
《Linux内核原理与分析》task_struct数据结构
task_struck数据结构
在Linux内核中,通过task_struct这个结构体对进程进行管理,我们可以叫他PCB或者进程描述符。这个结构体定义在include/linux/sched.h中。
鉴于这个结构体的复杂,本文分成多个部分来分析它。
进程状态
进程状态由结构体中的如下代码定义:
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
其中state的可取的值如下:
/*
* Task state bitmask. NOTE! These bits are also
* encoded in fs/proc/array.c: get_task_state().
*
* We have two separate sets of flags: task->state
* is about runnability, while task->exit_state are
* about the task exiting. Confusing, but this way
* modifying one set can't modify the other one by
* mistake.
*/
#define TASK_RUNNING 0
#define TASK_INTERRUPTIBLE 1
#define TASK_UNINTERRUPTIBLE 2
#define __TASK_STOPPED 4
#define __TASK_TRACED 8
/* in tsk->exit_state */
#define EXIT_DEAD 16
#define EXIT_ZOMBIE 32
#define EXIT_TRACE (EXIT_ZOMBIE | EXIT_DEAD)
/* in tsk->state again */
#define TASK_DEAD 64
#define TASK_WAKEKILL 128
#define TASK_WAKING 256
#define TASK_PARKED 512
#define TASK_STATE_MAX 1024
················
#define TASK_KILLABLE (TASK_WAKEKILL | TASK_UNINTERRUPTIBLE)
#define TASK_STOPPED (TASK_WAKEKILL | __TASK_STOPPED)
#define TASK_TRACED (TASK_WAKEKILL | __TASK_TRACED)
其中,有五个互斥状态:
- TASK_RUNNING。表示进程要么正在执行,要么正要准备执行(已经就绪),正在等待cpu时间片的调度。
- TASK_INTERRUPTIBLE。进程因为等待一些条件而被挂起(阻塞)而所处的状态。这些条件主要包括:硬中断、资源、一些信号……,一旦等待的条件成立,进程就会从该状态(阻塞)迅速转化成为就绪状态TASK_RUNNING。
- TASK_UNINTERRUPTIBLE。意义与TASK_INTERRUPTIBLE类似,除了不能通过接受一个信号来唤醒以外,对于处于TASK_UNINTERRUPIBLE状态的进程,哪怕我们传递一个信号或者有一个外部中断都不能唤醒他们。只有它所等待的资源可用的时候,他才会被唤醒。这个标志很少用,但是并不代表没有任何用处,其实他的作用非常大,特别是对于驱动刺探相关的硬件过程很重要,这个刺探过程不能被一些其他的东西给中断,否则就会让进程进入不可预测的状态。
- TASK_STOPPED。进程被停止执行,当进程接收到SIGSTOP、SIGTTIN、SIGTSTP或者SIGTTOU信号之后就会进入该状态。
- TASK_TRACED。表示进程被debugger等进程监视,进程执行被调试程序所停止,当一个进程被另外的进程所监视,每一个信号都会让进程进入该状态。
两个终止状态:
- EXIT_ZOMBIE。进程的执行被终止,但是其父进程还没有使用wait()等系统调用来获知它的终止信息,此时进程成为僵尸进程。
- EXIT_DEAD。进程的最终状态。
以及新增的睡眠状态:
- TASK_KILLABLE。当进程处于这种可以终止的新睡眠状态中,它的运行原理类似于 TASK_UNINTERRUPTIBLE,只不过可以响应致命信号。
对于TASK_DEAD到TASK_STATE_MAX这五个定义,除了知道TASK_WAKEKILL是和进程睡眠有关以外,别的都没有找到具体含义。希望以后用得上的时候能知道。
进程标识符
sched.h中的以下代码定义进程标识符:
pid_t pid;
pid_t tgid;
Unix系统通过pid来标识进程,linux把不同的pid与系统中每个进程或轻量级线程关联,而unix程序员希望同一组线程具有共同的pid,遵照这个标准linux引入线程组的概念。一个线程组所有线程与领头线程具有相同的pid,存入tgid字段,getpid()返回当前进程的tgid值而不是pid的值。
在Linux系统中,一个线程组中的所有线程使用和该线程组的领头线程(该组中的第一个轻量级进程)相同的PID,并被存放在tgid成员中。只有线程组的领头线程的pid成员才会被设置为与tgid相同的值。注意,getpid()系统调用返回的是当前进程的tgid值而不是pid值。
注意系统中pid的范围是有限的,这也是为什么尽管僵尸进程几乎不占用资源,我们依然要将其回收。因为僵尸进程占用了pid空间,僵尸进程过多会导致没有pid可以分配给新进程。
进程内核栈
sched.h中的以下代码定义进程内核栈:
void *stack;
对于每个进程,linux都把两个不同的数据结构紧凑的存放在一个单独为进程分配的内存区域中,一个是内核态的进程堆栈,另一个是线程描述符thread_info。这两个数据结构被定义在一个联合体中,由alloc_thread_info_node分配内存空间。
进程标记
进程标记反映进程状态的信息,但不是运行状态,用于内核识别进程当前的状态,以备下一步操作。
unsigned int flags; /* per process flags, defined below */
flags可能的取值如下所示:
/*
* Per process flags
*/
#define PF_EXITING 0x00000004 /* getting shut down */
#define PF_EXITPIDONE 0x00000008 /* pi exit done on shut down */
#define PF_VCPU 0x00000010 /* I'm a virtual CPU */
#define PF_WQ_WORKER 0x00000020 /* I'm a workqueue worker */
#define PF_FORKNOEXEC 0x00000040 /* forked but didn't exec */
#define PF_MCE_PROCESS 0x00000080 /* process policy on mce errors */
