CNN之VGG
1.学会用pytorch实现CNN
首先上代码:mnist数据集的预测,代码来自于https://blog.csdn.net/WeilingDu/article/details/108620894
#暂时看不懂https://blog.csdn.net/qq_27825451/article/details/90550890 #https://blog.csdn.net/qq_27825451/article/details/90705328这个也看不懂,佛了 import torch from torchvision import transforms from torchvision import datasets from torch.utils.data import DataLoader import torch.nn.functional as F batch_size = 64 transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307, ), (0.3081, ))]) #这行代码是有关mnist数据集的标准化的(据说这样做可以加快模型的收敛) #回想一下mnist数据集的结构,是一个灰度矩阵,一张图片是28*28的像素,灰度值为[0,255] #transforms.ToTensor()可以将灰度矩阵的灰度值收敛到[0,1]的这个区间 #而transforms.Normalize(),顾名思义,就是对[0,1]的值标准化,类似以正态分布标准化(x-μ)/σ, #不是将数据收敛到[-1,1]的这个范围,而是将数据的分布改变为均值0,标准差为1(学过统计自然懂) #问题来了,0.1307和0.3081就是mnist数据集的均值和标准差,那么为何需要手动输入呢?不输入不行吗? #好像是从数据集中预先抽样统计出来的。。。真奇怪。。写代码之前还要计算μ和σ吗 train_dataset = datasets.MNIST(root='./mnist/', train=True, download=True, transform=transform) train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size) #pytorch当中读取数据的方法果然很简洁。 #shuffle=True可以打乱数据集,然后按照batch取出数据使用 test_dataset = datasets.MNIST(root='./mnist/', train=False, download=True, transform=transform) test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size) #训练集和测试集 # 28 28 # 28 * 28 64 # 16 7*7*64 #16 1024 #有个问题,cost=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred,labels=y)) #logits矩阵的col一定是batch?为什么上面有个16,是我哪里搞错了吗? class Net(torch.nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5) # 卷积层1:input channel=1, output channel=10 self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5) # 卷积层2:input channel=10, output channel=20 self.pooling = torch.nn.MaxPool2d(2) # 池化层 self.fc = torch.nn.Linear(320, 10) # 全连接层:输入维度为320, 输出维度为10 #结合之前TensorFlow当中的全连接层操作,不难想到 #28-5+1=24,第一次池化得到12 #12-5+1=8,第二次池化得到4 #然后64*4*4*20,全连接层输入就是320了 def forward(self, x): # Flatten data from (n, 1, 28, 28) to (n, 784) batch_size = x.size(0) x = F.relu(self.pooling(self.conv1(x))) x = F.relu(self.pooling(self.conv2(x))) x = x.view(batch_size, -1) # flatten,现在看来易如反掌 x = self.fc(x) return x #init和forwar之间是有关系的,init里面只是定义了一系列的层,但是没有说明层之间的联系是怎么样的。 #forward实现各层之间的联系。 #torch实现神经网络有两种方法,高层api方法使用torch.nn.xxx方法,低层函数使用torch.nn.functional.xxx来实现 #好像有点明白了,forward就是根据init定义的网络,接收输入数据,然后返回网络的输出数据 #看一下forward操作,就是很简单的操作,将一维的输入得到最终的CNN输出 model = Net() criterion = torch.nn.CrossEntropyLoss() optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.5) def train(epoch): running_loss = 0.0 for batch_idx, data in enumerate(train_loader, 0): inputs, target = data optimizer.zero_grad() # forward + backwar + updata outputs = model(inputs) loss = criterion(outputs, target) loss.backward() optimizer.step() running_loss += loss.item() if batch_idx % 300 == 299: print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300)) running_loss = 0.0 def test(): correct = 0 total = 0 with torch.no_grad(): for data in test_loader: images, labels = data outputs = model(images) _, predicted = torch.max(outputs.data, dim=1) total += labels.size(0) correct += (predicted == labels).sum().item() print('Accuracy on test set: %d %%' % (100 * correct / total)) for epoch in range(10): train(epoch) test()
