LLM大模型: MOE/mixtral原理和源码解析
1、古人云:闻道有先后,术业有专攻!每个人的能力范围是有限的,不可能360行,行行都精通!所以搞研究都会选一个细分领域深耕,争取在这个领域做到世界top级别的泰斗!一个团队,内部也都是在各个领域擅长的人组成,比如前端、ui、后端、算法、运维、运营等,大家互相配合,完成既定目标!本人多年前做传统的数据挖掘和机器学习,最常用的就是随机森林random forrest了:树模型不需要事先做归一化预处理,模型本身根据信息增益选择合适的特征分裂;单颗树可能判断错,那就用多棵树一起判断,找到判断结果最多的那个,正确的概率就很大了!说了这么多,想表达的就一个意思:群策群力!如果目标过于复杂,单个个体已经无法达到既定目标,那就把目标拆解,不同的细分目标让不同的专业人士去做,大家群策群力,这就是常说的:专业的事让专业的人去干!截至目前,这个道理同样也适用于大模型: 用户的需求多种多样,单一的大模型很难完全满足客户需求了,那就把单个大模型拆分成多个“小模型”,每个小模型都只用各个细分领域的数据训练,专门用于回答用户在细分领域的问题,这就是所谓的Mixture-of-Experts!google的论文(https://icml.cc/media/icml-2022/Slides/17378.pdf)中有效果对比,如下:同样都是64B参数,分成64个export,每个export只有1B的参数,这样做的效果比GPT3都还要好!
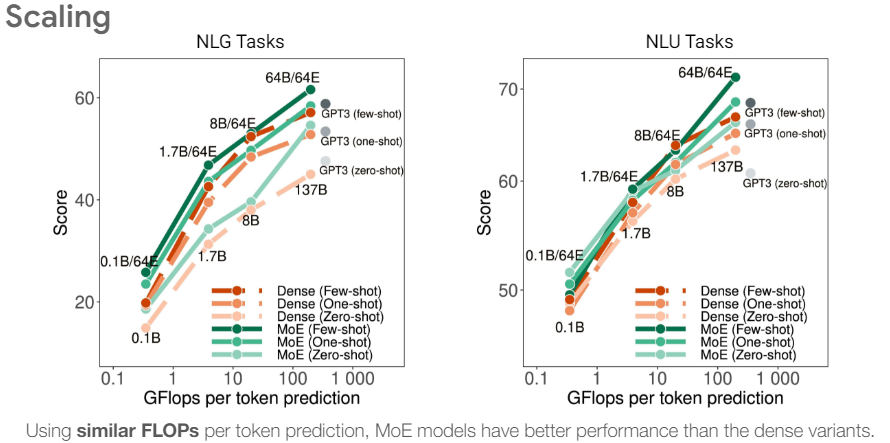
这个也可以从我之前做的代码相似度检测的效果来印证:https://www.cnblogs.com/theseventhson/p/18211242 这个GraphCodeBERT是基于bert用代码语料训练的,参数也就1.2亿个,保存模型的bin文件不到500M,是标准的小模型!但是这个小模型使用的数据全是代码,并且代码还提取了AST/DFG作为特征,用于判断两个函数是否语义相似效果非常好!所以模型效果好不好,和大小没太大关系,主要还是训练语料和输入特征是否高质,模型没必要盲目做大(模型在精不在大)!MOE的架构如下:

核心在于每个transformer block的MLP层:之前只有一个神经网络,一般是先升维再降维;现在是把一个大的神经网络拆分成多个小的FFN,多个小的FFN前面有个Gating,用来判断输入数据从那个FFN继续推进(本质就是个路由器,选择合适的分发路径)!和传统的稠密dense model比,MOE这种稀疏sparse model的优势:
- 推理时只有一小部分的export被激活用于计算,而不是整个网络,节约算力!
- 每个export各自专注于特定的任务或数据类型,MoE 模型能够更好地处理复杂和多样化的数据
- 增加export就能扩展模型容量(看着是不是像Lora?在原有线性层的旁边再增加一个旁路),处理新领域的问题和数据,泛化能力比dense model好!