#define PF_SUPERPRIV 0x00000100 /* used super-user privileges */
#define PF_DUMPCORE 0x00000200 /* dumped core */
#define PF_SIGNALED 0x00000400 /* killed by a signal */
#define PF_MEMALLOC 0x00000800 /* Allocating memory */
#define PF_NPROC_EXCEEDED 0x00001000 /* set_user noticed that RLIMIT_NPROC was exceeded */
#define PF_USED_MATH 0x00002000 /* if unset the fpu must be initialized before use */
#define PF_USED_ASYNC 0x00004000 /* used async_schedule*(), used by module init */
#define PF_NOFREEZE 0x00008000 /* this thread should not be frozen */
#define PF_FROZEN 0x00010000 /* frozen for system suspend */
#define PF_FSTRANS 0x00020000 /* inside a filesystem transaction */
#define PF_KSWAPD 0x00040000 /* I am kswapd */
#define PF_MEMALLOC_NOIO 0x00080000 /* Allocating memory without IO involved */
#define PF_LESS_THROTTLE 0x00100000 /* Throttle me less: I clean memory */
#define PF_KTHREAD 0x00200000 /* I am a kernel thread */
#define PF_RANDOMIZE 0x00400000 /* randomize virtual address space */
#define PF_SWAPWRITE 0x00800000 /* Allowed to write to swap */
#define PF_NO_SETAFFINITY 0x04000000 /* Userland is not allowed to meddle with cpus_allowed */
#define PF_MCE_EARLY 0x08000000 /* Early kill for mce process policy */
#define PF_MUTEX_TESTER 0x20000000 /* Thread belongs to the rt mutex tester */
#define PF_FREEZER_SKIP 0x40000000 /* Freezer should not count it as freezable */
#define PF_SUSPEND_TASK 0x80000000 /* this thread called freeze_processes and should not be frozen */
进程的父子、兄弟关系
进程的父子兄弟关系存储在以下代码:
/*
* pointers to (original) parent process, youngest child, younger sibling,
* older sibling, respectively. (p->father can be replaced with
* p->real_parent->pid)
*/
struct task_struct __rcu *real_parent; /* real parent process */
struct task_struct __rcu *parent; /* recipient of SIGCHLD, wait4() reports */
/*
* children/sibling forms the list of my natural children
*/
struct list_head children; /* list of my children */
struct list_head sibling; /* linkage in my parent's children list */
struct task_struct *group_leader; /* threadgroup leader */
这些字段具体描述如下:
- real_parent。指向其父进程,如果创建它的父进程不再存在,则指向PID为1的init进程。
- parent。指向其父进程,当它终止时,必须向它的父进程发送信号。它的值通常与real_parent相同。
- children。表示链表的头部,链表中的所有元素都是它的子进程。
- sibling。用于把当前进程插入到兄弟链表中。
- group_leader。指向其所在进程组的领头进程。
sys_clone工作流程
我们知道sys_fork,sys_vfork,和sys_clone最终都是调用的do_fork函数实现,共同目的都是创建一个新进程。(在较新的内核中都是调用_do_fork实现)
Linux内核中没有独立的“线程”结构,Linux的线程就是轻量级进程,换言之基本控制结构和Linux的进程是一样的(都是通过struct task_struct管理)。
fork是最简单的调用,不需要任何参数,仅仅是在创建一个子进程并为其创建一个独立于父进程的空间。fork使用COW(写时拷贝)机制,并且COW了父进程的栈空间。
vfork是一个过时的应用,vfork也是创建一个子进程,但是子进程共享父进程的空间。在vfork创建子进程之后,父进程阻塞,直到子进程执行了exec()或者exit()。vfork最初是因为fork没有实现COW机制,而很多情况下fork之后会紧接着exec,而exec的执行相当于之前fork复制的空间全部变成了无用功,所以设计了vfork。而现在fork使用了COW机制,唯一的代价仅仅是复制父进程页表的代价,所以vfork不应该出现在新的代码之中。在Linux的manpage中队vfork有这样一段话:It is rather unfortunate that Linux revived this specter from the past. The BSD man page states: "This system call will be eliminated when proper system sharing mechanisms are implemented. Users should not depend on the memory sharing semantics of vfork() as it will, in that case, be made synonymous to fork(2)."
