

下面将依次介绍:
1. 线程状态、Java线程状态和线程池状态
2. start方法源码
3. 什么是线程池?
4. 线程池的工作原理和使用线程池的好处
5. ThreadPoolExecutor中的Worker,线程池底层实现原理
6. 线程池工具类如Executors等
7. 如何停止一个线程(含代码),源码查看Thread.interrupted()和Thread.currentThread().isInterrupted()区别
8. 如何合理的配置 Java 线程池?如 CPU 密集型的任务,基本线程池 应该配置多大?IO 密集型的任务,基本线程池应该配置多大?用有界队列好还是无界队列好?任务非常多的时候,使用什么阻塞队列能获取 最好的吞吐量?
9. AQS的子类在各个同步工具类(如ReentrantLock)中的使用情况
10. 多个线程顺序打印不同字符ABCDEFG(利用线程池实现多线程)
线程状态
线程的生命周期:
首先new一个线程对象,进入New状态;
调用线程的start方法线程进入Runnable就绪状态,等待CPU调度;
然后该线程任务被CPU执行时,处于Running状态,如果放弃了CPU资源(如调用了yield方法),会进入到Runnable状态,等待CPU调度;
执行过程中有block IO(如DataInputStream.readUTF()方法)、获取重量级锁(自旋一定时间,未获取到锁进入Blocked状态)、wait、join(join底层调用的Object的wait方法)、condition.await等操作,进入Blocked状态;
与之对应的如果线程处于Blocked状态,block IO 完成、获取到锁(也不会立即被CPU执行),sleep时间完、被notify或notifyALL或condition.singal或condition.singalAll唤醒,由Blocked转为Runnable状态,等待CPU执行;
Terminated结束状态,线程run方法执行完毕、或者异常退出(比如其他线程调用了该线程的 interrupt方法(该方法仅仅只是设置线程标志位),如果该线程正在wait/join会抛出InterruptedException异常,线程终止,见本文末尾如何终止一个线程)。
注:Condition可以由ReentrantLock对象的newCondition生成(底层就是内部类Sync继承了AQS,sync对象生成的Condition对象),一个ReentrantLock对象多次调用newCondition方法可以生成多个不同的Condition对象。
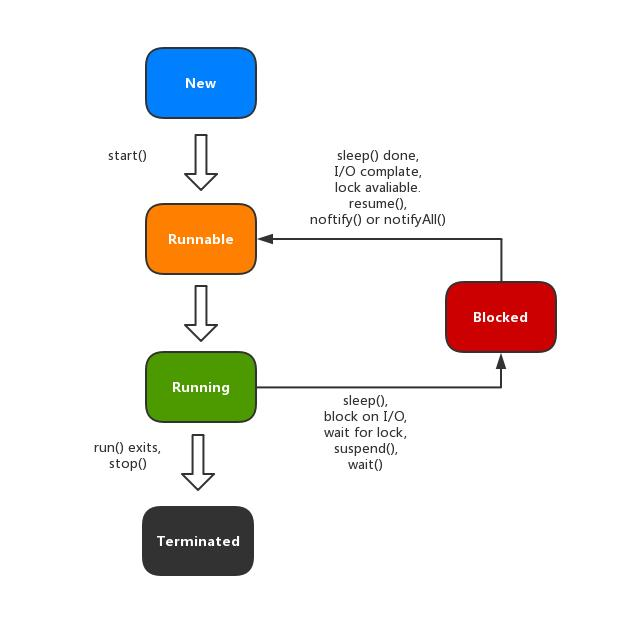
Java中的线程状态和上面有些区别
下面是Thread中枚举State源码:

public enum State { /** * Thread state for a thread which has not yet started. */ NEW, /** * Thread state for a runnable thread. A thread in the runnable * state is executing in the Java virtual machine but it may * be waiting for other resources from the operating system * such as processor. */ RUNNABLE, /**未获取到锁 * Thread state for a thread blocked waiting for a monitor lock. * A thread in the blocked state is waiting for a monitor lock * to enter a synchronized block/method or * reenter a synchronized block/method after calling * {@link Object#wait() Object.wait}. */ BLOCKED, /**调用wait方法不写timeout时间 * Thread