistentReplica:代表分区副本被彻底删除之后的状态
目标状态也是由合理的前置状态转换而来的。
KafkaController内部的监听器
KafkaController内部通过监听函数来维护集群的元数据。
- TopicChangeListener:注册在 /broker/topics 路径,监听Topic的创建
- AddPartitionListener:在Topic创建过程中会在 /broker/topics/[topic]目录下注册AddPartitionListener用于监听Topic分区的变化
- PartitionReassignedListener:KafkaController转换为Leader的过程中在路径 /admin/reassign_partitions注册了PartitionReassignedListener用于监听Topic分区的重分配。在正式启动重分配之前会判断是否需要进行重分配,重分配之后的AR列表和当前的AR列表不相同并且重分配之后的AR列表所在的Broker Server都在线,满足上面两个条件才会触发分区的重分配。
- ReassignedPartitionsIsrChangeListener:当Leader Replica所在的Broker Server接收到来自Follower Replica的FetchRequest请求时,KafkaApis的handleFetchRequest会统计每个Replica的状态,一旦发现改Replica同步上Leader Replica之后,此时会调用Partition的updateLeaderHWAndMaybeExpandIsr及时更新 /brokers/topics/[topic]/partitions/partitionId/state/ 目录上的Partition状态,包括Leader、ISR等信息,监听到分区状态发生变化会触发ReassignedPartitionsIsrChangeListener
- PreferredReplicaElectionListener:每个Partition可以有多个Replica,即AR列表。在这个列表中的第一个Replica称为“Preferred Replica”,当创建Topic时,Kafka要确保所有的Topic的“Preferred Replica”均匀地分布在Kafka集群中。Topic的Partition需要重新均衡Leader Replica至Preferred Replica,此时会触发PreferredReplicaElectionListener
- BrokerChangeListener:Broker Server的上下线影响着其中所有Replica的状态,因此ReplicaStateMachine在路径为/broker/topic的路径上注册了BrokerChangeListener,用于监听Broker Server的上下线。
Broker Server上线时步骤为:
- Leader状态的KafkaController同步Kafka集群所有的Topic信息给新上线的Broker Server。
- 将原本位于该Broker Server上的所有Replica状态切换至OnlineReplica
- 如果Partition的Replica有且只有一个,并且正好位于Broker Server上,则切换Partition状态至OnlinePartition。
- 如果分区重分配之前由于该Broker Server下线导致推出的话,则尝试重新进行分区重分配。
- 如果之前由于Broker Server下线导致对应的Replica无法删除的话,则恢复删除流程。
Broker Server下线步骤: - 更新ControllerContext内部正在下线的Broker Server列表
- 将Leader Replica位于该Broker Server上的分区状态切换为OnlinePartition,紧接着触发分区状态切换为OnlinePartition,利用OfflinePartitionLeaderSelector副本选举策略进行Leader Replica的选举。
- 将位于该Broker Server上的Replica状态切换为OfflineReplica
- 如果对应Replica的Topic处于删除队列中的话,则标记暂时无法删除。
- DeleteTopicsListener:监听Topic的删除
Kafka集群的负载均衡流程
Partition的AR列表的第一个Replica称为“Preferred Replica”,并均匀分布在整个Kafka集群中。由于每个Partition只有Leader Replica对外提供读写服务,并且Partition创建的时候默认的Leader Replica位于Preferred Replica之上,此时Kafka集群的负载是均衡的,如果Kafka集群长时间运行,Broker Server中途由于异常而发生重启,此时Partition的Leader Replica会发生迁移,这样会导致其Partition的Leader Replica在集群中不再均衡了。
Kafka集群的Topic删除流程
Topic是由Partition组成的,而Partition是由Replica组成的,因此只有Partition的Assigned Replica全部被删除了该Partition才可以被删除;只有Topic的所有Partition都被删除了,该Topic才可以最终真正的被删除。
KafkaController的通信模块
ControllerChannelManager提供了Leader状态的KafkaController和集群其他Broker Server通信的功能,内部针对每一个在线的Broker Server会维护一个通信链路,并分别通过各自的RequestSendThread线程将请求发送给对应的Broker Server。
