2019-03-14 Python爬虫问题 爬取网页的汉字打印出来乱码
html = requests.get(YieldCurveUrl, headers=headers)
html=html.content.decode('UTF-8')
# print(html)
soup = BeautifulSoup(html, 'lxml')
之前是这样的
html = requests.get(YieldCurveUrl, headers=headers) soup = BeautifulSoup(html.text, 'lxml')
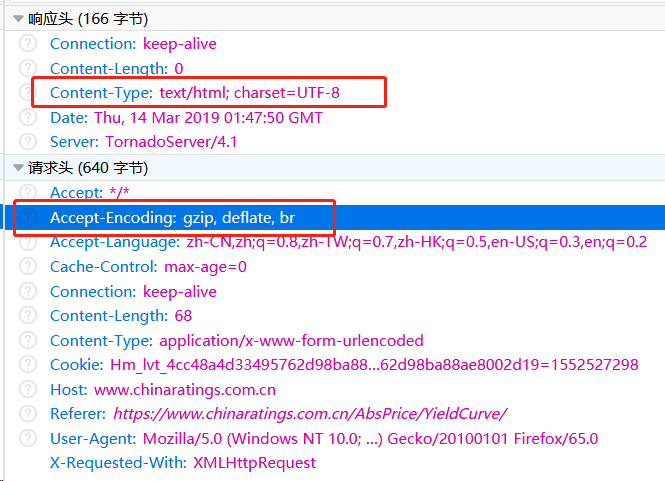
出现乱码,一般是两种原因,charset使用了geb2312的编码方式,而非utf-8
这里用的是utf-8,所以问题出在使用了gzip的压缩方式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号