kafka删除topic的方法及我在kafka上边的一些经验
 kafka删除topic的方法
kafka删除topic的方法
0.8的官方文档提供了一个删除topic的命令:
kafka-topics.sh --delete 但是在运行时会报错找不到这个方法。
kafka-topics.sh最终是运行了kafka.admin.TopicCommand这个类,在0.8的源码中这个类中没有找到有delete topic相关的代码。
在kafka的admin包下,提供了一个DeleteTopicCommand的类,可以实现删除topic的功能。
kafka.admin.DeleteTopicCommand
其中删除topic的具体实现代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
import org.I0Itec.zkclient.ZkClientimport kafka.utils.{Utils, ZKStringSerializer, ZkUtils}....... val topic = options.valueOf(topicOpt) val zkConnect = options.valueOf(zkConnectOpt) var zkClient: ZkClient = null try { zkClient = new ZkClient(zkConnect, 30000, 30000, ZKStringSerializer) zkClient.deleteRecursive(ZkUtils.getTopicPath(topic)) //其实最终还是通过删除zk里面对应的路径来实现删除topic的功能 println("deletion succeeded!") } catch { case e: Throwable => println("delection failed because of " + e.getMessage) println(Utils.stackTrace(e)) } finally { if (zkClient != null) zkClient.close() } |
因为这个命令只会删除zk里面的信息,真实的数据还是没有删除,所以需要登录各个broker,把对应的topic的分区数据目录删除,也可能正因为这一点,delete命令才没有集成到kafka.admin.TopicCommand这个类。
本文出自 “菜光光的博客” 博客,请务必保留此出处http://caiguangguang.blog.51cto.com/1652935/1548069
-------------------------------------------------------------------------------------------------------------------------------
kafka-topics.sh --delete 但是在运行时会报错找不到这个方法。
kafka-topics.sh最终是运行了kafka.admin.TopicCommand这个类,在0.8的源码中这个类中没有找到有delete topic相关的代码。
在kafka的admin包下,提供了一个DeleteTopicCommand的类,可以实现删除topic的功能。
kafka.admin.DeleteTopicCommand
其中删除topic的具体实现代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
import org.I0Itec.zkclient.ZkClientimport kafka.utils.{Utils, ZKStringSerializer, ZkUtils}....... val topic = options.valueOf(topicOpt) val zkConnect = options.valueOf(zkConnectOpt) var zkClient: ZkClient = null try { zkClient = new ZkClient(zkConnect, 30000, 30000, ZKStringSerializer) zkClient.deleteRecursive(ZkUtils.getTopicPath(topic)) //其实最终还是通过删除zk里面对应的路径来实现删除topic的功能 println("deletion succeeded!") } catch { case e: Throwable => println("delection failed because of " + e.getMessage) println(Utils.stackTrace(e)) } finally { if (zkClient != null) zkClient.close() } |
因为这个命令只会删除zk里面的信息,真实的数据还是没有删除,所以需要登录各个broker,把对应的topic的分区数据目录删除,也可能正因为这一点,delete命令才没有集成到kafka.admin.TopicCommand这个类。
在zookeeper上删除数据:用zookeeper客户端zkClient连接zookeeper,如:
./zkCli.sh -server 192.165.1.91:12181 此处最好只连接本机的zookeeper:端口,即在集群中每台机器上单独操作!!!
连接上后,可以用命令查看zk的目录结构
ls /brokers/topics
然后可以看到该目录下有test5目录 tab 补全 ls 发现下边有 (0,1) 字样 ,这是说test5 有俩个分区 然后以以下方式层层递减删除他...
删除方式:
delete /brokers/topics/test5/partitions/0/state
delete /brokers/topics/test5/partitions/1/state
delete /brokers/topics/test5/partitions/0
delete /brokers/topics/test5/partitions/1
delete /brokers/topics/test5/partitions
delete /brokers/topics/test5
===========停止kafka和zookeeper========================
a.查看server.properties中配置的log.dirs路径
b.进入到此路径中(如果kafka是一个集群,需要在每台机器上执行)

假定要删除的topic名称叫做:test5
vi replication-offset-checkpoint
原文为:

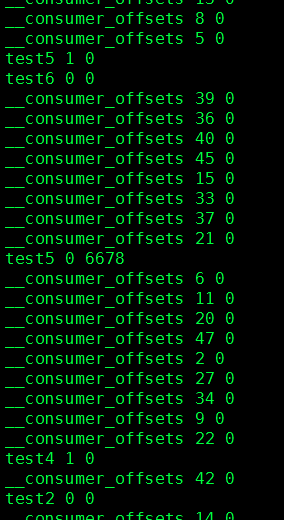
像我本地,是要全都删除的,直接改为:
0
同理修改
===========启动kafka和zookeeper========================此时,已修改好;
创建集群的时候要注意:kafka的日志清理
kafka将会保留所有发布的消息,不论他们是否被消费过
如果需要清理,则需要进行配置;
server.properties配置:
log.cleanup.policy=delete
日志清理策略
log.retention.hours=168 (即7天)
数据存储的最大时间超过这个时间会根据log.cleanup.policy设置的策略处理数据,也就是消费端能够多久去消费数据
log.retention.bytes和log.retention.minutes任意一个达到要求,都会执行删除
log.retention.bytes=-1
topic每个分区的最大文件大小
一个topic的大小限制=分区数*log.retention.bytes
-1表示没有大小限制
log.retention.bytes和log.retention.minutes任意一个达到要求,都会执行删除
log.retention.check.interval.ms=5minutes
文件大小检查的周期时间
3.kafka的分布式
一个日志的多个partition被分散在kafka集群的多个server上,并且每一个server处理来自于某个partition的数据请求。每个partition可以配置副本个数(即备份),以便容错。
(注:在创建topic时,可以指定--replication-factor参数)
每个partition都有一个server作为leader,并且有0或者多个server作为followers。leader处理对于这个partition的所有读写请求,而followers则被动的复制一切。如果leader挂掉了,一个followers则会自动的成为新的leader。每个server都会在某些partition上作为leader,而在另一些partition上作为follower,所以整个集群是非常平衡的。
(注:如果topic的repliation配置为1,则每个partition就只有唯一的一个leader,没有follower;所以要保证容错性,至少replication应该配置为2)这块我还没有闹懂,我现在的程序中是没有备份的,在另外一套系统中跑的程序入库,,然后另一套做实时展示计算;
4.kafka 的负载均衡问题 producer操作的时候,最好使用轮询的方式向topic写数据,保证topic每个partition的负载是均衡的,之前用的是默认的(随机算法),我现场用的是俩个分区,三台机器组成一个集群,结果一台机器的一个分区里边已经有10亿条数据了,集群中的另一台机器的分区中才只有8亿多一点,,,所以说最好用轮询,也有用hash的,但是为了负载均衡保证消费的高可用,(现场消费一般都是分组消费,consumer在消费的时候一般都是均衡的在broker上去取数据),,所以我个人极力鼓励用轮询来处理数据的分区的问题;省事,安全,不用去考虑负载不均衡带来的其他问题.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号