LLM大模型: RAG两大核心利器: M3E-embedding和bge-rerank
RAG的效果好不好,最核心依赖两点:文本embedding语义提取的好不好,rerank的排序效果好不好(包含正确答案的文本是不是排在前面)!各自使用的环节如下:
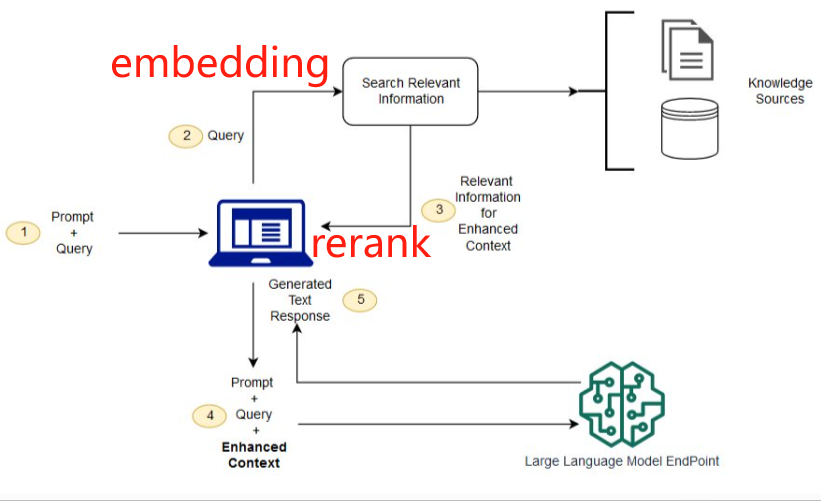
1、文本embedding的提取:理论上讲,任何transformer架构的encoder部分都可用于生成token的embedding,然后采用合适的pooling方式把整个setence中所有token的embedding融合成一个embedding。截止目前,哪个现成的LLM的encoder更适合提取整段句子的embedding了?
要想效果好,以下是必要条件:
- 模型不能太小,否则对训练预料的“”消化、承载“”能力不够,无法精准理解语义;模型也不能太大,否则过于耗费计算资源,同时还需要大量训练预料,否则会欠拟合(模型参数大小和所需token数详见scaling law)!
- 训练预料要足够,涵盖各行业、各领域;也要涵盖各种不同的类型、风格的文本(中英文、说明文、议论文、陈述文、小说、散文、诗歌)等
- 最好能提供微调的接口,利于用户使用自己特定领域的数据
截止目前,业界公认效果比较好的就是moka-ai/m3e了!以下是官方的介绍:
- Moka,此模型由 MokaAI 训练,开源和评测,训练脚本使用 uniem ,评测 BenchMark 使用 MTEB-zh
- Massive,此模型通过千万级 (2200w+) 的中文句对数据集进行训练
- Mixed,此模型支持中英双语的同质文本相似度计算,异质文本检索等功能,未来还会支持代码检索
最核心的还是训练数据了,如下:
- 中文训练集,M3E 在大规模句对数据集上的训练,包含中文百科,金融,医疗,法律,新闻,学术等多个领域共计 2200W 句对样本,数据集详见 M3E 数据集
- 英文训练集,M3E 使用 MEDI 145W 英文三元组数据集进行训练,数据集详见 MEDI 数据集,此数据集由 instructor team 提供
- 指令数据集,M3E 使用了 300W + 的指令微调数据集,这使得 M3E 对文本编码的时候可以遵从指令,这部分的工作主要被启发于 instructor-embedding (这点很牛逼,同样的sentence,可以根据不同的instruct生成不同的embedding,充分理解语义,比普通的bert模型强多了)
基础模型,还是基于bert架构:
- 基础模型,M3E 使用 hfl 实验室的 Roberta 系列模型进行训练,目前提供 small 、base和large 三个版本;只要是embedding,就离不开bert架构!
