LLM大模型: RAG的上下文语义聚类retrieval — GraphaRAG
截至目前,RAG最大的缺陷就是无法回答总结性的问题了。上篇文章(https://www.cnblogs.com/theseventhson/p/18281227)介绍了RAPTOR方法(利用GMM高斯混合模型对chunk聚类,然后再用LLM对每个cluster概括总结摘要)提取cluster的语义,借此来回答概括、总结性的问题,最核心的步骤就是聚类了:把语义接近的token用GMM聚集到一起,同时利用LLM对这些token做summerise,retrieval的时候先匹配上层的summerise,再匹配下一层包含细节的chunk,做到不同颗粒度都遍历一次,结果滴水不漏!这个思路本身是对的,就连sematic chunk的思路也是这样的,只不过sematic chunk对于chunk聚类的方式不同罢了。顺着这个思路,微软搞出了另一种聚类和retrieve的方式:GraphRAG!先说结论:GraphRAG的核心思路和RAPTOR完全一样:聚类 -> 提取cluster的summerise -> summerise的embedding入库 - > query匹配;最大的区别就在于:GraphRAG是通过命名实体识别NER等方式提取chunk的关键信息,利用knowledge graph组成图,然后用社区发现的算法对图的节点做聚类,以此把语义接近的token聚拢在一起。GraphRAG 具体是怎么做的了?有哪些注意事项?整个详细的流程都在论文公布了:https://arxiv.org/pdf/2404.16130
整个GraphRAG的流程如下:
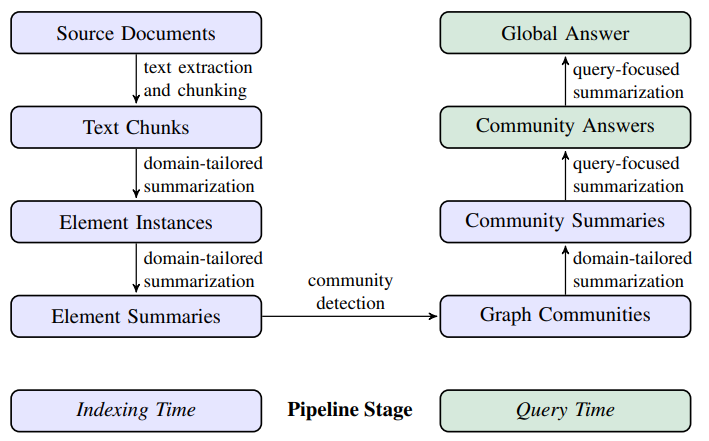
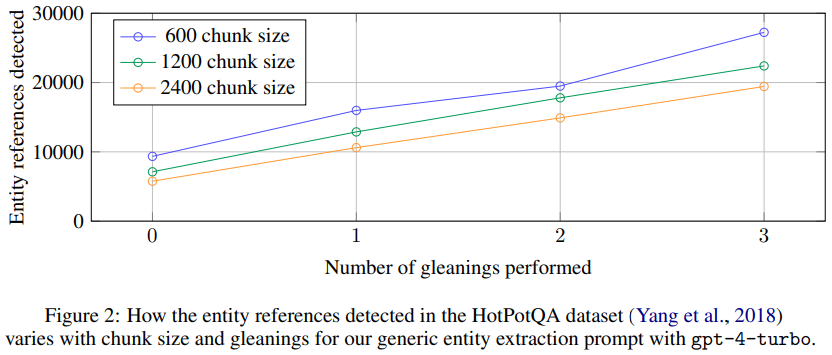
1、Source Documents → Text Chunks:A fundamental design decision is the granularity with which input texts extracted from source documents should be split into text chunks for processing. In the following step, each of these chunks will be passed to a set of LLM prompts designed to extract the various elements of a graph index. Longer text chunks require fewer LLM calls for such extraction, but suffer from the recall degradation of longer LLM context windows (Kuratov et al., 2024; Liu et al., 2023). This behavior can be observed in Figure 2 in the case of a single extraction round (i.e., with zero gleanings): on a sample dataset (HotPotQA, Yang et al., 2018), using a chunk size of 600 token extracted almost twice as many entity references as when using a chunk size of 2400. While more references are generally better, any extraction process needs to balance recall and precision for the target activity.
第一步先把原文档分割,分割的后的文档会用LLM提取命名实体、实体关系等。chunk size过大会导致扣取的实体和关系偏少,召回率降低。这里以chunk size=600和2400分别做测试,600的chunk size召回了两倍的实体!
