分布式事务解决方案
一、基础知识
- 事务:事务由一组操作构成,我们希望这组操作能够全部正确执行,如果这一组操作中的任意一个步骤发生错误,那么就需要回滚之前已经完成的操作。也就是同一个事务中的所有操作,要么全都正确执行,要么全都不要执行。
-
事务的四大特性ACID:
原子性:事务是一个不可分割的执行单元,事务中的所有操作要么全都执行,要么全都不执行。
隔离性:事务的执行是相互独立的,它们不会相互干扰,一个事务不会看到另一个正在运行过程中的事务的数据。
持久性:持久性要求,一个事务完成之后,事务的执行结果必须是持久化保存的。即使数据库发生崩溃,在数据库恢复后事务提交的结果仍然不会丢失。
一致性:事务在开始前和结束后,数据库的完整性约束没有被破坏。
- 脏读、幻读、虚读及不可重复读
脏读:如果一个事务中对数据进行了更新,但事务还没有提交,另一个事务可以“看到”该事务没有提交的更新结果,这样造成的问题就是,如果第一个事务回滚,那么,第二个事务在此之前所“看到”的数据就是一笔脏数据。
不可重复读:包括幻读和虚读两种情况
幻读:事务1在两次查询的过程中,事务2对该表进行了插入、删除操作,从而事务1第二次查询的结果发生了变化。
虚读:在事务1两次读取同一记录的过程中,事务2对该记录进行了修改,从而事务1第二次读到了不一样的记录。
-
数据库的四种隔离级别
1、Read uncommitted 读未提交
在该级别下,一个事务对一行数据修改的过程中,不允许另一个事务对该行数据进行修改,但允许另一个事务对该行数据读。
因此本级别下,不会出现更新丢失,但会出现脏读、不可重复读。
2、Read committed 读提交
在该隔离级别下,不允许2个未提交的事务之间并行执行,但它允许在一个事务执行的过程中,另外一个事务得到执行并提交。这样,会出现一种情况,第一个事务前后两次select出来的某行数据,值可能不一样。值改变的原因是,穿插执行的事务2对该行数据进行了update操作。在同一个事务中,两次select出来的值不相同的问题称为不可重复读问题。要想解决不可重复读问题,需要把数据的隔离级别设置为可重复读。
3、Repeatable read 重复读
在该隔离级别下,在一个事务使用某行的数据的过程中,不允许别的事务再对该行数据进行操作。可重复读应该是给数据库的行加上了锁。这种隔离级别下,依旧允许别的事务在该表中插入和删除数据,于是就会出现,在事务1执行的过程中,如果先后两次select出符合某个条件的行,如果在这两次select直接另一个事务得到了执行,insert或delete了某些行,就会出现先后两次select出来的符合同一个条件的结果不一样,第一次select好像出现了幻觉一样,因此,这个问题也被成为幻读。要想解决幻读问题,需要将数据库的隔离级别设置为串行化。
4、Serializable 序列化
该级别要求所有事务都必须串行执行,因此能避免一切因并发引起的问题,但效率很低。
ps:mysql默认的隔离级别是重复读级别,oracle是读提交
-
乐观锁和悲观锁
乐观锁:总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制和CAS算法实现。乐观锁适用于多读的应用类型,这样可以提高吞吐量。
悲观锁:总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程)。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。Java中synchronized和ReentrantLock等独占锁就是悲观锁思想的实现。
二、mysql如何保证持久性和原子性
在数据库系统中,既有存放数据的文件,也有存放日志的文件。日志在内存中也是有缓存Log buffer,也有磁盘文件log file。
MySQL中的日志文件,有这么两种与事务有关:undo日志与redo日志。
-
undo日志
数据库事务具备原子性(Atomicity),如果事务执行失败,需要把数据回滚。
事务同时还具备持久性(Durability),事务对数据所做的变更就完全保存在了数据库,不能因为故障而丢失。
原子性可以利用undo日志来实现。
Undo Log的原理很简单,为了满足事务的原子性,在操作任何数据之前,首先将数据备份到Undo Log。然后进行数据的修改。如果出现了错误或者用户执行了ROLLBACK语句,系统可以利用Undo Log中的备份将数据恢复到事务开始之前的状态。
数据库写入数据到磁盘之前,会把**数据先缓存在内存**中,事务提交时才会写入磁盘中。
用Undo Log实现原子性和持久化的事务的简化过程:
假设有A、B两个数据,值分别为1,2。
A. 事务开始.
B. 记录A=1到undo log.
C. 修改A=3.
D. 记录B=2到undo log.
E. 修改B=4.
F. 将undo log写到磁盘。
G. 将数据写到磁盘。
H. 事务提交
- 如何保证持久性?
