Flink的状态与容错
本文主要运行到Flink以下内容
-
检查点机制(CheckPoint)
-
状态管理器(StateBackend)
-
状态周期(StateTtlConfig)
关系
首先要将state和checkpoint概念区分开,可以理解为checkpoint是要把state数据持久化存储起来,checkpoint默认情况下会存储在JoManager的内存中。checkpoint表示一个Flink job在一个特定时刻的一份全局状态快照,方便在任务失败的情况下数据的恢复。在启动 CheckPoint 机制时,状态会随着 CheckPoint 而持久化,以防止数据丢失、保障恢复时的一致性。状态内部的存储格式、状态在 CheckPoint 时如何持久化以及持久化在哪里均取决于选择的StateBackend。存储多长时间或者说是周期,取决于StateTtlConfig
1 检查点机制(CheckPoint)
Checkpoint 使 Flink 的状态具有良好的容错性,通过 checkpoint 机制,Flink 可以对作业的状态和计算位置进行恢复。
Checkpoint 在默认的情况下仅用于恢复失败的作业,并不保留,当程序取消时 checkpoint 就会被删除。当然,你可以通过配置来保留 checkpoint,这些被保留的 checkpoint 在作业失败或取消时不会被清除。这样,你就可以使用该 checkpoint 来恢复失败的作业。
参数设置与解释
val env: StreamExecutionEnvironment =
StreamExecutionEnvironment.getExecutionEnvironment
//只指定两个checkpoint的时间间隔,单位是毫秒
//指定checkpoint时间间隔,并指定checkpoint的模式,是exactly-once(刚好一次)
//还是AT_LEAST_ONCE(至少一次)。
//大多数情况下是exactly-once(默认就是这个模式),少数情况下,如果要求超低延迟的处理情况,才会设置AT_LEAST_ONCE
env.enableCheckpointing(1000,CheckpointingMode.EXACTLY_ONCE)
// 两种方式
// env.enableCheckpointing(1000)
// env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
/* 设置checkpoint上一个的结束点到下一个开始点之间的最短时间。
checkpoint触发时,需要一定时间去完成整个checkpoint的过程,
1、这里的时间间隔,指的是上一个checkpoint完成的时间点,到下一个checkpoint开始的时间点的间隔,如果过短,会导致频繁checkpoint,影响性能。假设这个间隔为T
2、而上面设置的checkpoint时间间隔,指的是前一个checkpoint的开始时间到下一个checkpoint的开始时间。所以是始终大于1中的时间间隔的。假设这个间隔为 N
如果T小于这里设置的值,那么无论N设置多少,下一个checkpoint的开始时间必须是5000ms之后。如果T大于这里设置的值,那么正常按照N设置的间隔来触发下一个checkpoint,这里设置的间隔无关了。
*/
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(5000)
// 设置checkpoint完成的超时时间
env.getCheckpointConfig().setCheckpointTimeout(60000)
// 设置checkpoint的最大并行度
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1)
/* 开启checkpoints的外部持久化,但是在job失败的时候不会自动清理,需要自己手工清理state
DELETE_ON_CANCELLATION:在job canceled的时候会自动删除外部的状态数据,但是如果是FAILED的状态则会保留;
RETAIN_ON_CANCELLATION:在job canceled的时候会保留状态数据*/
env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
// 当有更近的保存点时,优先采用savepoint来恢复成检查点
env.getCheckpointConfig().setPreferCheckpointForRecovery(true)
目录结构
/user-defined-checkpoint-dir
/{job-id}
|
+ --shared/
+ --taskowned/
+ --chk-1/
+ --chk-2/
+ --chk-3/
...
