LLM大模型: 常用的数据清洗方法总结
LLM的三大要素:
- 算力:算力的本质是拼财力,普通人是无力改变的;
- 算法/模型结构:目前最流行的还是transformer架构, 各种LLM都是基于transformer改细节,暂时没有用新的框架替代transformer。至于后续manba会不会替代transformer架构,有待观察!
- 数据:这块是做LLM pre-train或fine-tune最大的苦力活,做这块业务的研发堪比苦力强~~~ 以前做传统数据挖掘和NLP,80%的时间都花在了数据的采集和清洗上。没想到现在搞LLM,虽说比以前好些,还是要花大量时间来采集和清洗各种数据,真的是造孽啊.......
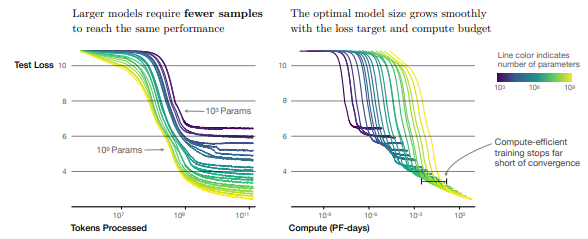
根据scanling law,tokens越多、模型越大、计算量越大,loss就越小!所以大量的优质数据是必不可少的!(从下图来看,预训练阶段,loss降到2以内就差不多了)
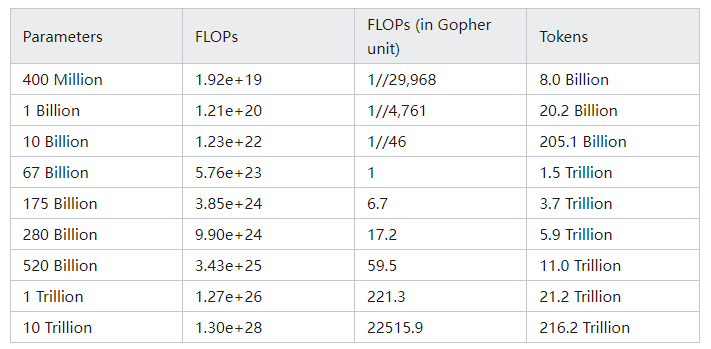
pre-train所需的参数量(不含embedding层,只有attention和FFN):
在安全垂直领域,数据清洗的核心思路总结如下:
- 质量过滤:数据质量低,模型生成的数据会前言不搭后语,前后没任何逻辑性可言
- 分类器过滤:用传统的分类器对文章打分,接近1的就是质量好的文章,可以人为设定一个阈值,比如0.8,超过阈值的就是高质量文章。传闻GPT-3在训练时用的数据就是使用了分类器精选优质数据;问题又来了:分类器也需要训练数据啊,”冷启动“阶段的数据哪来了?可以从一些权威的网站,比如维基百科、arxiv.org等,这些站点的文章作为正样本,人工选一些 不入流的N线网站文章作为作为负样本训练分类器
- 人为设定规则:比如去掉网页标签、 、%20、\u3000等无用字符;
- Perplexity困惑度:Perplexity本质是根据之前所有的token预测下一个token生成的概率值,比如 I am a 这三个token后面跟上student的概率较大,跟上air的概率很小,如果后面街上了air,那么这份语料的质量就大打折扣了,可以直接去掉啦!困惑都计算公式:
![]()
示例代码如下:
import torch from transformers import GPT2LMHeadModel, GPT2Tokenizer import math # 加载预训练的GPT-2模型和分词器 model_name = 'gpt2' model = GPT2LMHeadModel.from_pretrained(model_name) tokenizer = GPT2Tokenizer.from_pretrained(model_name) # 准备测试集文本 test_texts = [ "I am a student. I go to school everyday cause I like every of my classmates and teachers", "Mike is a software engineer,he programs on working days. he has very high skill to produce good quality software!", "haha, I adrt gqsf fgwf dgwa wuklala.", "The quick brown fox jumps over a lazy dog, the dog didn't take any actions." ] def calculate_perplexity(model, tokenizer, text): model.eval() inputs = tokenizer(text, return_tensors='pt') with torch.no_grad(): outputs = model(**inputs, labels=inputs['input_ids']) loss = outputs.loss perplexity = torch.exp(loss) return perplexity.item() # 设置困惑度阈值 perplexity_threshold = 200 filtered_texts = [] for text in test_texts: ppl = calculate_perplexity(model, tokenizer, text) if ppl < perplexity_threshold: filtered_texts.append((text, ppl)) print(f"Text: {text}, Perplexity: {ppl}") print("\nFiltered Texts:") for text, ppl in filtered_texts: print(f"Text: {text}, Perplexity: {ppl}")
结果:质量差的文本被正确筛选出来!
