
MapReduce编写的正确姿势
- 先看一下目录结构
这里是job接口,负责参数的传递和定时的调用
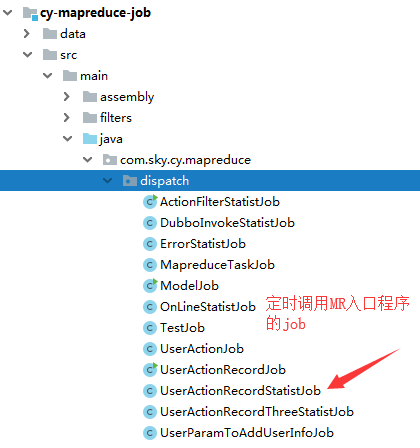
下面的图是MR 程序相关的目录图片,其中MR的入口程序负责读取数据,并指定对应的Map、Reduce程序。
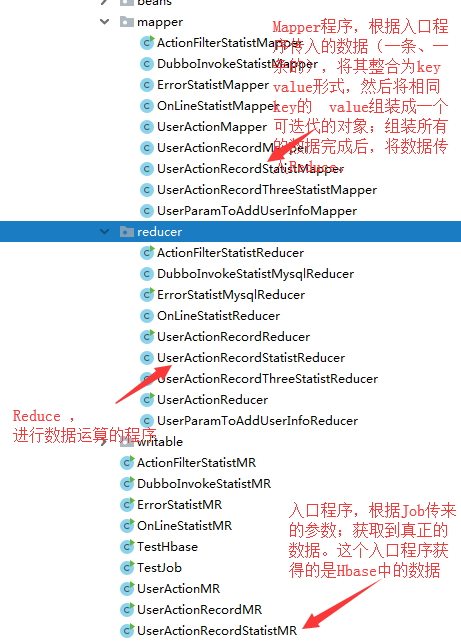
- 程序的流程
首先简单的说一下,整体的流程:
- 首先是一个Job(定时任务),定时调用 入口程序,拼装参数。
- job调用 MR的入口程序,入口程序获得job传入的参数,根据参数获得所需的数据;可以去Hbase、mysql、HDFS中获取数据;这个文件会配置job名、要调用的Mapper、Reduce,添加需要的jar包
- 数据传入Mapper程序,Mapper程序进行数据的整合,整合完成的数据会变成:key:{value1,value2,value3,...}这个样子,所以传入Reduce的value应该是一个可迭代的参数(在这里坑了一会)。Mapper将所有的数据整合完成后,会进入Reduce程序
- Reduce程序,接受参数,参数类型要和Mapper的返回类型是一样的;values 的入参是 一个可迭代的类型,泛型必须与Mapper的value返回类型一致。然后根据需求进行处理。
- 上代码
Job程序:
package com.sky.cy.mapreduce.dispatch; import com.sky.cy.mapreduce.util.BasicMapreduceJob; import com.ssports.util.LogFormat; import com.ssports.util.ToolUtil; import org.apache.commons.logging.Log; import org.apache.commons.logging.LogFactory; import org.springframework.stereotype.Component; import java.util.Date; /** * @描述: * @文件名: UserActionRecordStatistJob * @创建人: YangLianjun * @创建时间: 2019/4/2 9:58 * @修改人: * @修改备注: Copyright 北京和信金谷科技有限公司 2019/4/2 */ @Component public class UserActionRecordStatistJob extends BasicMapreduceJob { public static Log log = LogFactory.getLog(UserActionRecordStatistJob.class); @Override public String[] preProcessJob(String... args) { log.info(LogFormat.formatMsg("UserActionRecordStatistJob.preProcessJob","","UserActionRecordStatistJob is start")); String statTimeStr = ""; if (args != null && args.length == 1) { statTimeStr = args[0]; } else { Date date = ToolUtil.addDay(new Date(), -1); String statTime = ToolUtil.getDateStr(date, "yyyyMMdd"); // String statTime = "20190401"; log.info(LogFormat.formatMsg("UserActionRecordStatistJob.preProcessJob","statTime:"+statTime,"")); statTimeStr = statTime; } String[] retArgs = new String[2]; // 这个参数是指定哪个 MR入口程序 retArgs[0] = "com.sky.cy.mapreduce.job.UserActionRecordStatistMR" ; retArgs[1] = statTimeStr; return retArgs; } }
MR入口程序,负责数据的读取,指定对应的Map、Reduce程序:
package com.sky.cy.mapreduce.job; import com.sky.cy.mapreduce.job.mapper.UserActionRecordMapper; import com.sky.cy.mapreduce.job.mapper.UserActionRecordStatistMapper; import com.sky.cy.mapreduce.job.reducer.UserActionRecordReducer; import com.sky.cy.mapreduce.job.reducer.UserActionRecordStatistReducer; import com.sky.cy.mapreduce.util.BasicMapreduce; import com.ssports.util.LogFormat; import org.apache.commons.logging.Log; import org.apache.commons.logging.LogFactory; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.hbase.client.Scan; import org.apache.hadoop.hbase.filter.*; import org.apache.hadoop.hbase.mapreduce.MultiTableOutputFormat; import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil; import org.apache.hadoop.hbase.util.Bytes; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import java.io.IOException; /** * @描述: * @文件名: UserActionRecordStatistMR * @创建人: YangLianjun * @创建时间: 2019/4/2 14:47 * @修改人: * @修改备注: Copyright 北京和信金谷科技有限公司 2019/4/2 */ public class UserActionRecordStatistMR extends BasicMapreduce { public static final Log LOG = LogFactory.getLog(UserActionRecordStatistMR.class); public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { LOG.info(LogFormat.formatMsg("UserActionRecordStatistMR.main","","start ...")); init(); String statTime = args[0]; // 将日期作为查询条件 Filter filter = new