python中的迭代器和生成器
在我们学习迭代器和生成器之前的时候,我们要先搞清楚几个概念:
「迭代协议:」 有 __next__方法会前进道下一个结果,而且在一系列结果的末尾时,会引发StopIteration异常的对象.「可迭代对象:」 实现了 __iter__方法的对象「迭代器:」 实现了 __iter__和__next__方法的对象「生成器:」 通过生成器表达式或者yeild关键字实现的函数.
这里不太好理解,我们借用一个图
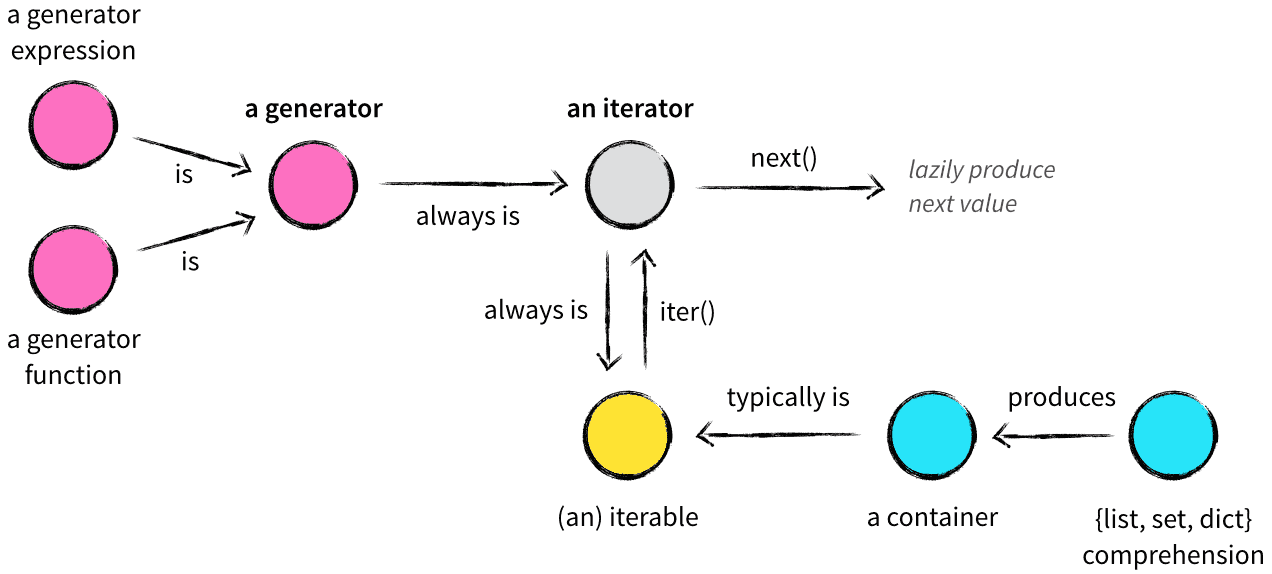
可迭代对象
需要注意的是可迭代对象不一定是迭代器.比如列表类型和字符串类型都是可迭代对象,但是他们都不是迭代器.
In [1]: L1 = [1,2,3,4]
In [2]: type(L1)
Out[2]: list
In [3]: L1_iter=L1.__iter__()
In [4]: type(L1_iter)
Out[4]: list_iterator
但是对于容器以及文件这样的可迭代对象来说的话,他们都实现了一个__iter__方法. 这个方法可以返回一个迭代器.

迭代器中的__next__方法,next()方法和for语句
首先迭代器中都实现了__next__()方法. 我们可以直接调用迭代器的__next__方法来得到下一个值. 比如:
In [10]: L1_iter.__next__()
Out[10]: 1
In [11]: next(L1_iter)
Out[11]: 2
注意这里,next()方法也是去调用迭代器内置的__next__方法. 所以这两种操作是一样的.
但是在日常使用的时候,我们不会直接去调用next()方法来使用生成器.
更多的操作是通过for语句来使用一个生成器.
就下面这两段代码来看,其作用上是等效的.
L1 = [1, 2, 3, 4]
for x in L1:
print(x, end=" ")
print("\nthe same result of those two statements!")
