LLM大模型:deepseek浅度解析(三):R1的reinforcement learning GRPO复现
deepseek-R1比较创新的点就是reward函数了,其自创的GRPO方法,详解如下:https://www.cnblogs.com/theseventhson/p/18696408

训练出了R1-zero和R1两个强化学习版本!幸运的是,GRPO的这个算法已经有人实现,并集成到huggingface啦,直接调用就行,demo在这里:https://gist.github.com/willccbb/4676755236bb08cab5f4e54a0475d6fb?permalink_comment_id=5417630
1、训练肯定是要数据啦,这里用 https://huggingface.co/datasets/openai/gsm8k 这个数据集,长这样的:question、answer(reason + result) 左边是问题,右边是回答,回答有推理过程和最终结果

数据集齐了,就要处理训练样本了,这个类似dataset的功能,代码如下:
#从answer中提取计算结果;这些都是数学题,最终答案都是一个数字作为ground truth,数字和reason之间用####隔开的,所以用####做分割 def extract_hash_answer(text: str) -> str | None: if "####" not in text: return None return text.split("####")[1].strip() # 构造prompt,单独抽取answer def get_gsm8k_questions(split = "train") -> Dataset: data = load_dataset('openai/gsm8k', 'main')[split] # type: ignore data = data.map(lambda x: { # type: ignore 'prompt': [ {'role': 'system', 'content': SYSTEM_PROMPT}, {'role': 'user', 'content': x['question']} ], 'answer': extract_hash_answer(x['answer']) }) # type: ignore return data # type: ignore
dataset = get_gsm8k_questions()
2、deepseek训练时,reward除了最终的结果外,还要求response的格式正确,比如要有reasoning过程,也要有最终的答案,所以这里要定义response的格式,如下:
import re import torch from datasets import load_dataset, Dataset from transformers import AutoTokenizer, AutoModelForCausalLM from trl import GRPOConfig, GRPOTrainer # Load and prep dataset:格式就是推理过程+最终结果 SYSTEM_PROMPT = """ Respond in the following format: <reasoning> ... </reasoning> <answer> ... </answer> """ XML_COT_FORMAT = """\ <reasoning> {reasoning} </reasoning> <answer> {answer} </answer> """
def extract_xml_answer(text: str) -> str:
answer = text.split("<answer>")[-1]
answer = answer.split("</answer>")[0]
return answer.strip()
最核心的部分来了,这个reward是怎么在代码层面实现的?针对gsm8k数据集的reward函数代码实现:使用正则计算reward,可以有效避免LLM计算reward时产生的reward hacking!同时极大降低计算成本、容易实现!
def correctness_reward_func(prompts, completions, answer, **kwargs) -> list[float]: responses = [completion[0]['content'] for completion in completions] q = prompts[0][-1]['content'] extracted_responses = [extract_xml_answer(r) for r in responses] #把问题、答案、LLM的回复、从回复中抽取的结果都打印出来 print('-'*20, f"Question:\n{q}", f"\nAnswer:\n{answer[0]}", f"\nResponse:\n{responses[0]}", f"\nExtracted:\n{extracted_responses[0]}") #如果LLM的结果和训练样本的答案是一样的,说明回答正确,reward=2,奖励2分 return [2.0 if r == a else 0.0 for r, a in zip(extracted_responses, answer)] #训练样本最终的结果是个数字,所以要求LLM最终输出的结果是数字,才能奖励0.5,reward=0.5 def int_reward_func(completions, **kwargs) -> list[float]: responses = [completion[0]['content'] for completion in completions] extracted_responses = [extract_xml_answer(r) for r in responses] return [0.5 if r.isdigit() else 0.0 for r in extracted_responses] #LLM的回复中如果有reasoning推理过程和answer结果标签,才符合既定的格式要求,这里reward=0.5 def strict_format_reward_func(completions, **kwargs) -> list[float]: """Reward function that checks if the completion has a specific format.""" pattern = r"^<reasoning>\n.