LLM大模型:推理优化-vLLM显存使用优化
1、众所周知,transformer架构取得了巨大的成功,核心原因之一就是attention的引入。当年那篇论文的名称就叫attention is all you need,可见attention机制在transformer中的巨大作用!attention的计算示意图如下:
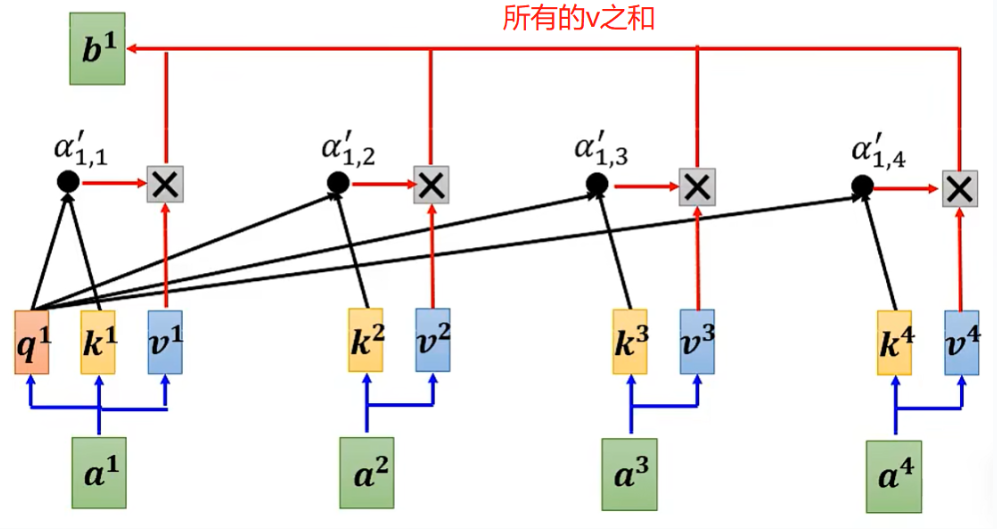
同一个sequence中,每个token的q会和其他所有token的k求内积,得到相似度,然后作为各自v的权重,最终把每个带权重的v相加,就得到了该token的v向量,举例: “我喜欢吃水果,比如苹果、菠萝、西瓜、梨、李子等”。水果的q要和其他所有token的k求内积,结果作为v的权重,最后叠加所有token的v就是水果这个token的最终v向量; 很明显,这里的水果代指的是苹果、菠萝、西瓜、梨、李子,所以正常情况下,水果q和苹果、菠萝、西瓜、梨、李子这些token的k很接近,那么内积的值就比较高,意味者权重大,最终水果v中包含苹果、菠萝、西瓜、梨、李子这些token的v就多,也就是水果v中包含的主要信息就是苹果、菠萝、西瓜、梨、李子这些token的v[其他token的v在水果v的值很小,可以忽略不记];这就是attention的精髓所在:每个token都会根据context调整自己的v值,达到“千人千面”的效果!这也是区分“苹果”到底是可以吃的水果还是电子产品的方法;后续如果有新token加入,现有token之间的q、k内积不需要重新计算了,让新token的q乘以现有token的k,然后用同样的方法更新新token的v向量即可,这就是所谓的kv cache!以13B模型为例,推理时的显存耗费大致如下:

所有parameters占用26GB(应该是FP16,一个参数占用2byte,13B参数占用26GB),kv cache大约占用了12GB、30%的显存;其中kv cache可以用这个公式估算:
- Memory=batch_size * seq_length * hidden_size * layers * 2 * 2 ; 第一个2是key + value的vector都要cache,第二个2是fp16;
这两大块显存中,parameters占用是刚性的,只要参数量不减少,这个部分显存是没法节约的(除非INT8甚至INT4量化)!剩下的就是kv cache了,用vllm官网的话说:As a result, efficiently managing the KV cache presents a significant challenge. We find that existing systems waste 60% – 80% of memory due to fragmentation and over-reservation. kv cache浪费了60%~80%的显存,原因如下:
- 预分配显存,但不会用到;比如根据max token = 512,就分配存放512个token的显存,但实际可能第200个token时回答就结束了,剩下的312个token存放空间全浪费
- 预分配显存,但暂时没用到;比如刚开始分配512个空间,但token是一个一个生成的,刚开始是用不了512个token的,只有等到生成快结束时才会用完512的存储空间
- 显存之间的间隔碎片,不足以预分配给下个文本生成。
以上问题导致了kv cache方式对显存的实际利用只有20%~40%,怎么提升显存利用率了?
