

(一)前言
我们刚开始学习linux c的时候,一般都是在一个c文件里面写完所有程序,然后用gcc编译这个c文件就好了,十分简单。
但是你有没有想过,如果我们希望将不同模块的代码放到不同的c文件,然后最后编译成一个程序,这个时候又应该怎么办呢?
有人会说,怎么用这么麻烦,直接放在一个c文件里面就好了。但是你总是要考虑一下现实情况的多变性,虽然同时编译很多个c文件不好,但是只会编译一个c文件显得你很LOW。
(二)例子
具一个现实当中简单的例子
比如说我们要编译如下程序,程序当中有两个c文件。以下程序都是我在之前的博客发过的,大家如果很在意代码的意思的话,可以在之前的博客里面找一找。
main.c
#include <stdio.h> #include <stdlib.h> #include <string.h> #include <unistd.h> #define MEM_PART "/proc/meminfo" #include "file.h" //用于存储内存信息的结构体 struct mem_info { char MemTotal[20]; char MemFree[20]; char MemAvailable[20]; char Buffers[20]; char Cached[20]; }; typedef struct mem_info MEM_info,*pMEM_info; //按行读取/proc/meminfo中的信息,并保存到mem结构体中 int get_mem_info(pMEM_info mem) { char buffer[300]; if(NULL==mem) { printf("\nget_mem_info:param null!\n"); return 0; } memset(mem,0,sizeof(MEM_info)); if(1==get_file_line(buffer,MEM_PART,1))//读取第一行 { sscanf(buffer,"%*s %s",mem->MemTotal); if(1==get_file_line(buffer,MEM_PART,2))//读取第二行 { sscanf(buffer,"%*s %s",mem->MemFree); if(1==get_file_line(buffer,MEM_PART,3))//读取第三行 { sscanf(buffer,"%*s %s",mem->MemAvailable); if(1==get_file_line(buffer,MEM_PART,4))//读取第四行 { sscanf(buffer,"%*s %s",mem->Buffers); if(1==get_file_line(buffer,MEM_PART,5))//读取第五行 { sscanf(buffer,"%*s %s",mem->Cached); return 1; } } } } } return 0; } int main() { char result[3000]; char result2[100]; MEM_info mem; get_file_line(result,MEM_PART,1); sscanf(result,"%*s %s",result2); printf("\n%s\n",result); printf("\n%s\n",result2); get_mem_info(&mem); printf("\n%s %s %s %s %s\n",mem.MemTotal,mem.MemFree,mem.MemAvailable,mem.Buffers,mem.Cached); printf("\n%s\n",result); return 1; }
file.c
#include <stdio.h> #include <stdlib.h> #include <sys/stat.h> #include <sys/types.h> #include <string.h> #include <fcntl.h> #define FILEBUFFER_LENGTH 5000 #define EMPTY_STR "" //打开fileName指定的文件,从中读取第lineNumber行 //返回值:成功返回1,失败返回0 int get_file_line(char *result,char *fileName,int lineNumber) { FILE *filePointer; int i=0; char buffer[FILEBUFFER_LENGTH]; char *temp; memset(buffer,'\0',FILEBUFFER_LENGTH*sizeof(char)); strcpy(buffer,EMPTY_STR); if((fileName==NULL)||(result==NULL)) { return 0; } if(!