*?\n</reasoning>\n<answer>\n.*?\n</answer>\n$" responses = [completion[0]["content"] for completion in completions] matches = [re.match(pattern, r) for r in responses] return [0.5 if match else 0.0 for match in matches] #同上,不过这里的正则检查没那么严格 def soft_format_reward_func(completions, **kwargs) -> list[float]: """Reward function that checks if the completion has a specific format.""" pattern = r"<reasoning>.*?</reasoning>\s*<answer>.*?</answer>" responses = [completion[0]["content"] for completion in completions] matches = [re.match(pattern, r) for r in responses] return [0.5 if match else 0.0 for match in matches] def count_xml(text) -> float: count = 0.0 if text.count("<reasoning>\n") == 1: count += 0.125 if text.count("\n</reasoning>\n") == 1: count += 0.125 if text.count("\n<answer>\n") == 1: count += 0.125 count -= len(text.split("\n</answer>\n")[-1])*0.001 if text.count("\n</answer>") == 1: count += 0.125 count -= (len(text.split("\n</answer>")[-1]) - 1)*0.001 return count def xmlcount_reward_func(completions, **kwargs) -> list[float]: contents = [completion[0]["content"] for completion in completions] return [count_xml(c) for c in contents]
选择base model:
model_name = "Qwen/Qwen2.5-1.5B-Instruct" #可以按需换成其他的 output_dir="outputs/Qwen2.5-1.5B-Instruct-GRPO" run_name="Qwen-1.5B-GRPO-gsm8k" training_args = GRPOConfig( output_dir=output_dir, run_name=run_name, learning_rate=5e-6, adam_beta1 = 0.9, adam_beta2 = 0.99, weight_decay = 0.1, warmup_ratio = 0.1, lr_scheduler_type='cosine', logging_steps=1, bf16=True, per_device_train_batch_size=1, gradient_accumulation_steps=4,#8k样本,这里有2k步梯度 num_generations=16, max_prompt_length=256, max_completion_length=200,#reasoning长度限制 num_train_epochs=1, save_steps=100, max_grad_norm=0.1, log_on_each_node=False, use_vllm=False, vllm_gpu_memory_utilization=.3, vllm_device="cuda:0", report_to="none" #disabling Wandb. ) model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype=torch.bfloat16, device_map=None ).to("cuda") tokenizer = AutoTokenizer.from_pretrained(model_name) tokenizer.pad_token = tokenizer.eos_token
直接用现成的接口开始训练了:每次会根据这5个reward的辅助函数计算reward值,然后update gradient!
trainer = GRPOTrainer( model=model, processing_class=tokenizer, reward_funcs=[ xmlcount_reward_func, #自定义的格式reward函数 soft_format_reward_func,#自定义的格式reward函数 strict_format_reward_func,#自定义的格式reward函数 int_reward_func,#自定义的结果数字reward函数 correctness_reward_func],#自定义的结果reward函数 args=training_args, train_dataset=dataset, #peft_config=peft_config ) trainer.train() trainer.save_model(output_dir)
怎样,因为reward方法别人已经写好,自己直接调用GRPOTrainer就行了,是不是很简单了!
3、结果解读
循环刚开始的时候,base model的回答和微调前一样,没啥变化:可以看出base model的结果毫无格式和正确性而言,效果很差,只体现了model的基座能力!