2、记得以前学操作系统时,内存管理是非常重要的一个核心功能。内存是有限的,但是用户想要运营的app是无限的,怎么尽可能提高内存利用率,让有限的内存满足用户无限的需求了?
(1)page:为了减少内存浪费,需要把内存切分成N个小分,有app需要的时候就提供多个小分内存供其使用,每一小分就是一个page,大小为4KB. 同理,为了节约显存的使用,也可以人为把显存切分成多个小块,每个小块在需要的时候才分配。
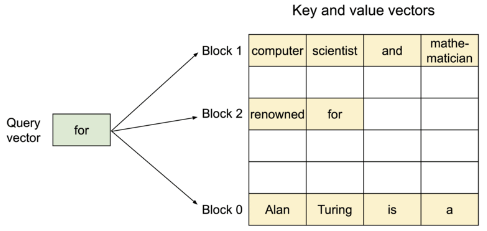
如上图所示:显存被切分为多个block,每个block最多存放4个token。block按需分配,就算浪费,最多闲置3个token的空间[自助餐都吃过吧?有些商家为了防止用户浪费,每份食物的量都很少,提倡多拿,就是这个道理]!官方的数据:In practice, this results in near-optimal memory usage, with a mere waste of under 4%. This boost in memory efficiency proves highly beneficial: It allows the system to batch more sequences together, increase GPU utilization, and thereby significantly increase the throughput as shown in the performance result above. 采用小的block按需分配内存,浪费降到了4%;
(2)内存浪费的问题解决了,碎片化怎么办了?搞IT的人都直到的基本数据结构:链表!这种数据结构相比数组,不需要连续的内存,只需要下一个数据节点的内存地址即可,所以链表完全可以被使用在碎片化的内存中存放数据;对于碎片化的显存,可以采用同样的思路充分利用起来,方案如下:
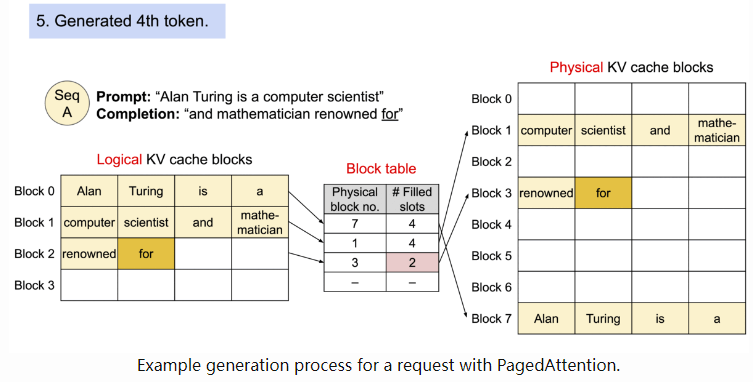
建立一个映射表block table,记录logical kv cache block和physical kv cache block之间的对应关系;physical kv cache block之间可以是不连续的、碎片化的,但只要正确的位置被记录在block table(本质就是个hashmap,时间复杂度仅为O(1)),程序在读取的时候就能找到正确的数据;
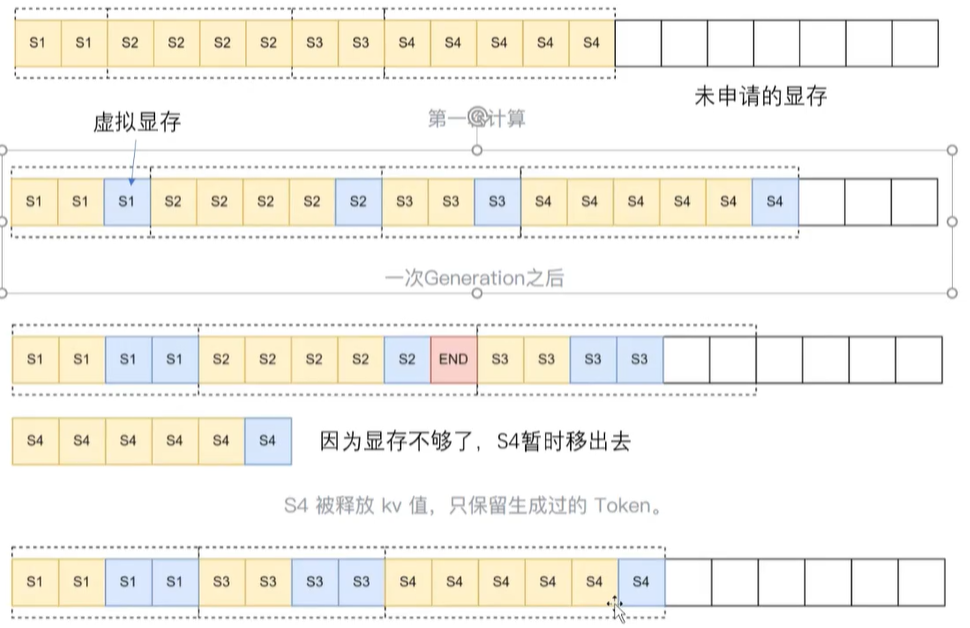
利用logical KV cache,不同的prompt物理上可以分散开来,但是逻辑上完全是紧凑连接的!