只能说会了TensorFlow版本的pytorch看懂了大概架构就不难,做的都是一样的事情。
这个可以作为一个小模板。里面的细节还没看完,以后边写代码边学。
2.学会用pytorch实现VGG
神经网络发展:https://zhuanlan.zhihu.com/p/213137993?utm_source=ZHShareTargetIDMore
感受野计算相关:https://blog.csdn.net/program_developer/article/details/80958716
:https://zhuanlan.zhihu.com/p/44106492
代码来自https://blog.csdn.net/weixin_38132153/article/details/107616764
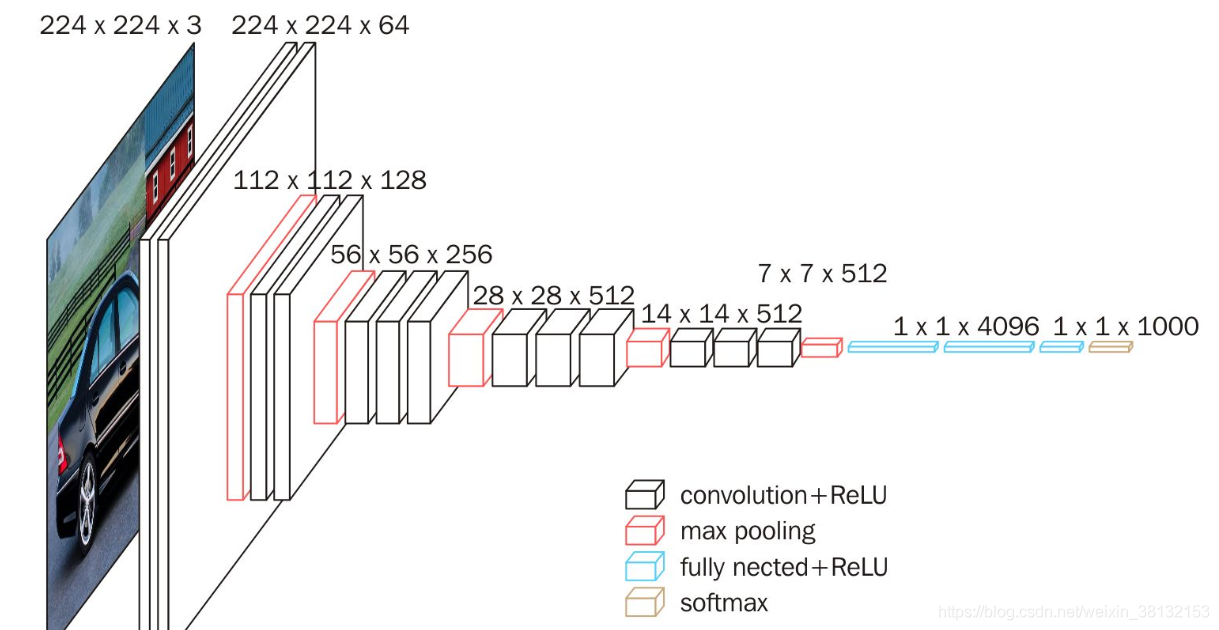
VGG的结构其实很简单,如下图:
import torch import torch.nn as nn class VGG16(nn.Module): def __init__(self, nums): super(VGG16, self).__init__() self.nums = nums vgg = [] # 第一个卷积部分 # 112, 112, 64 vgg.append(nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, stride=1, padding=1)) vgg.append(nn.ReLU()) vgg.append(nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1)) vgg.append(nn.ReLU()) vgg.append(nn.MaxPool2d(kernel_size=2, stride=2)) # 第二个卷积部分 # 56, 56, 128 vgg.append(nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1)) vgg.append(nn.ReLU()) vgg.append(nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1)) vgg.append(nn.ReLU()) vgg.append(nn.MaxPool2d(kernel_size=2, stride=2)) # 第三个卷积部分 # 28, 28, 256 vgg.append(nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1)) vgg.append(nn.ReLU()) vgg.append(nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1)) vgg.append(nn.ReLU()) vgg.append(nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1)) vgg.append(nn.ReLU()) vgg.append(nn.MaxPool2d(kernel_size=2, stride=2)) # 第四个卷积部分 # 14, 14, 512 vgg.append(nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1)) vgg.append(nn.ReLU()) vgg.append(nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1)) vgg.append(nn.ReLU()) vgg.append(nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1)) vgg.append(nn.ReLU()) vgg.append(nn.MaxPool2d(kernel_size=2, stride=2)) # 第五个卷积部分 # 7, 7, 512 vgg.append(nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1)) vgg.append(nn.ReLU()) vgg.append(nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1)) vgg.append(nn.ReLU()) vgg.append(nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1)) vgg.append(nn.ReLU()) vgg.append(nn.MaxPool2d(kernel_size=2, stride=2)) # 将每一个模块按照他们的顺序送入到nn.Sequential中,输入要么事orderdict,要么事一系列的模型,遇到上述的list,必须用*号进行转化 self.main = nn.Sequential(*vgg) # 全连接层 classfication = [] # in_features四维张量变成二维[batch_size,channels,width,height]变成[batch_size,channels*width*height] classfication.append(nn.Linear(in_features=512 * 7 * 7, out_features=4096)) # 输出4096个神经元,参数变成512*7*7*4096+bias(4096)个 classfication.append(nn.ReLU()) classfication.append(nn.Dropout(p=0.5)) classfication.append(nn.Linear(in_features=4096, out_features=4096)) classfication.append(nn.ReLU()) classfication.append(nn.Dropout(p=0.5)) classfication.append(nn.Linear(in_features=4096, out_features=self.nums)) self.classfication = nn.Sequential(*classfication) def forward(self, x): feature = self.main(x) # 输入张量x feature = feature.view(x.size(0), -1) # reshape x变成[batch_size,channels*width*height] result = self.classfication(feature) return result x = torch.rand(size=(8, 3, 224, 224)) vgg16 = VGG16(nums=1000) out = vgg16(x) print(vgg16)
