LLM大模型:LLaVa多模态图片检索原理
训练安全垂直领域的LLM,会用到很多著名安全论坛(52pojie\kanxue\xianzhi\freebuf等)、博客的数据,这些数据100%都有很多图片(文不如图嘛,图片比文字更直观,更容易表达业务意义),之前微调LLM只能使用文字,图片只能丢弃,非常可惜,需要利用多模态的技术充分提取图片信息!
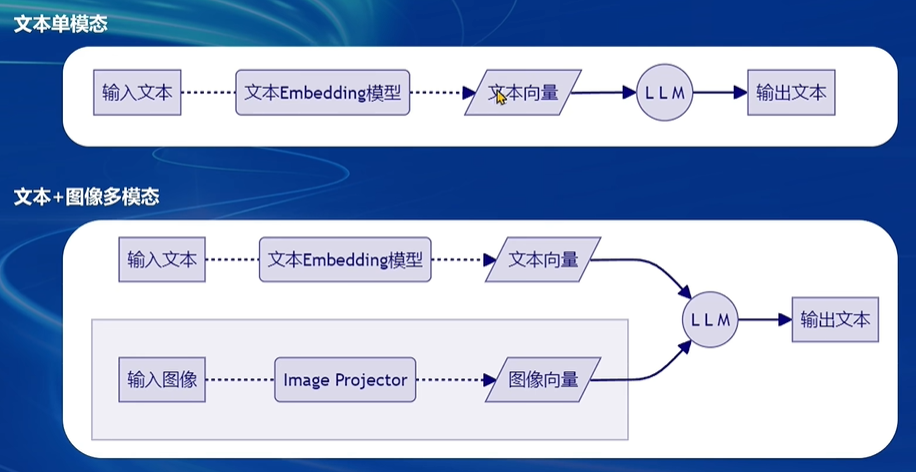
1、以前做传统的数据挖掘、机器学习,人为寻找各种数据特征,然后清洗、归一化,再通过专门的特征工程(相关系数、卡方检验、信息增益等)找到明显的特征,最后用分类器/回归器+显著特征一起解决业务问题!深度学习兴起后,以前人工手动处理特征的方式落后啦,可以直接通过DNN、RNN、LSTM等方式提取和转换特征,然后使用embedding的形式表示;特征或embedding的质量,决定了最终任务效果的下限!只要特征构造的好,最终任务的下限就非常高!对于文本,可以通过transformer的encoder提取特征,其对应的图片可以通过CNN等提取特征,但CNN和transformer明显是两个不同的模型,提取的embedding明显不是一个语义空间的,直接对比两个embedding明显属于驴唇不对马嘴!此时就需要把这两个embedding想办法在新的矩阵空间中尽可能接近,甚至重合,这就叫align vector!图示如下:单模态的模型分别提取文字、不同图片、声音的embedding,然后需要在新空间内做alignment对齐!

2、既然是alignment,第一步肯定是embedding啦!文本求embedding的方式前面做RAG的时候已经很熟悉了,常见的有M3E、bge等模型,那图片了?常见的有CNN、VIT等,求出embedding后是怎么对齐的了?openAI是这么干的(https://openai.com/index/clip/) CLIP (Contrastive Language–Image Pre-training):openAI收集了大量(号称有400Million的图片-文本对)的文本和图片配对的数据(当然肯定有匹配错误的噪音):