-------------------- Question: #训练样本的问题 There are 15 tables in the school's cafeteria. Each table can seat 10 people. Usually, only 1/10 of the seats are left unseated. How many seats are usually taken? Answer: #训练样本的结果 135 Response: # model的回复:毫无章法 To find out how many seats are usually taken, we can follow these steps: 1. **Calculate the total number of seats in the cafeteria:** - There are 15 tables, and each table seats 10 people. \[ \text{Total seats} = 15 \text{ tables} \times 10 \text{ seats/table} = 150 \text{ seats} \] 2. **Determine the number of seats that are usually left unseated:** - Typically, only 1/10 of the seats are left unseated. \[ \text{Unseated seats} = 150 \text{ seats} \times \frac{1}{10} = 15 \text{ seats} \] 3. **Calculate the number of seats that are usually taken:** - The total number of seats is 150, and Extracted: # model的结果 To find out how many seats are usually taken, we can follow these steps: 1. **Calculate the total number of seats in the cafeteria:** - There are 15 tables, and each table seats 10 people. \[ \text{Total seats} = 15 \text{ tables} \times 10 \text{ seats/table} = 150 \text{ seats} \] 2. **Determine the number of seats that are usually left unseated:** - Typically, only 1/10 of the seats are left unseated. \[ \text{Unseated seats} = 150 \text{ seats} \times \frac{1}{10} = 15 \text{ seats} \] 3. **Calculate the number of seats that are usually taken:** - The total number of seats is 150, and
大概经历了100多轮后,model终于输出了要求的format:
-------------------- Question: There are 18 green leaves on each of the 3 tea leaf plants. One-third of them turn yellow and fall off on each of the tea leaf plants. How many green leaves are left on the tea leaf plants? Answer: 36 Response: <reasoning> Initially, there are 18 * 3 = 54 green leaves on all the tea leaf plants. One-third of them turn yellow on each plant, which means 54 / 3 = 18 leaves turn yellow. After the yellow leaves turn yellow, there are 54 - 18 = 36 leaves left on all the tea leaf plants. </reasoning> <answer> 36 green leaves </answer> Extracted: 36 green leaves
换句话说,前面100多轮基本就是瞎搞,纯属浪费算力,R1-zero估计面临的就是这种情况,所以继续训练R1的时候会基于base model做SFT(部分数据来自R1-zero的生成,核心目的还是适当引导一下方向,避免model前面迭代时乱打方向;说直白点,就是通过SFT让model学会按照特定的模板template输出responce),再用GRPO做RL,可以极大减少前期的这种算力浪费!
训练完成后,经典问题检测:
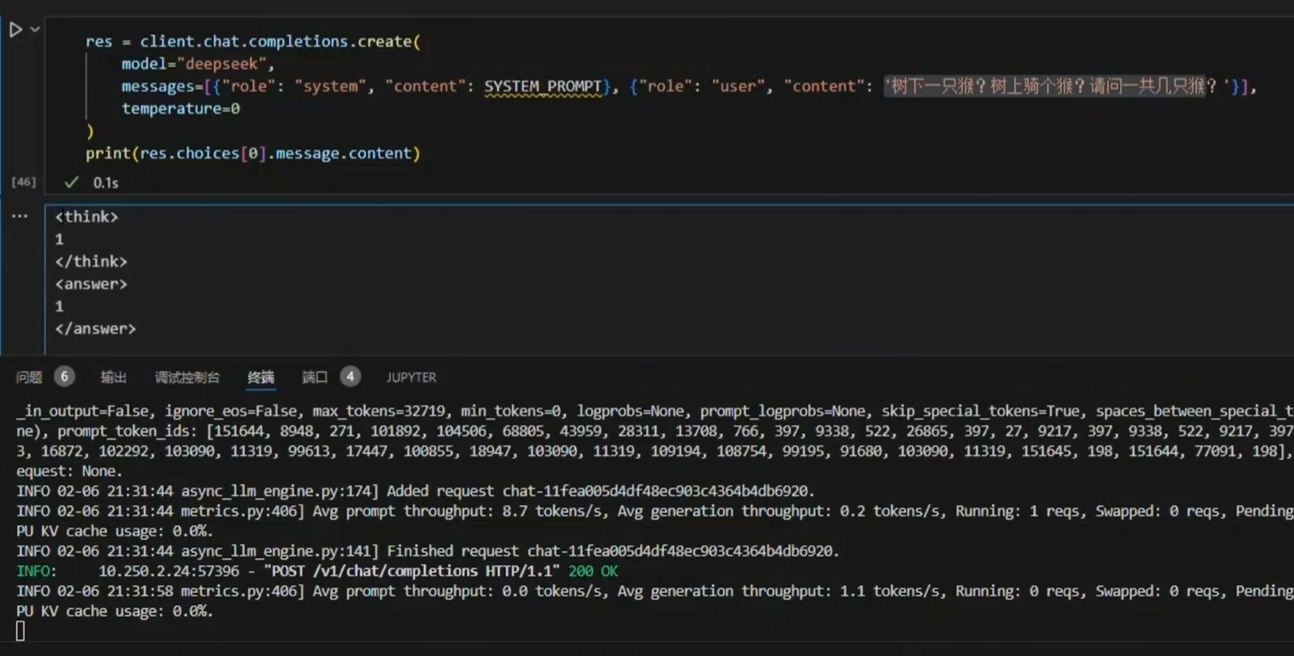
(1) "how many r's are in strawberry?"

