eclipse中使用Hadoop插件
一、准备
1.1 下载插件
链接: https://pan.baidu.com/s/15ol7KuQ4mNeAro_pCTnjDA 提取码: 7fq3
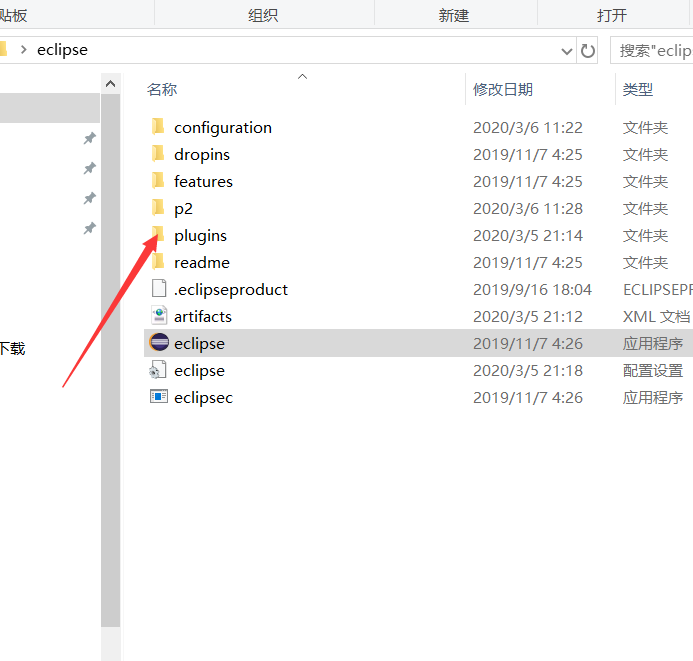
1.1.1 将hadoop-eclipse-plugin-2.7.3.jar 放到eclipse的plugins中
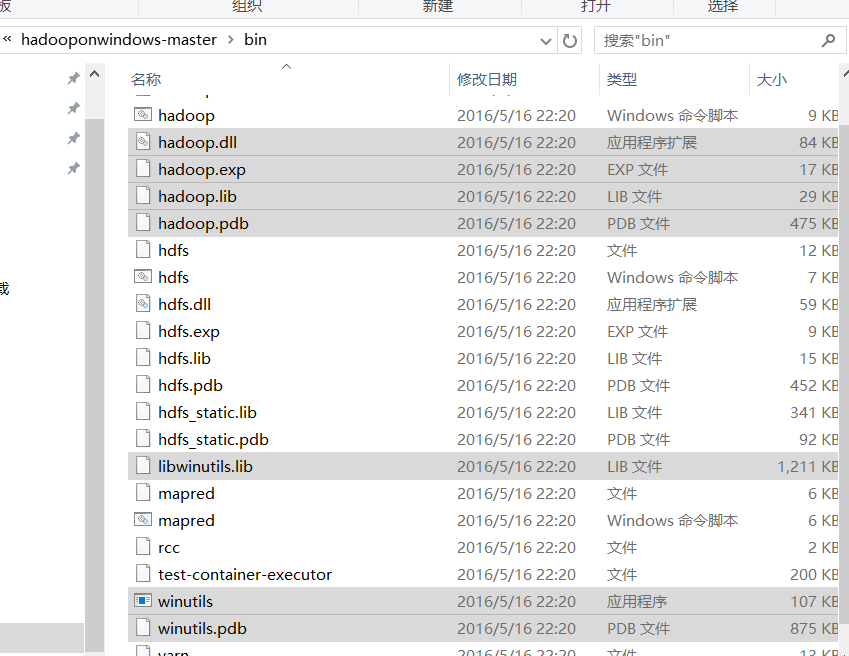
1.1.2 把编译后的文件放到hadoop中的bin目录下
1.1.3 配置环境变量
创建 HADOOP_HOME=C:\Users\123\Desktop\HADOOP\hadoop-2.7.7(hadoop的安装目录)
PATH:添加

