论文总结
首先就是机器包含着许多并行运行的处理器(DEVICE),以及通信链路(LINK)。
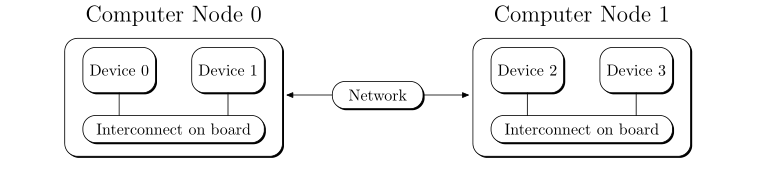
链路分为两种,一种是处理器间的链路,一种是计算机节点之间的链路。
每个处理器上都有自己的内存(RAM,在程序上标注了大小)。可以有任务Vi被调度到处理器Pj上面。显然任务被
调度到处理器Pj上面的话,那么就需要用到处理器Pj的内存管理(需要注意到每个处理器上面都有自己的内存)。然后,
处理器Pj上面就会有一个内存块被分配给这个任务vi。由于数据流模型是任务间是存在先后顺序的。如果处理器Pj上面没有
足够大的内存的话,那么这个调度还不能完成呢。
Q1:论文原文说的是Vi与所有的后继节点完成通信之后(即一个表示 当前内存块仍被多少后继节点使用的计数器
清零之后,我猜是表示当前的数据已经完全传递给了需要当前节点数据的后续节点),那么内存块就被释放了。我猜任务
节点就是数据流的DAG任务图,那个图和这里的处理器节点图是不一样的两个图。
之后的就是师兄提到的这个模拟器高度理想化的问题。没有考虑到内存一致性和cache机制,这是实际当中无法想象的。
在这里的数据重用只体现在:两个互相依赖的任务被分配到同一个设备上,两者之间不会发生数据传输,而是后继任务直接
使用前驱任务的输出数据。(感觉印证了上面的猜测Q1)
这个模拟器上的通信时间取决于带宽这个数据。
下面就了解到了,确实任务DAG图是另外的一个图形。在这个数据结构当中,有三级调度队列来完成这个模拟过程。正如
Q1当中所说,一个任务完成之后就会把信息传递给它的后续任务。所有前置条件完成之后任务也只是会从等待队列当中来到
就绪队列当中。
但是,任务从就绪队列来到执行队列,不是FCFS,而是要考虑不同任务在不同处理器上面的执行效率。。。。
Q2:那么考虑这样的一个情况,怎么进行调度?
在3.3.4节当中说了,任务调度分为选取一个就绪队列当中的任务,以及处理器调度这两步。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号