(2) 整体的reward情况:超过250个epoch后,回答问题的reward居然还降低了很多,可能是数据量较大,模型小了的原因!
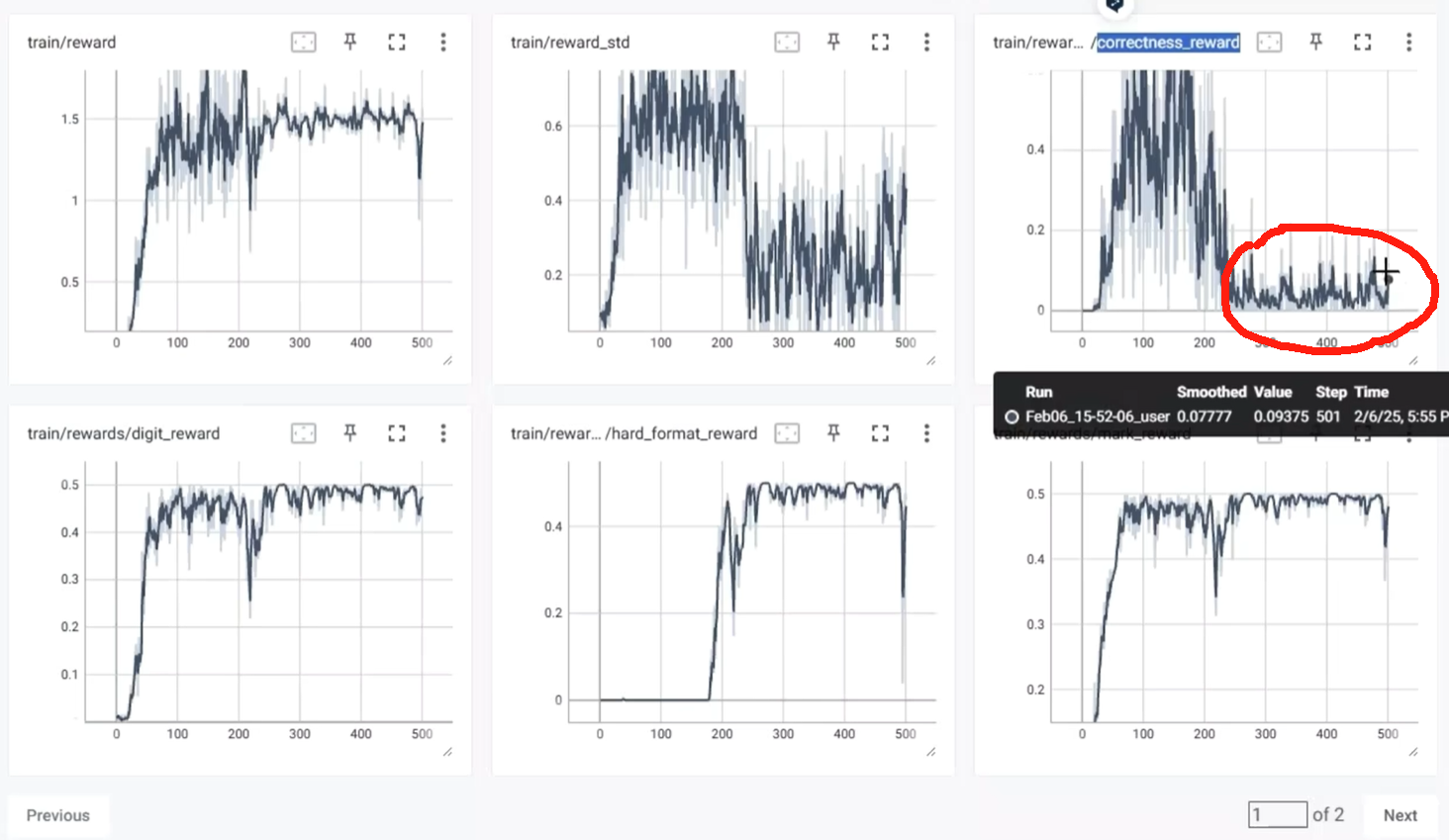
回答问题越来越简洁,reasoning接近于无:
总结:
1、reinforcement learning用在这里原理并不复杂, 其实很简单,只要定义好reward就行了!
