
Bridging the Gap between Deep Learning and Sparse Matrix Format Selection
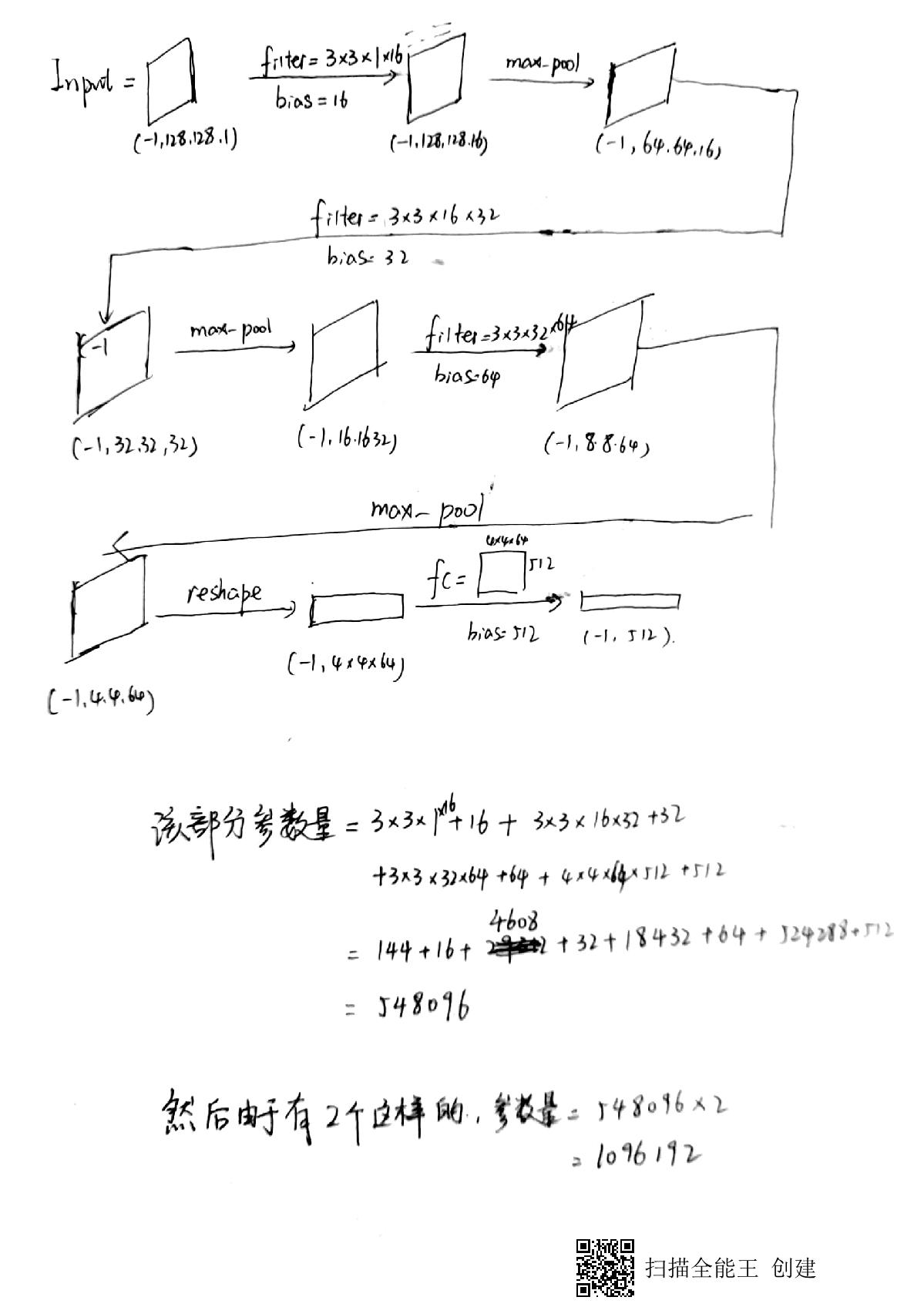
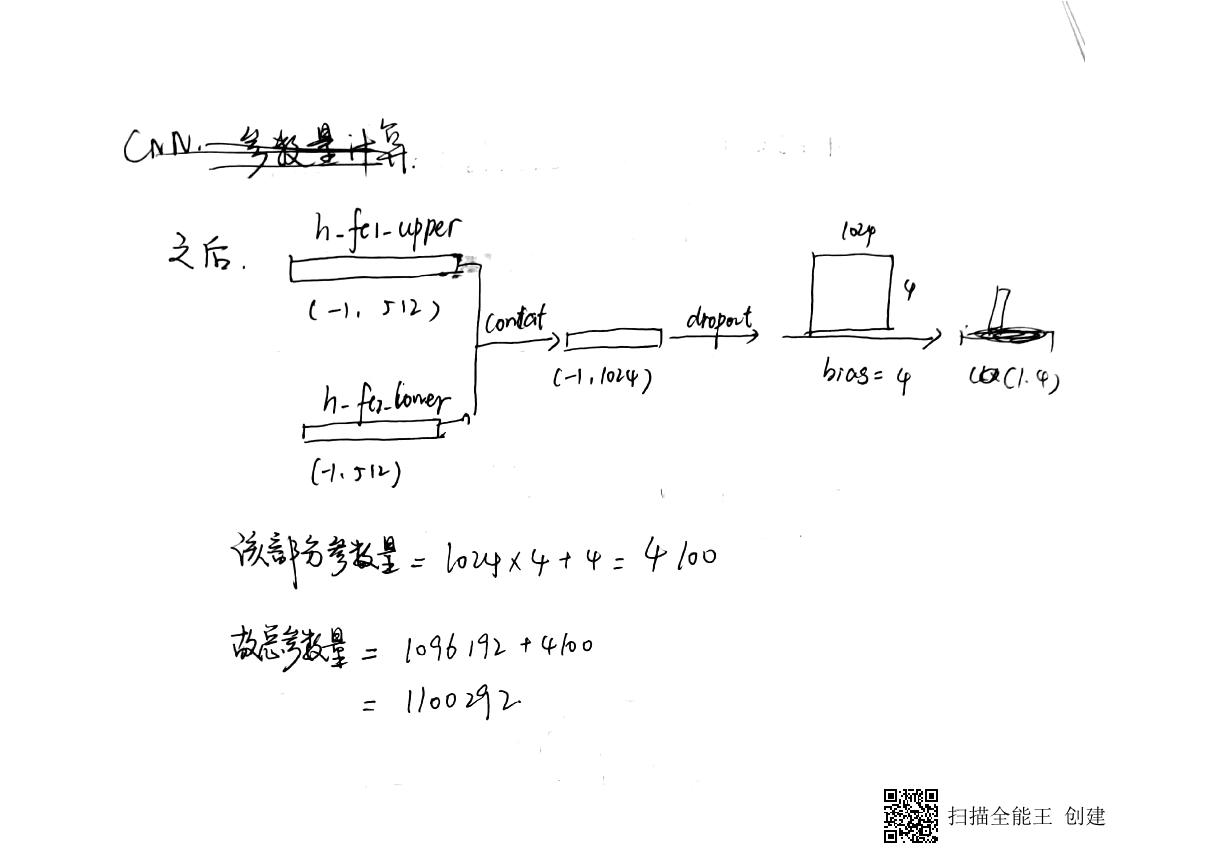
典型的CNN网络,学习,代码风格都一样的
import os import sys ROOTDIR = os.path.abspath(os.path.join(sys.path[0], '../../..')) sys.path.append(ROOTDIR) import tensorflow as tf import numpy as np from dnnspmv.model.dataset import DataSet from dnnspmv.model.lib.sample_wrapper import DlSample as Sampler # read data def load_data(filename): try: data = np.load(filename) ds = DataSet(data['img'], data['code']) except: print("Can not find data file") ds = None finally: return ds # help functions to build graph def weight_variable(shape): initial = tf.truncated_normal(shape, stddev=0.1) return tf.Variable(initial) def bias_variable(shape): initial = tf.constant(0.1, shape=shape) return tf.Variable(initial) def conv2d(x, W, strides=[1, 1, 1, 1]): return tf.nn.conv2d(x, W, strides=strides, padding='SAME') def max_pool_2x2(x): return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') def single_net(RES): with tf.name_scope('input'): x = tf.placeholder(tf.float32, shape=[None, RES, RES], name='x') y_ = tf.placeholder(tf.float32, shape=[None, 4], name='y') x_image = tf.reshape(x, [-1, RES, RES, 1], name='x-reshape') # first layer with tf.name_scope('layer1'): W_conv1 = weight_variable([3, 3, 1, 16]) b_conv1 = bias_variable([16]) h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) h_pool1 = max_pool_2x2(h_conv1) # [-1, 64, 64, 16] # second layer with tf.name_scope('layer2'): W_conv2 = weight_variable([3, 3, 16, 32]) b_conv2 = bias_variable([32]) h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2, strides=[1, 2, 2, 1]) + b_conv2) h_pool2 = max_pool_2x2(h_conv2) # [-1, 16, 16, 32] with tf.name_scope('layer3'): W_conv3 = weight_variable([3, 3, 32, 64]) b_conv3 = bias_variable([64]) h_conv3 = tf.nn.relu(conv2d(h_pool2, W_conv3, strides=[1, 2, 2, 1]) + b_conv3) h_pool3 = max_pool_2x2(h_conv3) # [-1, 4, 4, 64] = [-1, 1024] # dense layer with tf.name_scope('fc1'): W_fc1 = weight_variable([4 * 4 * 64, 512]) b_fc1 = bias_variable([512]) h_pool3_flat = tf.reshape(h_pool3, [-1, 4 * 4 * 64]) h_fc1 = tf.nn.relu(tf.matmul(h_pool3_flat, W_fc1) + b_fc1) # [-1, 512] return x, y_, h_fc1 