LLM大模型:deep research深度研究,吊打传统RAG?
LLM在2年多前火了后,RAG也跟着火了,因其解决了当时LLM的一些缺陷问题:
- 可解释性:数据来自知识库,能找到出处
- 幻觉:最后一步LLM生成response的内容都来自语义相关的chunk,缩小了LLM的生成范围,能在一定程度上避免幻觉
- 时效性:一旦有新数据,加入知识库、向量数据库即可,不需要再微调LLM
但是随着用户需求的提升,传统RAG的缺陷也愈发明显:
- RAG的回答都是“一次性”、“单轮”的,如果response不满意,用户只能重新query!
- 这种“一次性”查询的回答长度也是有限的,通常只是简单地收集整合知识库的信息,所以response也只是泛泛而谈,无法深度归纳、总结和洞察,毫无深度可言!为了解决这个问题(传统RAG无法深度归纳总结),deep research诞生了!先说一个事实:openAI的deep research 200美刀一个月,而且限制使用1000次,就这个价格和限制,足以说明这个功能的牛逼之处了!其产品的界面展示如下:
![]()
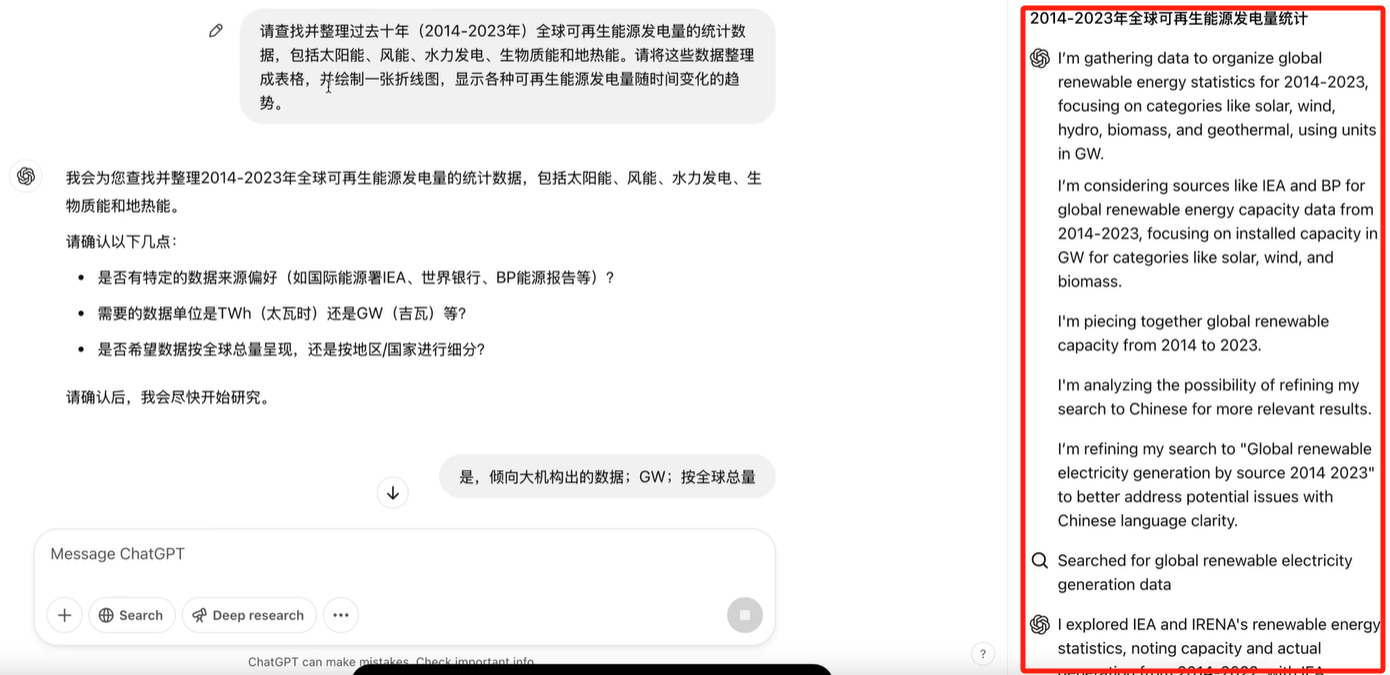
用户query后,chatGPT会根据用户的query细化,提炼多个要点,然后和用户确认需求和意图(做一个耗时几分钟~几十分钟不等,非常耗费token和算力,所以必须在事前确认清楚用户真实的需求),没问题后就开始联网爬取数据,整个过程简单直观!