state for a waiting thread. * A thread is in the waiting state due to calling one of the * following methods: * <ul> * <li>{@link Object#wait() Object.wait} with no timeout</li> * <li>{@link #join() Thread.join} with no timeout</li> * <li>{@link LockSupport#park() LockSupport.park}</li> * </ul> * * <p>A thread in the waiting state is waiting for another thread to * perform a particular action. * * For example, a thread that has called <tt>Object.wait()</tt> * on an object is waiting for another thread to call * <tt>Object.notify()</tt> or <tt>Object.notifyAll()</tt> on * that object. A thread that has called <tt>Thread.join()</tt> * is waiting for a specified thread to terminate. */ WAITING, /**调用sleep和wait方法写了timeout时间 * Thread state for a waiting thread with a specified waiting time. * A thread is in the timed waiting state due to calling one of * the following methods with a specified positive waiting time: * <ul> * <li>{@link #sleep Thread.sleep}</li> * <li>{@link Object#wait(long) Object.wait} with timeout</li> * <li>{@link #join(long) Thread.join} with timeout</li> * <li>{@link LockSupport#parkNanos LockSupport.parkNanos}</li> * <li>{@link LockSupport#parkUntil LockSupport.parkUntil}</li> * </ul> */ TIMED_WAITING, /** * Thread state for a terminated thread. * The thread has completed execution. */ TERMINATED; }
注意:对 Java 线程状态而言,不存在所谓的running 状态,它的 runnable 状态包含了 running 状态。
JAVA8线程池THREADPOOLEXECUTOR底层原理及其源码解析
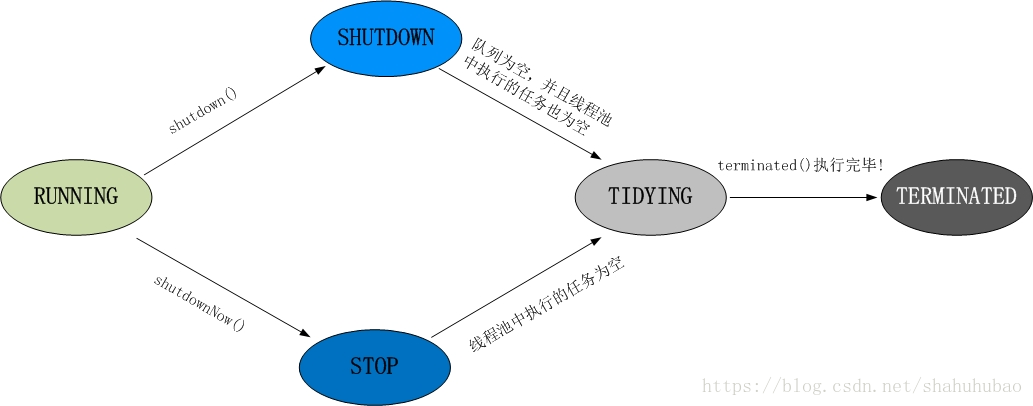
线程池的状态
ThreadPoolExecutor源码中的五种状态
// runState is stored in the high-order bits
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
private static final int COUNT_BITS = Integer.SIZE - 3;
下面也会说到一个int整数4字节32位中,高三位表示线程状态,所以这里COUNT_BITS=32-3=29,然后右移29为表示线程状态;
下图转载于:https://blog.csdn.net/shahuhubao/article/details/80311992
start 方法源码解析,何时调用的 run() 方法?