(filePointer=fopen(fileName,"rb"))) {return 0;} while((!feof(filePointer))&&(i<lineNumber)) { if(!fgets(buffer,FILEBUFFER_LENGTH,filePointer)) { return 0; } i++;//差点又忘记加这一句了 } /* printf("\n%d\n",sizeof(*result)); if(strlen(buffer)>sizeof(*result))//不能够这么写,虽然fgets读取一行后会在末尾加上'\0',但是sizeof(result)得到的结果却是result本身类型的大小,所以不能够这么算。当静态数组传入函数时,在函数内部只能知道它是一个指针 { return 0; }*/ if(0!=fclose(filePointer)) { return 0; } if(0!=strcmp(buffer,EMPTY_STR)) { while(NULL!=(temp=strstr(buffer,"\n"))) { *temp='\0'; } while(NULL!=(temp=strstr(buffer,"\r"))) { *temp='\0'; } strcpy(result,buffer); }else { strcpy(result,EMPTY_STR); return 0; } return 1; }
file.h
#ifndef FILE_H_INCLUDED #define FILE_H_INCLUDED extern int get_file_line(char *result,char *fileName,int lineNumber);//result前少打一个*号,然后就出现段错误 #endif
从中可以看到,main.c要用到file.c中的函数,所以引用了file.h头文件。
如果我们在只编译main.c文件的话程序会报错,如图:
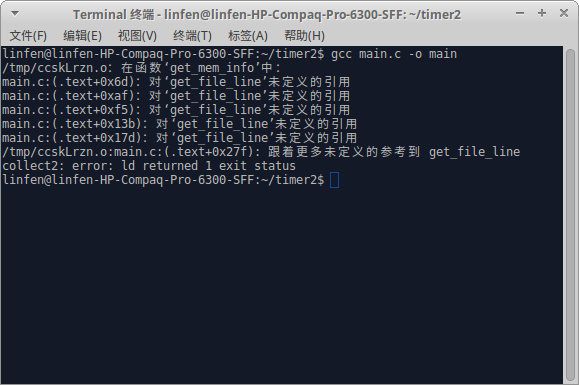
只有当同时编译main.c和file.c的时候程序才不会报错:
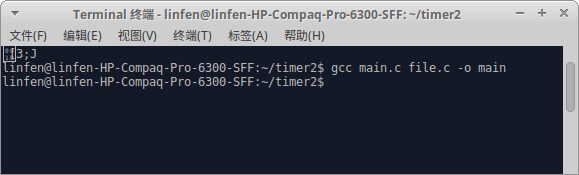
由此可见多文件编译的方法为:主文件要包含声明被引用文件函数的头文件,编译的时候主文件和被所有引用的文件要同时编译才可以。
这样的方法,在文件很少的时候还可以,在文件很多的时候就不怎么适用了。
当然,多个文件的编译还有其他方法,比如说makefile,不过如果你是一个一无所知的初学者的话,像codeblock这样的ide恐怕会更加让你觉得方便一些。
(三)具体方法
在codeblock当中编译多个文件十分简单,只要把所有相关联的文件添加到一个工程里面就够了。
使用codeblock编译实际上和命令行编译没有多大的区别,因为它实际上也是自动生成gcc 或g++命令行进行编译,无须我们手动费劲地输入命令行。codeblock本身不带编译器,使用的是我们系统本身已有的编译器。