1、先来理理解决问题的思路:传统RAG(其实主要问题在于最后一个环节的LLM)只能简单地整合知识,核心原因还是传统RAG的架构导致的:query是“单轮一次性”的,不是多轮迭代产生的!这个过程和人的回答方式非常类似:对于一个问题,如果立刻脱口而出,那么response的长度大概率是很短的,也是不可能有什么深度见解的!如果想要深度归纳、总结、洞察,通常的做法:
- 先把大的问题分解成多个小步骤,形成逻辑严密的回答思路,俗称planning;这一步好比是修大楼时的挖地基、搭骨架
- 然后逐个解答各个小步骤,丰满整个回答的细节,俗称action;这一步好比是封顶、砌墙、内外装修
整个过程和COT、TOT、GOT不能说非常相似,只能说一摸一样的!我个人觉得核心点在于:怎么精确地理解用户需求,合理拆解,形成工作流!以 https://github.com/jina-ai/node-DeepResearch?tab=readme-ov-file node-deepresearch这个开源产品为例,整个流程图示如下:
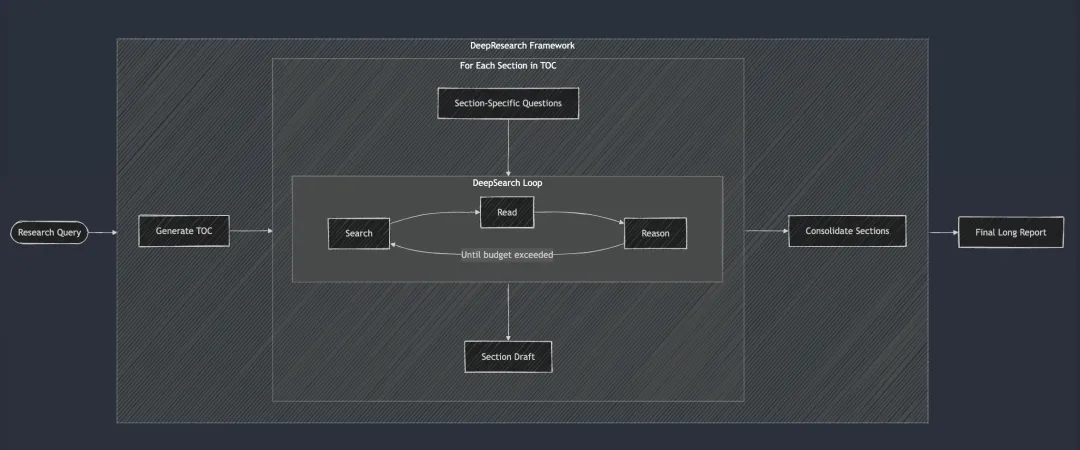
用户输入query,LLM产生TOC,然后进入循环:查找、读取和推理,直到达到结束的条件,然后再通过LLM做总结,最终给用户输出完整的研究报告!中间这个循环的实现如下:
// 主推理循环 while (tokenUsage < tokenBudget && badAttempts <= maxBadAttempts) { // 追踪进度 step++; totalStep++; // 从 gaps 队列中获取当前问题,如果没有则使用原始问题 const currentQuestion = gaps.length > 0 ? gaps.shift() : question; // 根据当前上下文和允许的操作生成提示词 system = getPrompt(diaryContext, allQuestions, allKeywords, allowReflect, allowAnswer, allowRead, allowSearch, allowCoding, badContext, allKnowledge, unvisitedURLs); // 让 LLM 决定下一步行动 const result = await LLM.generateStructuredResponse(system, messages, schema); thisStep = result.object; // 执行所选的行动(回答、反思、搜索、访问、编码) if (thisStep.action === 'answer') { // 处理回答行动... } else if (thisStep.action === 'reflect') { // 处理反思行动... } // ... 其他行动依此类推 }
这个getPrompt不就是分解任务的plan函数么?具体是这么实现的:
// Add header section prompt里明确了specialized in多步推理,让LLM分解任务 sections.push(`Current date: ${new Date().toUTCString()} You are an advanced AI research agent from Jina AI. You are specialized in multistep reasoning. Using your training data and prior lessons learned, answer the user question with absolute certainty. `); ...... // Add knowledge section if exists 添加知识 if (knowledge?.length) { const knowledgeItems = knowledge .map((k, i) => ` <knowledge-0> <question> How can I get the last update time of a URL? </question> <answer> Just choose <action-visit> and put URL in it, it will fetch full text and estimate the last update datetime of that URL. </answer> </knowledge-0> <knowledge-${i + 1}> ......... // Add context section if exists 添加action,就是执行步骤 if (context?.length) { sections.push(` You have conducted the following actions: <context> ${context.join('\n')} </context> `); } // Add bad context section if exists if (badContext?.length) { const attempts = badContext .map((c, i) => ` <attempt-${i + 1}> - Question: ${c.question} - Answer: ${c.answer} - Reject Reason: ${c.evaluation} - Actions Recap: ${c.recap} - Actions Blame: ${c.blame} </attempt-${i + 1}> `) ....... //必须选一个action sections.push(` Based on the current context, you must choose one of the following actions: <actions> ${actionSections.join('\n\n')} </actions> `); // Add footer 逐个执行,用json输出结果 sections.push(`Think step by step, choose the action, and respond in valid JSON format matching exact JSON schema of that action.`);
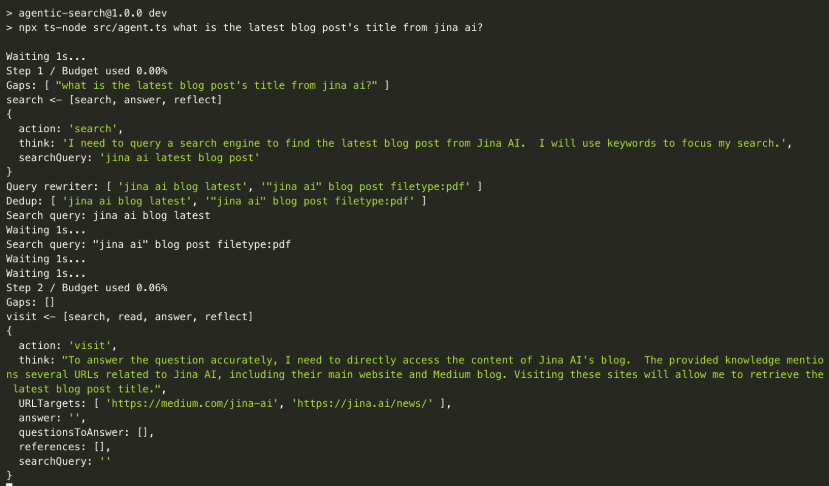