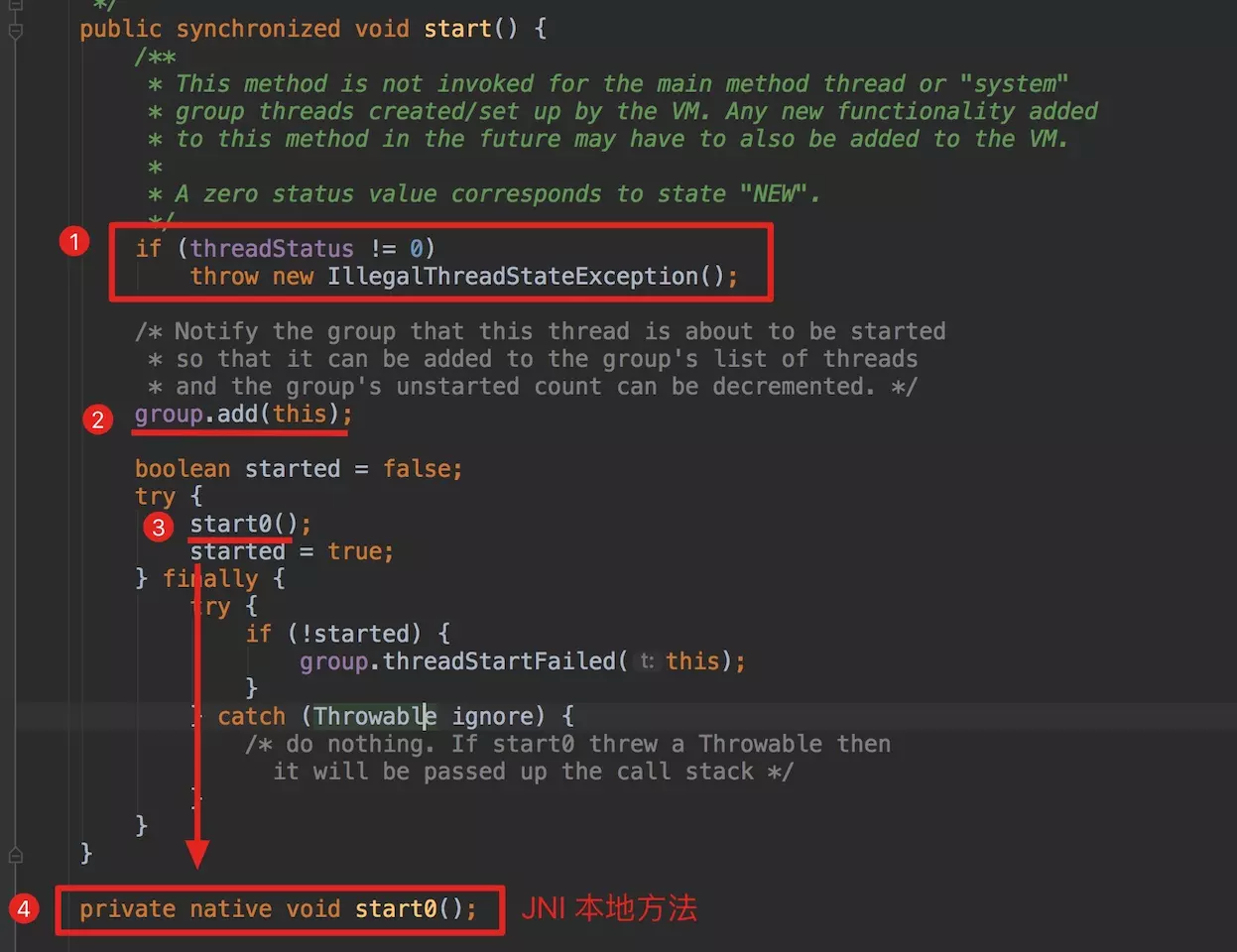
- ①:首先,会判断线程的状态是否是 NEW 状态,内部对应的状态标识是个 0,也就是说如果不等于 0,直接抛线程状态异常(所以不能调用start方法超过一次);
- ②:线程在启动后被加入到
ThreadGroup中; - ③:
start0是最核心的方法了,就是运行状态为 NEW (内部状态标识为 0) 的线程; - ④:
start0是个native方法,也就是 JNI 方法;
看到这里,你也许会有个疑问,自己重写的 run 方法是什么时候被调用的呢?源码中也没看到调用啊!!
Causes this thread to begin execution; the Java Virtual Machine calls the run method of this thread.
上面这段截自 JDK 官方文档,意思是说:
run 方法是在调用 JNI 方法 start0() 的时候被调用的,被调用后,我们写的逻辑代码才得以被执行。
什么是线程池?线程池的工作原理和使用线程池的好处?