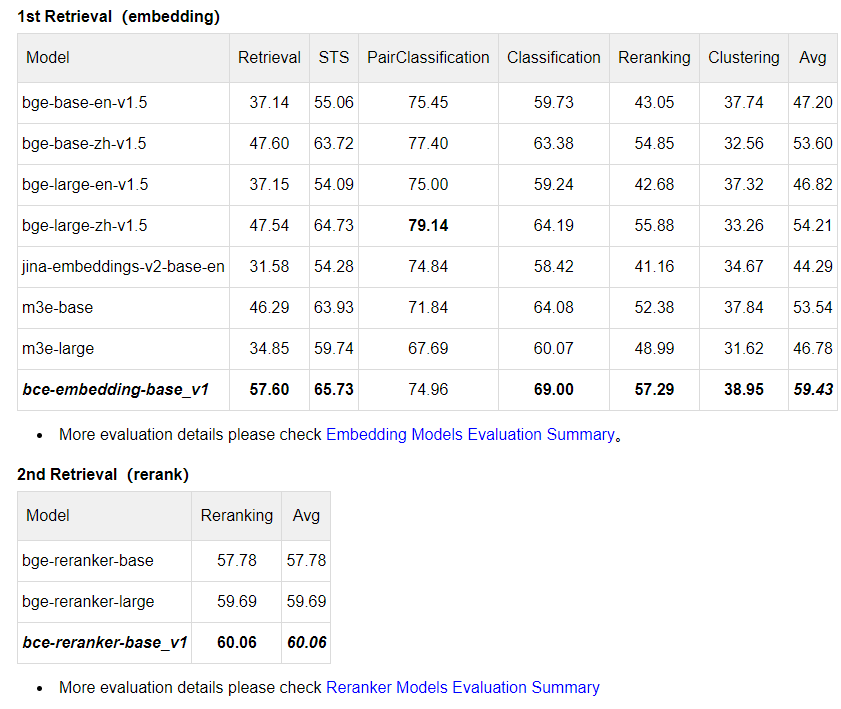
最终的效果就是:ALL IN ONE,不仅支持同质句子相似度判断,还支持异质文本检索,只需要一个模型就可以覆盖全部的应用场景,各个指标对比如下:
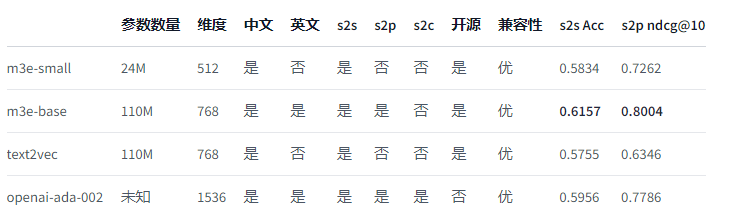
看着还是很牛逼的! M3E的配置文件 1_Pooling/config.json,有pooling的方式和embedding的dimension:这里可以看出M3E默认采用的是每个token取均值的pooling方式!
{ "word_embedding_dimension": 768, "pooling_mode_cls_token": false, "pooling_mode_mean_tokens": true, "pooling_mode_max_tokens": false, "pooling_mode_mean_sqrt_len_tokens": false }
2、rerank: 经过第一步使用cosin余弦相似度从密集向量数据库 + keyword search(稀疏向量召回)初步召回top K相似度的文本,按理来说就可以让LLM根据用户的query + 召回的context生成最终答案了,还要这个rerank干啥了?实际操作时,还是会发现一些问题:包含正确答案的文本在context中的排名可能并不靠前。比如query = “清华大学在哪座城市?” 。正确答案肯定是“北京”啦!但实际召回的context中包含北京的文本不一定排在前面,可能在中间甚至后面,给最后一个LLM输入的context会很大,直接导致LLM需要处理很长的文本,推理效率低不说,还容易出错,核心问题还是在于:初步召回的context还是有进一步压缩提炼的空间!造成这种现象的原因是啥了?
利用cosin求两个向量的相似度,本质是看两个向量的距离。比如“北京”、“上海”、“深圳”这些都是中国的一线大城市,这3个词的embedding的cosin会很近,所以使用cosin召回的时候也可能把“上海”、“深圳”这些不是正确答案的sentence召回,所以要用tf-idf这类稀疏向量补充召回部分向量,整个过程称为 hybrid search。经过hybird search后,召回的context变多,给最后一步的LLM生成最终答案带来了麻烦,所以需要进一步从context中继续提炼,优中选优!比如初步召回20条,需要通过rerank选择更接近的3~5条,这个过程就是rerank!整个流程图示如下:

确定要做rerank后,怎么做才能达到既定的目的?要想明白这个问题,还要回到最初的动机:cosin计算的是两个向量的距离,只考虑语义相似,不考虑字面符号是否一致;而稀疏检索tf-idf只考虑字面的符号, 不考虑语义,怎么整合这两种retrieve的优势,摒弃其劣势了?这就需要用到传统NLP常见的手段了:classifier!