Topic管理工具
kafka-topics.sh提供了Topic的创建、修改、列举、描述、删除功能,在内部时通过TopicCommand类来实现的。
kafka-reassign-partitions.sh提供来重新分配分区副本的能力。该工具可以促进Kafka集群的负载均衡。因为Follower Replica需要从Leader Replica Fetch数据以保持与与Leader Replica同步,仅保持Leader Replica分布的平衡对整个集群的负载均衡时不够的。另外当Kafka集群扩容后,该工具可以将已有Topic的Partition迁移到新加入的Broker上。
分区重分片是一个异步的流程,因此该脚本还提供了查看当前分区重分配进度的指令。
kafka-preferred-replica-election.sh用于在整个集群中恢复Leader Replica为Preferred Replica。
生产者
生产者是指消息的生成者。生产者可以通过特定的分区函数决定消息路由到Topic的某个分区。消息的生产者发送消息有两种模式,分别为同步模式和异步模式。
kafka.javaapi.producer.Producer#send方法发送
指定 metadata.broker.list 属性,配置Broker地址
指定 partitioner.class 属性,配置分区函数,分区函数决定路由。分区函数必须实现 kafka.producer.Partitioner的 partition接口,参数为消息key值,分区总数,返回值为分区的索引。
Producer内部包括以下几个主要模块:
- ProducerSendThread:当producer.type配置为async,则其主要用于缓存客户端的KeyedMessage,然后累积到batch.num.messages配置数量或者间隔 queue.enqueue.timeout.ms配置的时间还没有获取到新的客户端的KeyedMessage,则调用DefaultEventHandler将KeyedMessage发送出去
- ProducerPool:缓存客户端和各个Broker Server的通信,DefaultEventHandler从ProducerPool中获取和某个Broker Server的通信对象SyncProducer,然后通过SyncProducer将KeyedMessage发送给指定的Broker Server。
- DefaultEventHandler:将KeyedMessage集合按照分区规则计算不同Broker Server所应该接收的部分KeyedMessage,然后通过SyncProducer将KeyedMessage发送出去。在DefaultEventHandler模块内部提供来SyncProducer发送失败的重试机制和平滑扩容Broker Server的机制。
发送模式
生产者由两种发送模式:同步和异步
当producer.type配置为sync时,同步发送消息。
当producer.type配置为async时,异步发送消息。
消费者
Kafka提供了两种不同的方式来获取消息:简单消费者和高级消费者。简单消费者获取消息时,用户需要知道待消费的消息位于哪个Topic的哪个分区,并且该目的分区的Leader Replica位于哪个Broker Server上;高级消费者获取消息时,只需要指定待消费的消息属于哪个Topic即可。
简单消费者
简单消费者提供的客户端API称为低级API,本质上客户端获取消息最终时利用FetchRequest请求从目的端Broker Server拉取消息。
FetchRequest请求中可以指定Topic的名称,Topic的分区,起始偏移量、最大字节数。
客户端无论生产消息还是消费消息,最终都是通过与目的地端Broker Server建立通信链路,并且以阻塞模式允许,然后通过该条链路将不同的请求发送出去。
高级消费者
高级消费者以Consumer Group(消费组)的形式来管理消息的消费,以Stream(流)的形式来提供具体消息的读取。Stream是指来自若干个Broker Server上的若干个Partition的消息。客户端需要正确设置Stream的个数,并且应该针对每个Stream开启一个线程进行消息的消费。一个Stream代表了多个Partition消息的聚合,但是每一个Partition只能映射到一个Stream。
消息的最终获取是通过遍历KafkaStream的迭代器ConsumerIterator来逐条获取的,其数据来源于分配给该KafkaStream的阻塞消息队列BlockingQueue,而BlockingQueue的数据来源针对每个Broker Server的FetchThread线程。FetchThread线程会将Broker Server上的部分Partition数据发送给对应的阻塞消息队列BlockingQueue,而KafkaStream正是从该阻塞消息队列BlockingQueue中不断的消费消息。
ConsumerThread本质上是客户端的消费线程,消费若干个Partition上的数据,并且与BlockingQueueu相互映射,只要确定了ConsumerThread和Partition之间的关系,也就确定了BlockingQueue和Partition之间的关系。Kafka提供了两种ConsumerThread和Partition的分配算法Range(范围分区分配)和RoundRobin(循环分区分配)