线程池源码里最主要的类:ThreadPoolExecutor;
对该类的源码进行部分解析;
线程池重要的两个状态:
-
runState:线程池运行状态
-
workerCount:工作线程的数量
线程池用一个32位的int来同时保存runState和workerCount,其中高3位(第31到29位)是runState,其余29位是workerCount(大约500 million 即5亿左右,2的29次方-1);如下图

一个线程池管理了一组工作线程,同时它还包括了一个用于放置等待执行任务的任务队列(阻塞队列)。
默认情况下,在创建了线程池后,线程池中的线程数为 0。
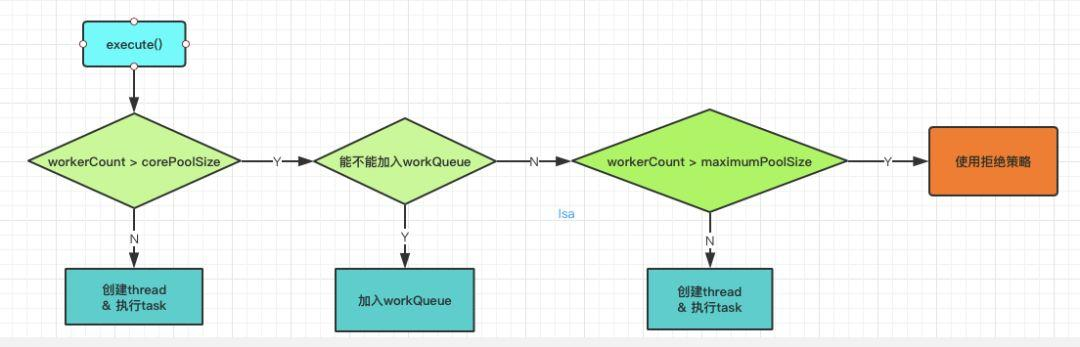
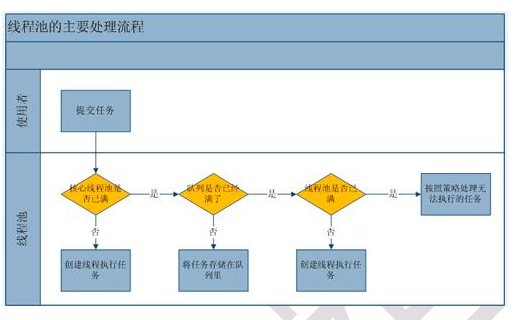
当任务提交给 线程池之后的处理策略如下:
1. 如果此时线程池中的线程数量小于 corePoolSize(核心池的大小),即使线程池中的线程都处于空闲状态,也要创建新的线程来处理被添加的任务(也 就是每来一个任务,就要创建一个线程来执行任务)。
2. 如果此时线程池中的数量大于等于 corePoolSize,但是缓冲队列 workQueue 未满,那么任务被放入缓冲队列,则该任务会等待空闲线程将其 取出去执行。
3. 如 果 此 时 线 程 池 中 的 数 量 大 于 等 于 corePoolSize , 缓 冲 队 列 workQueue 满,并且线程池中的数量小于 maximumPoolSize(线程池 最大线程数),建新的线程来处理被添加的任务。
4. 如果 此时 线程 池中 的数量 大 于 等 于 corePoolSize, 缓 冲 队列 workQueue 满,并且线程池中的数量等于 maximumPoolSize,还有任务需要线程执行,那么通 过 RejectedExecutionHandler 所指定的策略(任务拒绝策略)来处理此任务;也就是处理任务的优先级为:核心线程 corePoolSize、任务队列 workQueue、最大线程 maximumPoolSize,如果三者都满了,使用 handler 处理被拒绝的任务。
5. 特别注意,在 corePoolSize 和 maximumPoolSize 之间的线程 数会被自动释放。当线程池中线程数量大于 corePoolSize 时,如果某线程 空闲时间超过 keepAliveTime,线程将被终止,直至线程池中的线程数目不大于 corePoolSize。这样,线程池可以动态的调整池中的线程数。
6. threadFactory
创建线程的工厂,所有的线程都是通过这个Factory创建的;
默认会使用Executors.defaultThreadFactory 来作线程工厂;
也可以通过guava包下com.google.common.util.concurrent.ThreadFactoryBuilder创建;
如下可通过ThreadFactory指定线程池中线程的名称。
ThreadFactory namedThreadFactory = new ThreadFactoryBuilder() .setNameFormat("order-pool-%d") .build();
7. handler 线程池的饱和策略。做不了任务了找理由罢工
-
AbortPolicy
-
直接抛出异常,默认策略;
-
CallerRunsPolicy
-
用调用者所在的线程来执行任务;
-
DiscardOldestPolicy
-
丢弃阻塞队列中第一个(即最旧)的任务,并执行当前任务;
-
DiscardPolicy
-
直接丢弃任务。
什么是Worker ?