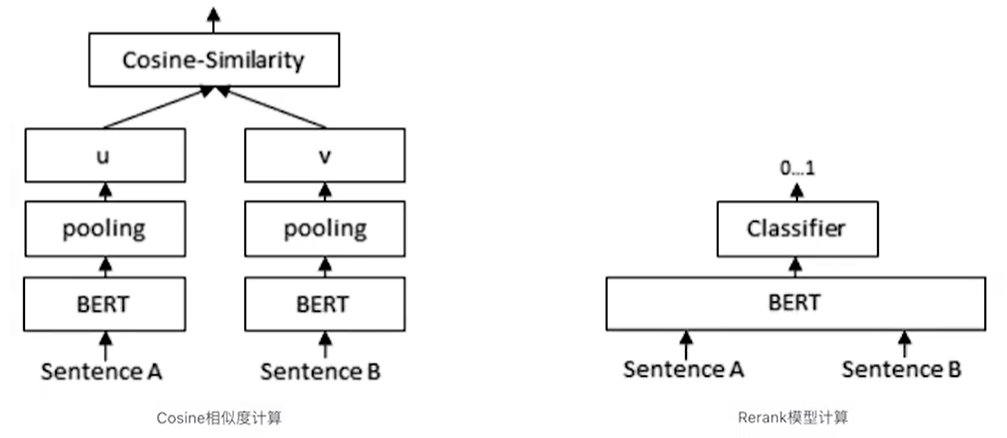
如上图右边所示:两个sentence先进入同一个bert,lm_head用一个二分类来判断这两个sentence是否匹配!右边这种classifier判断是否匹配比左边这种cosin判断是否相似更准确,原因又是啥了?两个sentence首尾拼接进入bert后:
- 先要计算attention计算token之间的相似度,再进入FFN生成非线性特征,更利于lm_head的分类
- 两个sentence的特征能两两组合交互生成新的维度特征,捕捉复杂的细节关系
- cosin相似度的计算是基于整个sentence的embedding,但这种embeeding涉及到pooling,这个过程会有一定的信息丢失,造成精度下降
上面两个角度是从特征维度考虑的,从模型维度看,还有以下优点:
- cosin是没有参数可调节的,但classifier可以通过调节参数,让模型的目标函数主动适配特定的任务和数据分布。具体到这里,可以让模型生成的答案主动适配query;可以简单理解为answer对query的1v1 有针对性的VIP服务!
