Python进阶篇02-函数
一、常规函数的定义
函数
- 函数就是一段组织好的、可以重复使用的代码块。比如在你写的某个
.py文件中,需要频繁的计算面积,这样我们会有很多相似、重复的代码,在这种情况下,我们就可以将这些代码块封装起来,这就是函数。每次需要进行面积的计算时,就调用这个函数; - 在Python中,有可以直接进行使用的内建函数,我们也可以自定义函数;
如何自定义函数
- 在Python中,我们使用
def关键字来定义函数,def func_name(args):,使用def定义了函数名字与参数后,:冒号后就是函数体,return [表达式]关键字返回了需要的值后(不带表达式则返回None)就结束函数,函数的整体结构如下:
![]()

如何调用函数
- 函数可以有参数,也可以没有参数;
def print_str():
print('打印了一串文字')
print_str()
----------
打印了一串文字
def area(length, width):
"""
:param length: 长
:param width: 宽
:return: 面积
"""
result = length * width
return result
print(area(3, 2))
----------
6
二、函数的参数
参数就是在这段可重复使用的代码块中,会变化的变量。比如在计算面积的函数中,不同的长方形的长和宽是不同的,因此长和宽就是我们计算面积的函数的参数;
必选参数
- 必选参数就是:我们在定义函数的时候,正常定义的参数,调用函数的时候必须要传递定义好的必选参数,否则会报错。当函数有多个必选参数,调用函数给函数传递参数的时候,需要按照定义时参数的位置顺序来进行传递,因此必选参数又叫做 位置参数。
- 在上述定义的计算面积的函数中,
length、width就是必选/位置参数,我们调用area()这个函数的时候,必须传递这两个参数、且要按照其定义的位置进行传递。
默认参数
- 默认参数:当一个函数有多个参数,且其中的某些参数变化较小,经常用某个值的时候,可以给这个参数设置默认值为常用的那个值;设定了默认值的参数我们称之为默认参数。使用默认参数,我们就不再需要给函数多次传递相同的值。
- 调用的函数有默认参数时,若我们使用此参数的默认值,则不需要再传递此参数;若我们需要使用其他值,则直接给此参数传递其他值即可;
def area(length, width=3):
"""
:param length: 长
:param width: 宽,设置默认值为3
:return: 面积
"""
result = length * width
return result
# 调用函数时,若使用默认值3,则不传递 width
print(area(3))
# 调用函数,需要计算宽为2,不使用默认值,则直接给width传递值2
print(area(3, 2))
----------
9
6
- 默认参数无需按照参数顺序来进行传递,传递默认参数时,可以使用key=value的形式指定给某个默认参数传值;
def param_test(a=1, b=2, c=3):
print(a)
print(b)
print(c)
param_test(b=8)
----------
1
8
3
注意
- 使用默认参数时,如果有必选参数(可以没有必选参数,都是默认参数),必选参数必须在默认参数之前;这是为啥呢?反向思考一下,当函数既有必选参数又有默认参数时,如果必选参数在默认参数的后面,我们调用函数时,若只传必选参数,则会让人搞不清楚这个参数是传给默认参数还是必选参数,当然也可以使用key=value的形式,这样显然会更麻烦;若先传默认参数(与默认值相同的值)、再传必选参数,则默认参数也就没有了存在的意义。
# 实际上,这种写法在编译器会报错
def test_a(x=2, y):
print(x)
print(y)
# 4到底是传给x还是y呢?
test_a(4)
----------
SyntaxError: non-default argument follows default argument
- 默认参数的参数值必须是不可变对象,”虽然说使用可变对象在语法上没错,但是在逻辑上是不安全的,代码量很大时,可能会出现难以查找的bug“。假如默认参数的值为可变对象,在函数内部会对这个值进行更改的话,每次调用函数都会修改此可变对象的值,那么这个默认参数值也就不是我们最初所需要的那个参数值了,这与我们默认参数的初衷背道而驰,例子如下:
def param_test(a=[]):
a.append('test')
print(a)
param_test()
param_test()
----------
['test']
['test', 'test']
可变参数
- 可变参数:当给一个函数传递的参数个数不定,可以有0个、1个或者多个时,我们可以将此参数定义为为可变参数,格式为
def func_name(*args):。在函数的参数前面加一个*后,此参数就变成了可变参数; - 给函数的可变参数传递的值,会将所有的值组装为一个tuple;
def print_num(*args):
print('参数:{}'.format(args))
for i in args:
print(i)
print_num() # 不传递参数
print_num(1) # 传递一个参数
print_num(1, 2, 3, 4) # 传递4个参数
----------
参数:()
参数:(1,)
1
参数:(1, 2, 3, 4)