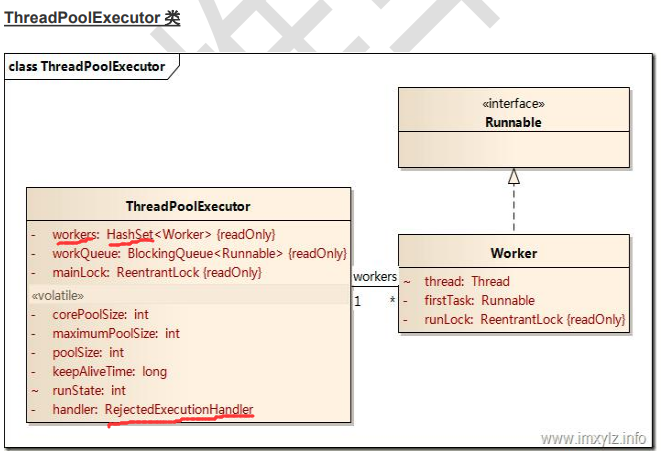
private final class Worker extends AbstractQueuedSynchronizer implements Runnable
Worker唯一构造方法:
Worker(Runnable firstTask) { setState(-1); // inhibit interrupts until runWorker this.firstTask = firstTask; this.thread = getThreadFactory().newThread(this); }
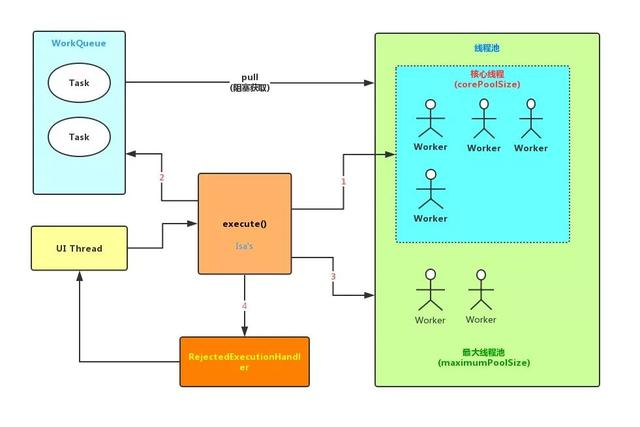
线程池底层原理
(重点)Worker既实现了Runnable,又继承了AbstractQueuedSynchronizer(AQS),所以它既是一个可执行的任务,又可以判断线程是否处于活跃状态(源码中正在执行同步代码块)。
Worker还有两个重要属性,一个是firstTask,一个是final Thread thread, thread用来执行线程任务task。
当往核心线程池里添加线程任务时,如果此时线程数小于corePoolSize,会new 一个 Worker,在new Worker(task)的构造方法里通过threadFactory创建线程提交worker任务,并且把当前worker添加到一个HashSet( hashSet.add(worker))中;
后续如果满了添加到workQueue,从阻塞队列中出队后的任务也是由Worker执行;
workQueue满了,但线程数小于maximumPoolSize,也是通过new Worker(task, false)执行任务, 第二个参数false表示不是核心线程, 是临时线程。

使用线程池的好处:
1.通过重复利用已创建的线程,减少在创建和销毁线程上所花的时间以及系统资源的开销。
2.提高响应速度。当任务到达时,任务可以不需要等到线程创建就可以立即执行。
3.提高线程的可管理性。使用线程池可以对线程进行统一的分配和监控。
4.如果不使用线程池,有可能造成系统创建大量线程而导致消耗完系统内存。
工具类Executors

对于原理,有几个接口和类值得我们关注:
Executor 接口
Executors 类
ExecutorService 接口
AbstractExecutorService 抽象类
ThreadPoolExecutor 类
Executor 是一个顶层接口,在它里面只声明了一个方法 execute(Runnable),返回 值为 void,参数为 Runnable 类型,从字面意思可以理解,就是用来执行传进去的任务的;
然后 ExecutorService 接口继承了 Executor 接口,并声明了一些方法:submit、 invokeAll、invokeAny 以及 shutDown 等;
抽象类 AbstractExecutorService 实现了 ExecutorService 接口,基本实现了 ExecutorService 中声明的所有方法;
然后 ThreadPoolExecutor 继承了类 AbstractExecutorService。
