深度学习数据集 && 第一次了解虚拟环境
- MNIST:这是最大的手写数字(0~9)数据库。它由 60000 个示例的训练集和 10000 个示例的测试集组成。该数据集存放在 Yann LeCun 的主页(http://yann.lecun.com/exdb/mnist/)中。这个数据集已经包含在tensorflow.examples.tutorials.mnist 的 TensorFlow 库中。
- CIFAR10:这个数据集包含了 10 个类别的 60000 幅 32×32 彩色图像,每个类别有 6000 幅图像。其中训练集包含 50000 幅图像,测试数据集包含 10000 幅图像。数据集的 10 个类别分别是:飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船和卡车。该数据由多伦多大学计算机科学系维护(https://www.cs.toronto.edu/kriz/cifar.html)。
- WORDNET:这是一个英文的词汇数据库。它包含名词、动词、副词和形容词,被归为一组认知同义词(Synset),即代表相同概念的词语,例如 shut 和 close,car 和 automobile 被分组为无序集合。它包含 155287 个单词,组织在 117659 个同义词集合中,总共 206941 个单词对。该数据集由普林斯顿大学维护(https://wordnet.princeton.edu/)。
- ImageNET:这是一个根据 WORDNET 层次组织的图像数据集(目前只有名词)。每个有意义的概念(synset)由多个单词或单词短语来描述。每个子空间平均由 1000 幅图像表示。目前共有 21841 个同义词,共有 14197122 幅图像。自 2010 年以来,每年举办一次 ImageNet 大规模视觉识别挑战赛(ILSVRC),将图像分类到 1000 个对象类别中。这项工作是由美国普林斯顿大学、斯坦福大学、A9 和谷歌赞助(http://www.image-net.org/)。
- YouTube-8M:这是一个由数百万 YouTube 视频组成的大型标签视频数据集。它有大约 700 万个 YouTube 视频网址,分为 4716 个小类,并分为 24 个大类。它还提供预处理支持和框架功能。数据集由 Google Research(https://research.google.com/youtube8m/)维护。
TensorFlow当中读取数据的方法
首先学习MNIST数据集的使用。
这个过程真的是折磨啊,搞了一个下午。。。。还在搞
首先我想的是刚接触TensorFlow,那么就从可视化开始做起吧。。。先至少看看用于机器学习的图片是什么样子的。
首先看了这个博客https://www.cnblogs.com/xiaoyh/p/10813413.html
输入了里面的代码:
from tensorflow.examples.tutorials.mnist import input_data import scipy.misc import os from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets("MNIST_data/",one_hot=True) save_dir = 'MNIST_data/raw/' #图片的保存路径 if os.path.exists(save_dir) is False: os.mkdir(save_dir) for i in range(20): image_array = mnist.train.images[i,:] image_array = image_array.reshape(28,28) filename = save_dir+'mnist_train_%d.jpg' % i scipy.misc.toimage(image_array,cmin=0.0,cmax=1.0).save(filename)
结果显示scipy.misc导入错误。。。
那么就pip install scipy吧。。然而还是不行。
最终从一个百度知道页面https://zhidao.baidu.com/question/2206839918952665348.html,发现
可能是安装scipy前需要安装numpy+mkl这个库
因此去http://www.lfd.uci.edu/~gohlke/pythonlibs/#scipy下载
我下载了numpy-1.16.6+mkl-cp35-cp35m-win_amd64.whl这个版本的文件,下了好久
刚想使用命令 pip install D:\Python\numpy-1.16.6+mkl-cp35-cp35m-win_amd64.whl ,愉快地安装
结果显示

居然版本不支持!!!!
然后就搜索怎么查看可支持的版本。。。
那些
还有
还有
统统都是没有用的!!!!
最后还是好人多,找到了解决方法。
import wheel.pep425tags as w
print(w.get_supported())
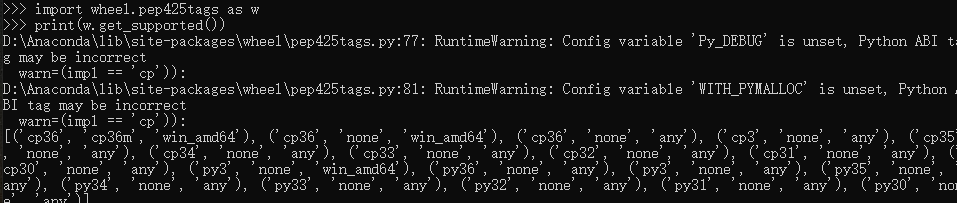
然后就看到了可支持的版本。。
。。。
终于解决这个问题了,根本就不需要下载这些狗币东西
根据这个百度知道https://zhidao.baidu.com/question/942690237717778852.html,这个问题和我的问题完美契合。