二、在eclipse中操作
2.1 Windows-->preferences
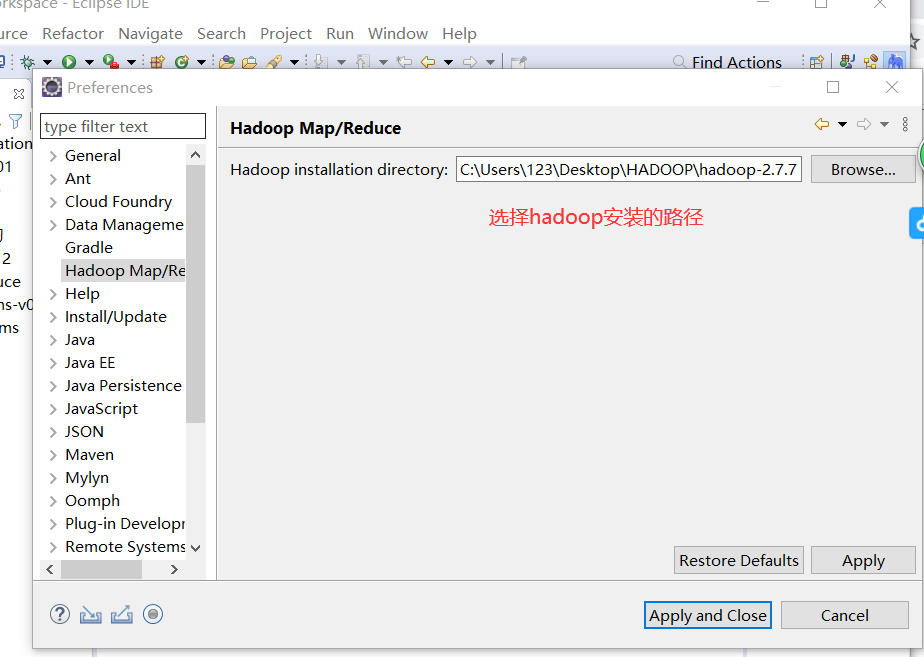
没有插件需重启eclipse
2.2 切换Map/Reduce视图

2.3 新建连接


2.4 打开HDFS的权限
将程序开发完成之后,直接将项目打包,然后rz到HDFS上执行
默认开启
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
三、MapReduce的简单案列
3.1 数据模拟
package com.blb; import java.io.BufferedWriter; import java.io.File; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; import java.io.OutputStreamWriter; import java.util.ArrayList; import java.util.Random; public class bill { private static Random random = new Random(); private static ArrayList<String> bashList = new ArrayList(); private static ArrayList<String> bedList = new ArrayList(); private static ArrayList<String> homeList = new ArrayList(); static { bashList.add("牙刷"); bashList.add("牙膏"); bashList.add("杯子"); bashList.add("脸盆"); bashList.add("肥皂"); bashList.add("沐浴露"); bashList.add("洗发水"); bedList.add("被套"); bedList.add("棉被"); bedList.add("床垫"); bedList.add("枕巾"); homeList.add("插板"); homeList.add("微波炉"); homeList.add("电磁炉"); homeList.add("电烤箱"); homeList.add("灯泡"); homeList.add("烧水壶"); } //用于判断是否需要代购商品【随机】 public static boolean isNeed() { int ran = random.nextInt(1000); if(ran % 2 == 0) { return true; } return false; } //用于判断代购的产品需要多少【随机】 public static int needCount(int num) { return random.nextInt(num); } //生成300个清单 public static void main(String[] args) throws FileNotFoundException, IOException { for(int i = 0; i < 300; i++) { /** * 输出文件要用输出流 * 特别注意: * I/O流: * 字节流:InputStream,OutPutStream * 字符流:Reader,Writer * 转换流:将字节流转换为字符流 BufferWrite,BufferReader * 字节流和字符流没有提供输出文件的编码格式 * 转换流可以设置输出文件的编码格式 */ FileOutputStream out = new FileOutputStream(new File("D:\\temp\\"+i+".txt")); //使用转换流,设置输出文件的编码格式 BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(out, "UTF-8")); //先看是否需要第一种代购商品【洗漱用品】 boolean need1 = isNeed(); if(need1) { //需求的种类不超过所有的list int count = needCount(bashList.size() + 1); //循环随机获取商品和数量 for(int j = 0; j < count; j++) { //随机获取商品 String product = bashList.get(random.nextInt(bashList.size())); //随机获取数量[1-6] int num = needCount(6)+1; //写入文件 writer.write(product + "\t" +num); //换行 writer.newLine(); } } //看是否需要第二种代购商品【床上用品】 boolean need2 = isNeed(); if(need2) { //需求的种类不超过所有的list int count = needCount(bedList.size() + 1); //循环随机获取商品和数量 for(int j = 0; j < count; j++) { //随机获取商品 String product = bedList.get(random.nextInt(bedList.size())); //随机获取数量[0-3] int num = needCount(3); //写入文件 writer.write(product + "\t" +num); //换行 writer.newLine(); } } //看是否需要第三种代购商品【家用电器】 boolean need3 = isNeed(); if(need3) { //需求的种类不超过所有的list int count = needCount(homeList.size() + 1); //循环随机获取商品和数量 for(int j = 0; j < count; j++) { //随机获取商品 String product = homeList.get(random.nextInt(homeList.size())); //随机获取数量[1-4] int num = needCount(4)+1; //写入文件 writer.write(product + "\t" +num); //换行 writer.newLine(); } } writer.flush(); writer.close(); } } }