(3)block 共享:离线部署大模型上线后,为了和用户需求对齐,需要收集用户的个人偏好,然后通过DPO的方式微调,所以同一个prompt,可能会生成2~3个不同的答案,让用户选择最喜欢的那个!问题又来了:同时生成2~3个答案,怎么提升速度了?
假如promt是“the future of artificial intelligence is”,回答有两个,如下:
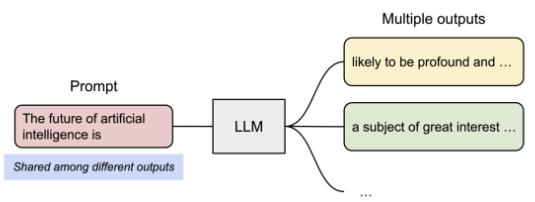
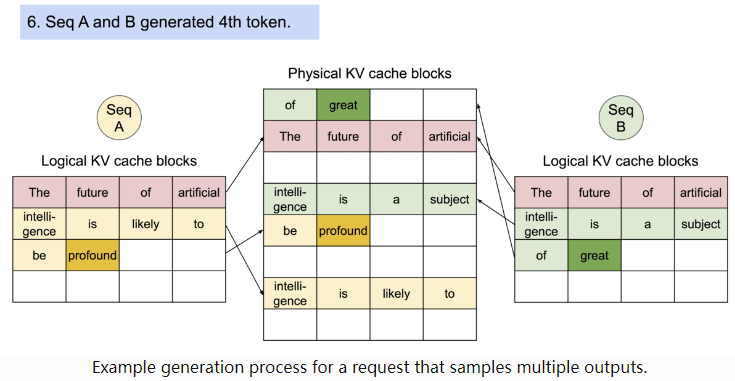
显存分配和使用如下:prompt相同部分存放的block共享,后续的生成一旦发生分歧,变得不一样,那么开始分配新的block,两个回答分别在新的block中存储,这就是copy on wirte!
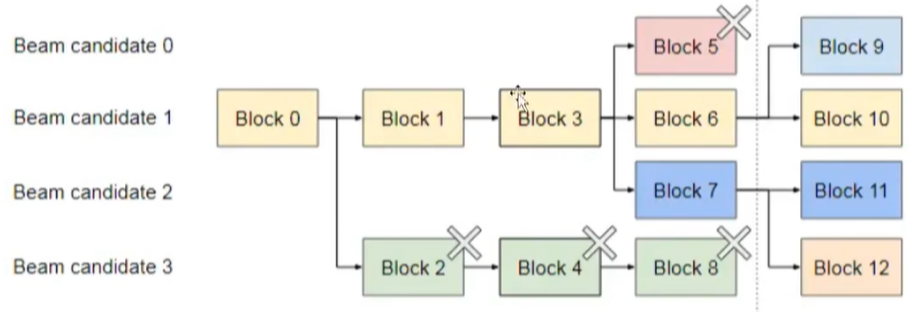
(4)除了合理分配显存,回收已使用显存也很重要,毕竟开源和节流两手都要抓、都要硬的嘛!jvm有GC机制,对于后续不再使用的各种变量都会删除,释放内存,这点VLLM完全可以借鉴的嘛!beam search就是个很好的机制:对于answer,可能有多条路径,只保留最终完整answer的路径,其他路径全都删除,释放显存!