clone是Linux为创建线程设计的(虽然也可以用clone创建进程)。所以可以说clone是fork的升级版本,不仅可以创建进程或者线程,还可以指定创建新的命名空间(namespace)、有选择的继承父进程的内存、甚至可以将创建出来的进程变成父进程的兄弟进程等等。clone和fork的调用方式也很不相同,clone调用需要传入一个函数,该函数在子进程中执行。此外,clone和fork最大不同在于clone不再复制父进程的栈空间,而是自己创建一个新的。
do_fork的参数如下:
- clone_flags。与clone()参数flags相同, 用来控制进程复制过的一些属性信息, 描述你需要从父进程继承那些资源。该标志位的4个字节分为两部分。最低的一个字节为子进程结束时发送给父进程的信号代码,通常为SIGCHLD;剩余的三个字节则是各种clone标志的组合(本文所涉及的标志含义详见下表),也就是若干个标志之间的或运算。通过clone标志可以有选择的对父进程的资源进行复制。
- stack_start。与clone()参数stack_start相同, 子进程用户态堆栈的地址。
- regs。是一个指向了寄存器集合的指针, 其中以原始形式, 保存了调用的参数, 该参数使用的数据类型是特定体系结构的struct pt_regs,其中按照系统调用执行时寄存器在内核栈上的存储顺序, 保存了所有的寄存器, 即指向内核态堆栈通用寄存器值的指针,通用寄存器的值是在从用户态切换到内核态时被保存到内核态堆栈中的(指向pt_regs结构体的指针。当系统发生系统调用,即用户进程从用户态切换到内核态时,该结构体保存通用寄存器中的值,并被存放于内核态的堆栈中)。
- stack_size。用户状态下栈的大小, 该参数通常是不必要的, 总被设置为0。
- parent_tidptr。与clone的ptid参数相同, 父进程在用户态下pid的地址,该参数在CLONE_PARENT_SETTID标志被设定时有意义。