![]()
注意:GPT2对中文支持很差,实际操作时建议换成千问、chatglm等国产大模型!
- 利用统计特征过滤:安全领域有些出名的论坛,比如看雪、52pojie、先知等,有部分网友发帖并不是做技术分享,而是灌水/打广告等,这部分语料也是要去掉的,可以根据标点符号分布、符号字比(Symbol-to-WordRatio)、文本长度等过滤
- 冗余去重:互联网有部分人自己创作内容的能力差,只会转载、洗稿,导致爬虫爬取的数据大量重复。这些数据用于训练时会让loss明显降低,但这是过拟合,模型生成数据时会明显倾向于重复的数据,陷入重复循环(RepetitionLoops),无法回答其他问题,所以一定要去重。具体操作时,面临一个颗粒度的选择:句子、段落和文章!句子颗粒度去重最精细,但是数量巨大,我的算力不够。所以我个人最终选择段落和文本的颗粒度去重!大量文本去重的算法思路有:
- 利用向量数据库:先用embedding模型把文本转成向量,然后存储向量数据库;每个新向量存入向量数据库时先计算一下库里面有没有相似度大于阈值(比如0.8)的向量,没有再入库;有就说明重复了,直接丢弃。等所有的文本都这么操作一次后,向量数据库的数据就是唯一的啦!这种思路本质是利用向量数据库去重
- 和google对网页去重的算法一样:simhash!
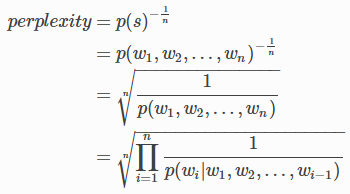

总的来讲:simhash的计算量小于使用向量数据库的计算量,所以这里选择simhash去重!核心demo代码如下:
from simhash import Simhash, SimhashIndex # 示例中文文本数据 texts = [ "rerank: 经过第一步使用cosin余弦相似度从密集向量数据库 + keyword search(稀疏向量召回)初步召回top K相似度的文本,按理来说就可以让LLM根据用户的query + 召回的context生成最终答案了,还要这个rerank干啥了?实际操作时,还是会发现一些问题:包含正确答案的文本在context中的排名可能并不靠前。比如query = “清华大学在哪座城市?” 。正确答案肯定是“北京”啦!但实际召回的context中包含北京的文本不一定排在前面,可能在中间甚至后面,给最后一个LLM输入的context会很大,直接导致LLM需要处理很长的文本,推理效率低不说,还容易出错,核心问题还是在于:初步召回的context还是有进一步压缩提炼的空间!造成这种现象的原因是啥了", "rerank: 经过第一步使用sim相似度从密集向量数据库 +关键词初步召回K个相似度的文本,按理来说就可以让LLM根据用户的问题 + 召回的文本生成最终答案了,还要这个重排干啥了?实际操作时,还是会发现一些问题:包含正确答案的文本在context中的排名可能并不靠前。比如问题 = “北京大学在哪座城市?” 。正确答案肯定是“北京”啦!但实际召回的context中包含北京的文本不一定排在前面,可能在中间甚至后面,给最后一个LLM输入的context会很大,直接导致LLM需要处理很长的文本,推理效率低不说,还容易出错,核心问题还是在于:初步召回的context还是有进一步压缩提炼的空间!造成这种现象的原因是啥了", "利用cosin求两个向量的相似度,本质是看两个向量的距离。比如“北京”、“上海”、“深圳”这些都是中国的一线大城市,这3个词的嵌入向量的余弦相似度会很近,所以使用cosin召回的时候也可能把“上海”、“深圳”这些不是正确答案的sentence召回,所以要用tf-idf这类稀疏向量补充召回部分向量,整个过程称为 hybrid search。经过hybird search后,召回的context变多,给最后一步的LLM生成最终答案带来了麻烦,所以需要进一步从context中继续提炼,优中选优!比如初步召回20条,需要通过重排选择更接近的3~5条,这个过程就是rerank!", "利用距离求两个向量的相似度,本质是看两个向量的距离。比如“北京”、“上海”、“深圳”这些都是中国的一线大城市,这3个词的embedding的cosin会很近,所以使用cosin召回的时候也可能把“上海”、“深圳”这些不是正确答案的sentence召回,所以要用tf-idf这类稀疏向量补充召回部分向量,整个过程称为 混合检索。经过混合检索后,召回的上下文变多,给最后一步的LLM生成最终答案带来了麻烦,所以需要进一步从context中继续提炼,优中选优!