事务提交前,会把修改数据到磁盘前,也就是说只要事务提交了,数据肯定持久化了。
- 如何保证原子性?
每次对数据库修改,都会把修改前数据记录在undo log,那么需要回滚时,可以读取undo log,恢复数据。
- 若系统在G和H之间崩溃
此时事务并未提交,需要回滚。而undo log已经被持久化,可以根据undo log来恢复数据
- 若系统在G之前崩溃
此时数据并未持久化到硬盘,依然保持在事务之前的状态
缺陷:**每个事务提交前将数据和Undo Log写入磁盘,这样会导致大量的磁盘IO,因此性能很低。
如果能够将数据缓存一段时间,就能减少IO提高性能。但是这样就会丧失事务的持久性。因此引入了另外一种机制来实现持久化,即Redo Log
-
redo日志
和Undo Log相反,Redo Log记录的是**新数据**的备份。在事务提交前,只要将Redo Log持久化即可,不需要将数据持久化,减少了IO的次数。
先来看下基本原理,Undo + Redo事务的简化过程:
假设有A、B两个数据,值分别为1,2
A. 事务开始.
B. 记录A=1到undo log buffer.
C. 修改A=3.
D. 记录A=3到redo log buffer.
E. 记录B=2到undo log buffer.
F. 修改B=4.
G. 记录B=4到redo log buffer.
H. 将undo log写入磁盘
I. 将redo log写入磁盘
J. 事务提交
- 安全和性能问题
- 如何保证原子性?
如果在事务提交前故障,通过undo log日志恢复数据。如果undo log都还没写入,那么数据就尚未持久化,无需回滚
- 如何保证持久化?
大家会发现,这里并没有出现数据的持久化。因为数据已经写入redo log,而redo log持久化到了硬盘,因此只要到了步骤`I`以后,事务是可以提交的。
- 内存中的数据库数据何时持久化到磁盘?
因为redo log已经持久化,因此数据库数据写入磁盘与否影响不大,不过为了避免出现脏数据(内存中与磁盘不一致),事务提交后也会将内存数据刷入磁盘(也可以按照固设定的频率刷新内存数据到磁盘中)。
- redo log何时写入磁盘
redo log会在事务提交之前,或者redo log buffer满了的时候写入磁盘
这里存在两个问题:
问题1:之前是写undo和数据库数据到硬盘,现在是写undo和redo到磁盘,似乎没有减少IO次数
- 数据库数据写入是随机IO,性能很差
- redo log在初始化时会开辟一段连续的空间,写入是顺序IO,性能很好
- 实际上undo log并不是直接写入磁盘,而是先写入到redo log buffer中,当redo log持久化时,undo log就同时持久化到硬盘了。
因此事务提交前,只需要对redo log持久化即可。