- child_tidptr。与clone的ctid参数相同, 子进程在用户态下pid的地址,该参数在CLONE_CHILD_SETTID标志被设定时有意义
do_fork的简化执行流程如下:
- copy_process()。此函数是fork的主体部分,它将父进程的运行环境复制到子进程。
- wake_up_new_task()。计算此进程的优先级和其他调度参数,将新的进程加入到进程调度队列并设此进程为可被调度的,以后这个进程可以被进程调度模块调度执行。
简单的说,copy_process()就是将父进程的运行环境复制到子进程并对某些子进程特定的环境做相应的调整。copy_process的简化流程如下:
1.dup_task_struct()。分配一个新的进程控制块,包括新进程在kernel中的堆栈。新的进程控制块会复制父进程的进程控制块,但是因为每个进程都有一个kernel堆栈,新进程的堆栈将被设置成新分配的堆栈。
2.初始化一些新进程的统计信息,如此进程的运行时间
3.copy_semundo()复制父进程的semaphore undo_list到子进程。
4.copy_files()、copy_fs()。复制父进程文件系统相关的环境到子进程
5.copy_sighand()、copy_signal()。复制父进程信号处理相关的环境到子进程。
6.copy_mm()。复制父进程内存管理相关的环境到子进程,包括页表、地址空间和代码数据。
7.copy_thread()/copy_thread_tls。设置子进程的执行环境,如子进程运行时各CPU寄存器的值、子进程的kernel栈的起始地址。
8.sched_fork()。设置子进程调度相关的参数,即子进程的运行CPU、初始时间片长度和静态优先级等。
9.将子进程加入到全局的进程队列中