- text用类似bert的LLM对文本做encoding,得到embedding;同时用CNN或vit对图片做encoder,得到embedding
- 每批次取一定数量的数据对(比如2000对),两方面的embedding分别做dot product,形成2000*2000的矩阵
- 矩阵对角线的值都是正确匹配的,非对角线都是错误匹配,所以对角线的值要比非对角线的值越大越好;具体使用的是noise contrastive estimation loss方法,简称 InfoNCE loss;k为类别个数, log 里面的分母叠加项是包括了分子项的。分子是正例对的相似度,分母是正例对+所有负例对的相似度。最小化 infoNCE loss,就是去最大化分子的同时最小化分母,也就是最大化正例对的相似度,最小化负例对的相似度。
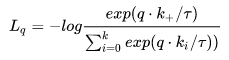
- 最后一步就是根据loss做back proporgation,分别调整text encoder和Image encoder的参数了
整个图示如下:
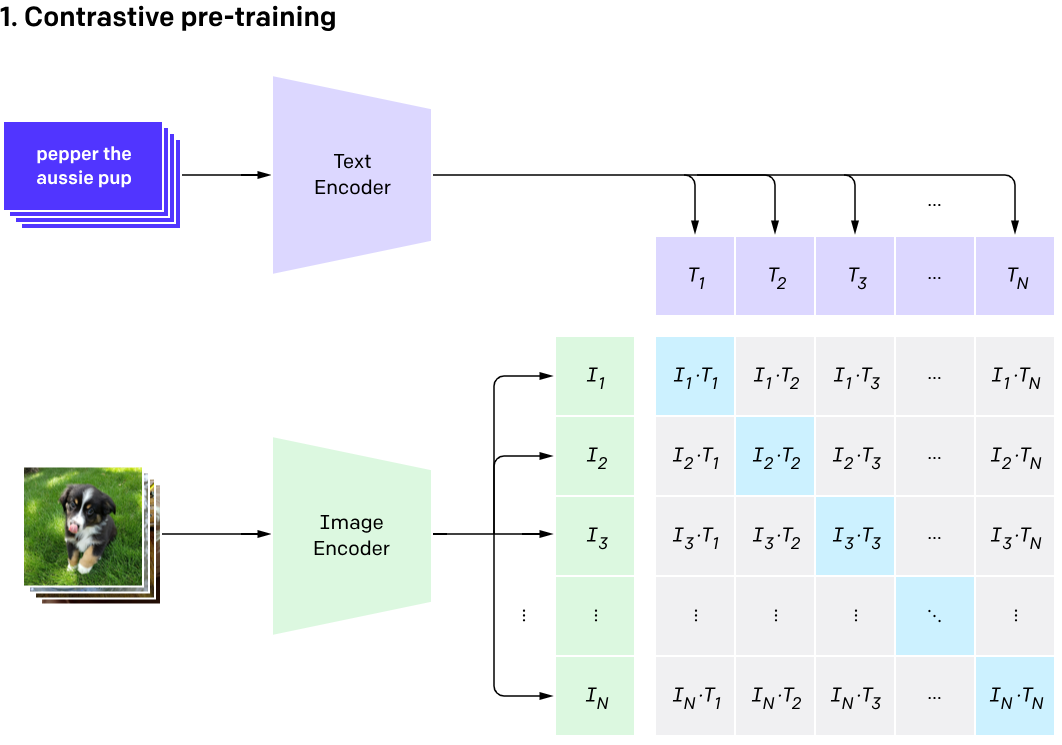
训练完成后,一段text和一张图片是否匹配了?分别通过text ecndoer和image encoder求出embedding,然后各自求dot product,找到最大的那个即可!这不就是文本检索图片么?
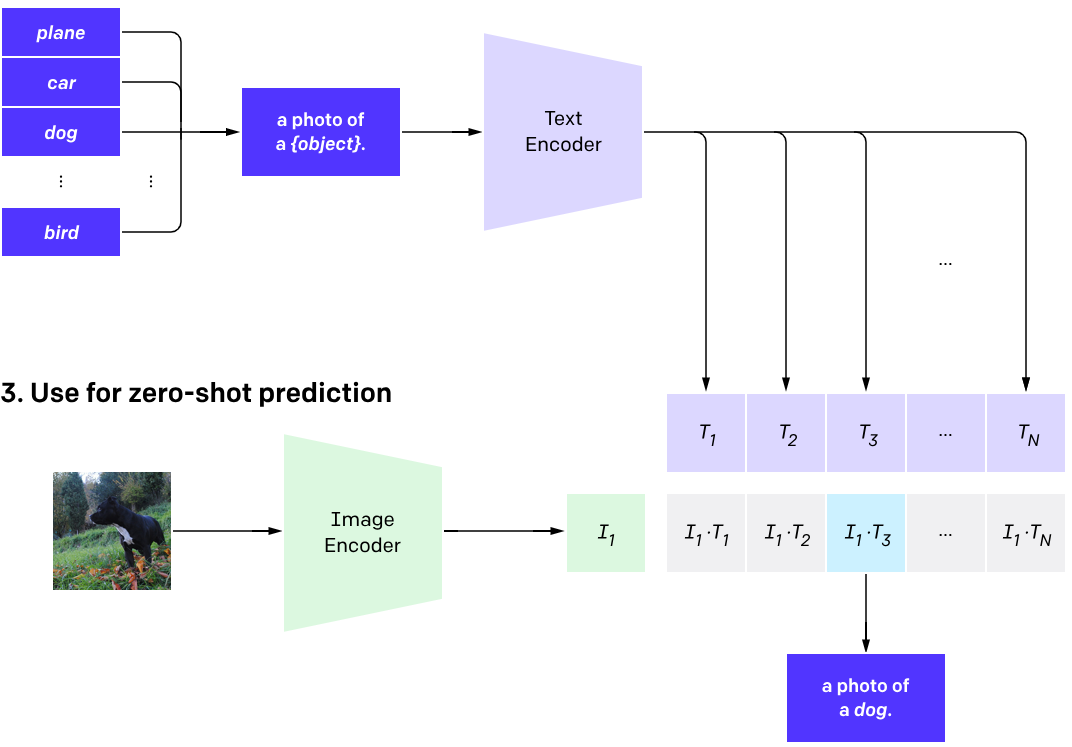
clip模型一旦训练完成,就具备zero-shot能力了;被集成到其他下游任务中后,本身是不需要再次微调的(训练数据400Million对,见多识广啦)!