L1_iter = L1.__iter__()
while True:
try:
x = L1_iter.__next__()
print(x, end=" ")
except StopIteration:
break
但是实际上,使用for语句在运行速度可能会更快一点. 因为迭代器在Python中是通过C语言实现的. 而while的方式则是以Python虚拟机运行Python字节码的方式来执行的.
毕竟...你大爷永远是你大爷. C语言永远是你大爷...
列表解析式
列表解析式或者又叫列表生成式,这个东西就比较简单了. 举个简单的例子,比如我们要定义一个1-9的列表. 我们可以写L=[1,2,3,4,5,6,78,9] 同样我们也可以写L=[x for x in range(10)]
再举一个简单的例子,我们现在已经有一个列表L2=[1,2,3,4,5] 我们要得到每个数的平方的列表. 那么我们有两种做法:
L2 = [1, 2, 3, 4, 5]
# statement1
for i in range(len(L2)):
L2[i] = L2[i]*L2[i]
#statement2
L3 = [x*x for x in L2]
显然从代码简洁渡上来说 第二种写法更胜一筹. 而且它的运算速度相对来说会更快一点(往往速度会快一倍.P.S.书上的原话,我没有验证...). 因为列表解析式式通过生成器来构造的,他们的迭代是python解释器内部以C语言的速度来运行的. 特别是对于一些较大的数据集合,列表解析式的性能优点更加突出.
列表解析式还有一些高端的玩法. 比如可以与if语句配合使用:
L4 = [1, 2, 3, 4, 5, 6, 7, 8, 9]
L5 = [x for x in L4 if x % 2 == 0]
还可以使用for语句嵌套;
L6=[1,2,3,4,5]
L7=['a','b','c','d','e']
L8=[str(x)+y for x in L6 for y in L7]
或者可以写的更长
L9=[(x,y) for x in range(5) if x % 2 ==0 for y in range(5) if y %2 ==1]
一个更复杂的例子
M = [
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
]
print(M[1][1])
print(M[1])
print([row[1] for row in M])
print([M[row][1] for row in (0,1,2)])
print([M[i][i] for i in range(len(M))])
同样的,我们可以通过for语句来实现上述的功能. 但是列表解析式想对而言会更加简洁.
另外map函数比等效的for循环要更快,而列表解析式往往会比map调用还要快一点.
python3中新的可迭代对象
python3相比如python2.x来说,它更强调迭代. 除了文件,字典这样的内置类型相关的迭代外. 字典方法keys,values都在python3中返回可迭代对象. 就像map,range,zip方法一样. 它返回的并不是一个列表. 虽然从速度和内存占用上更有优势,但是有时候我们不得不使用list()方法使其一次性计算所有的结果.
range迭代器
In [12]: R=range(10)
In [13]: R
Out[13]: range(0, 10)
In [14]: I = iter(R)
In [15]: next(I)
Out[15]: 0
In [16]: R[5]
Out[16]: 5
In [17]: len(R)
Out[17]: 10
In [18]: next(I)
Out[18]: 1
range的话,仅支持迭代,len()和索引. 不支持其他的序列操作. 所以如果需要更多的列表工具的话,使用list()...
map,zip和filter迭代器
和range类似, map,zip和filter在python3.0中也转变成了迭代器以节约内存空间. 但是它们和range又不一样.(确切来说是range和它们不一样) 它们不能在它们的结果上拥有在那些结果中保持不同位置的多个迭代器.(第四版书上原话,看看这叫人话吗...)
翻译一下就是,map,zip和filter返回的都是正经迭代器,不支持len()和索引. 以map为例做个对比.
In [20]: map_abs = map(abs,[1,-3,4])
In [21]: M1 = iter(map_abs)
In [22]: M2=iter(map_abs)
In [23]: next(M1)
Out[23]: 1
In [24]: next(M2)
Out[24]: 3
而range不是正经的迭代器. 它支持在其结果上创建多个活跃的迭代器.
In [25]: R=range(10)
In [26]: r1 = iter(R)
In [27]: r2=iter(R)
In [28]: next(r1)
Out[28]: 0
In [29]: next(r2)
Out[29]: 0
字典中的迭代器
同样的,python3中字典的keys,values和items方法返回的都是可迭代对象.而非列表.
