Hadoop的完全分布式搭建
一、准备虚拟机两台
1.将虚拟机进行克隆https://www.cnblogs.com/the-roc/p/12336745.html
2.1将克隆虚拟机的IP修改一下
vi /etc/sysconfig/network-scripts/ifcfg-ens33

完成后:systemctl restart network
2.2 修改主机名
vim /etc/hostname
reboot 重启生效
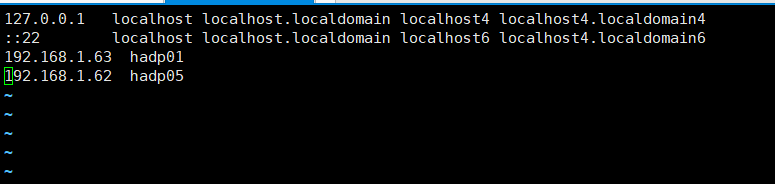
2.3修改ip与主机映射
vim /etc/hosts
reboot 重启
二、开始完全分布式搭建
1.1先清空克隆机dfs文件夹的内容
cd /opt/software//hadoop-2.7.7/tmp/dfs/
删除所有 rm -rf *
1.2在原机上添加从节点ip映射
vim /etc/hosts

1.3做ssh免密
生成密钥对 ssh-keygen
ssh-copy-id hdp05
1.4修改hdfs-site.xfs
两台虚拟机都需要修改
vim /opt/software/hadoop-2.7.7/etc/hadoop/hdfs-site.xml
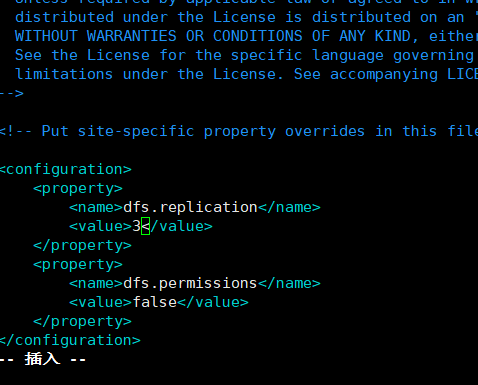
1.5把从节点别名加主节点的slaves 配置中
vim /opt/software/hadoop-2.7.7/etc/hadoop/slaves

1.6启动测试
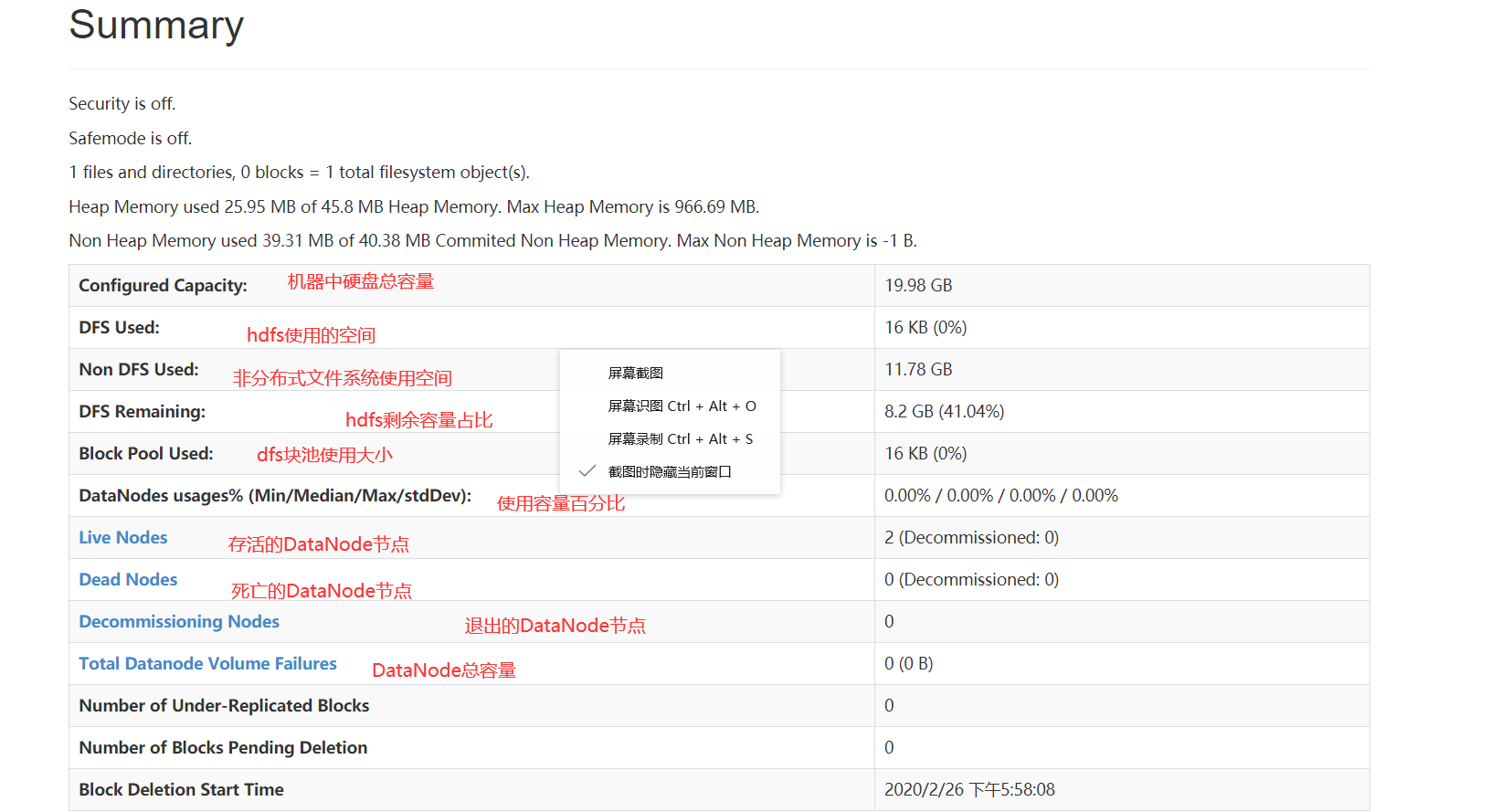
start-dfs.sh(主节点启动,从节点也会启动DataNode)
http://主机ip :50070 进入网页如图
三.sbin下的脚本启动
1.start-all.sh/stop-all.sh
启动/停止所有(5个)的软件【NameNode,DataNode,secondarynamenode,nodemanager,resourcesmanager】
2.start-dfs.sh/stop-dfs.sh
一次性启动/停止3个软件【NameNode,DataNode,secondarymanager】
3.start-yarn.sh/stop-yarn.sh【MapReduce使用】
一次性启动/停止2个软件【nodemanager,resourcesmanager】
4.hadoop-daemon.sh start XXX
只想启动/停止其中某一个软件【NameNode,DataNode,secondarymanager】
5.yarn-daemon.sh start XXX
只想启动/停止其中某一个软件【nodemanager,resourcesmanager】

 浙公网安备 33010602011771号
浙公网安备 33010602011771号