(1)新建一个工程
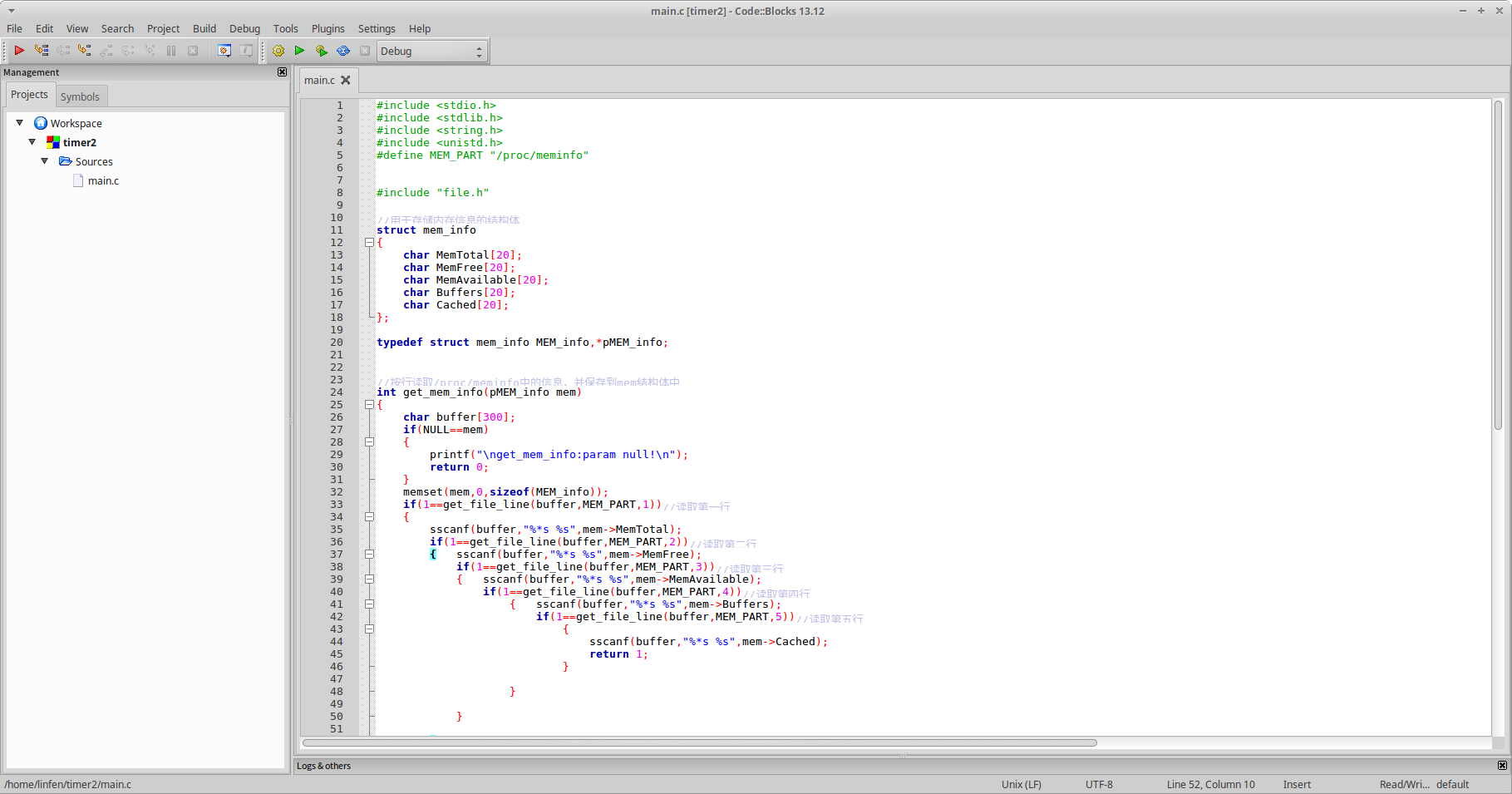
新建工程的过程在上一篇的文章中已经说过,把main.c代码复制粘贴进去就成这样
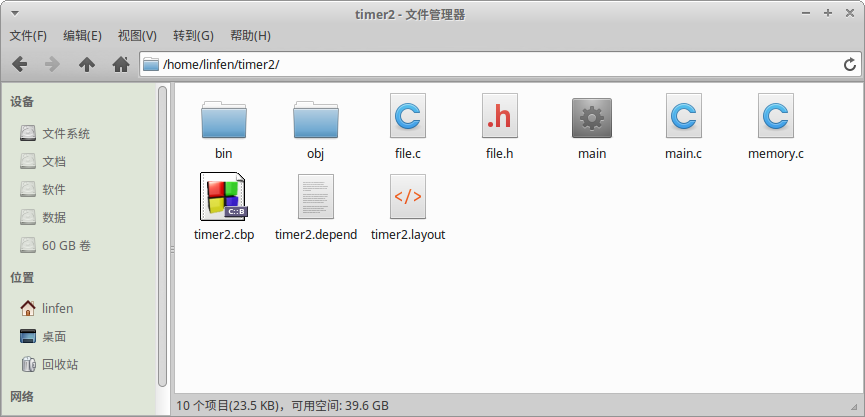
(2)把file.c file.h文件复制到工程目录下。
(3)在codeblock界面当中点击工程名,选择add file,将file.c和file.h都添加进工程里面(选中两个文件后点击open)
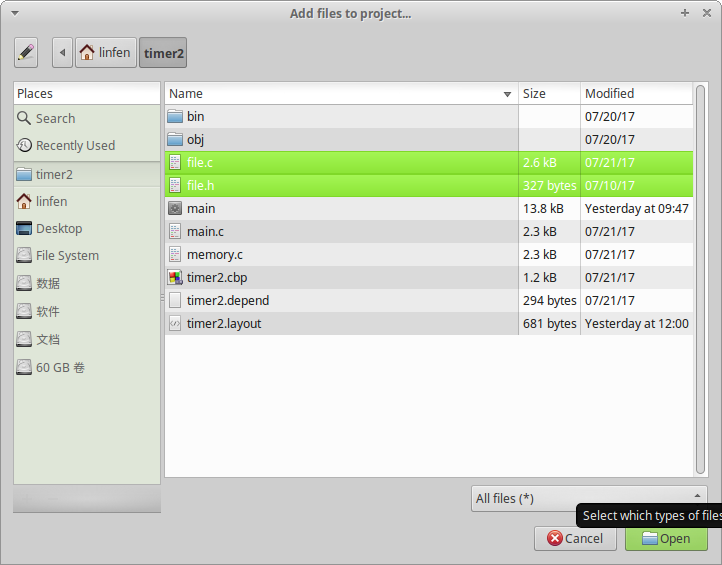
然后出现以下界面
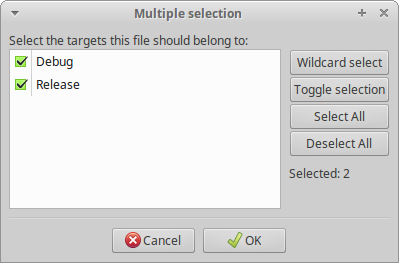
不用管太多,选择ok就好。
完成后的project界面就是如下这样子
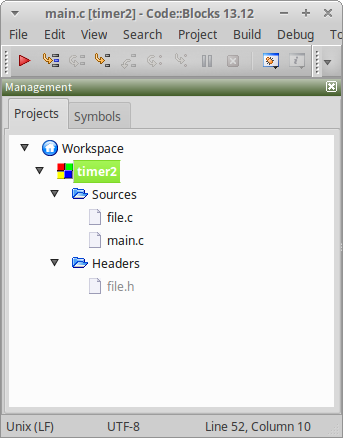
(4)编译
点击build 编译成功
如图
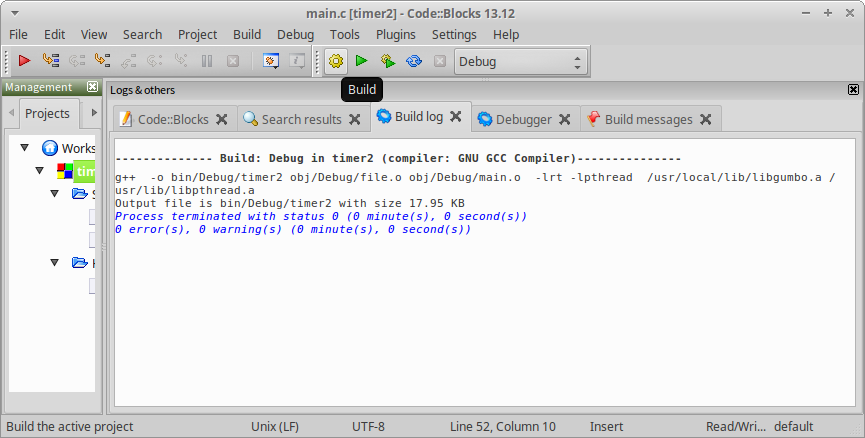
我的codeblock编译产生的命令行是这样子的
gcc -Wall -g -c /home/linfen/timer2/main.c -o obj/Debug/main.o
g++ -o bin/Debug/timer2 obj/Debug/file.o obj/Debug/main.o -lrt -lpthread /usr/local/lib/libgumbo.a /usr/lib/libpthread.a
但是你们自己编译的时候应该不会有-lrt -lpthread /usr/local/lib/libgumbo.a /usr/lib/libpthread.a这个东西。本工程即使没有-lrt -lpthread /usr/local/lib/libgumbo.a /usr/lib/libpthread.a也能正常编译(因为根本就没有用到那些库)。
之所以产生-lrt -lpthread /usr/local/lib/libgumbo.a /usr/lib/libpthread.a与我自己对codeblock编译器的编译设定有关,目的是引用第三方库。不过,本工程并没有引用第三方库,所以有没有-lrt -lpthread /usr/local/lib/libgumbo.a /usr/lib/libpthread.a都没有什么关系。
要想这方面了解更多可以继续看下一篇文章。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号