另外,redo log并不是写入一次就持久化一次,redo log在内存中也有自己的缓冲池:`redo log buffer`。每次写redo log都是写入到buffer,在提交时一次性持久化到磁盘,减少IO次数。
问题2:redo log 数据是写入内存buffer中,当buffer满或者事务提交时,将buffer数据写入磁盘。
redo log中记录的数据,有可能包含尚未提交事务,如果此时数据库崩溃,那么如何完成数据恢复?
数据恢复有两种策略:
- 恢复时,只重做已经提交了的事务
- 恢复时,重做所有事务包括未提交的事务和回滚了的事务。然后通过Undo Log回滚那些未提交的事务
Inodb引擎采用的是第二种方案,因此undo log要在 redo log前持久化
-
总结
最后总结一下:
- undo log 记录更新前数据,用于保证事务原子性
- redo log 记录更新后数据,用于保证事务的持久性
- redo log有自己的内存buffer,先写入到buffer,事务提交时写入磁盘
- redo log持久化之后,意味着事务是**可提交**的
三、分布式事务
应用场景:
当我们的系统采用了微服务架构后,一个电商系统往往被拆分成如下几个子系统:商品系统、订单系统、支付系统、积分系统等。整个下单的过程如下:
用户通过商品系统浏览商品,他看中了某一项商品,便点击下单
此时订单系统会生成一条订单
订单创建成功后,支付系统提供支付功能
当支付完成后,由积分系统为该用户增加积分
上述步骤2、3、4需要在一个事务中完成。对于传统单体应用而言,实现事务非常简单,只需将这三个步骤放在一个方法A中,再用Spring的@Transactional注解标识该方法即可。Spring通过数据库的事务支持,保证这些步骤要么全都执行完成,要么全都不执行。但在这个微服务架构中,这三个步骤涉及三个系统,涉及三个数据库,此时我们必须在数据库和应用系统之间,通过某项黑科技,实现分布式事务的支持。
-
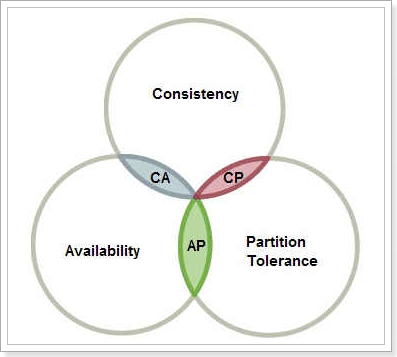
CAP理论:
在一个分布式系统中,最多只能满足C、A、P中的两个需求。
C--Consistency 一致性,同一数据的多个副本是否实时相同。
A--Availability 可用性,一定时间内 ,系统返回一个明确的结果 则称为该系统可用。
P--Partition tolerance 分区容错性,将同一服务分布在多个系统中,从而保证某一个系统宕机,仍然有其他系统提供相同的服务。
-
BASE理论:
BASE是三个单词的缩写:
- Basically Available(基本可用)
- Soft state(软状态)
- Eventually consistent(最终一致性)
如图所示,订单服务、库存服务、用户服务及他们对应的数据库就是分布式应用中的三个部分。
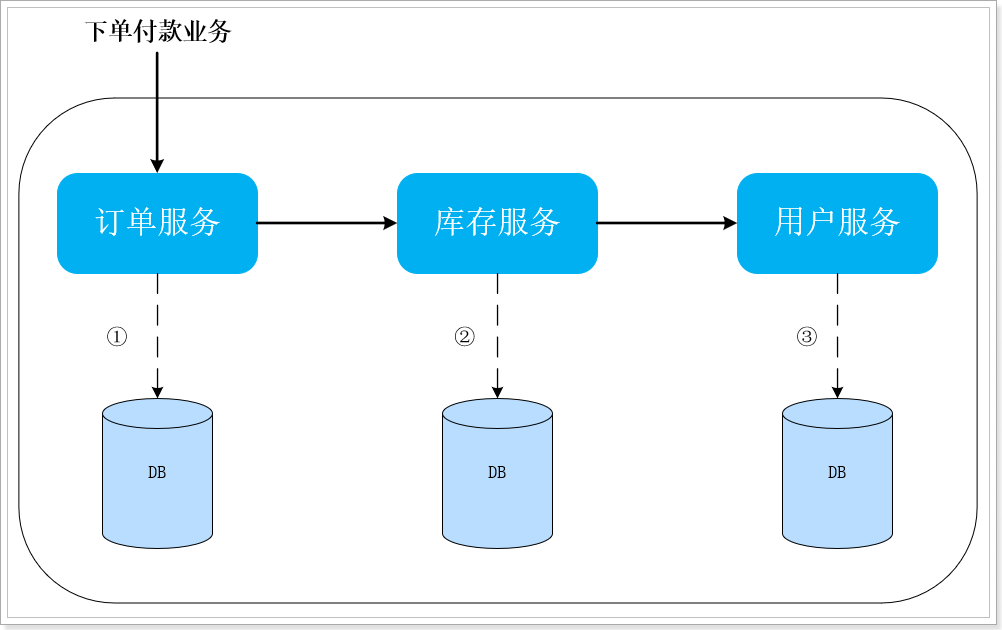