class DLSpMVModel(object): def __init__(self, train_data, test_data): self.RES = 0 self.mean = 0 self.std = 1 self.train = load_data(train_data) if self.train: print(self.train.images.shape, self.train.labels.shape) self.RES = self.train.images.shape[-1] # 128 self.mean = np.mean(self.train.images[:,0,:,:], axis=0) self.std = np.std(self.train.images[:,0,:,:], axis=0) self.test = load_data(test_data) if self.test and self.RES == 0: print(self.test.images.shape, self.test.labels.shape) self.RES = self.test.images.shape[-1] # 128 self.STEPS = 10000 def build_graph(self): pass def training(self): print("Model is in training mode") assert self.train is not None and self.test is not None, "data not loaded" with tf.name_scope('upper'): x, y_, h_fc1_upper = single_net(self.RES) with tf.name_scope('lower'): x2, y2_, h_fc1_lower = single_net(self.RES) h_fc1 = tf.concat([h_fc1_upper, h_fc1_lower], axis=1) # [-1, 512 * 2] with tf.name_scope('dropout'): keep_prob = tf.placeholder(tf.float32, name='keep_prob') h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob) with tf.name_scope('out'): W_fc2 = weight_variable([512 * 2, 4]) b_fc2 = bias_variable([4]) y_conv = tf.add(tf.matmul(h_fc1_drop, W_fc2), b_fc2, name='y_conv_restore') #这就得到输出了 with tf.name_scope('cross_entropy'): cross_entropy = tf.reduce_mean( tf.nn.softmax_cross_entropy_with_logits( labels=y_, logits=y_conv) # takes unnormalized output ) with tf.name_scope('train'): train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy) correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1)) accuracy = tf.reduce_mean( tf.cast(correct_prediction, tf.float32), name='acc_to_restore') tf.summary.scalar('accuracy', accuracy) merged = tf.summary.merge_all() saver = tf.train.Saver() # traditional saving api # train the model with tf.Session() as sess: sess.run(tf.global_variables_initializer()) for i in range(self.STEPS): batch = self.train.next_batch(50) if i % 100 == 0: train_accuracy = sess.run(accuracy, feed_dict={x: batch[0][:,0,:,:], y_: batch[1], x2: batch[0][:,1,:,:], y2_: batch[1], keep_prob: 1.0}) print('step %d, training accuracy %g' % (i, train_accuracy)) else: _ = sess.run(train_step, feed_dict={x: batch[0][:,0,:,:], y_: batch[1], x2: batch[0][:,1,:,:], y2_: batch[1], keep_prob: 0.5}) # test print('test accuracy %g' % accuracy.eval(feed_dict={x: self.test.images[:,0,:,:], y_: self.test.labels, x2: self.test.images[:,1,:,:], y2_: self.test.labels, keep_prob: 1.0})) # save model and checkpoint save_path = saver.save(sess, os.path.join(ROOTDIR, "dnnspmv/model/spmv/model-{}.ckpt".format(self.STEPS))) print("Model saved in file %s" % save_path) def testing(self): """ restore model and checkpoint [description] """ print("Model is in testing mode") assert self.test is not None, "data not loaded" tf.reset_default_graph() # the graph is empty now, must build graph before restore value with tf.Session() as sess: # retore graph saver = tf.train.import_meta_graph(os.path.join(ROOTDIR, 'dnnspmv/model/spmv/model-{}.ckpt.meta'.format(self.STEPS))) # the current graph can be explored by graph = tf.get_default_graph() # restore value saver.restore(sess, tf.train.latest_checkpoint(os.path.join(ROOTDIR, 'dnnspmv/model/spmv'))) print("Model restored") x = graph.get_tensor_by_name("upper/input/x:0") y = graph.get_tensor_by_name("upper/input/y:0") x2 = graph.get_tensor_by_name("lower/input/x:0") y2_ = graph.get_tensor_by_name("lower/input/y:0") keep_prob = graph.get_tensor_by_name("dropout/keep_prob:0") # for tensor, use get_tensor_by_name() # for operation, use get_operation_by_name() # NOTE: Tensor names must be of the form "<op_name>:<output_index>" acc = graph.get_tensor_by_name('train/acc_to_restore:0') # test print("-------------------------------------------------------") print('Test accuracy %g' % sess.run(acc, feed_dict={x: self.test.images[:,0,:,:], y: self.test.labels, x2: self.test.images[:,1,:,:], y2_: self.test.labels, keep_prob: 1.0})) print("-------------------------------------------------------") # for prediction def _img_norm(self, img): return (img - self.mean) / self.std def predict(self, matrix_mtx): print("Model is in prediction mode") assert self.train is not None, "train data required" format_dict = ['COO', 'CSR', 'DIA', 'ELL'] sl = Sampler() img, img_ = sl.sample(matrix_mtx, self.RES) img = self._img_norm(img); img_ = self._img_norm(img_) imgs = img.reshape(1, self.RES, self.RES); imgs_ = img_.reshape(1, self.RES, self.RES) tf.reset_default_graph() # the