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) 创建一个支持定时及周期性的任务执行的线程池,多数情况下可用来替代 Timer 类。

根据上面的源码中corePoolSize、maximumPoolSize和workQueue的类型可知如下特点:
1. newSingleThreadExecutor
创建一个单线程的无界阻塞队列线程池;
这个线程池只有一个线程在工作,也就是相当于单线程串行执行所有任务;
如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它;
此线程池保证所有任务的执行顺序按照任务的提交顺序执行。
2.newFixedThreadPool
创建固定线程数量的无界阻塞队列线程池;
每次提交一个任务就创建一个线程,直到线程达到线程池的最大大小;
线程池的大小一旦达到最大值就会保持不变,如果某个线程因为执行异常而结 束,那么线程池会补充一个新线程。
3. newCachedThreadPool
创建一个可缓存的线程池(corePoolSize为0,全部都是临时线程);
如果线程池的大小超过了处理任务所需要的线程,那么就会回收部分空闲(60 秒不执行任务)的线程,当任务数增加时,此线程池又可以智能的添加新线程来处理任务;
此线程池不会对线程池大小做限制,线程池大小完全依赖于操作系 统(或者说 JVM)能够创建的最大线程大小。
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit, BlockingQueue workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler);

在 ThreadPoolExecutor 类中有几个非常重要的方法:
execute()
submit()
shutdown()
shutdownNow()
execute 和 submit 区别: submit 有返回值,execute 没有返回值;
所以说可以根据任务有无返回 值选择对应的方法。 submit 方便异常的处理;
如果任务是实现的Callable接口,会返回值,也可能会抛出异常,而且希望外面的调用者获取返回值能够感知这些异常,那么就需要调用 submit 方法,通过捕获 Future.get 抛出的异常;
FutureTask.get方法:线程会阻塞直至状态达到最终状态,若最终状态为NORMAL,则正常返回,若状态为CANCELLED或INTERRUPTED,则抛出CancellationException,若状态为EXCEPTIONAL,则抛出对应的执行异常;
shutdown()和 shutdownNow()的区别: shutdown()和 shutdownNow()是用来关闭线程池的。
shutdown 方法:此方法执行后不得向线程池再提交任务,如果有空闲线程则销毁空闲线程,等待所有正在执行的任务及位于阻塞队列中的任务执行结束,然后销毁所有线程。
shutdownNow 方法:此方法执行后不得向线程池再提交任务,如果有空闲线程则销毁空闲线程,取消所有位于阻塞队列中的任务,并将其放入 List容器,作为返回值;取消正在执行的线程(实际上仅仅是设置正在执行线程的中断标志位,调用线程的 interrupt 方法来中断线程)。
如何停止一个线程?