2、(1)MOE架构也已经实现了,在transformer包的transformers-main\src\transformers\models\mixtral\modeling_mixtral.py这个文件里面。整体的代码结构如下:新增了几个MOE相关的类,其余的结构和llama几乎一样。
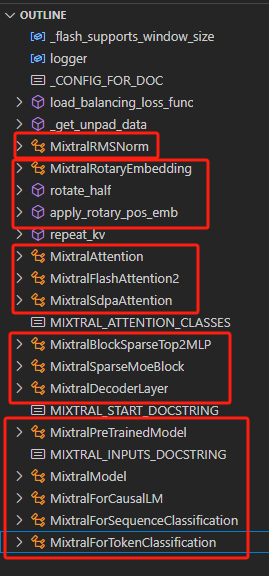
在decoder端的forward函数中的fully connect模块,attention和norm之后就是MOE啦,如下:
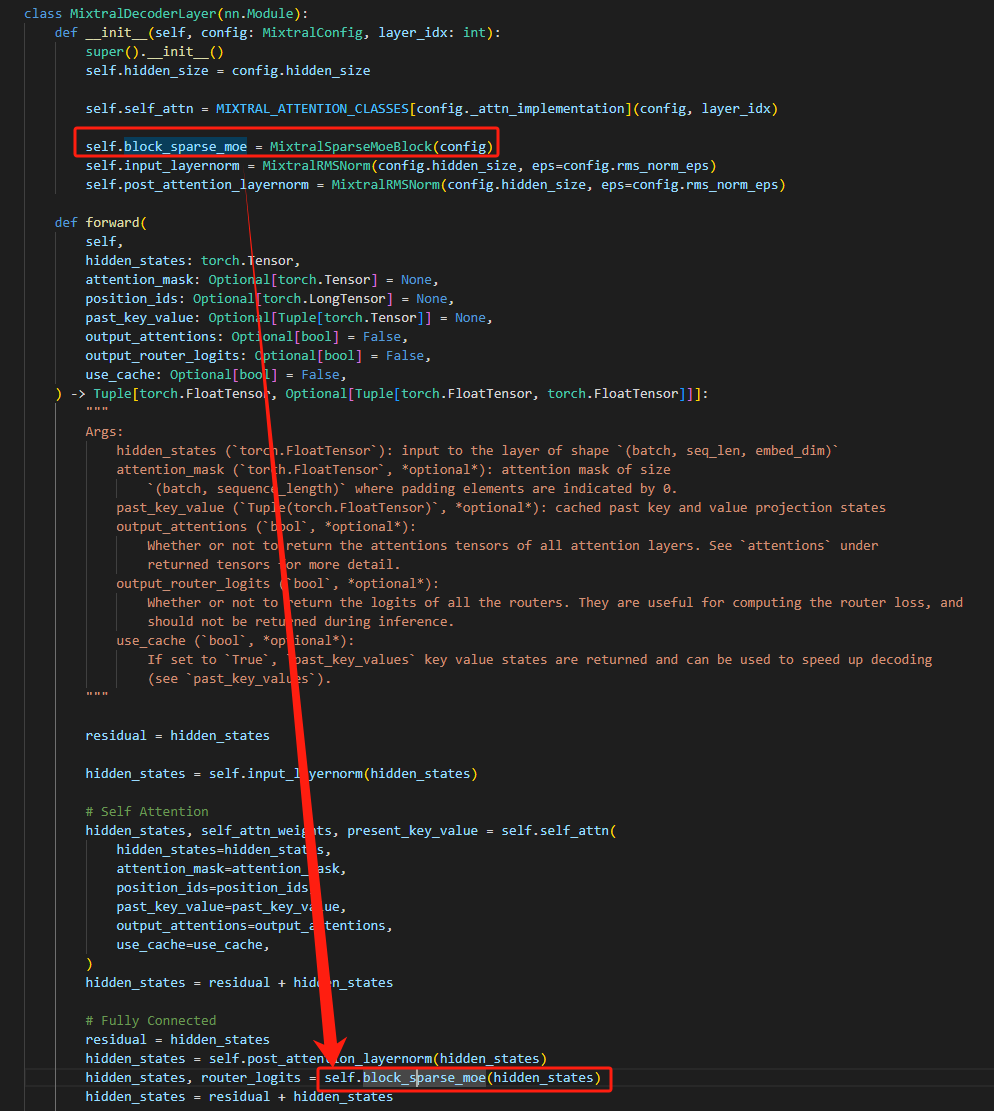
所谓的export:就是个3层的神经网络:
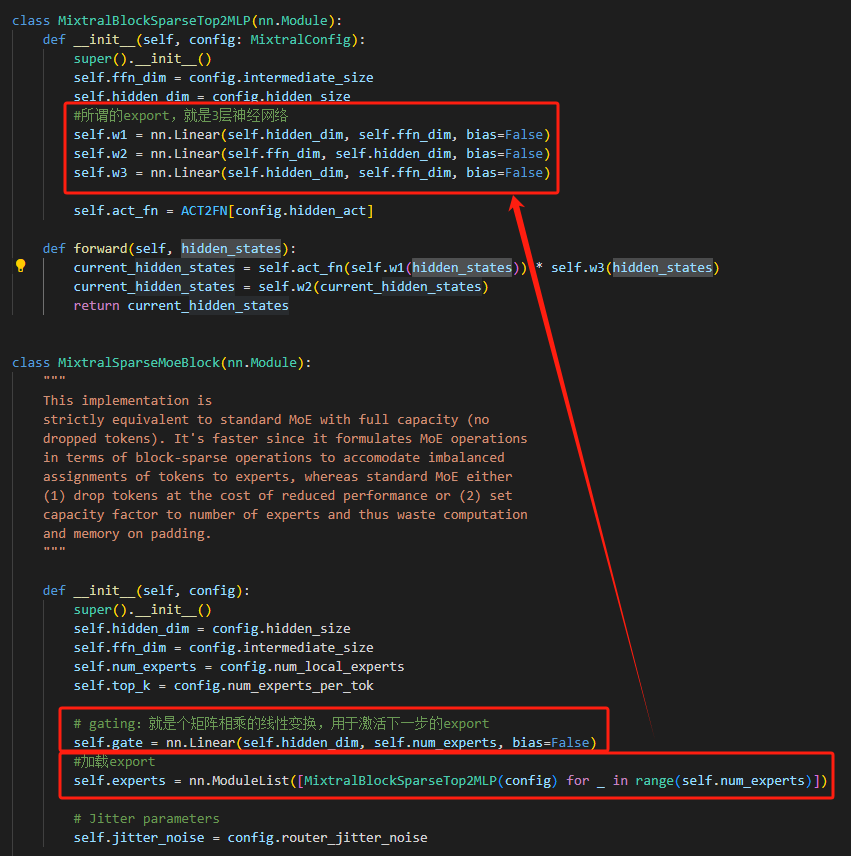
特别说明一下MixtralBlockSparseTop2MLP这里的forward函数:
def forward(self, hidden_states): current_hidden_states = self.act_fn(self.w1(hidden_states)) * self.w3(hidden_states) current_hidden_states = self.w2(current_hidden_states) return current_hidden_states
同一个hidden_states,经过w1线性转换后激活,然后和w3线性转换后相乘,再通过w2做线性转换,为啥要这么干?
- self.act_fn(self.w1(hidden_states)) * self.w3(hidden_states) :核心还是特征的非线性组合,目的是为了更好地生成非线性特征,举例如下:

- current_hidden_states = self.w2(current_hidden_states) 再次通过线性变换进入下一个空间,后续所有的操作都在新空间进行,不会和现有空间的操作互相影响!
(2)选择export的forward函数整个流程:
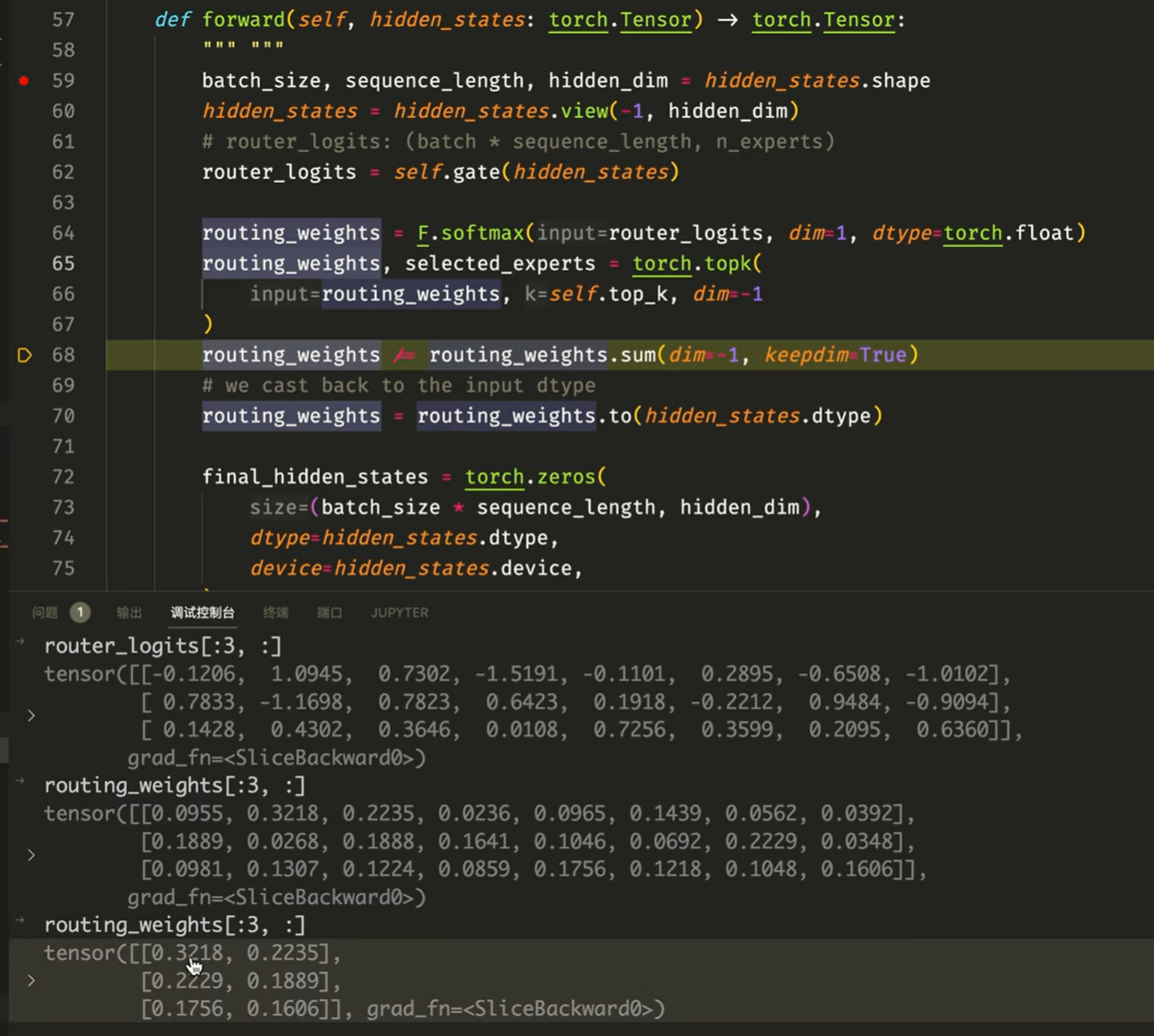
"""将输入数据通过多个export进行处理,并根据动态计算的路由权重将不同输入分配给不同的export""" def forward(self, hidden_states: torch.Tensor) -> torch.Tensor: """ """ batch_size, sequence_length, hidden_dim = hidden_states.shape if self.training and self.jitter_noise > 0: hidden_states *= torch.empty_like(hidden_states).uniform_(1.0 - self.jitter_noise, 1.0 + self.jitter_noise)#对输入数据应用抖动噪声(jitter noise),增加模型的鲁棒性 hidden_states = hidden_states.view(-1, hidden_dim)#三维变为二维,方便后续处理 # router_logits: (batch * sequence_length, n_experts) # 通过gate计算路由权重得分routing_weights,选择export router_logits = self.gate(hidden_states) routing_weights = F.softmax(router_logits, dim=1, dtype=torch.float) # 选择概率最高的 k 个export routing_weights, selected_experts = torch.topk(routing_weights, self.top_k, dim=-1) # 归一化权重 routing_weights /= routing_weights.sum(dim=-1, keepdim=True) # we cast back to the input dtype routing_weights = routing_weights.to(hidden_states.dtype) final_hidden_states = torch.zeros( (batch_size * sequence_length, hidden_dim), dtype=hidden_states.dtype, device=hidden_states.device ) # One hot encode the selected experts to create an expert mask # this will be used to easily index which expert is going to be sollicitated expert_mask = torch.nn.functional.one_hot(selected_experts, num_classes=self.num_experts).permute(2, 1, 0) # Loop over all available experts in the model and perform the computation on each expert for expert_idx in range(self.num_experts): expert_layer = self.experts[expert_idx] idx, top_x = torch.where(expert_mask[expert_idx]) # Index the correct hidden states and compute the expert hidden state for # the current expert. We