1
2
3
4
- 除了直接给可变参数传递多个参数值外,我们也可以将list/tuple/dict中的元素作为参数传递给可变参数。只需要在list/tuple/dict前加上
*号,就可以将它们的元素作为可变参数传递给函数; - 但我最开始不太明白,加
*和不加有什么区别呢,不都是将所有的元素传给函数吗?然后我将两种写法传递给函数后的参数打印了出来:
def print_num(*args):
print('参数:{}'.format(args))
for i in para:
print(i)
nums = [1, 2, 3, 4, 5]
test = ('a', 'b')
dicts = {'c': 6, 'd': 7}
# 此种写法的意思是 将list/tuple/dict作为一个参数传递给*para这个可变参数
print_num(nums)
print_num(test)
print_num(dicts)
# 此种写法的意思是 将list/tuple/dict 中的每个元素(key值)都作为参数传递给*para这个可变参数
print_num(*nums)
print_num(*test)
print_num(*dicts)
----------
参数:([1, 2, 3, 4, 5],)
[1, 2, 3, 4, 5]
参数:(('a', 'b'),)
('a', 'b')
参数:({'c': 6, 'd': 7},)
{'c': 6, 'd': 7}
参数:(1, 2, 3, 4, 5)
1
2
3
4
5
参数:('a', 'b')
a
b
参数:('c', 'd')
c
d
注意
- 当我们要将list/tuple/dict中的元素作为可变参数传递给函数时,必须加上
*号,否则就是将整个list/tuple/dict作为一个参数传递给了函数,也就是只传递了一个值给此可变参数。
关键字参数
- 关键字参数:可以给此参数传递0个、1个或多个
key=value形式的参数,格式为def func_name(**kwargs):,给函数的关键字参数传递的所有参数会被组装为一个dict; - 可以将dict中的键值对作为多个
key=value形式的参数传递给函数的关键字参数,只需在dict前加**即可;
def print_param(name, age, **kwargs):
print('关键字参数:{}'.format(kw))
print_param('mike', 18, city='1', sex=2, other={'a': 1, 'b': 2})
dicts = {'happy': 1, 'new': 2, 'year': 3}
print_param('kk', 19, **dicts)
----------
关键字参数:{'city': '1', 'sex': 2, 'other': {'a': 1, 'b': 2}}
关键字参数:{'happy': 1, 'new': 2, 'year': 3}
命名关键字参数
- 对于关键字参数的
key=value,可以随便传入任意key值,但这样我们可能会在函数中去使用多余的代码来确定是否有我们所需要的key值。为了解决这一问题,我们可以使用 命名关键字参数 来限制可以传入的key,只需要加一个*作为分隔符,*后的参数就是 命名关键字参数。 - 使用命名关键字参数时,给函数传递参数就必须要传入对应的
key值,否则会被认为未传入所需参数; - 命名关键字参数可以设置默认值,当我们不需要其他值时,即可不传入此参数值;
def print_param(name, age, *, city, sex):
print(city, sex)
print_param('lily', 20, city='beijing', sex=1)
def print_param(name, age, *, city='beijing', sex):
print(city, sex)
print_param('lily', 20, sex=1)
- 如果函数中已有可变参数,那么可变参数后的命名关键字参数不再需要以
*来作为分隔符;
def person(name, age, *args, city, job):
print(name, age, args, city, job)
多种参数时的顺序
参数的类型:必选(位置)参数、默认参数、可变参数、命名关键字参数、关键字参数;当使用多种类型的参数时,参数的顺序必须是:必选参数-默认参数-可变参数-命名关键字参数-关键字参数。
- 必选参数与默认参数的顺序上述已经分析过;
- 可变参数必须在必选参数与默认参数之后,这是因为可变参数可以传递多个参数,若可变参数在前,则传递的参数都会被当成可变参数(不指定参数名的情况下);
三、递归函数
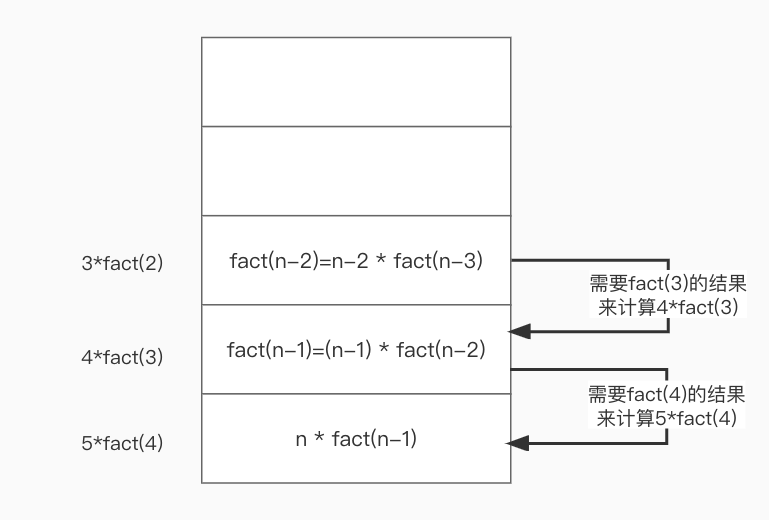
递归函数即为:在函数内部调用自身的函数。当我们发现某个问题的解决逻辑可以拆分成多个相同的解决逻辑来进行计算时,就可以使用递归函数,不断的调用自身,将问题不断的拆分缩小化去解决。
def fact(n):
"""
计算n的阶乘
:param n:
:return:
"""
if n == 1:
return 1
print('{}*fact({})'.format(n, n-1))
return n * fact(n-1)
print('结果:{}'.format(fact(5)))
----------
5*fact(4)
4*fact(3)
3*fact(2)
2*fact(1)