当然,既然classifier的准确性提高了,为啥不从一开始就用这种classifier来召回生成context了?还用cosin计算相似度干嘛了?这里就是计算量的问题了!cosin的计算量远比classifier小,并且可以事先离线计算embedding存入向量数据库,所以适合第一步从大量数据中初步召回数十条;classifier精准度高,但计算量大,适合从初步召回的数十条context中进一步精选出几条包含或最接正确答案的context;
原理搞清楚了,接下来看代码:
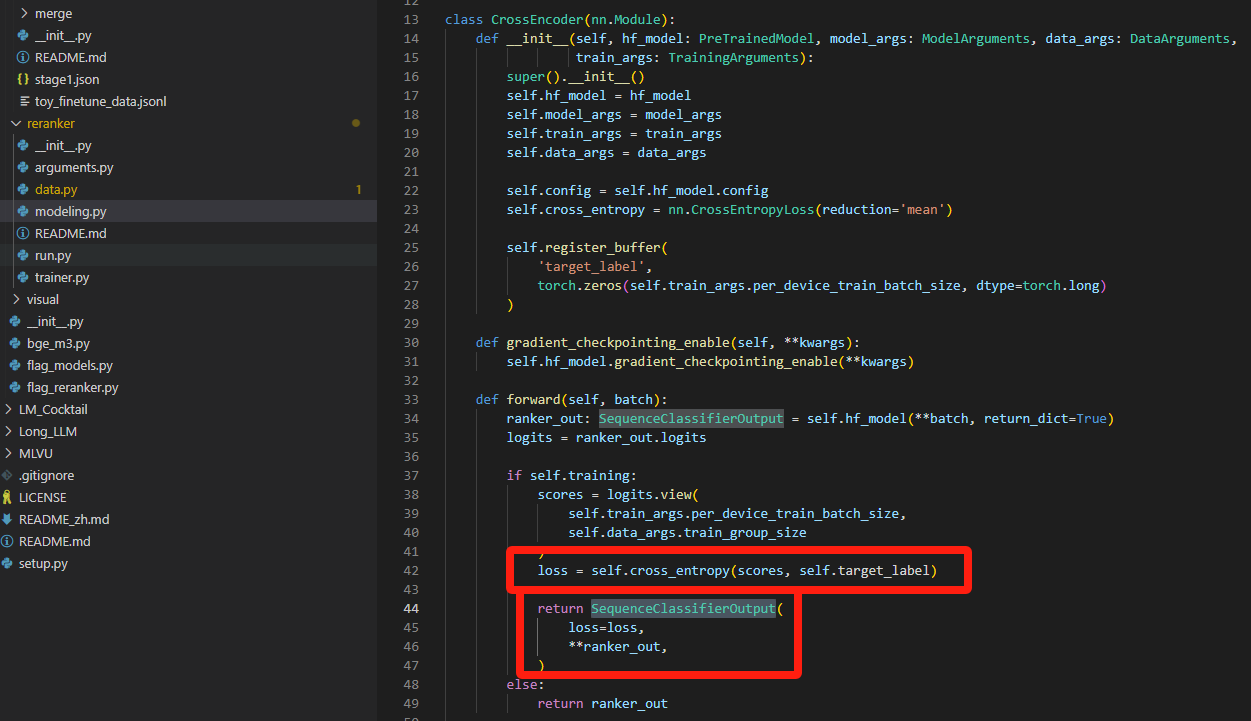
getitem方法要对query、pos、neg三个不同的答案按照一定的逻辑配对,后续的loss才知道是0还是1;
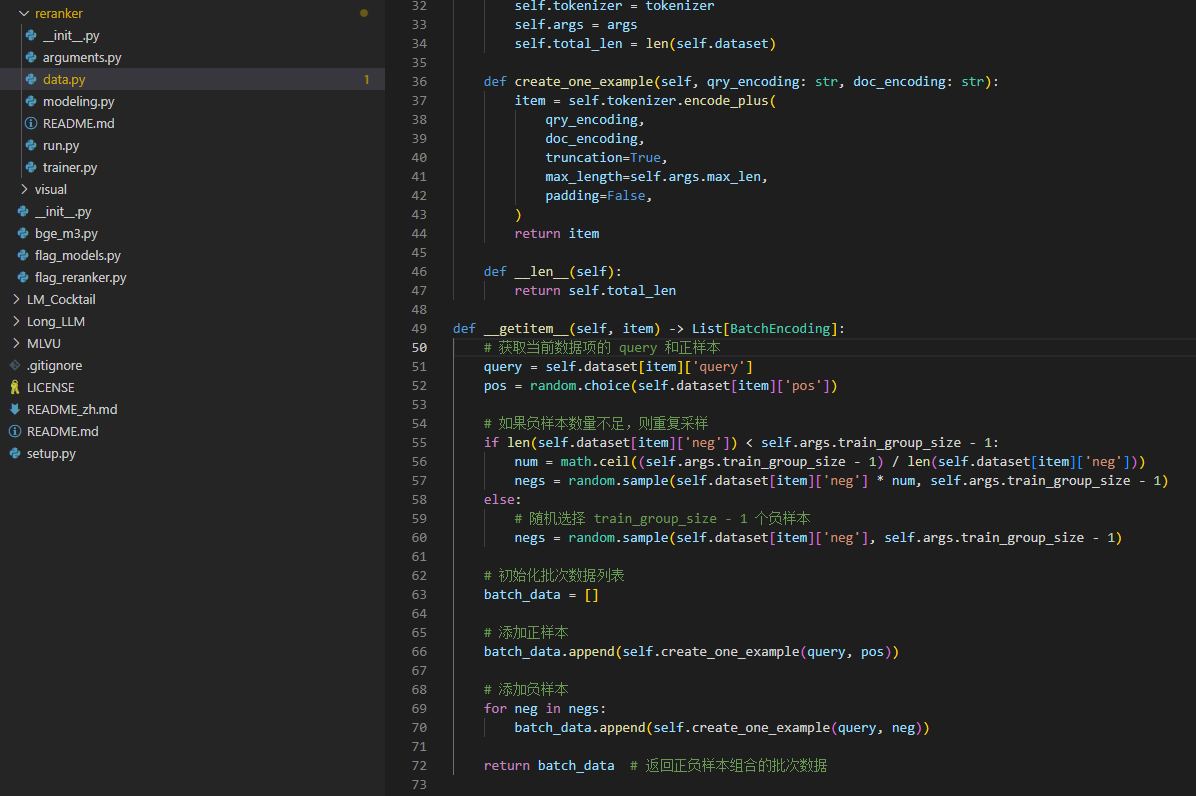
看看吧:loss用的是常规的cross entropy;classifier也是常规的SequenceClassifierOutput,没啥特别的!