- CP方式:现在如果要满足事务的强一致性,就必须在订单服务数据库锁定的同时,对库存服务、用户服务数据资源同时锁定。等待三个服务业务全部处理完成,才可以释放资源。此时如果有其他请求想要操作被锁定的资源就会被阻塞,这样就是满足了CP。
这就是强一致,弱可用
- AP方式:三个服务的对应数据库各自独立执行自己的业务,执行本地事务,不要求互相锁定资源。但是这个中间状态下,我们去访问数据库,可能遇到数据不一致的情况,不过我们需要做一些后补措施,保证在经过一段时间后,数据最终满足一致性。
这就是高可用,但弱一致(最终一致)。
由上面的两种思想,延伸出了很多的分布式事务解决方案:
- XA
- TCC
- 可靠消息最终一致
- AT
-
二阶段提交
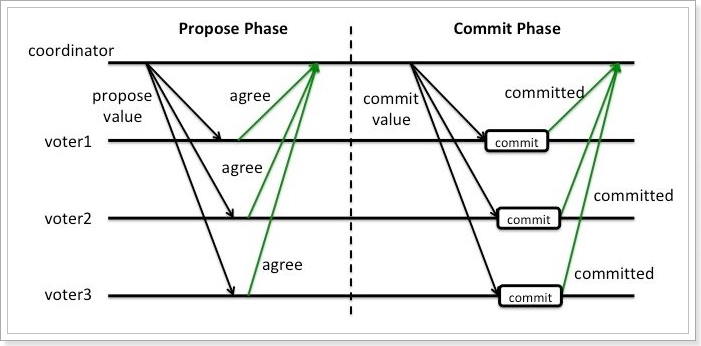
如上图所示,正常情况可分为两阶段:
投票阶段:协调组询问各个事务参与者,是否可以执行事务。每个事务参与者执行事务,写入redo和undo日志,然后反馈事务执行成功的信息(`agree`)
提交阶段:协调组发现每个参与者都可以执行事务(`agree`),于是向各个事务参与者发出`commit`指令,各个事务参与者提交事务。
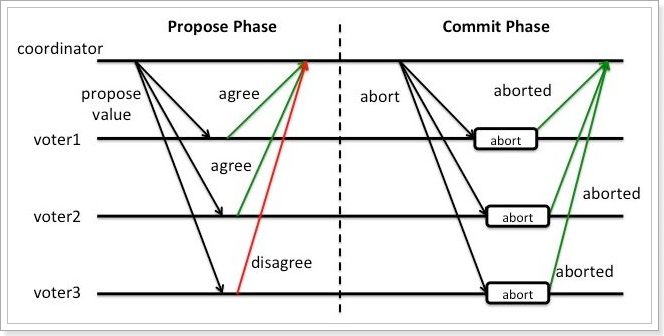
如上图所示,异常情况的处理方式为:
投票阶段:协调组询问各个事务参与者,是否可以执行事务。每个事务参与者执行事务,写入redo和undo日志,然后反馈事务执行结果,但只要有一个参与者返回的是`Disagree`,则说明执行失败。
提交阶段:协调组发现有一个或多个参与者返回的是`Disagree`,认为执行失败。于是向各个事务参与者发出`abort`指令,各个事务参与者回滚事务。
缺点:
2PC的缺点在于不能处理fail-stop形式的节点failure. 比如下图这种情况.
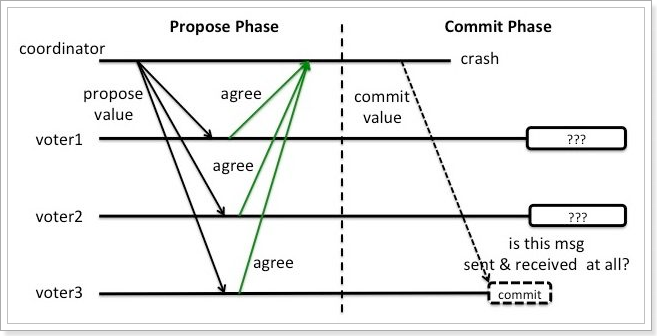
假设coordinator和voter3都在Commit这个阶段crash了, 而voter1和voter2没有收到commit消息. 这时候voter1和voter2就陷入了一个困境. 因为他们并不能判断现在是两个场景中的哪一种:
(1)上轮全票通过然后voter3第一个收到了commit的消息并在commit操作之后crash了
(2)上轮voter3反对所以干脆没有通过.
- 阻塞问题
在准备阶段、提交阶段,每个事物参与者都会锁定本地资源,并等待其它事务的执行结果,阻塞时间较长,资源锁定时间太久,因此执行的效率就比较低了。
-
TCC模式
TCC模式可以解决2PC中的资源锁定和阻塞问题,减少资源锁定时间。
它本质是一种补偿的思路。事务运行过程包括三个方法,
- Try:资源的检测和预留;
- Confirm:执行的业务操作提交;要求 Try 成功 Confirm 一定要能成功;
- Cancel:预留资源释放。
执行分两个阶段:
- 准备阶段(try):资源的检测和预留;
- 执行阶段(confirm/cancel):根据上一步结果,判断下面的执行方法。如果上一步中所有事务参与者都成功,则这里执行confirm。反之,执行cancel
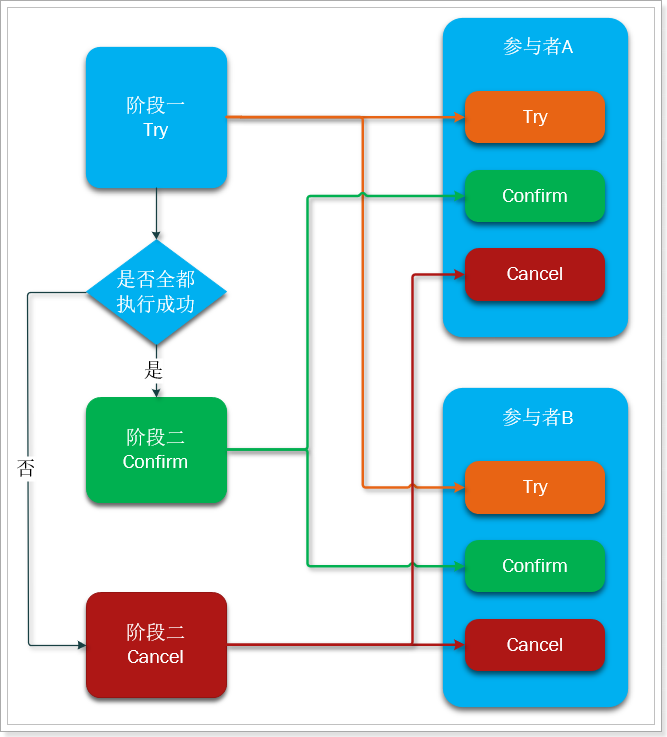
粗看似乎与两阶段提交没什么区别,但其实差别很大:
- try、confirm、cancel都是独立的事务,不受其它参与者的影响,不会阻塞等待它人
- try、confirm、cancel由程序员在业务层编写,锁粒度有代码控制
下单业务中的扣减余额为例来看下怎么编写,假设账户A原来余额是100,需要余额扣减30元。如图:

- 一阶段(Try):余额检查,并冻结用户部分金额,此阶段执行完毕,事务已经提交
- 检查用户余额是否充足,如果充足,冻结部分余额
- 在账户表中添加冻结金额字段,值为30,余额不变
- 二阶段
- 提交(Confirm):真正的扣款,把冻结金额从余额中扣除,冻结金额清空
- 修改冻结金额为0,修改余额为100-30 = 70元
- 补偿(Cancel):释放之前冻结的金额,并非回滚
- 余额不变,修改账户冻结金额为0
-
- 优势
TCC执行的每一个阶段都会提交本地事务并释放锁,并不需要等待其它事务的执行结果。而如果其它事务执行失败,最后不是回滚,而是执行补偿操作。这样就避免了资源的长期锁定和阻塞等待,执行效率比较高,属于性能比较好的分布式事务方式。
-
- 缺点
- 代码侵入:需要人为编写代码实现try、confirm、cancel,代码侵入较多
- 开发成本高:一个业务需要拆分成3个步骤,分别编写业务实现,业务编写比较复杂
- 安全性考虑:cancel动作如果执行失败,资源就无法释放,需要引入重试机制,而重试可能导致重复执行,还要考虑重试时的幂等问题
-
- 使用场景
- 对事务有一定的一致性要求(最终一致)
- 对性能要求较高
- 开发人员具备较高的编码能力和幂等处理经验
-
可靠消息服务
一般分为事务的发起者A和事务的其它参与者B:
- 事务发起者A执行本地事务
- 事务发起者A通过MQ将需要执行的事务信息发送给事务参与者B
- 事务参与者B接收到消息后执行本地事务
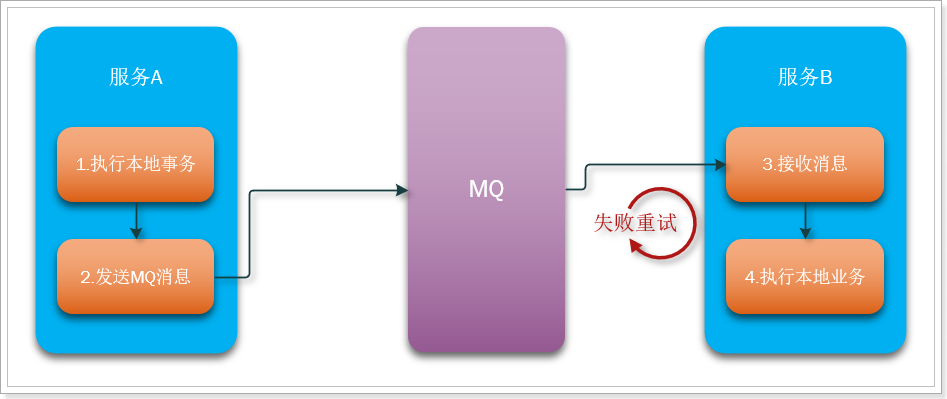
这个过程有点像你去学校食堂吃饭:
- 拿着钱去收银处,点一份红烧牛肉面,付钱
- 收银处给你发一个小票,还有一个号牌,你别把票弄丢!
- 你凭小票和号牌一定能领到一份红烧牛肉面,不管需要多久
几个注意事项:
- 事务发起者A必须确保本地事务成功后,消息一定发送成功
- MQ必须保证消息正确投递和持久化保存
- 事务参与者B必须确保消息最终一定能消费,如果失败需要多次重试
- 事务B执行失败,会重试,但不会导致事务A回滚
那么问题来了,我们如何保证消息发送一定成功?如何保证消费者一定能收到消息?