In [30]: D = dict(a=1,b=2,c=3)
In [31]: D
Out[31]: {'a': 1, 'b': 2, 'c': 3}
In [32]: K = D.keys()
In [33]: K
Out[33]: dict_keys(['a', 'b', 'c'])
In [34]: next(K)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-34-02c2ef8731e9> in <module>
----> 1 next(K)
TypeError: 'dict_keys' object is not an iterator
In [35]: i = iter(K)
In [36]: next(i)
Out[36]: 'a'
In [37]: for k in D.keys(): print(k,end=' ')
同样的,我们可以利用list()函数来显式的把他们变成列表. 另外,python3中的字典仍然有自己的迭代器. 它返回连续的见. 因此在遍历的时候,无需显式的调用keys().
In [38]: for key in D: print(key,end=' ')
a b c
生成器
生成器可以说是迭代器的一个子集. 有两种创建方法:
生成器函数: 编写常规的以def为关键字的函数,使用yield关键字返回结果. 在每个结果之间挂起和继续他们的状态. 生成器表达式: 类似前面所说的列表解析式.
生成器函数关键字 yeild
「状态挂起」
和返回一个值并且退出的常规函数不同,生成器函数自动在生成值得时刻挂起并继续函数的执行. 它在挂起时会保存包括整个本地作用域在内的所有状态. 在恢复执行时,本地变量信息依旧可用.
生成器函数使用yeild语句来挂起函数并想调用者发送回一个值.之后挂起自己. 在恢复执行的时候,生成器函数会从它离开的地方继续执行.
「生成器函数的应用」
def gensquares(num):
for i in range(num):
yield i**2
for i in gensquares(5):
print(i)
同样的,生成器其实也是实现了迭代器协议. 提供了内置的__next__方法.
上面这个例子如果我们要改写为普通函数的话,可以写成如下的样子.
def buildsquares(num):
res = []
for i in range(num):
res.append(i**2)
return res
for i in buildsquares(5):
print(i)
看上去实现的功能都是一样的. 但是区别在于 生成器的方式产生的是一个惰性计算序列. 在调用时才进行计算得出下一个值. 而第二种常规函数的方式,是先计算得出所有结果返回一个列表. 从内存占用的角度来说,生成器函数的方式更优一点.
生成器表达式
与列表解析式差不多. 生成器表达式用来构造一些逻辑相对简单的生成器. 比如
g = (x**2 for x in range(4))
在使用时可以通过next()函数或者for循环进行调用.
实战:改写map和zip函数
改写map函数
「一年级版本:」
def mymap(func,*seqs):
res=[]
print(list(zip(*seqs)))
for args in zip(*seqs):
res.append(func(*args))
return res
「二年级版本:」
def mymap(func,*seqs):
return [func(*args) for args in zip(*seqs)]
「三年级版本:」
def mymap(func,*seqs):
res=[]
for args in zip(*seqs):
yield func(*args)
print(list(mymap(abs,[-1,-2,1,2,3])))
print(list(mymap(pow,[1,2,3],[2,3,4,5])))
「小学毕业班版本」
def mymap(func,*seqs):
return (func(*args) for args in zip(*seqs))
改写zip函数
「一年级版本」
def myzip(*seqs):
seqs = [list(S) for S in seqs]
print(seqs)
res = []
while all(seqs):
res.append(tuple(S.pop(0) for S in seqs))
return res
print(myzip('abc', 'xyz'))
❝知识点: all()函数和any()函数. all()函数,如果可迭代对象中的所有元素都为True或者可迭代对象为None. 则返回True. any()函数,可迭代对象中的任一元素为True则返回True.,如果迭代器为空,则返回False.
❞
「二年级版本」
def myzip(*seqs):
seqs = [list(S) for S in seqs]
while all(seqs):
yield tuple(S.pop(0) for S in seqs)
print(list(myzip('abc', 'xyz')))
❝参考资料:
❞
更多精彩内容,敬请关注公众号"吾码2016"


 浙公网安备 33010602011771号
浙公网安备 33010602011771号