《程序员的自我修养》学习笔记 && Linux环境下的编译,链接综合学习
书看了很多,但是看书太抽象了。
CSapp第三版当中,第七章就是关于这本书所讲的ELF文件,编译链接这些东西,可以结合起来一起看
对于C语言来说,编译器默认函数和初始化了的全局变量为强符号,未初始化的全局变量为弱符号(C++并没有将未初始化的全局符号视为弱符号)
这很重要。
Question 1:课后习题7.7

下面默认把3改成5,不要在意这些细节上的错误。
对于x的重复定义,并且还使用了不同的变量类型来定义,怎么解决使得编译不会报错呢?
错误:

为了修改这个错误:
可以
/* bar5.c */ static double x; void f() { x=-0.0; }
这样就可以了。将全局变量x定义为
为什么这样就可以呢?STATIC变量问题 - 一个人的天空@ - 博客园 (cnblogs.com),这篇博客对于static介绍得非常好!非常好!
我们知道:
定义在函数内部的变量是局部变量,编译器为它在栈上分配空间,函数结束时分配的空间被收回。(使用GDB调试反汇编的时候加深了对于这一环节的认识)
定义在函数外部的变量是全局变量,编译器将它存储在静态存储区。全局变量有一个特点,那就是不仅仅可以被当前的编译单元访问(也就是当前的.c文件)。
堆上存储的是malloc之类的,这里不详细说了。
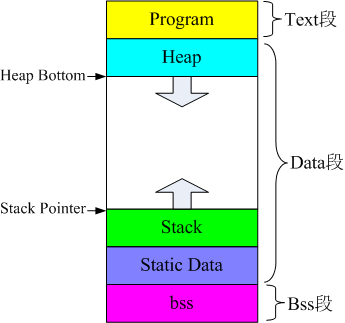
可以看书上p285,静态存储区包含初始化全局变量以及静态变量,未初始化全局变量和未初始化静态变量在bss段。:
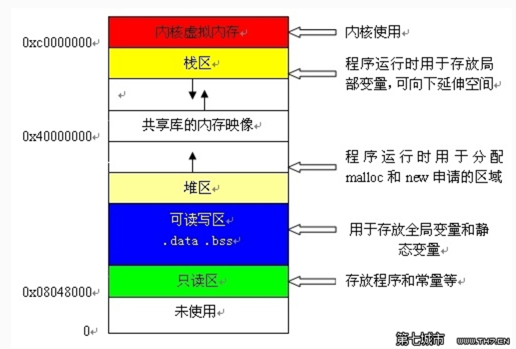
找不到图,linux的进程地址空间布局图,找一张类似的。
可读可写就是read/write section(.data .bss)
只读区:readonly section(.init .rodata .text)
静态存储区:(40条消息) 动态存储区、静态存储区、堆和栈的区别_qq_36802648的博客-CSDN博客_静态存储区


可见,对于变量来说,它有两种可见(全局可见,仅该编译单元可见),多种存储方式(堆,栈,静态存储区等)。
static的两大作用:
作用1:
使得该变量编译仅该编译单元可见。
作用2:
使得该变量存储在静态存储区。
对于局部变量使用static修饰,编译的时候已经是仅该编译单元可见了,使用static修饰仅仅是让它存储在静态存储区。
对于全局变量使用static修饰,全局变量已经存储在静态存储区,因此只是让它编译从全局可见变为仅本单元可见。
Question 2课后习题7.8
首先搞清楚什么是三个规则:

第一个的答案应该就如练习题7.2所说:

这题的答案:

我们来到习题:

答案是:

我想可能是因为,前一个main,函数,强符号,后一个是内部的静态变量,所以各找各妈。
Question 3 课后习题7.10 库依赖问题
静态编译的库依赖问题,很重要。
定义main2.c

这个c语言程序需要调用库libvector当中的函数。
在静态编译环境下,我们可以这样生成可执行文件:

具体的过程是:
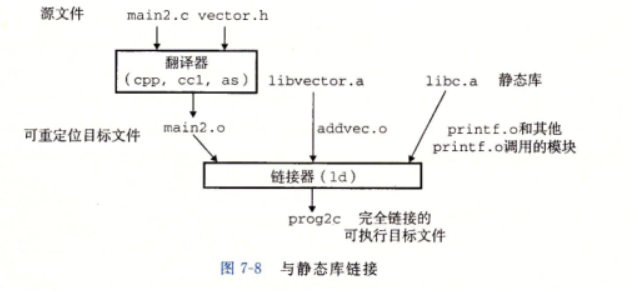
那么LINUX连接器如何解析这些引用呢?(也就是gcc的参数顺序的问题)
相信很多小伙伴都有在使用gcc时,因为参数顺序错误导致链接失败的经验。
gcc从左到右扫描参数,并且维护三个集合:
E:可重定位目标文件集合
U:未解析符号集合
D:在前面输入文件当中已定义符号集合
然后来介绍一下什么是Linux当中的存档文件。存档文件是一组连接起来的可重定位目标文件的集合,有一个头部用来描述每个成员目标文件的大小和位置。存档文件名用后缀.a来标识。
然后,对于gcc命令行当中的每一个输入文件f,链接器会判断f是一个目标文件还是一个存档文件。比如gcc -static -o prog2c main2.o ./libvector.a。对于这个gcc语句来说,有两个文件main2.o以及libvector.a这两个文件。前者是目标文件,后者是存档文件。
如果当前的是目标文件(main2.o),目标文件会被添加到E集合当中去,并且修改U和D集合来反映输入目标文件(main2.o)当中的符号和引用,继续读下一个文件(如果还有的话)。
如果当前的是存档文件(libvector.a),那么链接器此时就会尝试匹配U当中未解析的符号(由前面的main2.o生成的)。如果当前的存档文件(libvector.a)当中存在一个成员文件m(我们之前已经提到过了,存档文件是可重定位目标文件的集合),能够解析U中的一个未解析的符号(由前面的main2.o生成的),那么就把这个成员文件m加入到E集合当中。并且同时链接器会修改U和D文件。链接器会一直扫描.a存档文件,直到U和D都不再变化。然后.a文件当中不需要的部分都会被丢弃。链接器继续处理下一个文件。
举一个错误的例子:

为什么是错误的呢?因为这里.a文件在前,处理.a文件的时候,U集合是空的,相当于.a文件什么事情都干不了。
我们在了解了链接器的作用原理之后,再来分析一下各文件之间的依赖关系。
例子1:foo.c调用libx.a以及libz.a当中的函数,这两个库又依赖于liby.a当中的函数:

例子2:foo.c调用libx.a当中的函数,libx.a又调用liby.a当中的函数,liby.a又要调用libx.a当中的函数:
了解了链接器的作用原理之后显然我们需要这样来干。

答案:

Question 4 课后习题7.12 重定位问题:
在编译器完成了符号解析这一步之后,就需要重定位了。
举一个例子来说明:
如图所示的c语言程序:

对于main函数,反汇编得到反汇编代码:
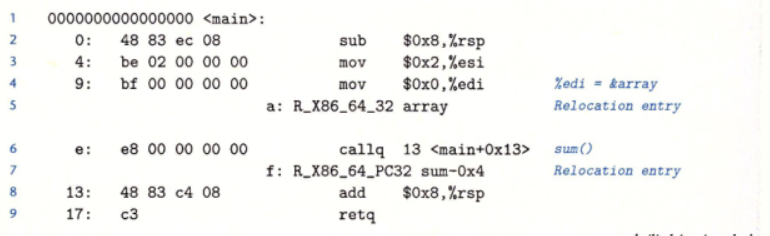
main函数当中,引用了两个全局符号:array和sum。
对于sum需要使用32位PC相对地址进行重定位,对于array的引用需要使用32位绝对地址。
重定位有重定位算法:

s是重定位节。首先链接器将所有输入模块相同的节合并成一块,比如来自所有输入模块的.data被合并成了.data节。在重定位节被确定之后,程序当中的所有指令和全局变量都有唯一的运行时内存地址了。比如对于text节,有了确定之后的地址ADDR(s)=ADDR(.text)=0x4004d0。对于符号ADDR(r.symbol)=ADDR(sum)=0x4004e8。
但是到了这里事情还没有完全完成。因为程序内部的指令还有对于这些全局变量的引用,这些指令还不知道这些全局变量的重定位之后的地址。如下面的这两个例子。
r是ELF重定位条目,结构如图所示:

可以看到refptr就是最终需要的重定位之后的地址。
算法分两种,一种是pc相对:R_X86_64_PC32,一种是绝对R_X86_64_32。
PC相对引用:
就是sum。显然sum定义在main.c的外部,因此是相对引用。
我们注意到反汇编代码当中,call指令开始于0xe的位置。

这条指令的机器码是e8 00 00 00 00,e8是这条指令的操作码,后面的32bit是留给sum的32位相对引用的。等到重定位的时候,sum的重定位之后的地址才会被填入这里。
这里首先,代码节地址是ADDR(s)=ADDR(.text)=0x4004d0
然后确定sum这个全局符号的地址也被确定:ADDR(r.symbol)=ADDR(sum)=0x4004e8。
重定位条目r:

重定位条目前面也提到了,这个东西是什么时候生成的呢?就如图前面的0xe800000000,这条代码,当链接器遇到这样的暂时不能够确定数据和代码的最终内存存放位置的时候,就会生成这样的一个重定位条目。
根据重定位算法:

显然,相对跳转,refaddr是需要重定位的指令的位置,在机器码往后一个。
用目标symbol的地址减去这个东西,4偏移量,我猜和00000000有关,这些都是重定位条目里的。
重定位绝对引用:
就是array。

重定位条目:

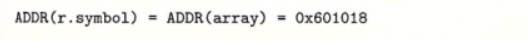

这里甚至不需要节地址,因为最终装载上去的就是这个符号的绝对地址,懂了就很简单。
最终重定位完成:
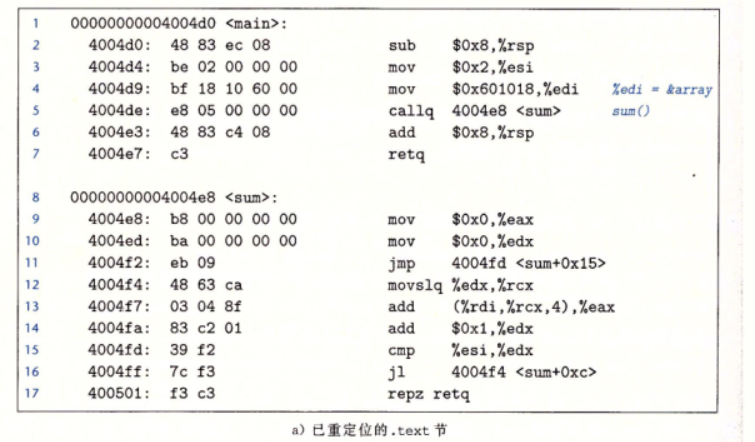
习题:


答案:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号