-
- update model的参数,总要有个方向或目标,不能随意更新数值,那么这个方向或目标是啥了?
- pre-train(next token的prob distribute)、STF微调(output接近训练语料的答案):一般都是各种loss,比如KL散度。此时要求loss最小,所以用梯度下降 gradient descent;
- reinforcement learning:一般都是各种reward,此时要求reward最大,所以用梯度上升 gradient ascend;
- 两种更新参数的方式,仅仅是方向不同,从数学上讲没啥本质区别!
- update model的参数,总要有个方向或目标,不能随意更新数值,那么这个方向或目标是啥了?
2、也有华人团队研究R1-Zero,发现aha moment并不是R1-zero上特有的,Qwen等基础模型在epoch 0也会出现顿悟时刻(应该是pre-train的语料导致的),也有COT,只不过是浅层的顿悟;R1-zero通过RL将aha moment转换成了有效的反思(aha moment并不是R1-zero特有的,只是通过了RL的方式,去掉了reward差的顿悟,留下了reward好的顿悟)!不同model responce中展现的顿悟token:这些token疑似与pew-train的训练语料有关

详见:https://www.thepaper.cn/newsDetail_forward_30111174
3、较高温度(如0.7-1.0)可能更易触发自我反思行为:temperature越高,model输出的logits概率分布越多样,越能得到多种不同类型的答案,这完美契合了Ai的计算逻辑;答案越多,越有可能接近reward的要求!
4、这种只看结果、不看过程的的reinforcement learning的奖励方式,极大地激发了大模型的复杂思考能力?
5、这种reinforcement learning还有非常广泛的用途:
- 金融领域
- 预测股价:prompt是公司的财报、每天的消息(宏观政策、微观公司),target是公司股价
- 互联网:
- 预测用户是否点击:promt是用户画像、用户历史行为,target是用户对某些item的评分
- 医疗:
- 预测患者的病概率:prompt是患者的各种检测指标、生活习性,target是患者得某种疾病的概率
- 安全
- UGC的内容:对于一段文本,从敏感、歧视、政治、商业、虚假、诱导等维度评分
- 网络流量:数据访问包是否正常
- 代码检测:代码是否有漏洞
参考:
1、https://www.bilibili.com/video/BV1XDPQeeEF7/?spm_id_from=333.999.0.0&vd_source=241a5bcb1c13e6828e519dd1f78f35b2 上手代码复现DeepSeek-R1强化学习训练演示
2、https://www.bilibili.com/video/BV13ZPdejE1K/?spm_id_from=333.788.recommend_more_video.3&vd_source=241a5bcb1c13e6828e519dd1f78f35b2 如何快速微调DeepSeek-R1-8b模型,并且可视化训练过程,赶紧行动起来
3、https://www.bilibili.com/video/BV13jPde5EPk/?spm_id_from=333.788.recommend_more_video.2&vd_source=241a5bcb1c13e6828e519dd1f78f35b2 大模型DeepSeek R1训练全流程流程详解
4、https://gist.github.com/willccbb/4676755236bb08cab5f4e54a0475d6fb?permalink_comment_id=5417630 GRPO强化学习算法demo
https://github.com/waylandzhang/DeepSeek-RL-Qwen-0.5B-GRPO-gsm8k/blob/main/train-checkpoint-900.ipynb qianwen的base model复现GRPO算法
5、https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Qwen2.5_(3B)-GRPO.ipynb#scrollTo=yUbluAAhD0Lg unsloth源码和训练中间结果及验证
6、https://www.thepaper.cn/newsDetail_forward_30111174 DeepSeek-R1-Zero不存在顿悟时刻?华人团队揭秘真相:或只因强化学习
7、https://www.bilibili.com/video/BV1RrA3esESH?spm_id_from=333.788.recommend_more_video.3&vd_source=241a5bcb1c13e6828e519dd1f78f35b2 GRPO训练,出现顿悟时刻
8、https://mp.weixin.qq.com/s/Ap-CBnqL_BxXH-bpH0CiTA HuggingFace 手把手教你构建DeepSeek-R1推理模型!