3、上述的策略是显存的合理使用与释放,vllm还有另一个策略:batching!先举个例子:比如一个饭店很火爆,客人很多,但是饭店的传菜员有限:如果后厨每做好一道菜就让传菜员上菜,人手完全不够,传菜员会在后厨和客户餐厅之间来回疲于奔命,所以只能退而求其次:给每个传菜员准备一个小推车,后厨做好的菜先放小推车上,等推车装满后传菜员一次性把这些菜送到不同客户的桌上,这样可以极大增加单个传菜员的吞吐量!同理,一个在线的问答系统,可能有很多用户都在提问,bakend为了提升吞吐量,会凑够一定数量的prompt后cpu才会从内存传输到显存,这样可以提升cpu和gpu的效率,详细的图示如下:
假设3个prompt分别是:
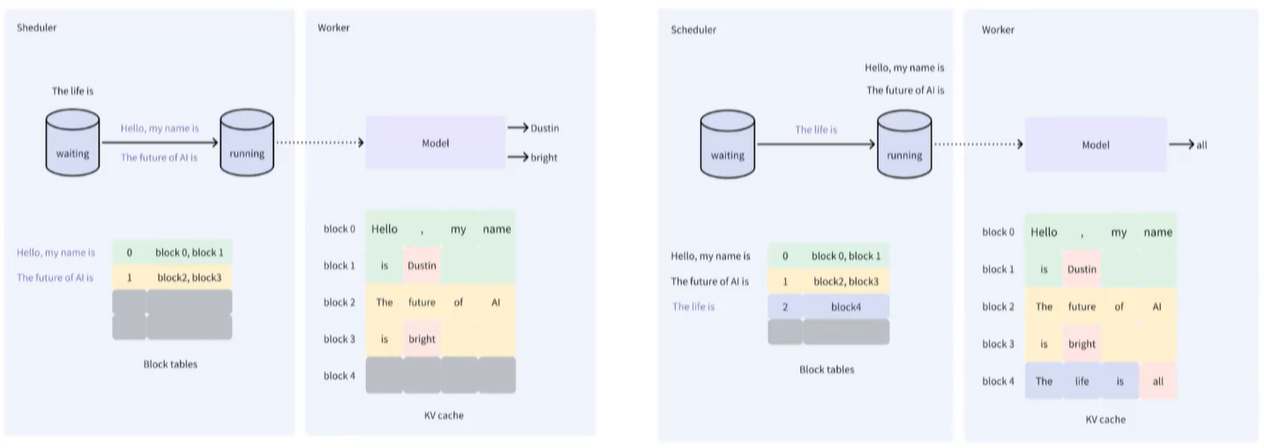
scheduler在内存,cpu负责调度;worker在显存,gpu负责执行计算!S0和S1凑成一个batch,cpu送入gpu开始执行,执行完毕后cpu再把S2从内存输送到gpu继续执行!
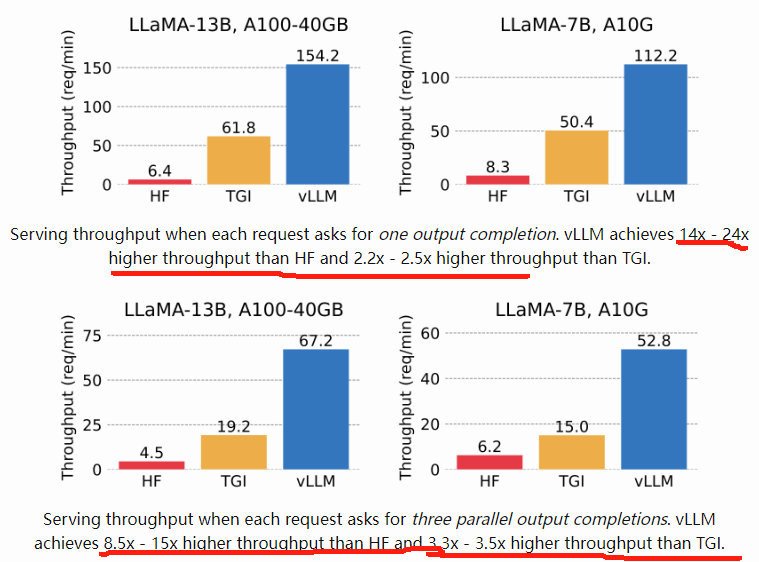
4、官方的效果数据:In our experiments, vLLM achieves up to 24x higher throughput compared to HF and up to 3.5x higher throughput than TGI.