我的python就是如下所说
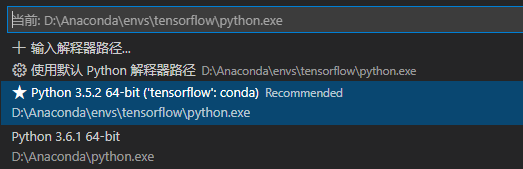
因为在Windows命令行里pip只能安装到外面,安装不到这里的环境当中来。
仔细看TensorFlow安装在anaconda的envs目录当中,envs就是virtual environment,是
python运行的虚拟环境。
现在的问题就是,如何在我的
这个虚拟环境下使用pip命令。
Q1,如何创建一个虚拟环境。
创建一个虚拟环境是很有必要的。因为python有很多的版本,可能不同项目需要在不同
版本的虚拟环境下运行。那么如果只有一个python版本,那么在运行的时候就会需要频繁地
对python进行卸载和安装,这显然是极其不方便的。
如上图,在vscode下安装TensorFlow的时候就自动为TensorFlow安装了一个虚拟环境。
当然虚拟环境的安装是需要一定的步骤的。这里就不展开了。以后需要用到的时候再来搞。
Q2,如何进入虚拟环境当中运行命令
显然,我们上面遇到的问题就是,电脑安装的python版本是3.6版本的,而TensorFlow的
python版本是3.5.2版本的。在外面的pip 显然是无法安装到TensorFlow当中去。
因此进入虚拟环境运行命令方法如下:
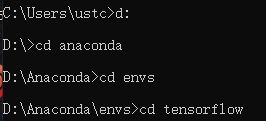
首先如上图,进入envs目录下的文件

第二步,如上图使用activate激活虚拟环境
激活之后就会变成这样
退出命令也很简单,deactivate即可。
我们在虚拟环境下显示一下python的版本:

可以看到成功进入到了这个版本的python
...但是显示这个版本的python好像不是因为进入了虚拟环境了,而是因为进入到了这个目录优先选择了这个目录下的python,
因为即使在这个目录下使用deactivate,还是显示的是3.5.2版本的python。
那么activate的作用是什么呢?
我去网上找了一下,
在https://cloud.tencent.com/developer/news/730978
和https://www.nuomiphp.com/eplan/369313.html这两个文件里。
实际在运行的时候,也没有发现activate命令修改了系统环境变量。。。
只能说先不管了。。。
我发现上面这些全都错了!!!
直接在
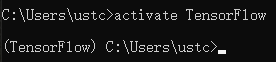
随便哪个目录下运行这个命令,这样才算是真正进入到了虚拟环境当中!
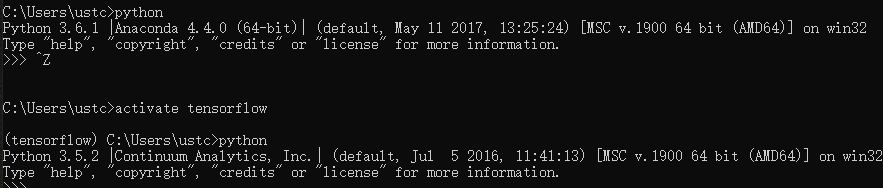
这个图就是对真正进入虚拟目录的最好说明,即使在c盘下面也能显示3.5.2版本的python。
然后成功安装scipy
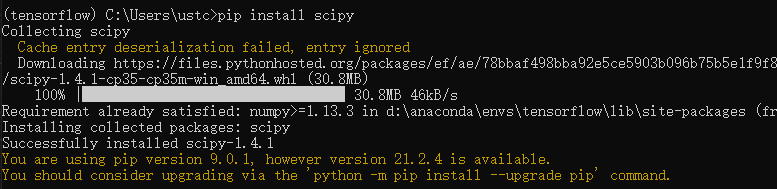
,程序也不报错了,
它换了一个地方报错
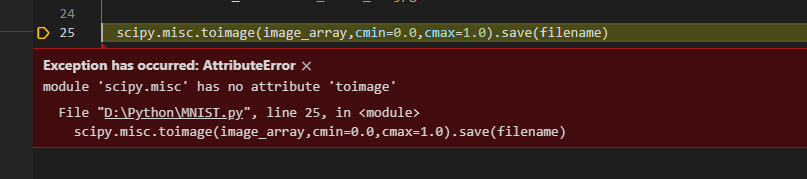
这个报错是因为scipy版本过高,已经不支持这个函数了。
那么如何解决这个问题呢。
只能用其他办法了。
在下一节开始讲吧。
QQQQQQQQQQQQQQQQQQQ
再来解决如何使用activate,以及如何更加简洁(如在vscode当中)地进入虚拟环境。以及
activate和conda activate有什么区别。。。Q2
疑惑来自于以下图片。。。

有用的信息:
python虚拟环境,whell支持版本查看方法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号