9、PPO2和GRPO的目标函数对比:GRPO多了正则,不过这不是最核心的;最核心的是Advantage的计算:根据目前的state,总要选出一些合适的action去执行吧,怎么找到当前state最合适的action了?
- GRPO:多生成几个action,通过规则或reward model判断哪些action的reward高于均值,选择这些action继续!
- 只关注当前即时reward,不关心后续state
- 适合数学、编程等需要多次尝试的
- PPO:使用critical/value model评估V(St+1)的价值,由此选出好的action;
- 根据V(St+1)和V(S)、即时reward判断action的好坏,更看中长远效益(有可能即时reward高,但是V(St+1)很小,导致A是负数)
- 适合游戏、机器人等需要评估V(St+1)的
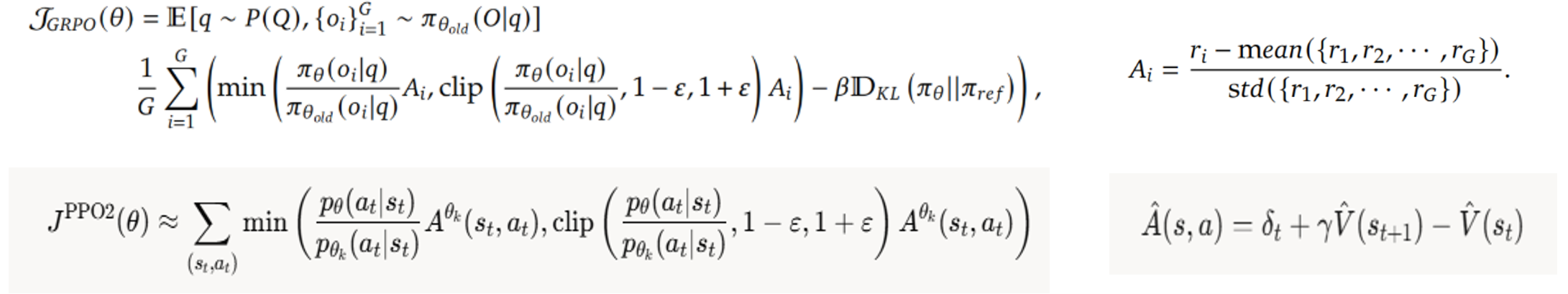
10、GRPO的缺陷:https://mp.weixin.qq.com/s/SBGO_1JXnI9CGcLL8eANBA

-
问题层面的难度偏差:这种偏差源于对问题的奖励进行标准差归一化处理。对于标准差较低的问题(即问题过于简单或过于困难),策略更新时会赋予更高的权重。尽管优势值归一化是强化学习中的常见技巧,但 GRPO 将其应用于单个问题层面,而非整个批次,这导致不同问题在目标函数中的权重分布不均。这种机制使得模型更偏好极端简单或极端困难的问题,而忽视了中等难度的问题,进一步影响了策略的优化方向。
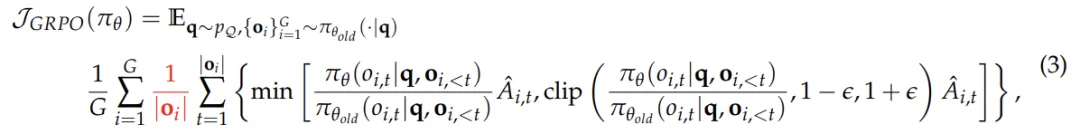
-
响应层面的长度偏差:这种偏差源于对响应长度进行归一化处理。当模型生成正确响应时(即优势值为正),较短的响应会获得更大的梯度更新,从而促使策略倾向于生成简洁的正确答案。然而,当模型生成错误响应时(即优势值为负),较长的响应由于长度较大而受到的惩罚较轻,导致策略更倾向于生成冗长的错误答案。这种长度规范化机制使得模型在正确时偏好简短,而在错误时偏好冗长,形成了一种不对称的优化倾向。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号