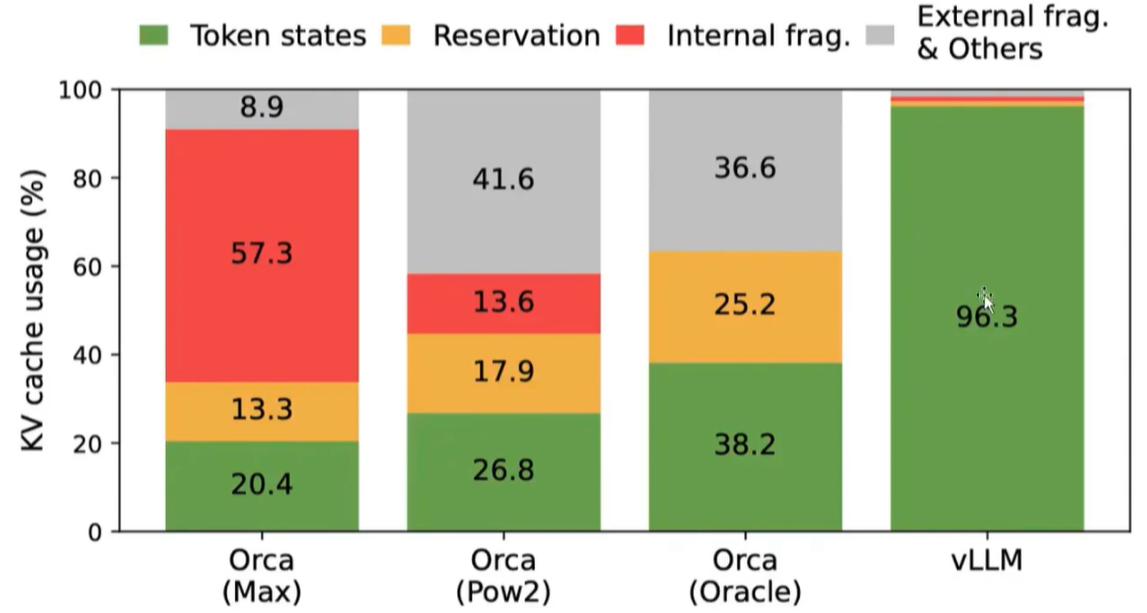
VLLM显存的利用率一骑绝尘:
5、具体实操,vllm官方已经提供了现成的API直接调用即可:这里的prompts是可以一次输入多条的,vllm框架可以根据上述的各种策略合理安排这些prompts的执行,完全不需要用户自己操心!
from vllm import LLM, SamplingParams prompts = [ "怎么用IDA打开二进制文件?", "frida hook失败了怎么办?", "sql map怎么查找sql注入点?", "怎么逆向app和服务器之间的通信协议?", ] sampling_params = SamplingParams(temperature=0.8, top_p=0.95, max_tokens=512) llm = LLM(model="/root/huggingface/secgpt", trust_remote_code=True) outputs = llm.generate(prompts, sampling_params) # Print the outputs. for output in outputs: prompt = output.prompt generated_text = output.outputs[0].text print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
5、注意,LLM infer速度的两大评价指标:时延和吞吐;vllm做的显存优化,并未对模型做本身的parameter做优化,所以LLM infer的时延并未减少!但是:因为优化了显存的使用,单位时间内处理的请求数增加了,换句话说吞吐增加了,给用户的感觉就是效率提升!
参考:
1、https://blog.vllm.ai/2023/06/20/vllm.html 官方介绍
2、https://www.bilibili.com/video/BV1kx4y1x7bu/?spm_id_from=333.337.search-card.all.click&vd_source=241a5bcb1c13e6828e519dd1f78f35b2 怎么加快大模型推理?10分钟学懂VLLM内部原理,KV Cache,PageAttention
3、https://aibyhand.substack.com/ AI by hand

 浙公网安备 33010602011771号
浙公网安备 33010602011771号