10.设置子进程的进程组ID和对话期ID等。
cgdb调试menuOS内核系统调用fork
分别在sys_clone,do_fork,copy_process,copy_thread,ret_from_fork处设置断点,调试结果如下:
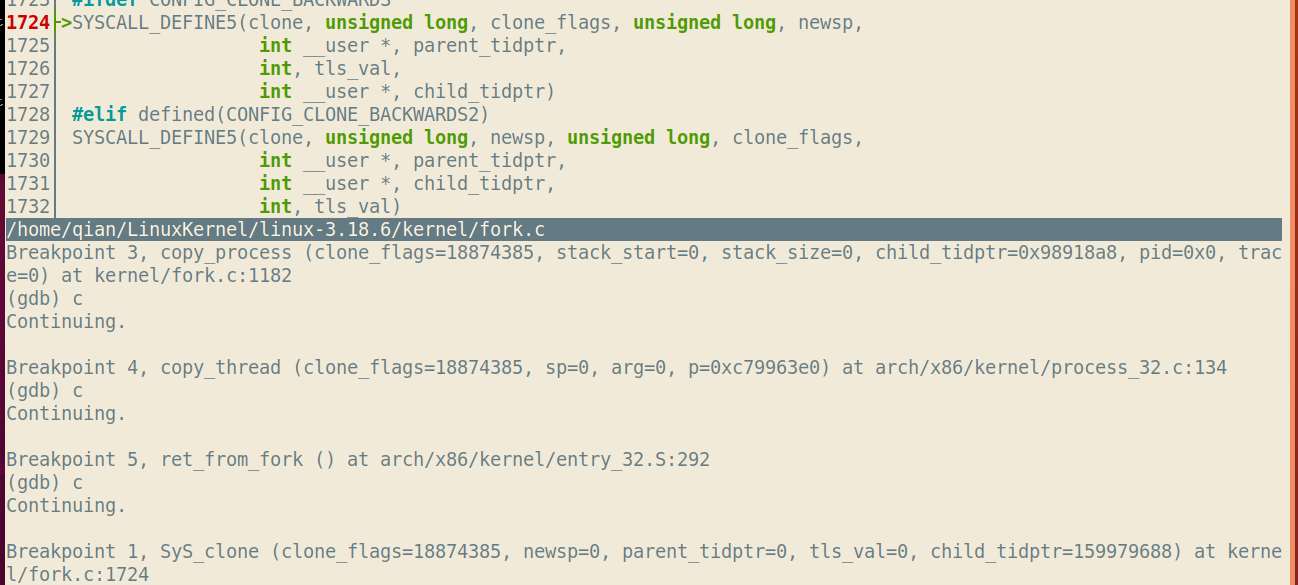

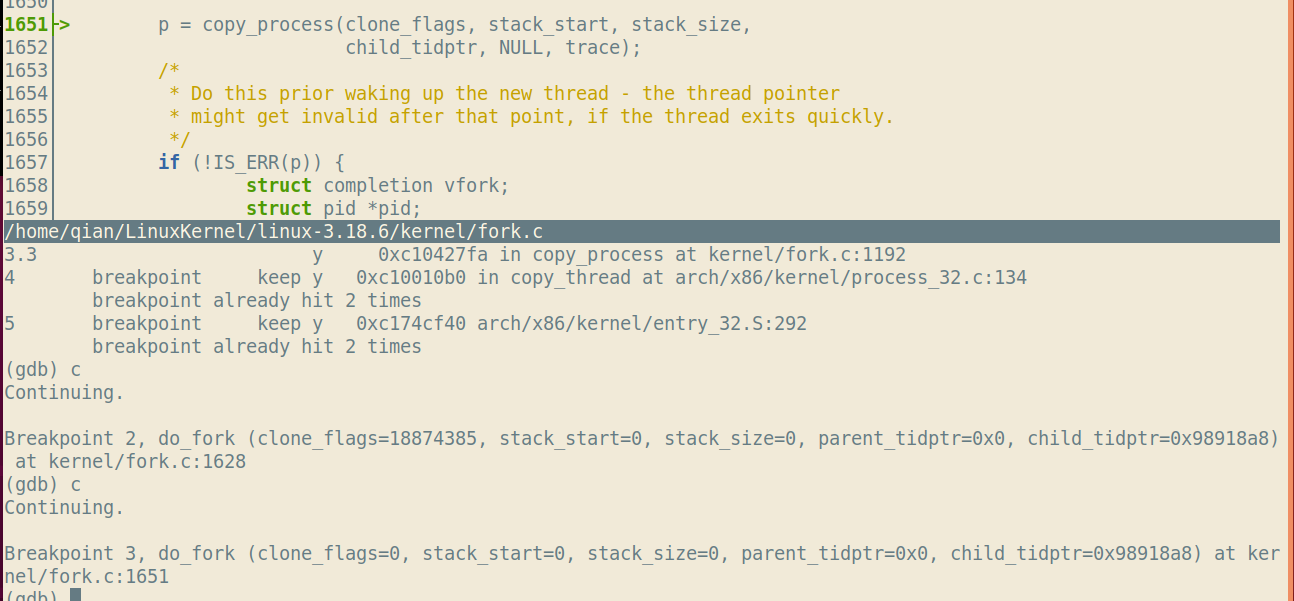
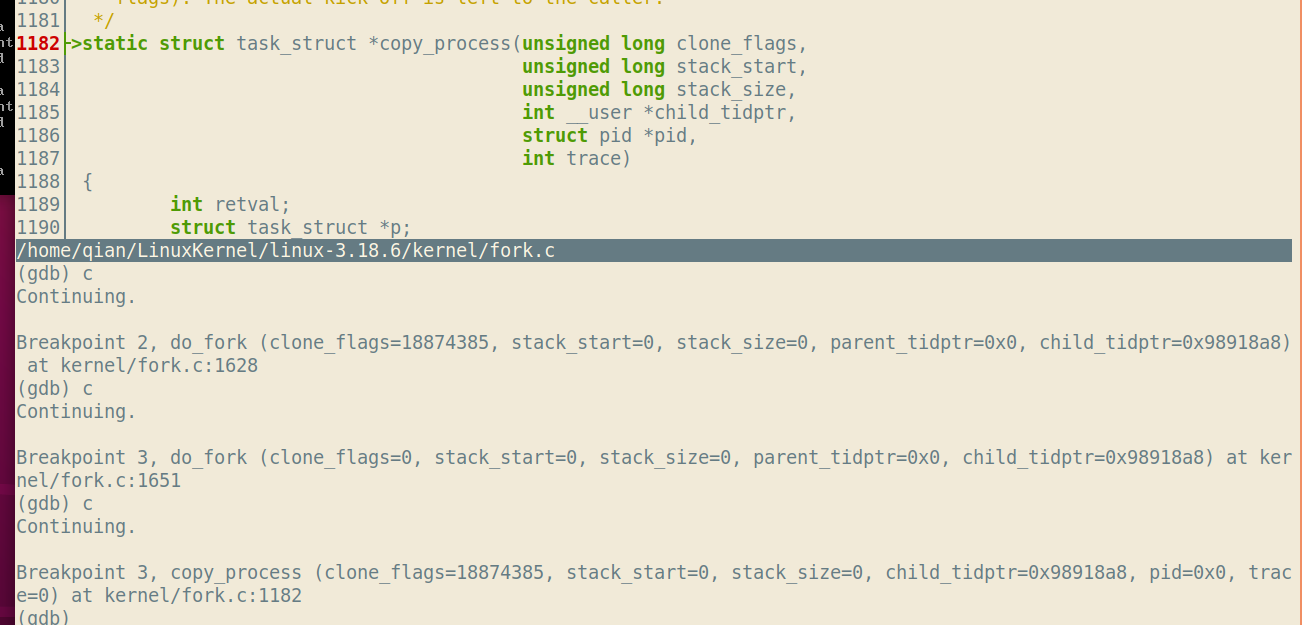


有一点小疑问,copy_process处停留了两次,一次是在do_fork函数内,调用copy_process之前,第二次则是在copy_process的入口,也就是该函数第一行停下。为什么需要停留两次呢?通过s命令查看每一步的代码发现会对clone_flags做一些判断,但还是不懂为什么需要停两次。
linux如何创建一个新进程
linux内核在初始化的时候会创建两个内核线程(轻量级进程),一个是kernel_init,他会启动用户态进程init,init是所有用户态进程的祖先;另一个是kthreadd,它是所有内核线程的祖先。这两个进程都是通过复制0号进程-idle创建的。
其后创建进程的方法和此类似,均是根据情况复制父进程的进程描述符,子进程从fork处开始执行。注意,即便fork前的代码子进程没有执行,但由于其复制了父进程的资源,因此之前的变量值同父进程保持一致。
当子进程被创立后,其是否运行服从操作系统的调度,不再受父进程影响。
参考链接
https://www.cnblogs.com/noble/p/4144247.html
https://blog.csdn.net/gatieme/article/details/51383272
https://blog.csdn.net/gatieme/article/details/51569932