SHARED目录保存了可能被多个 checkpoint 引用的文件
TASKOWNED保存了不会被 JobManager 删除的文件
EXCLUSIVE则保存那些仅被单个 checkpoint 引用的文件
2 状态管理器(StateBackend)
可用的 State Backends
-
MemoryStateBackend
-
FsStateBackend
-
RocksDBStateBackend
MemoryStateBackend
在 MemoryStateBackend 内部,数据以 Java 对象的形式存储在堆中。Key/value 形式的状态和窗口算子持有存储着状态值、触发器的 hash table。
在 CheckPoint 时,State Backend 对状态进行快照,并将快照信息作为 CheckPoint 应答消息的一部分发送给 JobManager(master),同时 JobManager 也将快照信息存储在堆内存中。
MemoryStateBackend 能配置异步快照。强烈建议使用异步快照来防止数据流阻塞,注意,异步快照默认是开启的。用户可以在实例化 MemoryStateBackend 的时候,将相应布尔类型的构造参数设置为 false 来关闭异步快照(仅在 debug 的时候使用),例如:
new MemoryStateBackend(MAX_MEM_STATE_SIZE, false)
FsStateBackend
FsStateBackend 将正在运行中的状态数据保存在 TaskManager 的内存中。CheckPoint 时,将状态快照写入到配置的文件系统目录中。少量的元数据信息存储到 JobManager 的内存中(高可用模式下,将其写入到 CheckPoint 的元数据文件中)。
FsStateBackend 默认使用异步快照来防止 CheckPoint 写状态时对数据处理造成阻塞。用户可以在实例化 FsStateBackend 的时候,将相应布尔类型的构造参数设置为 false 来关闭异步快照,例如:
new FsStateBackend(path, false)
RocksDBStateBackend
RocksDBStateBackend 将正在运行中的状态数据保存在 RocksDB 数据库中,RocksDB 数据库默认将数据存储在 TaskManager 的数据目录。CheckPoint 时,整个 RocksDB 数据库被 checkpoint 到配置的文件系统目录中。少量的元数据信息存储到 JobManager 的内存中(高可用模式下,将其存储到 CheckPoint 的元数据文件中)。RocksDBStateBackend 只支持异步快照。
设置 State Backend
后面的案例也以RocksDBStateBackend为例
val backend:StateBackend = new RocksDBStateBackend("hdfs://djcluster/Test/")
env.setStateBackend(backend)
3 状态周期(StateTtlConfig)
状态引入了TTL(time-to-live,生存时间)机制,支持Keyed State 的自动过期,有效解决了状态数据在无干预情况下无限增长导致 OOM 的问题。对于任何类型 Keyed State 都可以设定状态生命周期(TTL),以确保能够在规定时间内即时清理状态数据。
val config: StateTtlConfig = StateTtlConfig
.newBuilder(Time.minutes(1))