need to make sure to multiply the output hidden # states by `routing_weights` on the corresponding tokens (top-1 and top-2) current_state = hidden_states[None, top_x].reshape(-1, hidden_dim) current_hidden_states = expert_layer(current_state) * routing_weights[top_x, idx, None] # However `index_add_` only support torch tensors for indexing so we'll use # the `top_x` tensor here. final_hidden_states.index_add_(0, top_x, current_hidden_states.to(hidden_states.dtype)) final_hidden_states = final_hidden_states.reshape(batch_size, sequence_length, hidden_dim) return final_hidden_states, router_logits
调试结果:
参考:
1、https://arxiv.org/pdf/2405.11273
2、https://ar5iv.labs.arxiv.org/html/2402.07871
3、https://icml.cc/media/icml-2022/Slides/17378.pdf GLaM: Efficient Scaling of Language Models with Mixture-of-Experts
4、https://www.bilibili.com/video/BV1jH4y177DL/?spm_id_from=333.788.recommend_more_video.0&vd_source=241a5bcb1c13e6828e519dd1f78f35b2
5、https://www.bilibili.com/video/BV1Xu4y1K7zn/?spm_id_from=333.788.recommend_more_video.2&vd_source=241a5bcb1c13e6828e519dd1f78f35b2 MOE源码
6、https://www.bilibili.com/video/BV1cy421z7er/?spm_id_from=333.788.recommend_more_video.0&vd_source=241a5bcb1c13e6828e519dd1f78f35b2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号