值得学习的一点就是这里的
vgg = []
。。。
self.main = nn.Sequential(*vgg)
以及
classfication = []
。。。
self.classfication = nn.Sequential(*classfication)
这种按构造顺序运行的代码。这样在forward当中代码就相当好写了。
大概的执行流程就如下图,感觉也没怎么样。。。感觉不到这个网络的神奇之处。

那么这些卷积核为什么要这样设置呢?
3.读懂师兄的VGG代码
node_list=[] edge_list=[] kernel_h = 3 kernel_w = 3 kernel_size = kernel_h*kernel_w pool_size = 2*2 data_per_pix = 1 def jsonout(fileout, nodes, edges): with open(fileout, "w") as result: outItem = "{\n \"nodes\":\n [\n" result.write(outItem) # Write nodes for i in range(len(nodes)-1): outItem = "\t{\"id\":\""+(str)(nodes[i][0])+"\",\n\t\"comDmd\":\""+(str)(nodes[i][1])+"\",\n\t\"dataDmd\":\""+(str)(nodes[i][2])+"\"\n\t},\n" result.write(outItem) outItem = "\t{\"id\":\""+(str)(nodes[-1][0])+"\",\n\t\"comDmd\":\""+(str)(nodes[-1][1])+"\",\n\t\"dataDmd\":\""+(str)(nodes[-1][2])+"\"\n\t}\n" result.write(outItem) outItem = " ],\n \"edges\":\n [\n" result.write(outItem) for i in range(len(edges)-1): outItem = "\t{\"src\":\""+(str)(edges[i][0])+"\",\n\t\"dst\":\""+(str)(edges[i][1])+"\",\n\t\"weight\":\""+(str)(edges[i][2])+"\"\n\t},\n" result.write(outItem) outItem = "\t{\"src\":\""+(str)(edges[-1][0])+"\",\n\t\"dst\":\""+(str)(edges[-1][1])+"\",\n\t\"weight\":\""+(str)(edges[-1][2])+"\"\n\t}\n" result.write(outItem) outItem = " ]\n}\n" result.write(outItem) def conv_map(img_h, img_w, last_c, h_per_node_last_layer, w_per_node_last_layer, h_per_node, w_per_node, present_c, type): comm = kernel_size*last_c*present_c*h_per_node*w_per_node data = float(kernel_size*last_c*present_c + (h_per_node+2)*(w_per_node+2)*last_c*data_per_pix)/1024 node_per_row = int(img_w/w_per_node) node_per_col = int(img_h/h_per_node) if type == 0: w_per_node_last_layer = w_per_node h_per_node_last_layer = h_per_node node_per_row_last_layer = int(img_w/w_per_node_last_layer) node_per_col_last_layer = int(img_h/h_per_node_last_layer) node_num_last_layer = node_per_row_last_layer*node_per_col_last_layer node_part_num_row = int(node_per_row/node_per_row_last_layer) node_part_num_col = int(node_per_col/node_per_col_last_layer) pre_node_num = len(node_list) for raw_num in range(node_per_col): for col_num in range(node_per_row): node_list.append([raw_num*node_per_row+col_num+pre_node_num, comm, data]) #three kind of conv-layer dependencies: #type=0 means null-conv (first conv layer, no data dependencies) #type=1 means conv-conv (last layer is conv layer) #type=2 means pool-conv (last layer is pool layer) if type == 1: #one-to-one data dependencies, conv-conv weight1 = float(h_per_node*w_per_node*last_c*data_per_pix)/1024 weight2 = float(h_per_node*last_c*data_per_pix)/1024 weight3 = float(w_per_node*last_c*data_per_pix)/1024 weight4 = float(1*last_c*data_per_pix)/1024 for raw_num in range(node_per_col): for