.setUpdateType(StateTtlConfig.UpdateType.OnReadAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build()
val mapState = new MapStateDescriptor[String,Any]("aa",classOf[String],classOf[Any])
mapState.enableTimeToLive(config)
参数说明:
-
UpdateType:表示状态时间戳的更新的时机
| 参数 | 说明 |
|---|---|
| Disabled | 不更新时间戳 |
| OnCreateAndWrite | 当状态创建或每次写入时都会更新时间戳 |
| OnReadAndWrite | 除了在状态创建和写入时更新时间戳外,读取也会更新状态的时间戳 |
-
StateVisibility:表示对已过期但还未被清理掉的状态如何处理
| 参数 | 说明 |
|---|---|
| ReturnExpiredIfNotCleanedUp | 即使这个状态的时间戳表明它已经过期了,但是只要还未被真正清理掉,就会被返回给调用方 |
| NeverReturnExpired | 那么一旦这个状态过期了,那么永远不会被返回给调用方,只会返回空状态,避免了过期状态带来的干扰 |
上面是理论论述,下面是代码实现与测试
4.理论实现与测试
描述
通过 nc -lk 8765 在机器上输入逗号隔开的字符串,比如:event,1,1 要保证中间的值和下次输入的值一样,这样keyBy分流到一个分区中,方便测试看到效果。状态值保存到Hdfs上。
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment =
StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val backend:StateBackend = new RocksDBStateBackend("hdfs://cluster/Test/")
env.setStateBackend(backend)
env.enableCheckpointing(5000)
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
env.getCheckpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
val dataDS: scala.DataStream[String] = env.socketTextStream("localhost", 8765)
dataDS.map(item => {
val str = item.split(",")
(str(0),str(1),str(2))
}
)
.keyBy(_._2)
.process(
new KeyedProcessFunction[String,(String, String, String), String] {
var leastValueState: MapState[String, Any] = _
override def open(parameters: Configuration): Unit = {
println("open")
val config: StateTtlConfig = StateTtlConfig
.newBuilder(Time.minutes(15))