-
-
本地消息表
-
简化版:
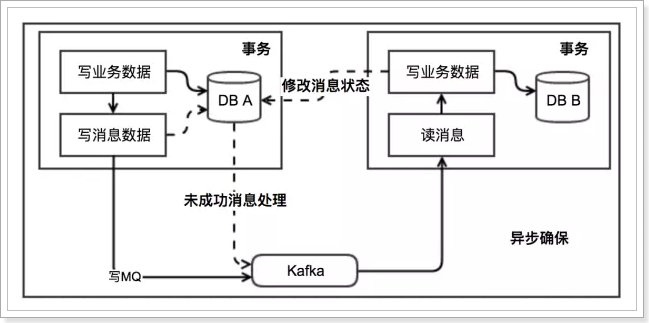
- 事务发起者:
- 开启本地事务
- 执行事务相关业务
- 发送消息到MQ
- 把消息持久化到数据库,标记为已发送
- 提交本地事务
- 事务接收者:
- 接收消息
- 开启本地事务
- 处理事务相关业务
- 修改数据库消息状态为已消费
- 提交本地事务
- 额外的定时任务
- 定时扫描表中超时未消费消息,重新发送
优点:
- 与tcc相比,实现方式较为简单,开发成本低。
缺点:
- 数据一致性完全依赖于消息服务,因此消息服务必须是可靠的。
- 需要处理被动业务方的幂等问题
- 被动业务失败不会导致主动业务的回滚,而是重试被动的业务
- 事务业务与消息发送业务耦合、业务数据与消息表要在一起
-
-
独立消息服务
-
为了解决上述问题,我们会引入一个独立的消息服务,来完成对消息的持久化、发送、确认、失败重试等一系列行为,大概的模型如下:
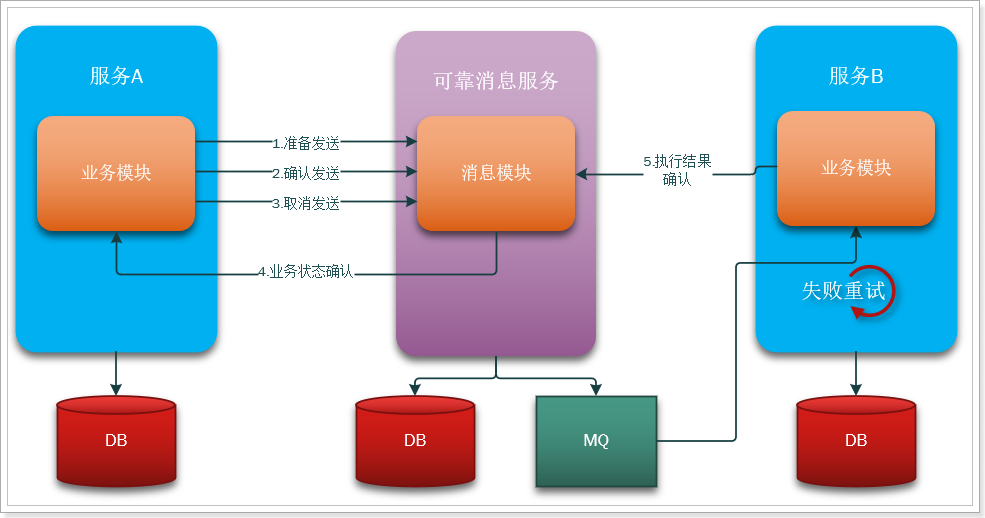
一次消息发送的时序图:
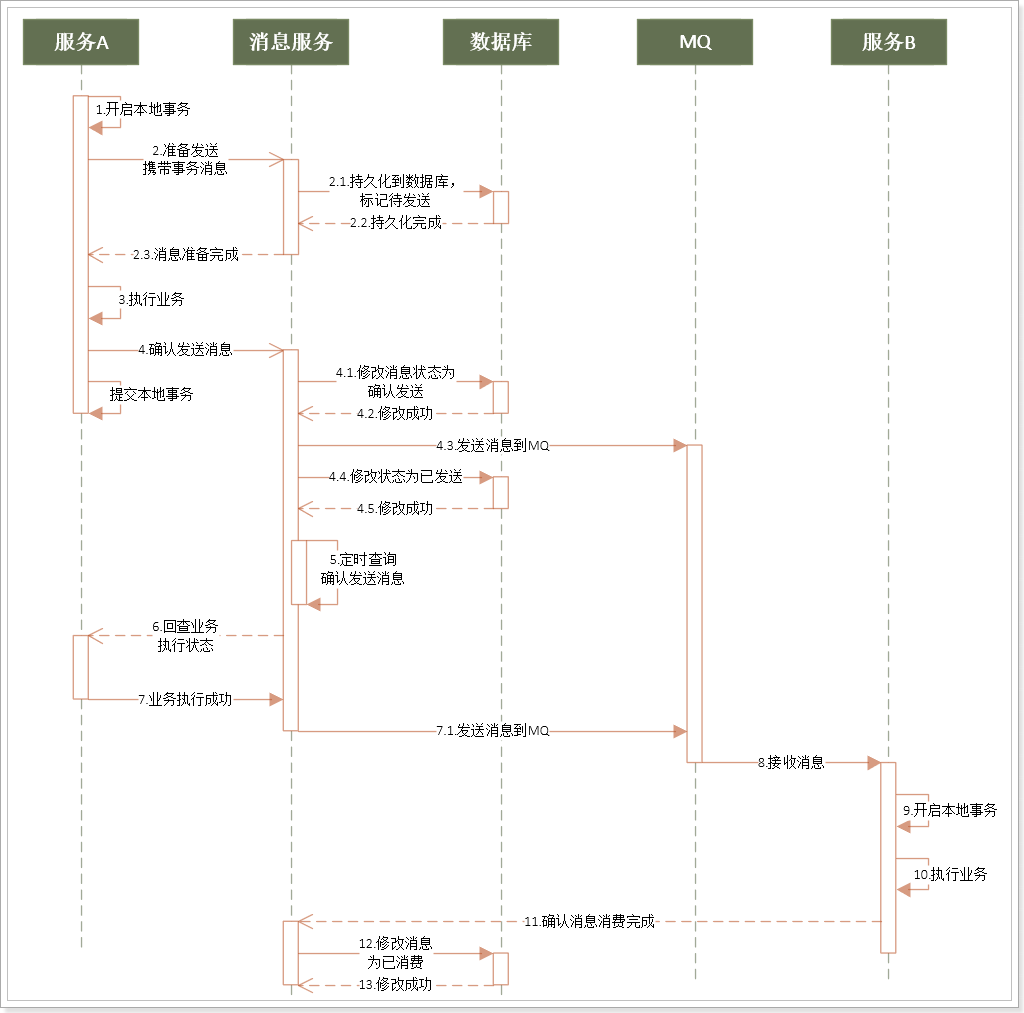
事务发起者A的基本执行步骤:
- 开启本地事务
- 通知消息服务,准备发送消息(消息服务将消息持久化,标记为准备发送)
- 执行本地业务,
- 执行失败则终止,通知消息服务,取消发送(消息服务修改订单状态)
- 执行成功则继续,通知消息服务,确认发送(消息服务发送消息、修改订单状态)
- 提交本地事务
消息服务本身提供下面的接口:
- 准备发送:把消息持久化到数据库,并标记状态为准备发送
- 取消发送:把数据库消息状态修改为取消
- 确认发送:把数据库消息状态修改为确认发送。尝试发送消息,成功后修改状态为已发送
- 确认消费:消费者已经接收并处理消息,把数据库消息状态修改为已消费
- 定时任务:定时扫描数据库中状态为确认发送的消息,然后询问对应的事务发起者,事务业务执行是否成功,结果:
- 业务执行成功:尝试发送消息,成功后修改状态为已发送
- 业务执行失败:把数据库消息状态修改为取消
事务参与者B的基本步骤:
- 接收消息
- 开启本地事务
- 执行业务
- 通知消息服务,消息已经接收和处理
- 提交事务
优点:
- 解除了事务业务与消息相关业务的耦合
缺点:
- 实现起来比较复杂
-
-
RabbitMQ的消息确认
-
RabbitMQ确保消息不丢失的思路比较奇特,并没有使用传统的本地表,而是利用了消息的确认机制:
- 生产者确认机制:确保消息从生产者到达MQ不会有问题
- 消息生产者发送消息到RabbitMQ时,可以设置一个异步的监听器,监听来自MQ的ACK
- MQ接收到消息后,会返回一个回执给生产者:
- 消息到达交换机后路由失败,会返回失败ACK
- 消息路由成功,持久化失败,会返回失败ACK
- 消息路由成功,持久化成功,会返回成功ACK
- 生产者提前编写好不同回执的处理方式
- 失败回执:等待一定时间后重新发送
- 成功回执:记录日志等行为
- 消费者确认机制:确保消息能够被消费者正确消费
- 消费者需要在监听队列的时候指定手动ACK模式
- RabbitMQ把消息投递给消费者后,会等待消费者ACK,接收到ACK后才删除消息,如果没有接收到ACK消息会一直保留在服务端,如果消费者断开连接或异常后,消息会投递给其它消费者。
- 消费者处理完消息,提交事务后,手动ACK。如果执行过程中抛出异常,则不会ACK,业务处理失败,等待下一条消息
经过上面的两种确认机制,可以确保从消息生产者到消费者的消息安全,再结合生产者和消费者两端的本地事务,即可保证一个分布式事务的最终一致性。
-
AT模式
基本原理:
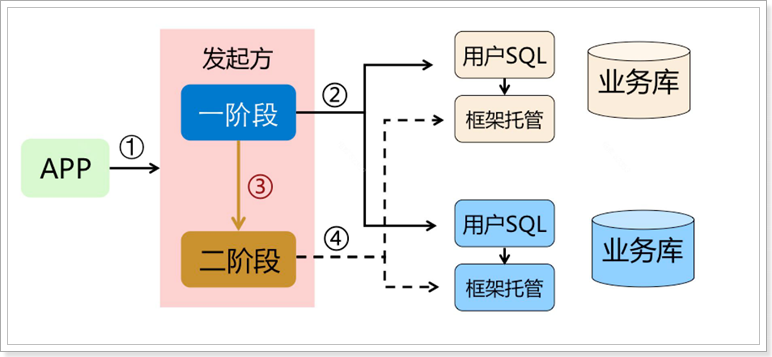
有没有感觉跟TCC的执行很像,都是分两个阶段:
- 一阶段:执行本地事务,并返回执行结果
- 二阶段:根据一阶段的结果,判断二阶段做法:提交或回滚