3、clip已经能图文互相检索了,但是还有个缺陷:没法生成文本,只能根据文本和图像互相检索!如果进一步要求根据图像生成详细的文本描述、回答关于图像的复杂问题了?clip就无能为力了!clip可以提供text和image的embedding,仅此而已,要想生成图片的文字描述,最终还是要依靠transformer的encdoer部分啦,也就是大家理解的GPT!LLaVa的架构如下:
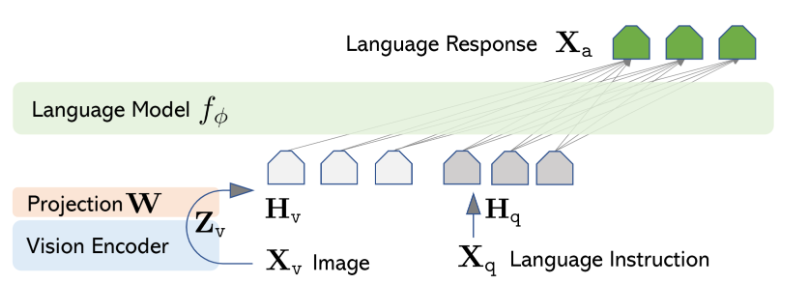
(1)最底层是vision encoder,就是对图片做encoding,这里使用的就是clip中的vit模型对Xv image编码得到Zv!同样:Xq这种query文本也用clip的text encoder(就是transformer的encoder)编码
(2)提取的图片embedding Zv需要和Xq的embedding对齐,所以这里额外乘以矩阵W做projection,得到Hv,就和Xq的embedding Hq对齐啦;projector可以是简单的linear线性变换,也可以是稍微复杂的2层神经网络MLP!MLP因为加入了激活函数,能拟合更多的非线性特征,理论上的效果要比linear好,但是计算更复杂!
projection代码如下:两个线性层中间加个激活函数
class LlavaNextMultiModalProjector(nn.Module): def __init__(self, config: LlavaNextConfig): super().__init__() self.linear_1 = nn.Linear(config.vision_config.hidden_size, config.text_config.hidden_size, bias=True) self.act = ACT2FN[config.projector_hidden_act] self.linear_2 = nn.Linear(config.text_config.hidden_size, config.text_config.hidden_size, bias=True) def forward(self, image_features): hidden_states = self.linear_1(image_features) hidden_states = self.act(hidden_states) hidden_states = self.linear_2(hidden_states) return hidden_states
(3)根据上述得到的Hv和Hq已经可以做图文检索了,但是没法生成text,下一步需要想办法融合Hv和Hq,经过language model生成text啦!
-
- 还记得transformer么?初衷本是用来做翻译的,有严格的匹配数据,所以有encoder和decoder。encoder的K和decoder的Q相乘,得到权重系数,再对V加权,借此让decoder的中间embedding融合encoder的最终输出。由于这种attention机制的Q和K、V分别来自encoder和decoder,所以叫cross attention!理论上讲:pre-train有image和text的配对数据,也可以使用decoder做corss attention的方式吸收Hv和Hq的信息;所以训练样本中from human这部分人提问text的embedding + image的embedding融合后(融合方式见下面第二点),通过cross attention的方式和gpt回复text的embedding做cross attention,以此将自身的信息传递进入decoder生成text!
