


堆排序
树的概念
# 树是一种数据结构 比如:目录结构
# 树是一种可以递归定义的数据结构
# 树是由n个节点组成的集合:
# 如果n=0,那这是一棵空树;
# 如果n>0,那存在1个节点作为树的根节点,其他节点可以分为m个集合,每个集合本身又是一棵树。
# 一些概念
# 根节点、叶子节点
# 树的深度(高度)
# 树的度 (最大节点的度)
# 孩子节点/父节点
# 子树

二叉树
# 二叉树:度不超过2的树
# 每个节点最多有两个孩子节点
# 两个孩子节点被区分为左孩子节点和右孩子节点

# 满二叉树:一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。
# 完全二叉树:叶节点只能出现在最下层和次下层,并且最下面一层的结点都集中在该层最左边的若干位置的二叉树。

# 二叉数的存储方式(表示方法)
#1 链式存储
#2 顺序存储(如列表)
二叉树的顺序存储方式
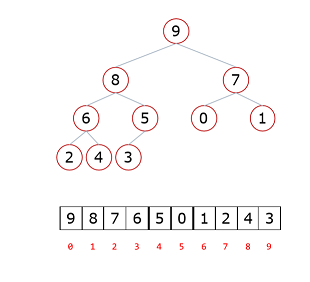
# 父节点和左孩子节点的编号下标有什么关系?
0-1 1-3 2-5 3-7 4-9
i → 2i+1
# 父节点和右孩子节点的编号下标有什么关系?
0-2 1-4 2-6 3-8 4-10
i → 2i+2
# 子节点找父节点:
i → (i-1)//2
堆
# 堆:一种特殊的完全二叉树结构
# 大根堆:一棵完全二叉树,满足任一节点都比其孩子节点大 (大跟堆排序是升序)
# 小根堆:一棵完全二叉树,满足任一节点都比其孩子节点小 (小跟堆排序是降序)

堆的向下调整性质
# 假设根节点的左右子树都是堆,但根节点不满足堆的性质
# 可以通过一次向下的调整来将其变成一个堆。
堆排序
原理
#1.建立堆(大跟堆);
#2.得到堆顶元素,为最大元素;
#3.去掉堆顶,将堆最后一个元素放到堆顶,此时可通过一次调整重新使堆有序;
#4.堆顶元素为第二⼤大元素;
#5.重复步骤3,直到堆变空。
代码实现
基于大跟堆实现列表升序排序
堆排序的时间复杂度是 O(nlogn)
# -*- coding: utf-8 -*-
# created by X. Liu on 2020/3/12
def sift(li, low, high):
"""
实现堆的向下调整性质
:param li:
:param low: 堆顶位置
:param high: 堆最后一个节点位置
:return: None
"""
tmp = li[low]
i = low
j = 2*i+1
while j <= high:
if j+1 <= high and li[j+1] > li[j]: # 比较左孩子节点和右孩子节点的大小
j = j+1 # 如果有右孩子且比左孩子点大,j指向右孩子节点
if li[j] > tmp: # 如果孩子节点元素大于i其父节点
li[i] = li[j] # 将子节点元素移动到父节点位置
i = j # i 指向该子节点,做下一轮的比较
j = 2*i+1
else: # 这种情况指的是tmp适合这个位置,大于它的子节点上的数
li[i] = tmp
break
else: # 这种情况值得是,比较到最下层了,将tmp放到此时i的位置(最下层位置)
li[i] = tmp
def heap_sort(li):
"""
先建堆,再挨个出数
:param li:
:return:
"""
n = len(li)
# 建堆
for i in range((n-2)//2, -1, -1): # i 是父节点,用堆最后一个位置行使high参数的功能
sift(li, i, n-1) # 子节点找父节点: k --> (k-1)//2
# high参数的功能是为了标记向下调整时子节点位置(j or j+1)不越界
# 挨个出数
for i in range(n-1, -1, -1): # n个数遍历n次
li[0], li[i] = li[i], li[0] # 将堆顶元素与堆最后一个位置的数据交换
sift(li, 0, i-1) # 将堆顶元素换下后,向下调整
# 值得注意的是,此时high位置是i-1。因为最后一个位置放最大元素了,已经不再堆内啦
# sift的时间复杂度是O(logn)
# heap_sort的时间复杂度是O(nlogn)
总结思考
# 堆排序实现需要注意三点:
- 向下调整的实现
- 建堆
- 挨个出数
# 向下调整:
- high参数指的是列表最后一个元素所在的位置
- 参数j需要时刻注意越界问题:j <= high
- 参数j+1 也需要注意越界问题 j+1 <= high
# 建堆:
- 建堆采用'农村包围城市的策略',在调用sift函数时,可以使用列表最后一个参数的位置当high参数
# 挨个出数:
- 挨个出数时,因为要将堆顶元素放在列表最后一个位置,需要时时缩小堆的范围。