.setUpdateType(StateTtlConfig.UpdateType.OnReadAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build()
val aa = new MapStateDescriptor[String,Any]("aa",classOf[String],classOf[Any])
aa.enableTimeToLive(config)
leastValueState = getRuntimeContext.getMapState(aa)
}
override def processElement(i: (String, String, String),
ctx: KeyedProcessFunction[String, (String, String, String), String]#Context,
out: Collector[String]): Unit = {
println(leastValueState.get("3"))
i._1 match {
case "order" => leastValueState.put("order", 12)
case "event" => out.collect("打印event")
case _ => out.collect("什么都没有")
}
out.collect(leastValueState.get("3")+":")
}
}
)
.uid("bbbbbbb")
.print()
env.execute()
}
打包上传集群测试
执行命令
./bin/flink run -m yarn-cluster
-yqu spark -c com.wang.StateBackend /usr/local/jars/flink.jar
-yn 7 -ys 2 -p 14 -ytm 2048m -yjm 2048m

这个不管是你自己亲自kill掉application 或者是某些原因flink任务挂掉,这个时候你就可以这样恢复数据
找到RocksDBStateBackend设置的地址 hdfs://cluster/Test/
找到挂掉任务的checkpoint地址(可以通过Flink历史服务器去找,如果任务少,也可以直接去hdfs上找)
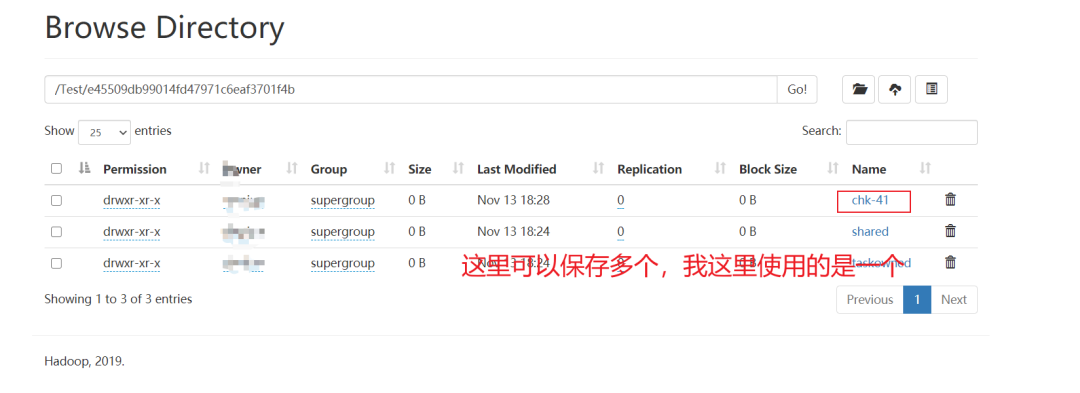
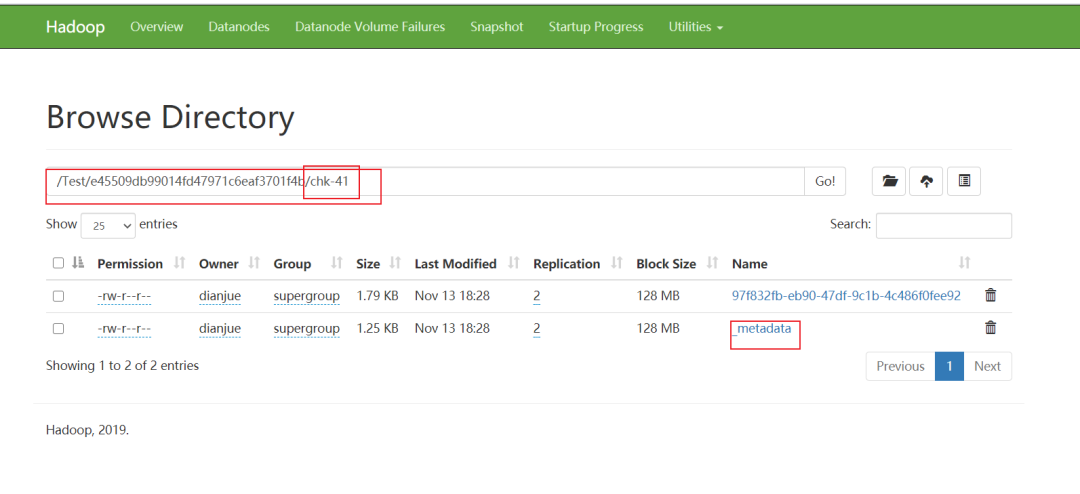
重新启动任务
这边遇到的一个坑就是命令参数位置不对,怎么设置都没有用,也不起效,下次一定记得。刚测试的时候 -s 写在后面的某一个位置,怎么测试都不起效,一直以为代码有问题,查询了好多资料,都是这样写的,没有问题,前前后后折腾好久。最后把 -s 参数调到最前面就神奇的好了......
./bin/flink run -m yarn-cluster
-s hdfs://cluster/Test/e45509db99014fd47971c6eaf3701f4b/chk-41/_metadata
-yqu spark -c com.wang.StateBackend /usr/local/jars/flink.jar
-yn 7 -ys 2 -p 14 -ytm 2048m -yjm 2048m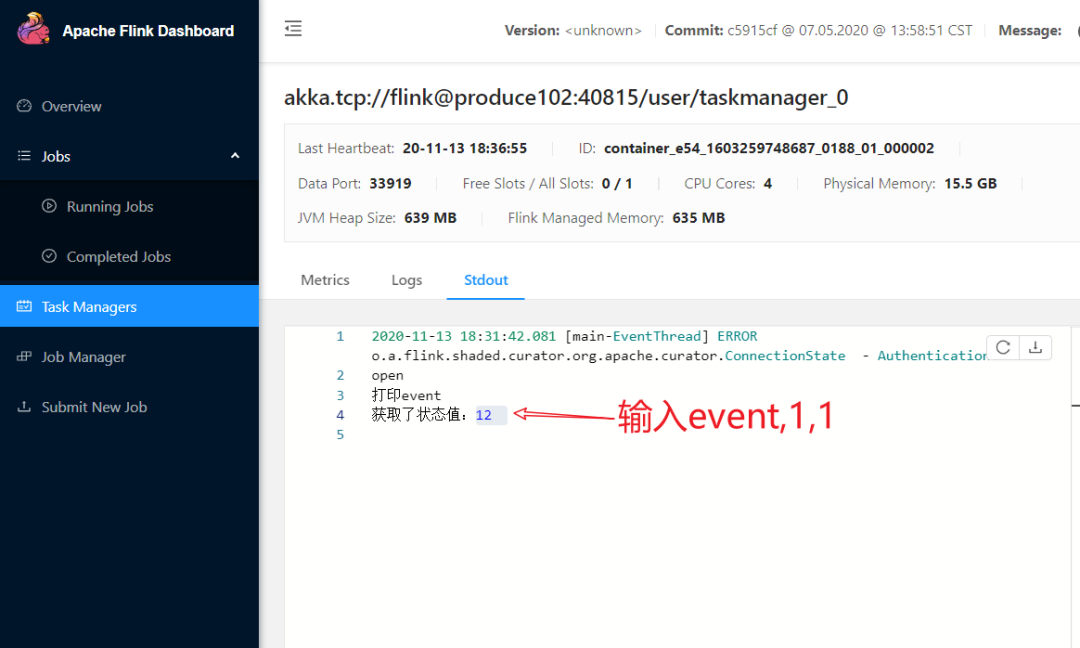
这个时候已经恢复到之前挂掉的数据了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号