总结:
1、RAG整个流程有3个地方涉及到LLM:文本embedding、rerank和根据context生成最终的答案
2、moka官方的建议:
- 使用场景主要是中文,少量英文的情况,建议使用 m3e 系列的模型
- 多语言使用场景,并且不介意数据隐私的话,我建议使用 openai text-embedding-ada-002
- 代码检索场景,推荐使用 openai text-embedding-ada-002
- 文本检索场景,请使用具备文本检索能力的模型,只在 Sentence 2 Sentence 上训练的文本嵌入模型,没有办法完成文本检索任务
3、 FlagEmbedding也有 Embedding Model: Visualized-BGE, BGE-M3, LLM Embedder, BGE Embedding,感兴趣的小伙伴也可以尝试一下!
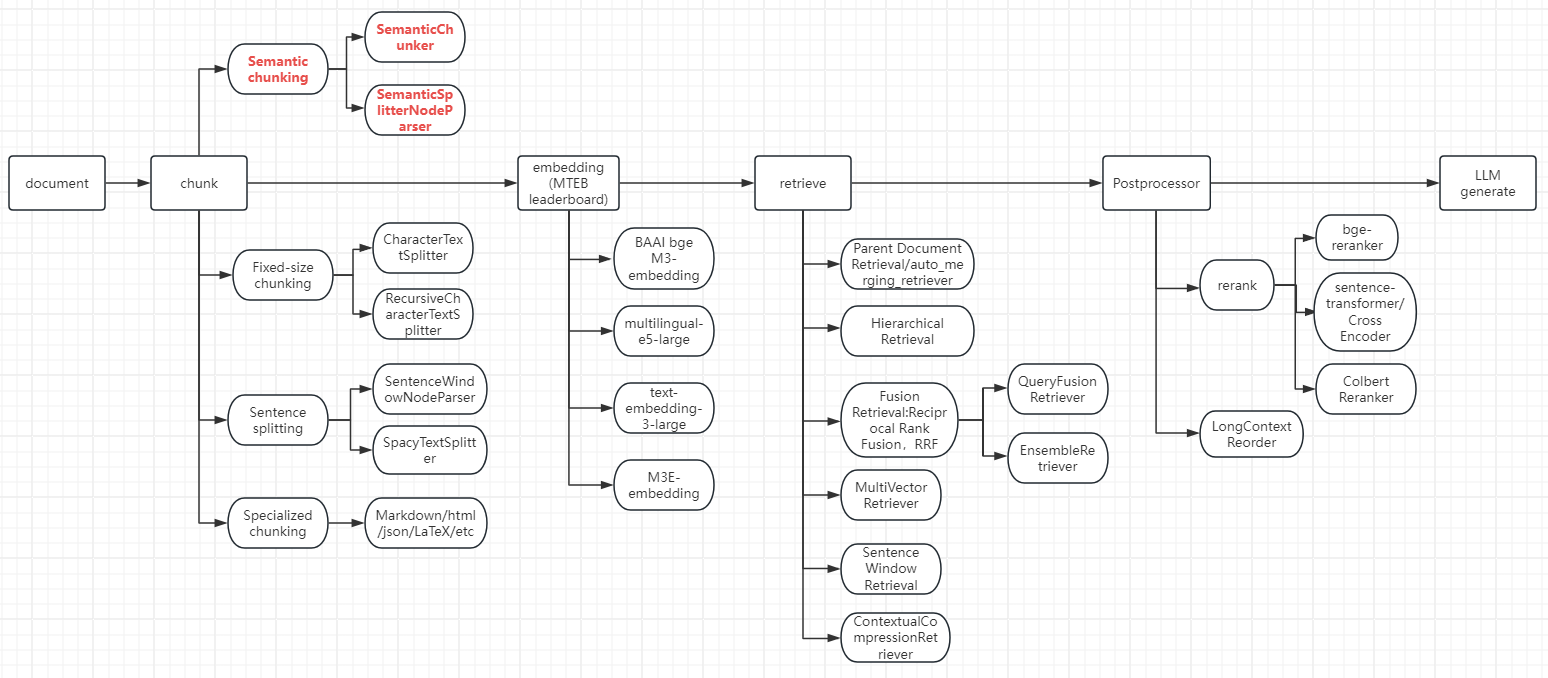
4、RAG整个流程中关键节点和涉及到的现成包列举如下:不同节点可以根据用户需求和实际情况选择,节点之间的选择可以排列组合!
参考:
1、https://huggingface.co/moka-ai/m3e-base https://github.com/wangyingdong/m3e-base