3.2将模拟数据上传到HDFS
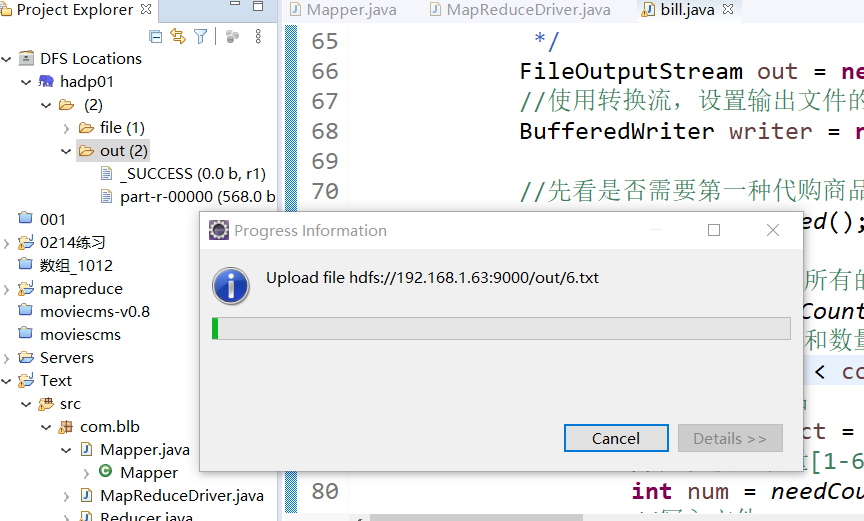
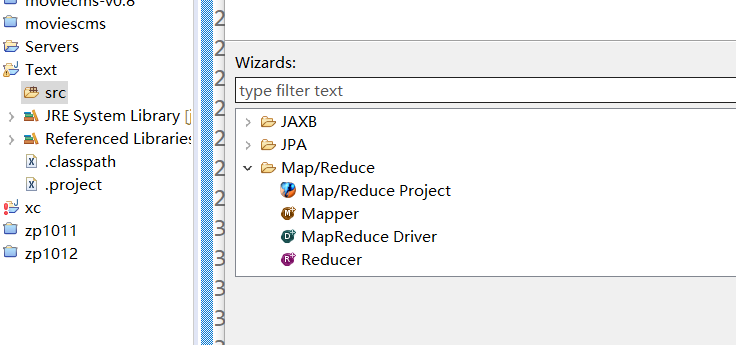
3.3创建MapReduce项目
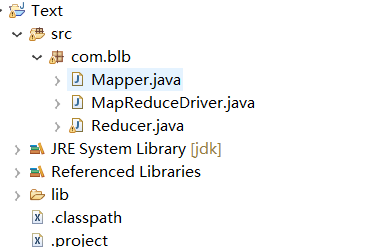
3.4创建Map类,Reduce类,Driver类
3.5 Map代码
public class CountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { public void map(LongWritable ikey, Text ivalue, Context context) throws IOException, InterruptedException { //读取一行的文件 String line = ivalue.toString(); //进行字符串的切分 String[] split = line.split("\t"); //写入 context.write(new Text(split[0]), new IntWritable(Integer.parseInt(split[1]))); } }
3.6 Reduce代码
public class CountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(Text _key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { // process values int sum=0; for (IntWritable val : values) { int i = val.get(); sum+=i; } context.write(_key,new IntWritable(sum)); }
3.7Driver代码
public class MapReduceDriver { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); //配置服务器的端口和地址 conf.set("fs.defaultFS", "hdfs://192.168.1.63:9000"); Job job = Job.getInstance(conf, "MapReduceDriver"); job.setJarByClass(com.blb.MapReduceDriver.class); // TODO: specify a mapper job.setMapperClass(CountMapper.class); // TODO: specify a reducer job.setReducerClass(CountReducer.class); //如果reducer的key类型和map的key类型一样,可以不写map的key类型 //如果reduce的value类型和map的value类型一样,可以不写map的value类型 // TODO: specify output types job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // TODO: specify input and output DIRECTORIES (not files) FileInputFormat.setInputPaths(job, new Path("/upload/")); FileOutputFormat.setOutputPath(job, new Path("/outupload/")); // job.waitForCompletion(true); if (!job.waitForCompletion(true)) return; } }
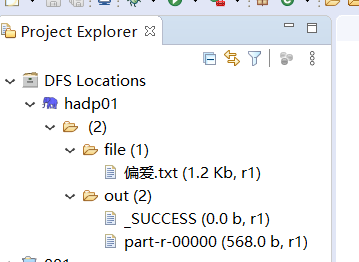
3.8最终结果

四、可能出现的一些问题
参考:https://blog.csdn.net/congcong68/article/details/42043093

 浙公网安备 33010602011771号
浙公网安备 33010602011771号