但AT模式底层做的事情可完全不同,而且第二阶段根本不需要我们编写,全部有Seata自己实现了。也就是说:我们写的代码与本地事务时代码一样,无需手动处理分布式事务。
一阶段:
在一阶段,Seata 会拦截“业务 SQL”,首先解析 SQL 语义,找到“`业务 SQL`”要更新的业务数据,在业务数据被更新前,将其保存成“`before image`”,然后执行“`业务 SQL`”更新业务数据,在业务数据更新之后,再将其保存成“`after image`”,最后获取全局行锁,**提交事务**。以上操作全部在一个数据库事务内完成,这样保证了一阶段操作的原子性。
这里的`before image`和`after image`类似于数据库的undo和redo日志,但其实是用数据库模拟的。

二阶段提交
二阶段如果是提交的话,因为“`业务 SQL`”在一阶段已经提交至数据库, 所以 Seata 框架只需将一阶段保存的快照数据和行锁删掉,完成数据清理即可。
二阶段回滚:
二阶段如果是回滚的话,Seata 就需要回滚一阶段已经执行的“`业务 SQL`”,还原业务数据。回滚方式便是用“`before image`”还原业务数据;但在还原前要首先要校验脏写,对比“数据库当前业务数据”和 “`after image`”,如果两份数据完全一致就说明没有脏写,可以还原业务数据,如果不一致就说明有`脏写`,出现脏写就需要转人工处理。
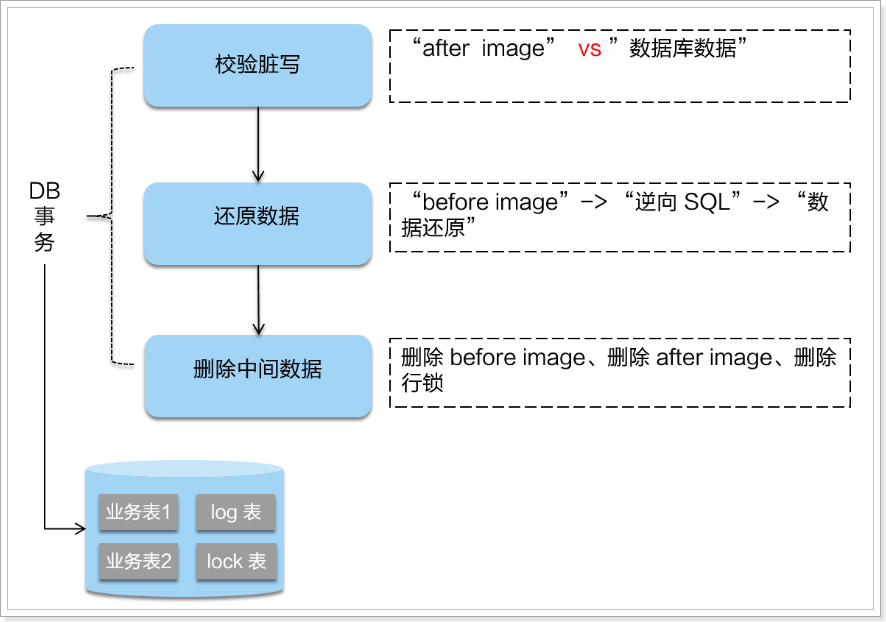
不过因为有全局锁机制,所以可以降低出现`脏写`的概率。
AT 模式的一阶段、二阶段提交和回滚均由 Seata 框架自动生成,用户只需编写“业务 SQL”,便能轻松接入分布式事务,AT 模式是一种对业务无任何侵入的分布式事务解决方案。
Seata的详细流程不做赘述。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号