SingleColumnValueFilter(Bytes.toBytes("f"),Bytes.toBytes("stat_time"), CompareFilter.CompareOp.EQUAL,Bytes.toBytes(statTime)) ; Scan scan = new Scan(); scan.setFilter(filter); Configuration configuration = defaultHbaseConfiguration(); configuration.set("statTime",statTime); Job job = Job.getInstance(configuration, "UserActionRecordStatistMR"); TableMapReduceUtil.initTableMapperJob(UserActionRecordStatistMR.Constants.HBASE_FILTER_TABLE, scan, UserActionRecordStatistMapper.class, Text.class, Text.class, job); job.setReducerClass(UserActionRecordStatistReducer.class); job.setNumReduceTasks(1); job.setOutputFormatClass(MultiTableOutputFormat.class); //添加mysql驱动包 job.addFileToClassPath(new Path(UserActionMR.Constants.MYSQL_JAR_PATH)); //添加spring的jar job.addFileToClassPath(new Path(ActionFilterStatistMR.Constants.SPRING_CONTEXT_JAR_PATH)); job.addFileToClassPath(new Path(ActionFilterStatistMR.Constants.SPRING_TX_JAR_PATH)); job.addFileToClassPath(new Path(ActionFilterStatistMR.Constants.SPRING_AOP_JAR_PATH)); job.addFileToClassPath(new Path(ActionFilterStatistMR.Constants.SPRING_BEAN_HADOOP_PATH)); job.addFileToClassPath(new Path(ActionFilterStatistMR.Constants.SPRING_DATA_HADOOP_PATH)); job.waitForCompletion(true); } public static class Constants { //需要获取的hbase数据的表名 public static final String HBASE_FILTER_TABLE = "sky_user_action_record"; } }
Map程序:
1 package com.sky.cy.mapreduce.job.mapper; 2 3 import com.sky.cy.mapreduce.util.HbaseUtil; 4 import com.sky.cy.mapreduce.util.RegexUtil; 5 import com.ssports.util.LogFormat; 6 import com.ssports.util.SpringHelper; 7 import com.ssports.util.ToolUtil; 8 import org.apache.commons.logging.Log; 9 import org.apache.commons.logging.LogFactory; 10 import org.apache.hadoop.hbase.client.Result; 11 import org.apache.hadoop.hbase.io.ImmutableBytesWritable; 12 import org.apache.hadoop.hbase.mapreduce.TableMapper; 13 import org.apache.hadoop.io.Text; 14 15 import java.io.IOException; 16 17 18 /** 19 * @描述: 20 * @文件名: UserActionRecordStatistMapper 21 * @创建人: YangLianjun 22 * @创建时间: 2019/4/2 14:46 23 * @修改人: 24 * @修改备注: Copyright 北京和信金谷科技有限公司 2019/4/2 25 */ 26 public class UserActionRecordStatistMapper extends TableMapper<Text, Text> { 27 private static final Log log = LogFactory.getLog(UserActionRecordStatistMapper.class); 28 public static final String FAMILY_F = "f"; 29 30 31 32 33 protected void map(ImmutableBytesWritable key, Result result, Context context) throws IOException, InterruptedException { 34 log.info(LogFormat.formatMsg("UserActionRecordStatistMapper.map", "", "mapper start ...")); 35 String userId = HbaseUtil.getValue(FAMILY_F, "user_id", result); 36 String actionName = HbaseUtil.getValue(FAMILY_F,"action_name",result) ; 37 String actionId = HbaseUtil.getValue(FAMILY_F,"action_id",result) ; 38 String statTime = context.getConfiguration().get("statTime"); 39 String keyOut = userId + ":" + statTime; 40 log.info(LogFormat.formatMsg("UserActionRecordStatistMapper.map", "keyOut:"+keyOut, "")); 41 Text text = new Text(keyOut); 42 String valueOut = actionId + ":"+actionName; 43 log.info(LogFormat.formatMsg("UserActionRecordStatistMapper.map", "valueOut:"+valueOut, "")); 44 Text value = new Text(valueOut); 45 context.write(text, value); 46 log.info(LogFormat.formatMsg("UserActionRecordStatistMapper.map", "", "mapper end ...")); 47 } 48 }
Reduce程序:
package com.sky.cy.mapreduce.job.reducer; import com.sky.cy.log.base.dao.SkyUserActionRecordStatistMapper; import com.ssports.util.LogFormat; import com.ssports.util.SpringHelper; import com.ssports.util.ToolUtil; import org.apache.commons.logging.Log; import org.apache.commons.logging.LogFactory; import org.apache.hadoop.hbase.mapreduce.TableReducer; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import java.io.IOException; import java.util.*; /** * @描述: * @文件名: UserActionRecordStatistReducer * @创建人: YangLianjun * @创建时间: 2019/4/2 14:47 * @修改人: * @修改备注: Copyright 北京和信金谷科技有限公司 2019/4/2 */ public class UserActionRecordStatistReducer extends TableReducer<Text, Text, NullWritable> { private static final Log log = LogFactory.getLog(UserActionRecordStatistReducer.class); private static final Integer ALL = 1 ; // 统计状态,全部统计 protected void setup(Context context) throws IOException, InterruptedException { SpringHelper.init("classpath*:spring/*.xml"); } protected void reduce(Text key, Iterable<Text> values, Context context){ log.info(LogFormat.formatMsg("UserActionRecordStatistReducer.reduce","","start ...")); String keyRow = new String(key.getBytes()); String[] keys = keyRow.split(":"); String userId = keys[0] ; log.info(LogFormat.formatMsg("UserActionRecordStatistReducer.reduce","userId:"+userId,"")); String statTime = keys[1] ; log.info(LogFormat.formatMsg("UserActionRecordStatistReducer.reduce", "key:"+keyRow, "")); List<String> actionList = new ArrayList<>(); for (Text value : values) { log.info(LogFormat.formatMsg("UserActionRecordStatistReducer.reduce", "value:"+value.toString(), "")); actionList.add(value.toString()) ; } SkyUserActionRecordStatistMapper mapper = SpringHelper.getBean("skyUserActionRecordStatistMapper") ; com.sky.cy.log.base.bean.SkyUserActionRecordStatistEntity entity = new com.sky.cy.log.base.bean.SkyUserActionRecordStatistEntity() ; Set<String> uniqueSet = new HashSet<>(actionList) ; for (String s : uniqueSet) { String actionId = s.split(":")[0] ; log.info(LogFormat.formatMsg("UserActionRecordStatistReducer.reduce","actionId:"+actionId,"")); String actionName = s.split(":")[1] ; int actionNumber = Collections.frequency(actionList, s) ; //统计出来数量 entity = mapper.selectTotalByIdAndType(userId,actionId,ALL) ; //查询全部统计 的信息 if (null == entity){ //不存在 这个信息,插入 log.info(LogFormat.formatMsg("UserActionRecordStatistReducer.reduce","","insert start ...")); com.sky.cy.log.base.bean.SkyUserActionRecordStatistEntity entity1 = new com.sky.cy.log.base.bean.SkyUserActionRecordStatistEntity() ; entity1.setUserId(userId); entity1.setActionId(actionId); entity1.setActionName(actionName); entity1.setStatistTotal(actionNumber); entity1.setStatistTime(statTime); entity1.setStatistType(ALL); int insert = mapper.insertSelective(entity1) ; log.info(LogFormat.formatMsg("UserActionRecordStatistReducer.reduce","insert number:"+insert,"")); }else { //存在,进行更新 log.info(LogFormat.formatMsg("UserActionRecordStatistReducer.reduce","","update start...")); int update = mapper.updateTotalAndDays(userId,actionId,actionNumber,ALL) ; //更新 log.info(LogFormat.formatMsg("UserActionRecordStatistReducer.reduce","update number:"+update,"update end...")); } } } }
说明:
利用集群进行整合、计算、归纳,本身是一个特别复杂的事情,Hadoop中的MR框架可以让我们从复杂的操作中解脱出来,只关注于逻辑本身,无疑是程序员的福音。只要理解了MR的流程和基本的运作原理,就可以像写java程序那样简单的对数据进行处理,但是却比单机的java程序效率高得多。当然既然使用到了MR,数据量应该是巨大的,如果只是对单机mysql中的数据进行统计与计算,建议还是使用普通的方式,毕竟最适合自己才是最好的!!!