高级消费者中,每个具体消费者实例启动之后会在/consumers/[group]/ids/的Zookeeper目录下注册自己的id;Kafka集群内部Topic会在/brokers/topics/[topic]/的Zookeeper目录下注册自己的Partition,因此消费者实例一旦发现以上2个路径的数据发生变化时,则会触发高级消费者的负载均衡流程,除此之外,消费者实例一旦和Zookeeper的链接重新建立时也会触发高级消费者的负载均衡流程。
高级消费者内部针对Zookeeper的连接建立、Topic的Partition变化、Consumer的新增会建立3个不同的Listener,分别是ZKSessionExpireListener、ZKTopicPartitionChangeListener和ZKRebalancerListener。
高级消费者消费消息时提供了两种持久化偏移量的机制,由参数auto.commit.enable,默认为true自动提交。否则需要手动调用ZookeeperConsumerConnector的commitOffsets。Kafka根据参数offsets.storage,默认为zookeeper(保存路径为/consumers/[group]/offset/[topic]/[partition]),可以设置为kafka(保存再Topic为“__consumer_offsets”的日志中)。高级消费者内部会自动间隔一定时间(由参数 auto.commit.interval.ms决定,默认60*1000ms)
面试相关
kafka高吞吐量的原因:
一、顺序读写磁盘,充分利用了操作系统的预读机制。
二、linux中使用sendfile命令,减少一次数据拷贝,如下。
①把数据从硬盘读取到内核中的页缓存。
②把数据从内核中读取到用户空间。(sendfile命令将跳过此步骤)
③把用户空间中的数据写到socket缓冲区中。
④操作系统将数据从socket缓冲区中复制到网卡缓冲区,以便将数据经网络发出
三、生产者客户端缓存消息批量发送,消费者批量从broker获取消息,减少网络io次数,充分利用磁盘顺序读写的性能。
四、通常情况下kafka的瓶颈不是cpu或者磁盘,而是网络带宽,所以生产者可以对数据进行压缩。
kafka在高并发的情况下,如何避免消息丢失和消息重复?
消息丢失解决方案:
首先对kafka进行限速, 其次启用重试机制,重试间隔时间设置长一些,最后Kafka设置acks=all,即需要相应的所有处于ISR的分区都确认收到该消息后,才算发送成功
消息重复解决方案:
消息可以使用唯一id标识
生产者(ack=all 代表至少成功发送一次)
消费者 (offset手动提交,业务逻辑成功处理后,提交offset)
落表(主键或者唯一索引的方式,避免重复数据)
业务逻辑处理(选择唯一主键存储到Redis或者mongdb中,先查询是否存在,若存在则不处理;若不存在,先插入Redis或Mongdb,再进行业务逻辑处理)
kafka怎么保证数据消费一次且仅消费一次
幂等producer:保证发送单个分区的消息只会发送一次,不会出现重复消息
事务(transaction):保证原子性地写入到多个分区,即写入到多个分区的消息要么全部成功,要么全部回滚流处理EOS:流处理本质上可看成是“读取-处理-写入”的管道。此EOS保证整个过程的操作是原子性。注意,这只适用于Kafka Streams
kafka保证数据一致性和可靠性
数据一致性保证
一致性定义:若某条消息对client可见,那么即使Leader挂了,在新Leader上数据依然可以被读到
HW-HighWaterMark: client可以从Leader读到的最大msg offset,即对外可见的最大offset, HW=max(replica.offset)
对于Leader新收到的msg,client不能立刻消费,Leader会等待该消息被所有ISR中的replica同步后,更新HW,此时该消息才能被client消费,这样就保证了如果Leader fail,该消息仍然可以从新选举的Leader中获取。
对于来自内部Broker的读取请求,没有HW的限制。同时,Follower也会维护一份自己的HW,Folloer.HW = min(Leader.HW, Follower.offset)
数据可靠性保证
当Producer向Leader发送数据时,可以通过acks参数设置数据可靠性的级别
0: 不论写入是否成功,server不需要给Producer发送Response,如果发生异常,server会终止连接,触发Producer更新meta数据;
1: Leader写入成功后即发送Response,此种情况如果Leader fail,会丢失数据
-1: 等待所有ISR接收到消息后再给Producer发送Response,这是最强保证
kafka到spark streaming怎么保证数据完整性,怎么保证数据不重复消费?
保证数据不丢失(at-least)
spark RDD内部机制可以保证数据at-least语义。
Receiver方式
开启WAL(预写日志),将从kafka中接受到的数据写入到日志文件中,所有数据从失败中可恢复。
Direct方式
依靠checkpoint机制来保证。
保证数据不重复(exactly-once)
要保证数据不重复,即Exactly once语义。
- 幂等操作:重复执行不会产生问题,不需要做额外的工作即可保证数据不重复。
- 业务代码添加事务操作
就是说针对每个partition的数据,产生一个uniqueId,只有这个partition的所有数据被完全消费,则算成功,否则算失效,要回滚。下次重复执行这个uniqueId时,如果已经被执行成功,则skip掉。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号