graph is empty now, must build graph before restore value with tf.Session() as sess: # retore graph saver = tf.train.import_meta_graph(os.path.join(ROOTDIR, 'dnnspmv/model/spmv/model-10000.ckpt.meta')) # the current graph can be explored by graph = tf.get_default_graph() # restore value saver.restore(sess, tf.train.latest_checkpoint(os.path.join(ROOTDIR, 'dnnspmv/model/spmv'))) print("Model restored") x = graph.get_tensor_by_name("upper/input/x:0") x2 = graph.get_tensor_by_name("lower/input/x:0") keep_prob = graph.get_tensor_by_name("dropout/keep_prob:0") y_conv = graph.get_tensor_by_name('out/y_conv_restore:0') y_pred = sess.run(y_conv, feed_dict={x: imgs, x2: imgs_, keep_prob: 1.0}) fmts = [*map(lambda i: format_dict[i], np.argmax(y_pred, axis=1))] print("-------------------------------------------------------") print('The predicted best format for matrix {} is {}'.format(os.path.basename(matrix_mtx), fmts)) print("-------------------------------------------------------") return def main(): if len(sys.argv) < 2: print("Usage: {} FLAG{train, test, predict}") exit() FLAG = sys.argv[1].lower() model = DLSpMVModel(os.path.join(ROOTDIR, 'dnnspmv/data/train-data.npz'), os.path.join(ROOTDIR, 'dnnspmv/data/test-data.npz')) print(type(model)) if FLAG == 'train': model.training() elif FLAG == 'test': model.testing() elif FLAG == 'predict': if len(sys.argv) < 3: print("Predict mode: {} predict <mtxfile>".format(sys.argv[0])) exit() mtxfile = sys.argv[2] model.predict(mtxfile.encode()) if __name__ == '__main__': main()
其网络结构真的很简单
这篇文章的暂时的一些想法:
整个程序的处理步骤应该是这样的:首先,线下选取很多矩阵,当做训练集。训练集中的矩阵,按照四种稀疏矩阵存储方式都跑一遍,然后测试得出该矩阵的最佳存储方式,作为label。
然后到了CNN训练环节。所有大小可能不统一的矩阵按照DistanceHistogramRepresentation 的格式表示成统一大小格式的矩阵,输入构造好的CNN。
然后就得到了训练好的CNN,可以用来预测最佳存储矩阵。
读这篇文章的收获如下:
1.使用CNN的方法来完成矩阵最佳适应存储方式匹配。CNN的分叉格式比较新颖。
2.使用DistanceHistogramRepresentation 的格式表示成统一大小格式的矩阵。以前不知道怎么将矩阵大小统一成同样的大小。该方法提供了新的思路。
3.使用迁移学习的方法,将训练好的CNN网络移植到其他的平台上去重复使用。
有点疑惑的地方:
1.感觉模型太简单了,相对于SMAT那篇文章来说。SMAT好像有许多的threshold以及对于矩阵,硬件平台都提取了很多的丰富的特征。但是这里提取的只是依据矩阵的形状然后用类似CNN图像识别的方法来获取最佳存储格式。我感觉还是要好好看一看SMAT,那里提取了很多的参数,然后用决策树的方法来进行机器学习。
和师兄交流以后终于明白了,难度不是机器学习方法,而是获取数据的正确训练方法,底层编译优化,cache等,使代码适应机器。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号