https://blog.csdn.net/zbw18297786698/article/details/53432879
1. 设置标志位
可以用一个boolean类型或int类型的变量
2.利用Java线程的中断
和上面的标志位有些许类似;
线程A被其他线程调用了interrupt方法设置线程A的标志位,线程A run方法内部判断Thread.currentThread().isInterrupted(),如果true就停止,前提是线程A不处于sleep/wait/yield/join;
中断可以理解为线程的一个标志位属性,它表示一个运行中的线程是否被其他线程进行了中断操作。
中断好比其他线程对该线程打了个招呼,其他线程通过调用该线程的interrupt()方法对其进行中断操作。
线程通过检查自身是否被中断来进行响应,线程通过方法isInterrupted()来进行判断是否被中断,也可以调用静态方法Thread.interrupted()对当前线程的中断标识位进行复位。
如果该线程已经处于终结状态,即使该线程被中断过,在调用该线程对象的isInterrupted()时依旧会返回false。
import java.util.concurrent.TimeUnit; public class InterruptThreadStateTest { public static void main(String[] args) throws InterruptedException { Thread t = new Thread(new Worker(), "WorkerThread"); t.start(); TimeUnit.MILLISECONDS.sleep(100); System.out.println("ThreadName: "+ Thread.currentThread().getName() +" call ThreadName:" + t.getName()+" Method:interrupt"); t.interrupt(); TimeUnit.MILLISECONDS.sleep(500); System.out.println("ThreadName:"+ t.getName()+" state : " + t.getState()); } private static class Worker implements Runnable{ @Override public void run() { Thread t = Thread.currentThread(); while (true) { System.out.println("ThreadName:" + t.getName() + " state : " + t.getState()); if (t.isInterrupted()) { System.out.println("ThreadName:" + t.getName() + " 被中断"); return; }else{ System.out.println("ThreadName:" + t.getName() + " 没有被中断"); } } } } }
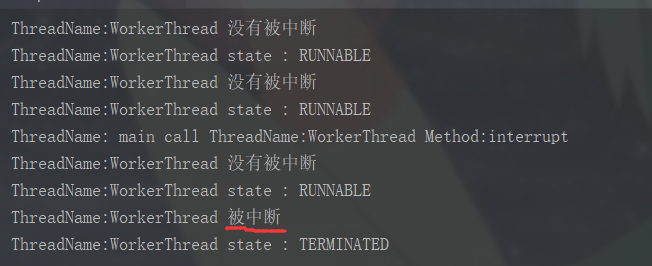
run方法执行完毕,线程状态Terminated。
3. 利用抛出InterruptedException的方式
中断可以理解为线程的一个标志位属性,它表示一个运行中的线程是否被其他线程进行了中断操作。
中断好比其他线程对该线程打了个招呼,其他线程通过调用该线程的interrupt()方法对其进行中断操作。
线程通过检查自身是否被中断来进行响应,线程通过方法isInterrupted()来进行判断是否被中断,也可以调用静态方法Thread.interrupted()对当前线程的中断标识位进行复位;
如果该线程已经处于终结Terminated状态,即使该线程被中断过,在调用该线程对象的isInterrupted()时依旧会返回false。
从Java的API中可以看到,许多声明抛出InterruptedException的方法(例如Thread.sleep(longmillis)方法,当线程在sleep/wait/yield/join时,如果被中断,这个异常就会产生)。
这些方法在抛InterruptedException之前,Java虚拟机会先将该线程的中断标识位清除,然后抛出InterruptedException,此时调用isInterrupted()方法将会返回false。
public class ThreadStopSafeInterrupted {
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread() {
@Override
public void run() {
while (true) {
// 使用中断机制,来终止线程
if (Thread.currentThread().isInterrupted()) {
System.out.println("Interrupted ...");
break;
}
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
System.out.println("Interrupted When Sleep ...");
// Thread.sleep()方法由于中断抛出异常。
// Java虚拟机会先将该线程的中断标识位清除,然后抛出InterruptedException,
// 因为在发生InterruptedException异常的时候,会清除中断标记
// 如果不加处理,那么下一次循环开始的时候,就无法捕获这个异常。
// 故在异常处理中,再次设置中断标记位
Thread.currentThread().interrupt();
}
}
}
};
// 开启线程
thread.start();
Thread.sleep(2000);
thread.interrupt();
}
}

4种阻塞队列
BlockingQueue包含了take和put两个重要方法,不同的BlockingQueue对这两个方法有不同的实现。
- ArrayBlockingQueue:是一个基于数组结构的有界阻塞队列,此队列按 FIFO(先进先出)原则对元素进行排序,初始化分配队列整个内存,用一个锁实现。
- LinkedBlockingQueue:一个基于链表结构的阻塞队列(可以是无界,无界阻塞队列可能会占满内存资源),此队列按FIFO (先进先出) 排序元素,吞吐量通常要高于ArrayBlockingQueue,put和take是用两个不同的锁实现;静态工厂方法Executors.newFixedThreadPool()使用了这个队列。
- SynchronousQueue:一个不存储元素的无界阻塞队列,(maximumPoolSize的值就应该无界或者说无限制)会直接将任务交给消费者,必须等队列中的添加元素被消费take后才能继续添加put新的元素。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQueue,静态工厂方法Executors.newCachedThreadPool使用了这个队列,因为SynchronousQueue没有存储功能,因此put和take会一直阻塞,直到有另一个线程已经准备好参与到交付过程中;仅当有足够多的消费者,并且总是有一个消费者准备好获取take的工作时,才适合使用同步队列。
- PriorityBlockingQueue:一个具有优先级得无限阻塞队列。
如何合理的配置 java 线程池?如 CPU 密集型的任务,基本线程池 应该配置多大?IO 密集型的任务,基本线程池应该配置多大?用有界 队列好还是无界队列好?任务非常多的时候,使用什么阻塞队列能获取 最好的吞吐量?
