用伪代码理解浏览器中的事件冒泡以及捕获
写在前面的
这里都是胡说的,错了勿怪
开撸代码
首先,当页面渲染好之后,我们的页面是一个dom树
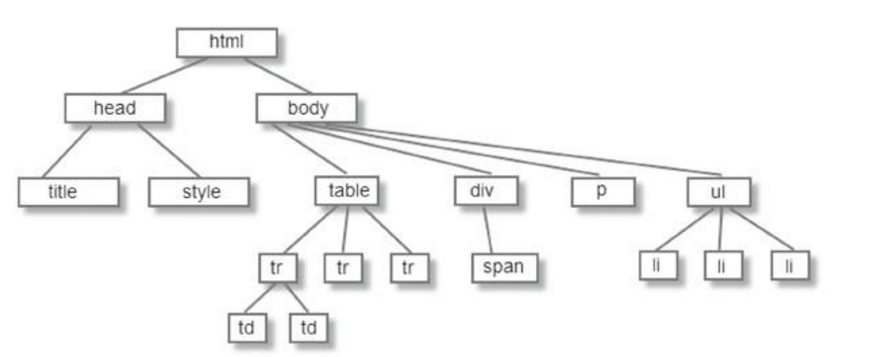
浏览器会获取到每一个节点的位置和宽度、高度。
好了,从这个时候开始,浏览器就会运行自己的事件循环,查看是否有各种事件发生
于是,这个时候,用户点击了一下页面上的某一块位置,但是浏览器并不知道用户点
击了哪一个dom,并且也不知道该dom是否有事件响应程序,浏览器知道的只是用户点
击的位置的x,y坐标,浏览器这个时候就开始从dom树的根开始寻找,(这里是捕获的
开始),x,y是否在根的位置上,根有没有注册点击事件?点击事件是否是捕获注册的
?如果事件是捕获注册的,那么执行这个事件处理函数,在该函数中,判断是否有
event.stopPropagation()来阻止事件的捕获,若阻止了,那么该点击事件的整个过程就完
成了,不论子节点是否注册了点击事件都不会执行到的。然后接着往后找,进行同样的
判断,知道找到叶子节点位置(这里是捕获的结束)。同样要判断该叶子节点是否注册
了点击事件?是否阻止了事件?然后怎么来的,就怎么回去(这里是冒泡的开始)。在回
去的过程中,判断每个节点是否注册了点击事件,是否是冒泡注册的,如果是冒泡注册的
事件,那么就执行,执行过程中如果发生了event.stopPropagation(),那么整个点击事件
就结束了,如果没有就接着往根走,直至结束。
以下是伪代码
while (true) {
...
if (eventHappen) {
var x = event.x;
var y = event.y;
var dom = body;
var Buhuoing = true;
while (dom !== html ) {
if (dom.hasEventHandler && ((dom.isBuhuo && Buhuoing) || (dom.isMaoPao && !Buhuoing)) ) {
dom.EventHandler();
if (preventEvent) {
break;
}
}
if (dom == '叶子节点') {
Buhuoing = false;
}
if (Buhuoing) {
dom = dom.nextDom();
} else {
dom = dom.prevDom();
}
}
}
...
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号