col_num in range(node_per_row): node_index = raw_num*node_per_row+col_num last_node_index = node_index edge_list.append([last_node_index+pre_node_num-node_num_last_layer, node_index+pre_node_num, weight1]) #(last_layer[i], pre_layer[i]) if col_num > 0: #has the left data dependencies edge_list.append([last_node_index+pre_node_num-node_num_last_layer-1, node_index+pre_node_num, weight2]) #(last_layer[i-1], pre_layer[i]) if col_num < node_per_row-1: #has the right data dependencies edge_list.append([last_node_index+pre_node_num-node_num_last_layer+1, node_index+pre_node_num, weight2]) #(last_layer[i+1], pre_layer[i]) if raw_num > 0: #has the upper data dependencies edge_list.append([last_node_index+pre_node_num-node_num_last_layer-node_per_row, node_index+pre_node_num, weight3]) #(last_layer[i-node_per_row], pre_layer[i]) if raw_num < node_per_col-1: #has the lower data dependencies edge_list.append([last_node_index+pre_node_num-node_num_last_layer+node_per_row, node_index+pre_node_num, weight3]) #(last_layer[i+node_per_row], pre_layer[i]) if col_num > 0 and raw_num > 0: #has the left and upper data dependencies edge_list.append([last_node_index+pre_node_num-node_num_last_layer-node_per_row-1, node_index+pre_node_num, weight4]) #(last_layer[i-node_per_row-1], pre_layer[i]) if col_num > 0 and raw_num < node_per_col-1: #has the left and lower data dependencies edge_list.append([last_node_index+pre_node_num-node_num_last_layer+node_per_row-1, node_index+pre_node_num, weight4]) #(last_layer[i+node_per_row-1], pre_layer[i]) if col_num < node_per_row-1 and raw_num > 0: #has the upper and left data dependencies edge_list.append([last_node_index+pre_node_num-node_num_last_layer-node_per_row+1, node_index+pre_node_num, weight4]) #(last_layer[i-node_per_row+1], pre_layer[i]) if col_num < node_per_row-1 and raw_num < node_per_col-1: #has the lower and left data dependencies edge_list.append([last_node_index+pre_node_num-node_num_last_layer+node_per_row+1, node_index+pre_node_num, weight4]) #(last_layer[i+node_per_row+1], pre_layer[i]) if type == 2: #one-to-many data dependencies, pool-conv weight0 = float((h_per_node+2)*(w_per_node+2)*last_c*data_per_pix)/1024 weight1 = float(h_per_node*w_per_node*last_c*data_per_pix)/1024 weight2 = float(h_per_node*last_c*data_per_pix)/1024 weight3 = float(w_per_node*last_c*data_per_pix)/1024 weight4 = float(1*last_c*data_per_pix)/1024 for raw_num in range(node_per_col): for col_num in range(node_per_row): node_index = raw_num*node_per_row+col_num last_node_index = int(raw_num/node_part_num_col)*node_per_row_last_layer+int(col_num/node_part_num_row) if col_num%node_part_num_row == 0 and col_num > 0: #left edge_list.append([last_node_index+pre_node_num-node_num_last_layer-1, node_index+pre_node_num, weight2]) if col_num%node_part_num_row == node_part_num_row-1 and col_num < node_per_row-1: #right edge_list.append([last_node_index+pre_node_num-node_num_last_layer+1, node_index+pre_node_num, weight2]) if raw_num%node_part_num_col == 0 and raw_num > 0: #upper edge_list.append([last_node_index+pre_node_num-node_num_last_layer-node_per_row_last_layer, node_index+pre_node_num, weight3]) if raw_num%node_part_num_col == node_part_num_col-1 and raw_num < node_per_col-1: #lower edge_list.append([last_node_index+pre_node_num-node_num_last_layer+node_per_row_last_layer, node_index+pre_node_num, weight3]) if col_num%node_part_num_row == 0 and col_num > 0 and raw_num%node_part_num_col == 0 and raw_num > 0: #left and upper edge_list.append([last_node_index+pre_node_num-node_num_last_layer-node_per_row_last_layer-1, node_index+pre_node_num, weight4]) if col_num%node_part_num_row == 0 and col_num > 0 and raw_num%node_part_num_col == node_part_num_col-1 and raw_num < node_per_col-1: #left and lower edge_list.append([last_node_index+pre_node_num-node_num_last_layer+node_per_row_last_layer-1, node_index+pre_node_num, weight4]) if col_num%node_part_num_row == node_part_num_row-1 and col_num < node_per_row-1 and raw_num%node_part_num_col == 0 and raw_num > 0: #right and upper edge_list.append([last_node_index+pre_node_num-node_num_last_layer-node_per_row_last_layer+1, node_index+pre_node_num, weight4]) if col_num%node_part_num_row == node_part_num_row-1 and col_num < node_per_row-1 and raw_num%node_part_num_col == node_part_num_col-1 and raw_num < node_per_col-1: #right and lower edge_list.append([last_node_index+pre_node_num-node_num_last_layer+node_per_row_last_layer+1, node_index+pre_node_num, weight4]) if col_num%node_part_num_row > 0 and col_num%node_part_num_row < node_part_num_row-1 \ and raw_num%node_part_num_col > 0 and raw_num%node_part_num_col < node_part_num_col-1: edge_list.append([last_node_index+pre_node_num-node_num_last_layer, node_index+pre_node_num, weight0]) elif col_num%node_part_num_row > 0 and col_num%node_part_num_row < node_part_num_row-1 \ and ((raw_num%node_part_num_col == 0) or (raw_num%node_part_num_col == node_part_num_col-1)): edge_list.append([last_node_index+pre_node_num-node_num_last_layer, node_index+pre_node_num, weight1+2*weight2+weight3]) elif ((col_num%node_part_num_row == 0) or (col_num%node_part_num_row == node_part_num_row-1)) \ and raw_num%node_part_num_col > 0 and raw_num%node_part_num_col < node_part_num_col-1: edge_list.append([last_node_index+pre_node_num-node_num_last_layer, node_index+pre_node_num, weight1+weight2+2*weight3]) else: edge_list.append([last_node_index+pre_node_num-node_num_last_layer, node_index+pre_node_num, weight1+weight2+weight3+weight4]) def pool_map(img_h, img_w, last_c, h_per_node_last_layer, w_per_node_last_layer, h_per_node, w_per_node): #many-to-one data dependencies, conv-pool comm = int(pool_size*h_per_node/2*w_per_node/2*last_c) data = float(h_per_node*w_per_node*last_c*data_per_pix)/1024 node_per_row = int(img_w/w_per_node) node_per_col = int(img_h/h_per_node) node_per_row_last_layer = int(img_w/w_per_node_last_layer) node_per_col_last_layer = int(img_h/h_per_node_last_layer) node_num_last_layer = node_per_row_last_layer*node_per_col_last_layer node_part_num_row = int(node_per_row_last_layer/node_per_row) node_part_num_col = int(node_per_col_last_layer/node_per_col) pre_node_num = len(node_list) for raw_num in range(node_per_col): for col_num in range(node_per_row): node_list.append([raw_num*node_per_row+col_num+pre_node_num, comm, data]) weight = float(h_per_node_last_layer*w_per_node_last_layer*last_c*data_per_pix)/1024 for raw_num in range(node_per_col): for col_num in range(node_per_row): node_index = raw_num*node_per_row+col_num last_node_index = raw_num*node_part_num_col*node_per_row_last_layer+col_num*node_part_num_row for part_raw_num in range(node_part_num_col): for part_col_num in range(node_part_num_row): part_node_index = part_raw_num*node_per_row_last_layer+part_col_num edge_list.append([last_node_index+pre_node_num-node_num_last_layer+part_node_index, node_index+pre_node_num, weight]) def fc_map(img_h, img_w, last_c, node_num_last_layer, present_c, fc_level): comm = img_h*img_w*last_c*fc_level data = float(img_h*img_w*last_c*data_per_pix+img_h*img_w*last_c*fc_level)/1024 node_num = int(present_c/fc_level) pre_node_num = len(node_list) for fc_num in range(node_num): node_list.append([pre_node_num+fc_num, comm, data]) weight = float(img_h*img_w/node_num_last_layer*last_c*data_per_pix)/1024 for node_index in range(node_num): for last_node_index in range(node_num_last_layer): edge_list.append([last_node_index+pre_node_num-node_num_last_layer, node_index+pre_node_num, weight]) def generage_dag(): print ("***start generation***") print ("\nlen(node_list):\t", len(node_list)) print ("\nlen(edge_list):\t", len(edge_list)) conv_map(224, 224, 3, 1, 1, 4, 4, 64, 0) print ("\n***conv1_1***") print ("\nlen(node_list):\t", len(node_list)) print ("\nlen(edge_list):\t", len(edge_list)) conv_map(224, 224, 64, 4, 4, 4, 4, 64, 1) print ("\n***conv1_2***") print ("\nlen(node_list):\t", len(node_list)) print ("\nlen(edge_list):\t", len(edge_list)) pool_map(224, 224, 64, 4, 4, 56, 56) print ("\n***pool1***") print ("\nlen(node_list):\t", len(node_list)) print ("\nlen(edge_list):\t", len(edge_list)) conv_map(112, 112, 64, 28, 28, 4, 4, 128, 2) print ("\n***conv2_1***") print ("\nlen(node_list):\t", len(node_list)) print ("\nlen(edge_list):\t", len(edge_list)) conv_map(112, 112, 128, 4, 4, 4, 4, 128, 1) print ("\n***conv2_2***") print ("\nlen(node_list):\t", len(node_list)) print ("\nlen(edge_list):\t", len(edge_list)) pool_map(112, 112, 128, 4, 4, 56, 56) print ("\n***pool2***") print ("\nlen(node_list):\t", len(node_list)) print ("\nlen(edge_list):\t", len(edge_list)) conv_map(56, 56, 128, 28, 28, 4, 4, 256, 2) print ("\n***conv3_1***") print ("\nlen(node_list):\t", len(node_list)) print ("\nlen(edge_list):\t", len(edge_list)) conv_map(56, 56, 256, 4, 4, 4, 4, 256, 1) print ("\n***conv3_2***") print ("\nlen(node_list):\t", len(node_list)) print ("\nlen(edge_list):\t", len(edge_list)) conv_map(56, 56, 256, 4, 4, 4, 4, 256, 1) print ("\n***conv3_3***") print ("\nlen(node_list):\t", len(node_list)) print ("\nlen(edge_list):\t", len(edge_list)) # conv_map(56, 56, 256, 7, 7, 7, 7, 256, 1) # print ("\n***conv3_4***") # print ("\nlen(node_list):\t", len(node_list)) # print ("\nlen(edge_list):\t", len(edge_list)) pool_map(56, 56, 256, 4, 4, 28, 28) print ("\n***pool3***") print ("\nlen(node_list):\t", len(node_list)) print ("\nlen(edge_list):\t", len(edge_list)) conv_map(28, 28, 256, 14, 14, 4, 4, 512, 2) print ("\n***conv4_1***") print ("\nlen(node_list):\t", len(node_list)) print ("\nlen(edge_list):\t", len(edge_list)) conv_map(28, 28, 512, 4, 4, 4, 4, 512, 1) print ("\n***conv4_2***") print ("\nlen(node_list):\t", len(node_list)) print ("\nlen(edge_list):\t", len(edge_list)) conv_map(28, 28, 512, 4, 4, 4, 4, 512, 1) print ("\n***conv4_3***") print ("\nlen(node_list):\t", len(node_list)) print ("\nlen(edge_list):\t", len(edge_list)) # conv_map(28, 28, 512, 7, 7, 7, 7, 512, 1) # print ("\n***conv4_4***") # print ("\nlen(node_list):\t", len(node_list)) # print ("\nlen(edge_list):\t", len(edge_list)) pool_map(28, 28, 512, 4, 4, 14, 14) print ("\n***pool4***") print ("\nlen(node_list):\t", len(node_list)) print ("\nlen(edge_list):\t", len(edge_list)) conv_map(14, 14, 512, 7, 7, 2, 2, 512, 2) print ("\n***conv5_1***") print ("\nlen(node_list):\t", len(node_list)) print ("\nlen(edge_list):\t", len(edge_list)) conv_map(14, 14, 512, 2, 2, 2, 2, 512, 1) print ("\n***conv5_2***") print ("\nlen(node_list):\t", len(node_list)) print ("\nlen(edge_list):\t", len(edge_list)) conv_map(14, 14, 512, 2, 2, 2, 2, 512, 1) print ("\n***conv5_3***") print ("\nlen(node_list):\t", len(node_list)) print ("\nlen(edge_list):\t", len(edge_list)) # conv_map(14, 14, 512, 7, 7, 7, 7, 512, 1) # print ("\n***conv5_4***") # print ("\nlen(node_list):\t", len(node_list)) # print ("\nlen(edge_list):\t", len(edge_list)) pool_map(14, 14, 512, 2, 2, 14, 14) print ("\n***pool5***") print ("\nlen(node_list):\t", len(node_list)) print ("\nlen(edge_list):\t", len(edge_list)) fc_map(7, 7, 512, 1, 4096, 1) print ("\n***fc1***") print ("\nlen(node_list):\t", len(node_list)) print ("\nlen(edge_list):\t", len(edge_list)) fc_map(1, 1, 4096, 1, 4096, 1) print ("\n***fc2***") print ("\nlen(node_list):\t", len(node_list)) print ("\nlen(edge_list):\t", len(edge_list)) fc_map(1, 1, 4096, 1, 1000, 1) print ("\n***fc3***") print ("\nlen(node_list):\t", len(node_list)) print ("\nlen(edge_list):\t", len(edge_list)) jsonout("4_unit_vgg16_graph.json", node_list, edge_list) with open("graph.json", "w") as f: for i in range(len(node_list)): f.write("id:") f.write(str(node_list[i][0])) f.write("\tcomDmd:") f.write(str(node_list[i][1])) f.write("\tdataDmd:") f.write(str(node_list[i][2])) f.write("\n") for i in range(len(edge_list)): f.write("src:") f.write(str(edge_list[i][0])) f.write("\tdst:") f.write(str(edge_list[i][1])) f.write("\tweight:") f.write(str(edge_list[i][2])) f.write("\n") generage_dag()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号