比如初步召回20条,需要通过rerank选择更接近的3~5条,这个过程就是rerank!", "确定要做rerank后,怎么做才能达到既定的目的?要想明白这个问题,还要回到最初的动机:cosin计算的是两个向量的距离,只考虑语义相似,不考虑字面符号是否一致;而稀疏检索tf-idf只考虑字面的符号, 不考虑语义,怎么整合这两种retrieve的优势,摒弃其劣势了?这就需要用到传统NLP常见的手段了:classifier", ] # 计算每个文本的Simhash值 simhashes = [(str(i), Simhash(text)) for i, text in enumerate(texts)] # 创建Simhash索引 index = SimhashIndex(simhashes, k=10) # 检查文本是否重复 def is_duplicate(new_text, index): new_simhash = Simhash(new_text) duplicates = index.get_near_dups(new_simhash) return duplicates # 检查每个文本是否重复 for i, text in enumerate(texts): duplicates = is_duplicate(text, index) if len(duplicates) > 1: # 因为自己也会在重复列表中,所以长度大于1 print(f"文本 {i} 是重复的,重复文本索引:{duplicates}") else: print(f"文本 {i} 没有重复。") # 例如,添加一个新文本并检查是否重复 new_text = "按理来说就可以让LLM根据用户的query + 召回的context生成最终答案了,还要这个rerank干啥了?实际操作时,还是会发现一些问题:包含正确答案的文本在context中的排名可能并不靠前." if is_duplicate(new_text, index): print("新文本是重复的。") else: print("新文本没有重复。") # 如果没有重复,则将其添加到索引中 index.add(str(len(texts)), Simhash(new_text))
我这里执行的结果:
文本 0 是重复的,重复文本索引:['1', '0'] 文本 1 是重复的,重复文本索引:['1', '0'] 文本 2 是重复的,重复文本索引:['3', '2'] 文本 3 是重复的,重复文本索引:['3', '2'] 文本 4 没有重复。 新文本没有重复。
注意事项:
- 看了很多资料,说是k=3就能判断是否重复。但就我个人的实测来看,3显然不够,我这里把k提升到了10就能准确找到重复的文档了!当然,如果只是简单复制粘贴,没有对内容做实质性地更改,k=3也能查重
- 对文本计算hash前,建议先用正则去掉换行、回车、逗号、句号、感叹号、问号等符号,只保留文字和数字,减少对hash值的干扰
- 对于长篇的文章分段,可以使用自然段落,也可以使用语义聚类的方式划分段落,详见:https://www.cnblogs.com/theseventhson/p/18279980
参考:
1、https://arxiv.org/pdf/2001.08361 scaling law
2、https://geek.digiasset.org/pages/affiliate/text-simhash-good-re-process-deep_21Apr03114628313403/ https://www.cnblogs.com/maybe2030/p/5203186.html#_label4 simhash原理
3、https://leons.im/posts/a-python-implementation-of-simhash-algorithm/ A Python Implementation of Simhash Algorithm
4、https://zhuanlan.zhihu.com/p/636812912 LLM训练指南:Token及模型参数准备
5、https://www.bilibili.com/video/BV1Gg4y1U7uc/?spm_id_from=333.337.search-card.all.click&vd_source=241a5bcb1c13e6828e519dd1f78f35b2 opencompass大模型测评

 浙公网安备 33010602011771号
浙公网安备 33010602011771号