Oracle是如何工作的?实例是如何响应用户请求?一条SQL的执行过程~
Oracle 是如何工作的?
- Select id,name from t order by id ;
– SQL 解析(查看语法是否错误,如果没有错误,分析语意,执行此语句的权限)
– 执行计划(ORACLE如何访问数据,按照执行计划取数据)
– 执行SQL
• 从磁盘中读取数据(如果数据在内存中没有,就去磁盘读取)
• 数据处理(数据读到内存后,就进行处理。排序,组合等处理)
• 返回结果(把结果返回给用户)
- Insert into t values(1,‘tigerfish’);
– SQL 解析
– 执行计划
– 执行SQL
• 从磁盘中读取数据块(如果内存中没有)
• 修改回滚段数据块(同时产生redo log)----Oracle特性(将数据修改前的数据放到回滚数据块)
• 修改原始数据块(同时产生redo log)
- Create table t values(id int,name varchar2(10);
– SQL 解析
– 执行计划
– 执行SQL
• 给对象分配初始化的存储空间(段),产生一些undo和redo日志。
• 在Oracle字典表中创建新的对象相关信息(表,字段,各种属性….),产生一些Undo和redo日志。
- Drop table t purge(truncate table t);
– SQL 解析
– 执行计划
– 执行SQL
• 收回对象占用的空间,产生一些undo和redo日志。
• 在Oracle字典表中删除的对象的相关信息(表,字段,各种属性….),产生一些Undo和redo日志。
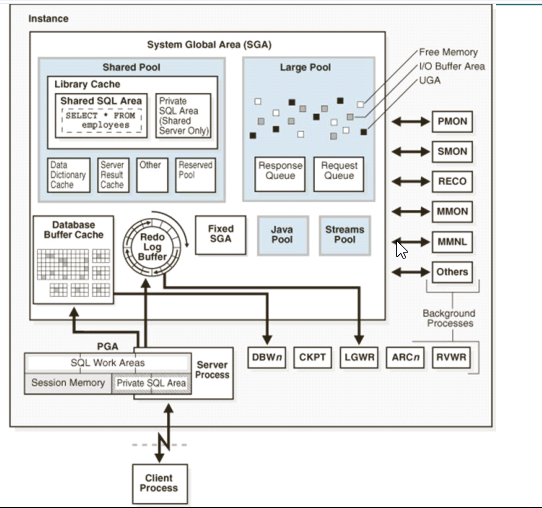
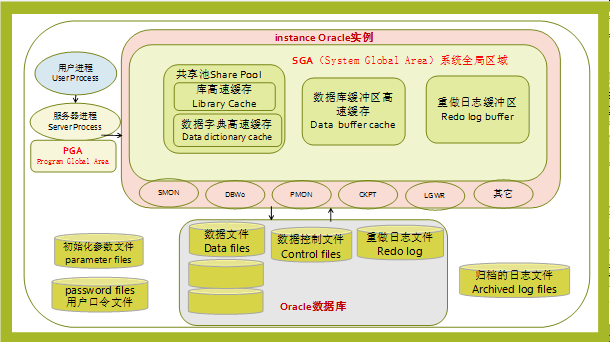
实例是如何响应用户请求?
- Client Process(用户端进程)向数据库发了一条SQL语句.
- 数据库端会启用一个Server Process(服务器进程).
- Client Process和Server Process组成了一个Session(会话).
- Server Process就会处理用户的请求.
- Server Process会开一块内存(PGA),用户的请求(SQL语句)首先会放在PGA里.
- Server Process开辟了内存后就要开始执行SQL语句了.这时候就需要去访问SGA.
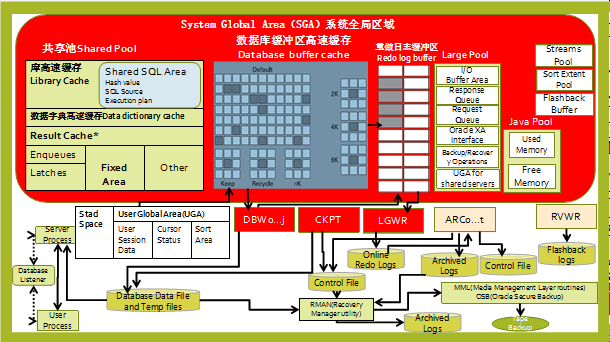
- 访问SGA,首先去Share Pool解析SQL语句,得到执行计划,然后按照执行计划去Database Buffer Cache查找数据.
- 如果Database Buffer Cache没有,Server Process就直接去磁盘里面读数据到Database Buffer Cache.
- 如果Database Buffer Cache里读到了数据,用户需要修改数据块,那么就会在Database Buffer Cache里修改数据块.
- 修改数据块后会产生redo log,redo log Buffer会产生响应的重做项。
- 如果用户发出commit的提交,redo log Buffer会通过LGWR进程将数据写到磁盘上.
- 如果用户发出了checkpoint检查点,数据会被DBWn进程会将修改了的脏数据(当buffer cache被修改了就会标记为脏数据)写入磁盘上.