2、https://github.com/coffeebean6/retrieval_augmented_generation
3、https://blog.csdn.net/lovechris00/article/details/138378828
4、https://github.com/wangyuxinwhy/uniem/blob/main/examples/finetune.ipynb
5、https://www.bilibili.com/video/BV1h142197Fm/?spm_id_from=333.788.recommend_more_video.0&vd_source=241a5bcb1c13e6828e519dd1f78f35b2 https://techdiylife.github.io/blog/blog.html?category1=c02&blogid=0047 如何选择embedding模型
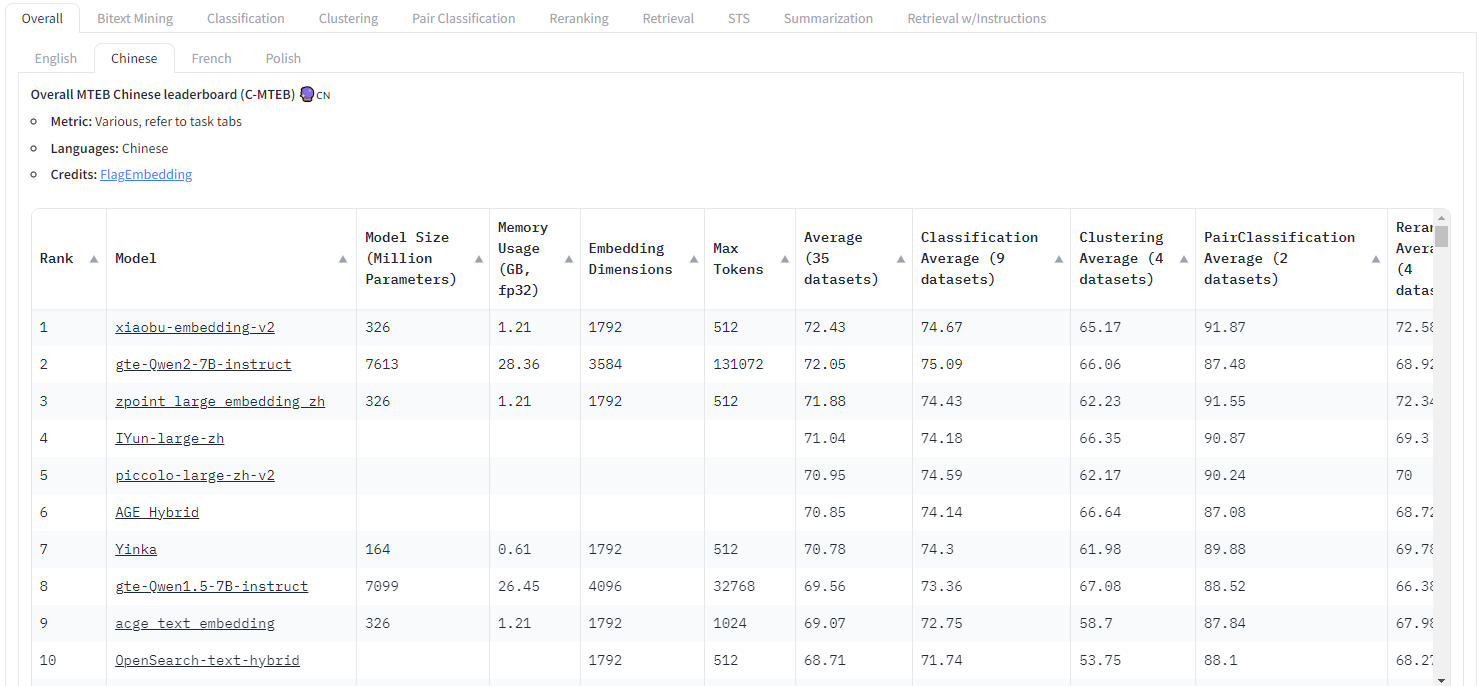
6、https://huggingface.co/spaces/mteb/leaderboard Massive Text Embedding Benchmark (MTEB) Leaderboard
7、https://mp.weixin.qq.com/mp/appmsgalbum?__biz=Mzg3NDIyMzI0Mw==&action=getalbum&album_id=3377833073308024836 RAG实战