答:
1)配置线程池时,CPU 密集型任务可以少配置线程数,大概和机器的 cpu 核数相 当,可以使得每个线程都在执行任务。
2)IO 密集型任务则由于需要等待 IO 操作,分配给该线程的时间片完了,CPU就执行其他线程的任务,则配置尽可能多的线程数,2*cpu 核数。
3)有界队列和无界队列的配置需区分业务场景,一般情况下配置有界队列,在一些 可能会有爆发性增长的情况下使用无界队列。
4)任务非常多时,使用非阻塞队列,使用 CAS 操作替代锁可以获得好的吞吐量。 synchronousQueue 吞吐率最高。
(重要)合理的配置线程池
以下仅仅只是参考,真正的配置还是需要各种测试之后,根据指标选择一个较为合适的配置。
要想合理的配置线程池,就必须首先分析任务特性,可以从以下几个角度来进行分析:
- 任务的性质:CPU密集型任务,IO密集型任务和混合型任务。
- 任务的优先级:高,中和低。
- 任务的执行时间:长,中和短。
- 任务的依赖性:是否依赖其他系统资源,如数据库连接。
任务性质不同的任务可以用不同规模的线程池分开处理;
CPU密集型任务配置尽可能少的线程数量,因为线程执行的任务,一直都在被CPU执行,如配置Ncpu+1个线程的线程池;
IO密集型任务则由于需要等待IO操作,线程并不是一直在执行任务,则配置尽可能多的线程,如2*Ncpu,这样在一个线程等待IO过程中,CPU时间片消耗完了,CPU就去执行其他线程;
混合型的任务,如果可以拆分,则将这个混合型任务拆分成一个CPU密集型任务和一个IO密集型任务,只要这两个任务执行的时间相差不是太大,那么分解后执行的吞吐率要高于串行执行的吞吐率,如果这两个任务执行时间相差太大,则没必要进行分解。我们可以通过Runtime.getRuntime().availableProcessors()方法获得当前设备的CPU个数。
优先级不同的任务可以使用优先级队列PriorityBlockingQueue来处理;
它可以让优先级高的任务先得到执行,需要注意的是如果一直有优先级高的任务提交到队列里,那么优先级低的任务可能永远不能执行。
执行时间不同的任务可以交给不同规模的线程池来处理,或者也可以使用优先级队列,让执行时间短的任务先执行。
依赖数据库连接池的任务,因为线程提交SQL后需要等待数据库返回结果,如果等待的时间越长CPU空闲时间就越长,那么线程数应该设置越大,这样才能更好的利用CPU。
建议使用有界队列,有界队列能增加系统的稳定性和预警能力,可以根据需要设大一点,比如几千。
比如后台任务线程池的队列和线程池全满了,不断的抛出抛弃任务的异常,通过排查发现是数据库出现了问题,导致执行SQL变得非常缓慢,因为后台任务线程池里的任务全是需要向数据库查询和插入数据的,所以导致线程池里的工作线程全部阻塞住,任务积压在线程池里。如果当时我们设置成无界队列,线程池的队列就会越来越多,有可能会撑满内存,导致整个系统不可用,而不只是后台任务出现问题。当然当我们的系统所有的任务是用的单独的服务器部署的,而我们使用不同规模的线程池跑不同类型的任务,但是出现这样问题时也会影响到其他任务。
即使如此,也还是要根据各个业务、系统环境等因素,测试之后来确定对应的参数,甚至在不同情况下,还需要不同的线程数来保证运行高效。
参考来源
http://ifeve.com/java-threadpool/



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架
2018-06-05 spring中的BeanFactory和FactoryBean的区别与联系