一条SQL的执行过程:
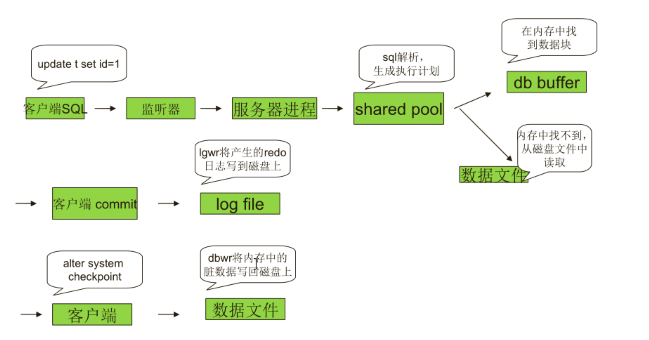
- 客户端发出请求(update set id=1),连接监听器,监听器将服务转到实例上,ORACLE启动服务器进程,和客户端进程建立连接,就完成了一个会话.
- ORACLE服务器进程将SQL语句在Share pool里面进行解析(语法分析、语义分析(权限啊,表是否存在),生成执行计划)
- ORACLE服务器进程按照执行计划访问数据,先到db buffer里面找数据块.如果有就对数据库做update!
- 如果db buffer里面没有,就会从磁盘相应的数据文件中找.再把数据读到db buffer里面去.就可以修改数据块了.
- 修改数据时会产生一个undo数据(重做数据).(如之前的id=99,那么id=99的数据块就会被放到undo表空间去,方便回滚),然后修改当前的数据块为1.
- 客户端提交commit命令.
- LGWR将undo产生的日志和当前数据块修改产生的日志放在一起,写在磁盘上.
- 客户端发出alter system checkpoint,DBWR将内存中的脏数据写到磁盘上.
执行一个SQL语句
执行查询语句的过程:
- 用户进程执行一个查询语句如select * from emp where empno=7839
- 用户进程和服务器进程建立连接,把改用户进程的信息存储到PGA的UGA中
- 语句经过PGA处理后传递给实例instance
- 实例instance中的共享池处理这条语句
- 库缓冲区去判断语句如何分析--软分析(快)或硬分析(慢)
- 根据cbo得到执行计划,准备去执行语句.(CBO和RBO是ORACLE提供的两种优化器)
- 查询语句中的对象(emp表和行)存放在那个表空间,指定的行放在那个块block里?需要到数据字典缓冲区得到这些信息。
- 开始执行
- 如何执行?在内存中执行
- 判断在database buffer cache数据缓存区中是否缓存了需要的block。
- 如果是,在内存读取数据得到需要的行的结果返回给用户,用户看到执行的结果。
- 如果不是,则服务器进程把块从磁盘读入到data bufer cache缓存下来,然后undo缓存块会对该块做镜像,然后读镜像中的数据得到行的结果返回给用户,用户看到执行的结果。
执行UPDATE语句的过程:
- 用户进程执行一个update语句:UPDATE emp set sal=10 WHERE id=1234
- 用户进程和服务器进程建立连接,把该用户进程的信息存储到PGA的UGA中
- 语句经过PGA处理后传递给实例instance
- 实例instance中的共享池处理这条语句
- 库缓冲区去判断语句如何分析--软分析(快)或硬分析(慢)
- 根据cbo得到执行计划,准备去执行语句.(CBO和RBO是ORACLE提供的两种优化器)
- 查询语句中的对象(emp表和行)存放在那个表空间,需要修改的行放在那个块block里?需要到数据字典缓冲区得到这些信息。
- 开始执行
- 如何执行?在内存中执行
- 判断在database buffer cache数据缓存区中是否缓存了需要修改的block。
- 如果是,直接在内存中操作。
- 如果不是,则服务器进程把块从磁盘读入到data buffer cache缓存下来,然后undo缓存块会对该块做镜像,然后对内存中的block做修改操作。
- 由于block发生了修改/变化,redo log buffer会记录块block修改的操作信息,同时,会将修改之前的数据放在undo块镜像,修改之后的数据放在undo块镜像。
- 提交的数据要写入磁盘,没有提交的不写入磁盘。如果执行了commit,data buffer chache的undo的块数据就会标记已经提交。
注:服务器进程把块从磁盘读入到data buffer cache缓存下来后,执行的操作:
1、通过undo把你需要的block做镜像,(这个时候判断操作类型)
(1)、如果是查询语句,执行语句会通过undo中的镜像数据进行游标操作,打开行,取记录,用户可以看到结果.
(2)、如果是更新、删除、插入,执行语句会修改database buffer cache的块,修改之后把修改之后的状态保留在undo中,作为一个新的镜像. 修改之前的镜像是之前就有的,这个镜像是之前数据文件中真实的记录,而后我们将数据进行修改,这个记录成为我们修改之后的状态,而修改之后的状态有2种,第一种是进行了事务提交(修改操作在undo中被标记为已提交),第二种是没有进行事务提交(修改操作在undo中被标记为未提交).
undo中所保留的镜像数据一直要到什么时候把没有提交的更改呢,要到事务结束,或事务撤销,事务崩溃,才能在undo中把这个没有提交的状态给清空或取消,undo中保存的临时数据有2种状态,对DML语句来说一种是修改之前的(原镜像),一个是修改之后的(新镜像). 如果是需要的数据,会根据事务提交commit,把语句通过CKPT来触发,由于块发生了变化,redo log buffer会记录变化的数据块更改的过程,然后根据需要database buffer cache 数据写入数据文件中.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号