2、Text Chunks → Element Instances The baseline requirement for this step is to identify and extract instances of graph nodes and edges from each chunk of source text. We do this using a multipart LLM prompt that first identifies all entities in the text, including their name, type, and description, before identifying all relationships between clearly-related entities, including the source and target entities and a description of their relationship. Both kinds of element instance are output in a single list of delimited tuples. The primary opportunity to tailor this prompt to the domain of the document corpus lies in the choice of few-shot examples provided to the LLM for in-context learning (Brown et al., 2020).For example, while our default prompt extracting the broad class of “named entities” like people, places, and organizations is generally applicable, domains with specialized knowledge (e.g., science, medicine, law) will benefit from few-shot examples specialized to those domains. We also support a secondary extraction prompt for any additional covariates we would like to associate with the extracted node instances. Our default covariate prompt aims to extract claims linked to detected entities, including the subject, object, type, description, source text span, and start and end dates. To balance the needs of efficiency and quality, we use multiple rounds of “gleanings”, up to a specified maximum, to encourage the LLM to detect any additional entities it may have missed on prior extraction rounds. This is a multi-stage process in which we first ask the LLM to assess whether all entities were extracted, using a logit bias of 100 to force a yes/no decision. If the LLM responds that entities were missed, then a continuation indicating that “MANY entities were missed in the last extraction” encourages the LLM to glean these missing entities. This approach allows us to use larger chunk sizes without a drop in quality (Figure 2) or the forced introduction of noise.
-
识别和提取图节点和边实例:
- 从每个源文本块中识别和提取图节点和边的实例。
- 使用一个LLM提示来完成这项工作。首先识别文本中的所有实体,包括它们的名称、类型和描述;然后识别明确、清晰相关实体之间的所有关系,包括源实体和目标实体以及它们关系的描述。
- 这两类元素实例输出为一个包含分隔tuple的list。
-
领域定制prompt:
- 某些领域需要定制prompt,提供few-shot的示例,比如有专业知识的领域(如科学、医学、法律)等
-
secondary extraction prompt:
- 首先提取人名、地名、组织名
- 其次提取与节点实例有额外关联关系 additional covariates的事务,比如与检测到的实体相关的声明,包括主题、客体、类型、描述、源文本范围以及开始和结束日期。
-
多轮提取(gleanings):
- 为了平衡效率和质量,使用多轮“gleanings”提取,直至达到指定的最大轮数,避免重要的entity遗漏。
- 这是一个多阶段过程,首先让LLM评估是否所有实体都已提取,使用 logit bias of 100 强制做出是/否决定。
- 如果LLM响应说有实体遗漏,则继续在promt加上 “ MANY entities were missed in the last extraction” ,让LLM提取遗漏的实体。
- 允许使用更大的文本块大小而不会降低质量(如图2所示)或强行引入噪音。
例如有一篇文章介绍二进制逆向的:
- 第一轮:提取专业术语,比如 二进制、frida、window、android等
- 关系识别:二进制逆向包括windows逆向、android逆向
- 次要提取secondary extraction:专业术语的描述,比如 android逆向是解压apk包,反编译class和so文件,分析其中的重要代码,可以借助frida、ida、android killer等专业工具
- 多轮提取:识别出前面几轮遗漏的重要实体
3、Element Instances → Element Summaries The use of an LLM to “extract” descriptions of entities, relationships, and claims represented in source texts is already a form of abstractive summarization, relying on the LLM to create independently meaningful summaries of concepts that may be implied but not stated by the text itself (e.g., the presence of implied relationships). To convert all such instance-level summaries into single blocks of descriptive text for each graph element (i.e., entity node, relationship edge, and claim covariate) requires a further round of LLM summarization over matching groups of instances. A potential concern at this stage is that the LLM may not consistently extract references to the same entity in the same text format, resulting in duplicate entity elements and thus duplicate nodes in the entity graph. However, since all closely-related “communities” of entities will be detected and summarized in the following step, and given that LLMs can understand the common entity behind multiple name variations, our overall approach is resilient to such variations provided there is sufficient connectivity from all variations to a shared set of closely-related entities. Overall, our use of rich descriptive text for homogeneous nodes in a potentially noisy graph structure is aligned with both the capabilities of LLMs and the needs of global, query-focused summarization. These qualities also differentiate our graph index from typical knowledge graphs, which rely on concise and consistent knowledge triples (subject, predicate, object) for downstream reasoning tasks.