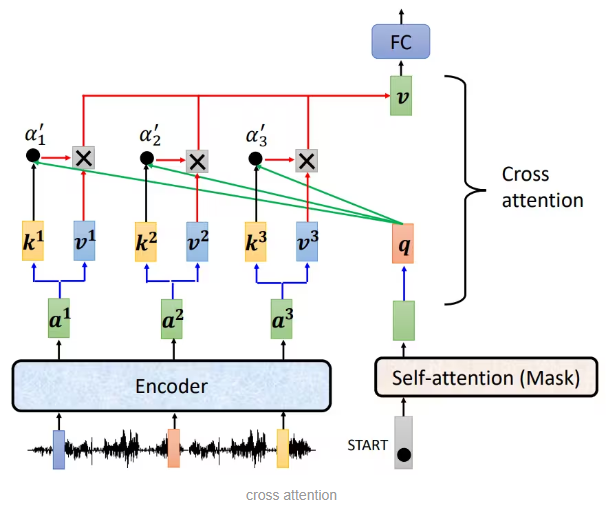
-
- transformer库中的LLaVa模型的modeling_llava.py中的 _merge_input_ids_with_image_features 方法定义了text和image的融合方式,先说结论:直接concat
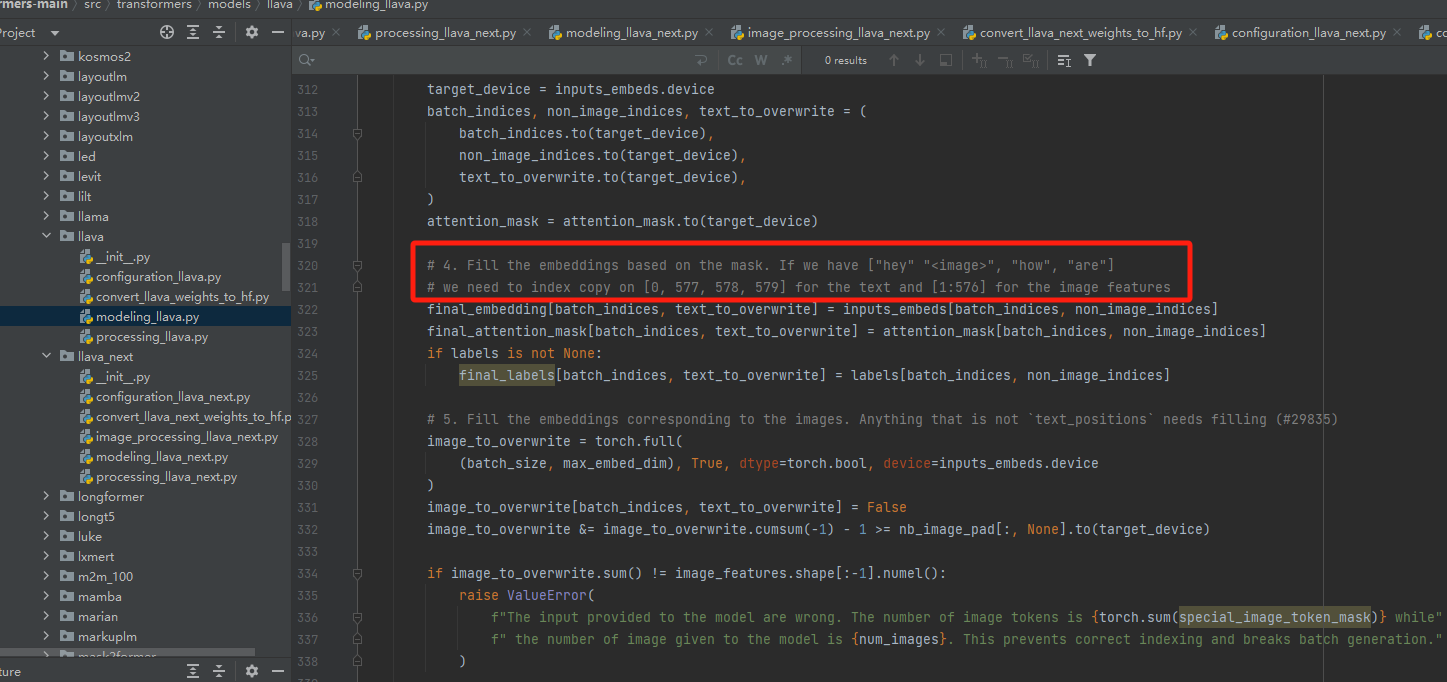
源码特意给了注释:text做tokenize的时候,给image留个位置;这个位置后续用image的embedding来补上!所以整个就是简单粗暴的首尾拼接!比如下图:value都是图片的embedding,就这样拼接起来!