8、https://www.pinecone.io/learn/series/rag/rerankers/ https://www.bilibili.com/video/BV1r1421R77Y/?spm_id_from=333.788.recommend_more_video.2&vd_source=241a5bcb1c13e6828e519dd1f78f35b2 为什么要用rerank
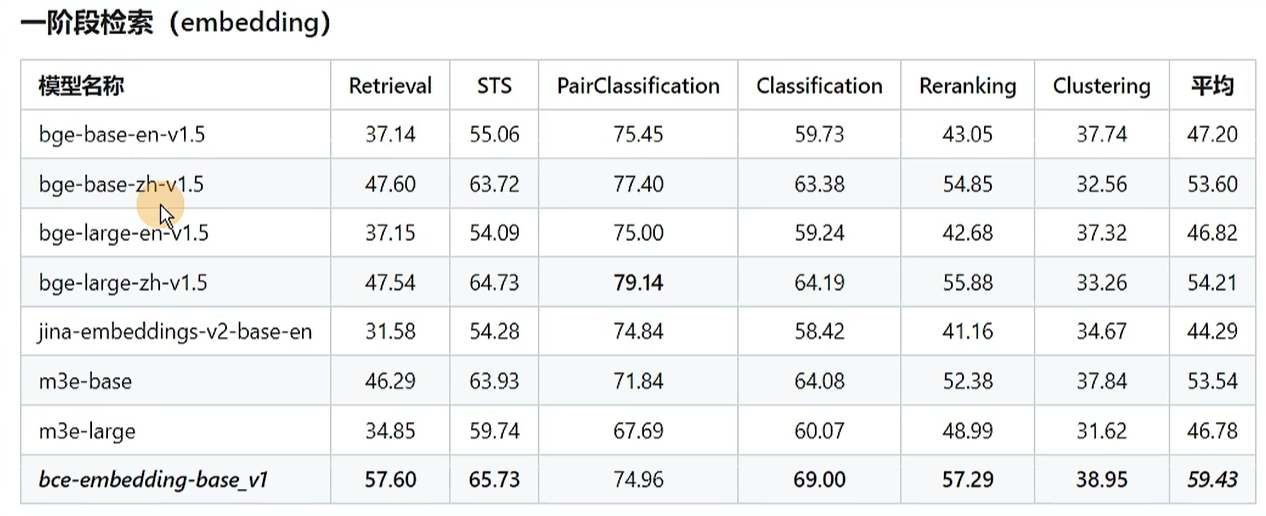
9、https://qanything.ai/docs/architecture embedding和rerank测评 https://github.com/netease-youdao/BCEmbedding/blob/master/Docs/EvaluationSummary/embedding_eval_summary.md https://github.com/netease-youdao/BCEmbedding/blob/master/Docs/EvaluationSummary/reranker_eval_summary.md

 浙公网安备 33010602011771号
浙公网安备 33010602011771号