用LLM对已经抽取的 entity node, relationship edge(包含隐藏关系), claim covariate 进一步做summerization,每个single block都做总结概括。这一步通过整合和摘要图元素实例,生成统一的描述性文本,为后续的图社区检测和全局摘要提供了一个详细且连贯的数据基础。
4、Element Summaries → Graph Communities The index created in the previous step can be modelled as an homogeneous undirected weighted graph in which entity nodes are connected by relationship edges, with edge weights representing the normalized counts of detected relationship instances. Given such a graph, a variety of community detection algorithms may be used to partition the graph into communities of nodes with stronger connections to one another than to the other nodes in the graph (e.g., see the surveys by Fortunato, 2010 and Jin et al., 2021). In our pipeline, we use Leiden (Traag et al., 2019) on account of its ability to recover hierarchical community structure of large-scale graphs efficiently (Figure 3). Each level of this hierarchy provides a community partition that covers the nodes of the graph in a mutually-exclusive, collective-exhaustive way, enabling divide-and-conquer global summarization. 这一步很关键,开始做社团发现了,核心目的还是聚类;
- 图构建:
- 将前一步中生成的元素摘要构建成一个同质无向加权图 homogeneous undirected weighted graph。
- 社区检测:
- 使用Leiden算法对图进行社区检测,划分出层次社区结构(最核心的语义聚类已完成)。
- 层次社区划分:
- 利用Leiden算法的层次社区检测能力,生成多个层级的社区划分。
- 每个层级的划分都是相互排斥的,并且覆盖了图的所有节点。
· 两个不同hop/不同层级communite聚类算法对比:

通过社区检测将图的节点组织成社区,从而为全局摘要和信息聚合提供结构化的基础。
5、Graph Communities → Community Summaries The next step is to create report-like summaries of each community in the Leiden hierarchy, using a method designed to scale to very large datasets. These summaries are independently useful in their own right as a way to understand the global structure and semantics of the dataset, and may themselves be used to make sense of a corpus in the absence of a question. For example, a user may scan through community summaries at one level looking for general themes of interest, then follow links to the reports at the lower level that provide more details for each of the subtopics. Here, however, we focus on their utility as part of a graph-based index used for answering global queries. Community summaries are generated in the following way:
- Leaf-level communities. The element summaries of a leaf-level community (nodes, edges, covariates) are prioritized and then iteratively added to the LLM context window until the token limit is reached. The prioritization is as follows: for each community edge in decreasing order of combined source and target node degree (i.e., overall prominance), add descriptions of the source node, target node, linked covariates, and the edge itself.
- Higher-level communities. If all element summaries fit within the token limit of the context window, proceed as for leaf-level communities and summarize all element summaries within the community. Otherwise, rank sub-communities in decreasing order of element summary tokens and iteratively substitute sub-community summaries (shorter) for their associated element summaries (longer) until fit within the context window is achieved.
上一步经过社区发现后,对每个node都做了聚类,划分到了合适的社区。为了匹配不同给颗粒度的query,需要对整个社区做summerization了!
- Leaf-level communities:节点、边、covariates等entity按优先级排列,然后逐步添加到LLM的上下文窗口,直到达到token限制。优先级的顺序:对于每条边,按源节点和目标节点度数降序排列(度数越大,越重要),依次添加源节点、目标节点、 linked covariates及边的描述
- Higher-level communities:如果所有元素的summaries都能在context的token限制内,则与Leaf-level communities处理方式相同,汇总社区内的所有元素的summaries。如果超出了context的token限制,则按element summary的token数降序排列子社区,并逐步用子社区摘要(较短)替换其关联的元素摘要(较长),直到符合context的限制
为啥要分层级提取summerise?还是为了匹配用户的query。用户可以浏览某个层级的社区summerise以寻找感兴趣的主题,然后通过链接查看下一级别的报告,获取每个子社区的更多详细信息。
通过生成communite summerise ,使用户能够快速了解每个社区的内容和结构。这些summerise 不仅在没有具体问题的情况下有助于理解数据集,还在回答全局查询时发挥重要作用。通过优先级排序和摘要生成,确保所有内容都在上下文窗口限制内,从而提供详细和有用的社区报告。
6、Community Summaries → Community Answers → Global Answer Given a user query, the community summaries generated in the previous step can be used to generate a final answer in a multi-stage process. The hierarchical nature of the community structure also means that questions can be answered using the community summaries from different levels, raising the question of whether a particular level in the hierarchical community structure offers the best balance of summary detail and scope for general sensemaking questions (evaluated in section 3). For a given community level, the global answer to any user query is generated as follows:
- Prepare community summaries. Community summaries are randomly shuffled and divided into chunks of pre-specified token size. This ensures relevant information is distributed across chunks, rather than concentrated (and potentially lost) in a single context window.