pre-train的数据需要预留图片的占位符,后续用图片的embedding替换:
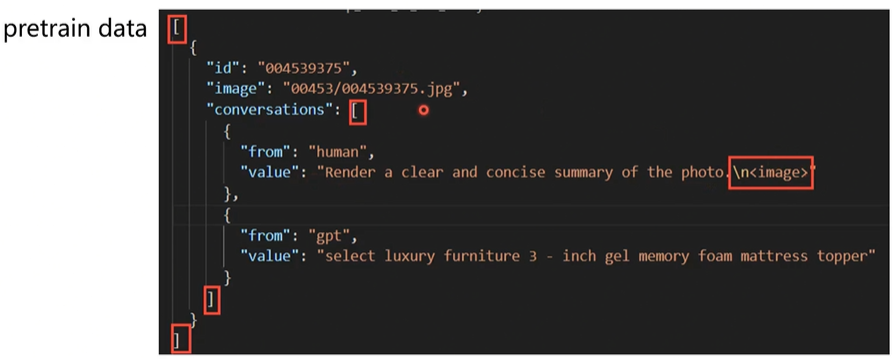
总结一下:image通过vit转成embedding,human提问的text通过bert等也转成embedding,然后concat融合;融合后的embedding通过cross attention的方式把自身信息传递给gpt的回答,最终通过decoder生成回答!
(4)网络架构设计完毕,就是pre-train和fine-tune了!最底层是clip,本身是经过400Mlillion配对数据训练出来的,是“见过大世面”的、具备zero-shot的能力,没必要调整了!
- pre-train阶段只改projection W,整个网络就能正常使用,适用于通用任务;
- 对于垂直领域的专用任务,还是要fine-tune的,这是调整就不仅限于projection W了,也要微调Language Model(可以用LoRA减少计算量);原作者用的是LLaMa或Vicuna
思考总结:
1、万物皆可embeddiing:认识怎么识别物理世界事务的了?本质还是通过事务的各种特征区分的,所以机器学习和AI最核心的方式也是通过构造好的强特征去识别事务的,所以不论是传统的特征工程feather engineering,还是DNN、LSTM、transformer的encoder,各种复杂的操作最终的目的无一例外都是构造特征!一旦强特征构造完成,整个任务已经完成了80%;hinton近期有个采访,据他透露,神经网络所谓的理解,本质就是得到合适的向量,并且向量之间能互相作用生成新向量!
2、多模态的核心:不同的单模态都可以把物理世界的客观事务做embedding,但每个单模态都是在自己的空间做BP,所以多个单模态之间是没法直接做比对的,每个单模态都需要进一步通过矩阵乘法的方式统一到相同的语义空间后,再使用Constrastive learning、cross attention、concat等方式对齐后,再做各种下游任务 ;
3、矩阵乘法:本质是把向量转换到新的空间,下游各种任务(分类、回归、相似度等)在新的空间解决【通过矩阵的参数值调整适配下游任务】;
4、softmax:做归一化,每个维度的结果也可以当成weight权重使用;另一种求weight的方式就是attention了!
参考:
1、https://www.bilibili.com/video/BV1ff421q7sC/?p=2&spm_id_from=pageDriver&vd_source=241a5bcb1c13e6828e519dd1f78f35b2
2、https://llava-vl.github.io
3、https://www.bilibili.com/video/BV1br421K7zu/?spm_id_from=333.337.search-card.all.click&vd_source=241a5bcb1c13e6828e519dd1f78f35b2 LLaVA为什么效果好?
4、https://www.bilibili.com/video/BV1nw4m1S7nZ/?spm_id_from=333.337.search-card.all.click&vd_source=241a5bcb1c13e6828e519dd1f78f35b2 LLaVA源码解读
5、https://openai.com/index/clip/
6、https://www.bilibili.com/video/BV1EJ4m1s7bk/?spm_id_from=pageDriver&vd_source=241a5bcb1c13e6828e519dd1f78f35b2 llava启动部署

 浙公网安备 33010602011771号
浙公网安备 33010602011771号