结果:120
递归涉及到的栈溢出
“在计算机中,函数调用是通过栈这种数据结构来实现的”,在调用函数时,会记录当前调用的方法栈,而对于在此种递归调用来讲,因为每一次调用函数所需要return的结果都是一个新的表达式,依赖于另一个调用函数的结果,因此每次会将新调用的函数存储在栈中,这样若是计算的数据过大,函数调用的次数过多时,就会出现栈溢出。
def fact(n):
if n == 1:
return 1
print('{}*fact({})'.format(n, n-1))
return n * fact(n-1)
print('结果:{}'.format(fact(1000)))
----------
RecursionError: maximum recursion depth exceeded while calling a Python object # 调用Python对象时超出了最大递归深度
尾递归
解决递归函数中栈溢出的方法是使用尾递归优化。
- 尾递归是指:在函数return的时候,调用该函数本身、且return语句不能包含表达式,仅仅调用其本身,不做其他额外的操作,这种递归调用就是尾递归。
- 编译器会利用尾递归特性去进行优化,当编译器检测到某个函数调用是尾递归的时候,它会覆盖栈中当前的记录,因为尾递归形式中,最后return的是一个新的函数调用,我们最终需要这个新的函数调用所返回的结果,不再需要使用这个结果再去进行表达式的计算了,因此这样就不会出现栈溢出这个问题。
- 但是Python目前并没有针对尾递归做优化,Python解释器也没有进行优化,所以哪怕我们改成尾递归的形式,仍旧会栈溢出。
def f(n, product):
if n == 1:
return product
print('f({}, {})'.format(n-1, n*product))
return f(n-1, n*product)
print(f(5, 1))
----------
f(4, 5)
f(3, 20)
f(2, 60)
f(1, 120)
120
此种写法即为尾递归,与递归来对比,区别如下:
- 第一次调用:f(5, 1)--在栈中记录f(5, 1),最终返回f(4, 5),我们只需要计算出f(4, 5)的值即可,因此直接覆盖栈中f(5, 1)的记录;
- 第二次调用:f(4, 5)--目前栈中是f(4, 5)的记录,最终返回f(3, 20),再次覆盖f(4, 5)的记录......
- 最终按照上述原理,就不会出现栈溢出这个问题
四、闭包函数
闭包函数:函数内部嵌套另一个函数,嵌套的这个内部函数引用了外部函数的参数和变量,最终外部函数返回这个内部函数或包含此内部函数的表达式,这里的内部函数即为闭包函数。
- 外部函数返回了此闭包函数,返回的并不是最终的结果,因此当我们需要最终结果时,需要调用返回的这个闭包函数;
注意
- 因为上述这一点,假如我们返回的闭包函数中引用了会发生变化的变量,那么最终获得的结果会与我们想要的有偏差:
def count():
fs = []
for i in range(1, 4):
def f():
return i * i
fs.append(f)
return fs
f1, f2, f3 = count()
print(f1(), f2(), f3())
----------
9 9 9
解析
- f1, f2, f3分别对应为调用
count函数所返回的列表fs的三个元素,而fs中每个元素为闭包函数f; - 在for循环中,每循环一次就将闭包函数
f的返回值i * i放进列表; - 因为返回的闭包函数并没有立刻执行,因此
fs中,是三个待执行的i * i; - 在for循环结束后,i的值变成了3;
- 因此最后调用
fs的三个元素,开始执行这三个f函数,每个都是i * i,即为9;
闭包函数的作用
- 闭包函数可以读取外部函数的参数和变量,并且随着外部函数的参数和变量的变化,同一个闭包函数就可以实现不同的功能;
- 闭包函数可以让外部函数的局部变量始终维持在内存中,因为函数内部的局部变量在函数运行结束后,就会从内存中清除,而使用闭包函数,就可以让外部函数的局部变量始终维持在内存中。
def outer(x):
y = x
def inner():
return 'x={}, x/2={}'.format(x, y / 2)
return inner
res = outer(9)
print(res()) # 此外部函数返回的结果为内部函数,因此需要再次调用返回的结果
五、匿名函数
匿名函数:不需要使用def关键字来创建函数,函数无名字,即为匿名;Python使用lambda关键字来创建匿名函数。
匿名函数格式为:lambda [arg1 [,arg2,.....argn]]:expression
[arg1 [,arg2,.....argn]]是参数,expression是表达式,也是匿名函数的返回值;- 匿名函数是一个函数对象,可以将匿名函数赋值给一个变量,也可以作为函数的返回值,但在PEP8规范中并不建议将lambda表达式赋值给一个变量,再通过变量调用函数这种方式,因为lambda匿名函数本身就是一个函数,此种方式是多此一举;
test = [9, 2, 3, 4, 5, 6]
res = map(lambda x: x+1, test)
print(list(res))
----------
[10, 3, 4, 5, 6, 7]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号