- Map community answers. Generate intermediate answers in parallel, one for each chunk. The LLM is also asked to generate a score between 0-100 indicating how helpful the generated answer is in answering the target question. Answers with score 0 are filtered out.
- Reduce to global answer. Intermediate community answers are sorted in descending order of helpfulness score and iteratively added into a new context window until the token limit is reached. This final context is used to generate the global answer returned to the user.
利用前一步生成的不同层次、 不同颗粒度的Community Summaries 回答用户的query,最终生成Global Answer。生成gloal answer的步骤:
- 将community summaries随机打乱,并按预先指定的大小划分为多个块。目的是确保相关信息分布在多个块中,而不是集中在单个上下文窗口中,这样可以避免重要信息的丢失
- 并行生成每个chunk的中间答案,并让LLM生成一个0到100的分数,表示生成的答案在回答目标问题时的helpful程度,去掉0分的回答
- 按helpful分数降序排列Intermediate community answers,并逐个将它们添加到新的上下文窗口,直到达到token限制,最终使用这个context生成global answer。
7、 视频号有博主实测,GraphRAG对里面默认自带的文本检测效果很好,但最大的问题在于使用openAI在线大模型的成本太高,耗费11刀!如果换成本地LLM,耗时太长(graph这种图结构更新慢),效果很差; ,所以微软开源GrapgRAG,可能是想借助“广大人民群众”的力量帮忙一起优化!
8、GraphRAG核心流程:
- 索引index流程:
- 文本单元切分:将输入文本分割成 TextUnits,每个 TextUnit 是一个可分析的单元,用于提取关键信息。
- 实体和关系提取:使用 LLM 从 TextUnits 中提取实体、关系和关键声明。如果使用本地开源LLM,至少32B以上,否则效果会很差,连entity都会识别错误!
- 图构建:构建知识图谱,使用 Leiden 算法进行实体的层次聚类。每个实体用节点表示,节点的大小和颜色分别代表实体的度数和所属社区。
- 社区总结:从下到上生成每个社区及其成员的总结summerise,帮助全局理解数据集。这些summerise可以选择性地转成embedding,存入向量数据库;
- 查询query流程:
-
-
全局搜索:当我们想了解整个语料库或数据集的整体概况时,GraphRAG 可以利用社区总结来快速推理和获取信息。这种方式适用于大范围问题,如某个主题的总体理解。
-
局部搜索:如果问题关注于某个特定的实体,GraphRAG 会向该实体的邻居(即相关实体)扩展搜索,以获得更详细和精准的答案。
-
DRIFT 搜索:这是对局部搜索的增强,除了获取邻居和相关概念,还引入了社区信息的上下文,从而提供更深入的推理和连接。
-
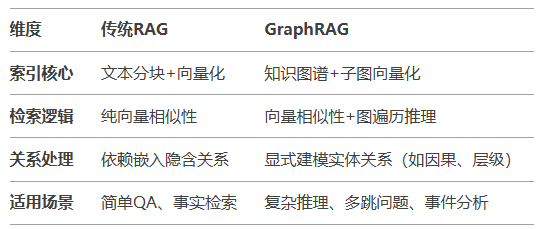
9、传统RAG和GraphRAG的对比:
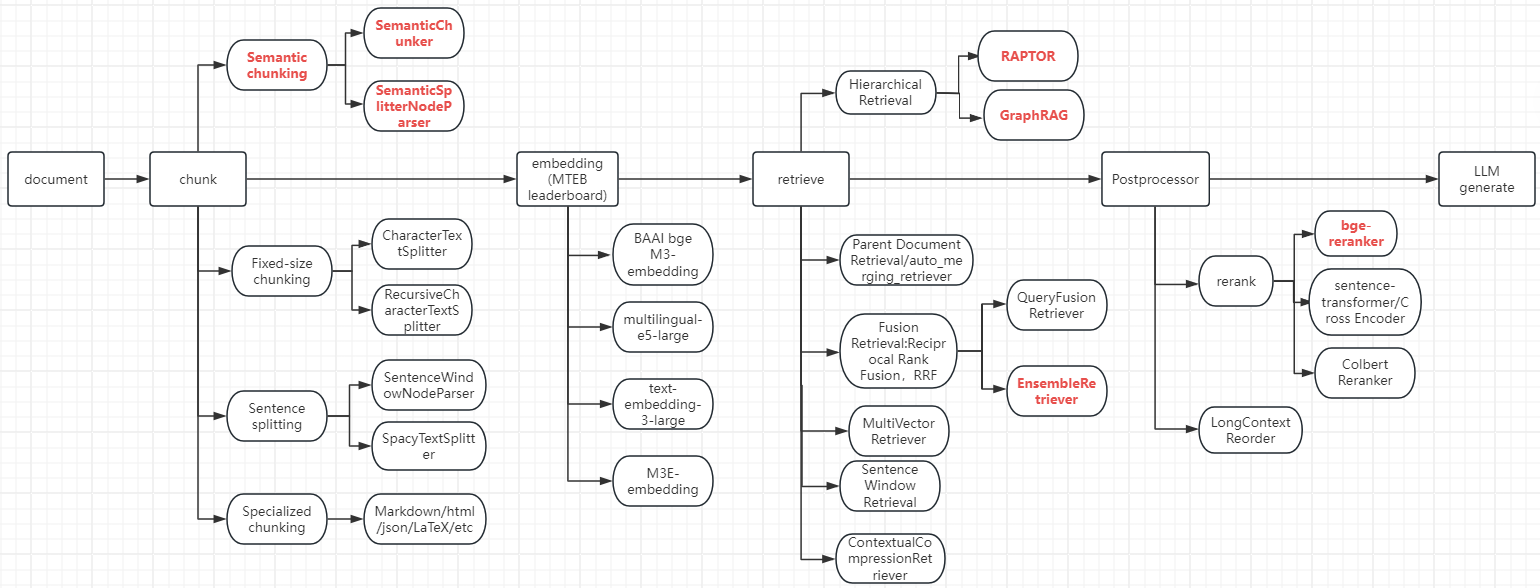
最后,最新的RAG总结如下:
参考:
1、https://www.microsoft.com/en-us/research/project/graphrag/ https://www.microsoft.com/en-us/research/blog/graphrag-unlocking-llm-discovery-on-narrative-private-data/
2、https://www.bilibili.com/video/BV1q7421o72E/?spm_id_from=333.788&vd_source=241a5bcb1c13e6828e519dd1f78f35b2 如何使用知识图谱(knowledge graph)做大模型RAG增强
3、https://arxiv.org/pdf/2404.16130 https://www.microsoft.com/en-us/research/project/graphrag/
4、https://jeongiitae.medium.com/from-rag-to-graphrag-what-is-the-graphrag-and-why-i-use-it-f75a7852c10c From RAG to GraphRAG , What is the GraphRAG and why i use it?
5、https://mp.weixin.qq.com/s/Y7XFZiytvOeeK1yk-T6PQw RAG很有潜力,但距离生产还有距离
6、https://www.bilibili.com/video/BV1Bg8pe8Ekb/?spm_id_from=333.788.recommend_more_video.0&vd_source=241a5bcb1c13e6828e519dd1f78f35b2 本地部署grapgRAG模型
https://www.bilibili.com/video/BV1Xm421g7q9/?spm_id_from=333.788.recommend_more_video.7&vd_source=241a5bcb1c13e6828e519dd1f78f35b2 本地部署grapgRAG模型
https://www.bilibili.com/video/BV1yw4m1a7Vc/?spm_id_from=333.788.recommend_more_video.1&vd_source=241a5bcb1c13e6828e519dd1f78f35b2 本地部署grapgRAG模型
7、传统RAG的缺陷:
- 知识库内容缺失:现有的文档其实回答不了用户的问题,系统有时被误导,给出的回应其实是“胡说八道”,理想情况系统应该回应类似“抱歉,我不知道”。
- TopK截断有用文档:和用户查询相关的文档因为相似度不足被TopK截断,本质上是相似度不能精确度量文档相关性。
- 上下文整合丢失:从数据库中检索到包含答案的文档,因为重排序/过滤规则等策略,导致有用的文档没有被整合到上下文中。
- 有用信息未识别:受到LLM能力限制,有价值的文档内容没有被正确识别,这通常发生在上下文中存在过多的噪音或矛盾信息时。
- 提示词格式问题:提示词给定的指令格式出现问题,导致大模型/微调模型不能识别用户的真正意图。
- 准确性不足:LLM没能充分利用或者过度利用了上下文的信息,比如给学生找老师首要考虑的是教育资源的信息,而不是具体确定是哪个老师。另外,当用户的提问过于笼统时,也会出现准确性不足的问题。
- 答案不完整:仅基于上下文提供的内容生成答案,会导致回答的内容不够完整。比如问“文档 A、B和C的主流观点是什么?”,更好的方法是分别提问并总结。
总的来看:
- 问题1-3:属于知识库工程层面的问题,可以通过完善知识库、增强知识确定性、优化上下文整合策略解决。
- 问题4-6:属于大模型自身能力的问题,依赖大模型的训练和迭代。
- 问题7:属于RAG架构问题,更有前景的思路是使用Agent引入规划能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号