整个过程原理并不复杂!效果演示:用户提问后,系统自动分解实现步骤为search、visit等步骤;每个步骤还展示了thinking思考过程的细节;
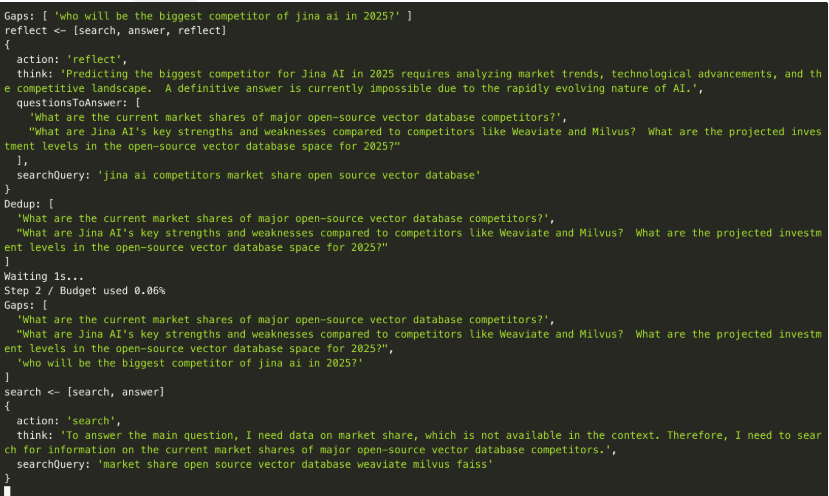
另一个例子,最大的靓点在于:
- questionsToAnswer:根据当前步骤,找到还需要回答、解决的问题
- searchQuery:LLM下一步要回答的问题
- Gap:当前已经得到的答案和预期之间的差距在哪,这也进一步知名了下一步的方向
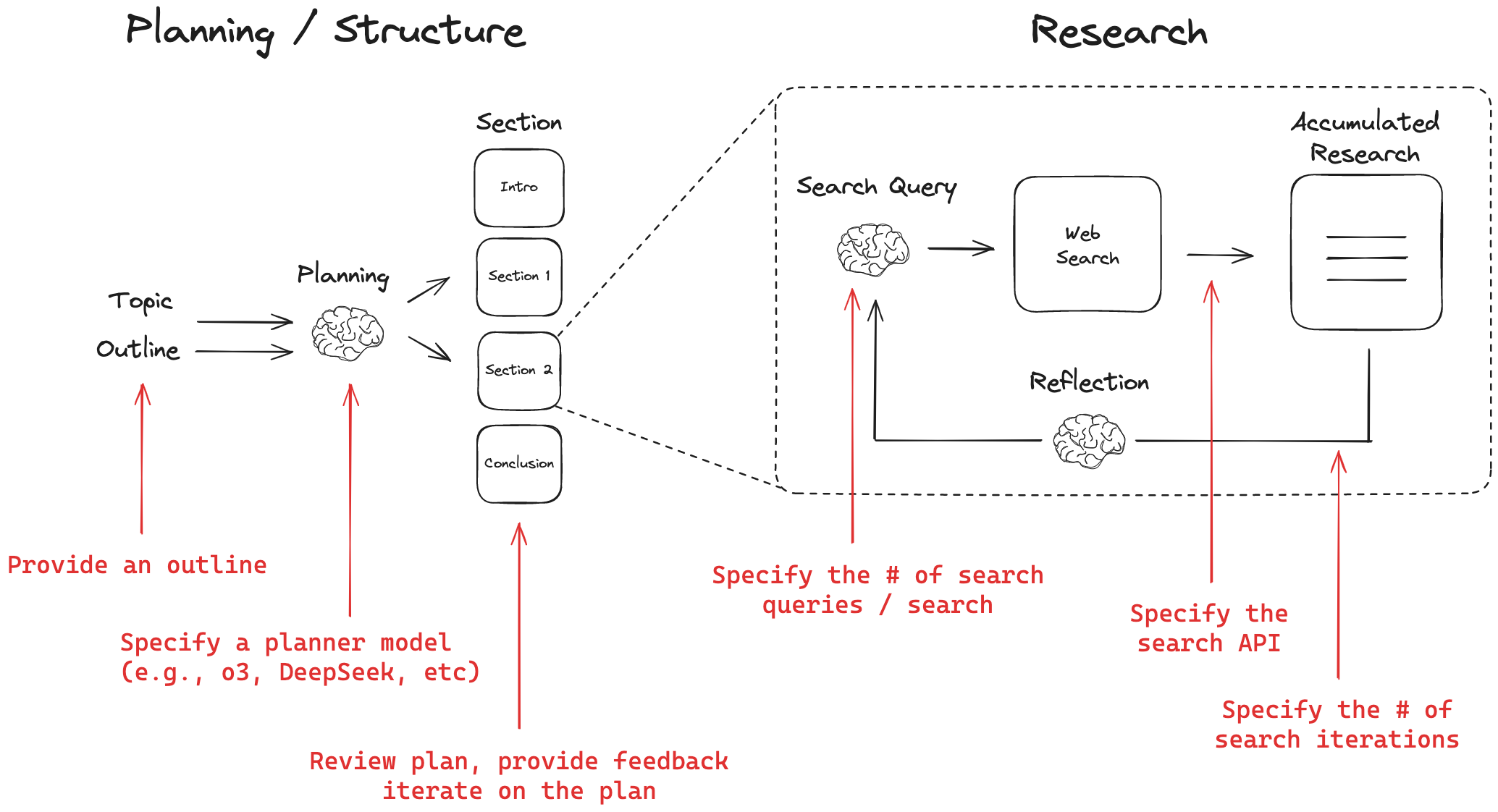
2、另一个 https://github.com/langchain-ai/open_deep_research.git 也采用类似的思路实现了deep research功能,具体包括:
- provide an outline with a desired report structure
- set the planner model (e.g., DeepSeek, OpenAI reasoning model, etc)
- give feedback on the plan of report sections and iterate until user approval
- set the search API (e.g., Tavily, Perplexity) and # of searches to run for each research iteration
- set the depth of search for each section (# of iterations of writing, reflection, search, re-write)
- customize the writer model (e.g., Anthropic)
小破站用户的现身说法:

总结:
1、各种agent(这两天manus又火了)、research越来越火,功能越来越完善,本质还是因为base model越来越强大!open ai为了实现deep research功能,专门用RL特意训练了一个model!
2、现阶段的deep research、manus等产品,本质是人为设置好plan、action、feedback等循环流程,相比显存的产品,性能有大幅提升,但我个人觉得还是不够智能,后续是不是能通过RL,把这整个流程直接嵌入、固化到LLM了?
参考:
1、https://www.bilibili.com/video/BV1rpAXeUEDV/?spm_id_from=333.337.search-card.all.click&vd_source=241a5bcb1c13e6828e519dd1f78f35b2 LangChain开源复现OpenAI DeepResearch
2、https://mp.weixin.qq.com/s/-pPhHDi2nz8hp5R3Lm_mww DeepResearch 的设计和实现
3、https://www.aivi.fyi/aiagents/introduce-node-DeepResearch 零成本复刻deep research

 浙公网安备 33010602011771号
浙公网安备 33010602011771号