
R-CNN,SSP-NET,Fast-RCNN,Faster-RCNN笔记
之前总结了yolo和SSD系列方法,今天简单介绍下RCNN,SSP-NET,Fast-RCNN,Faster-RCNN系列方法。毕竟已将发展到Faster-RCNN了,会在下一篇附上Faster-RCNN详细介绍及tensorflow源码解析
RCNN
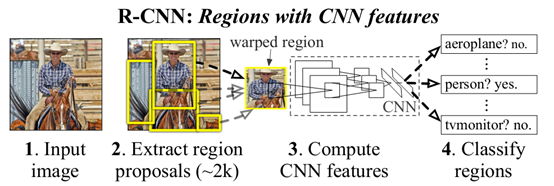
具体过程如下:
- 产生region proposals。使用的方法为selective search(需使用CPU,所以会限制速度),大约为2K的数量级。
- 特征提取。将产生的region proposals resize成统一格式(227X227),之后通过CNN网络,每一个region proposals产生1个4096维向量
- 之后使用SVM分别对类别和位置进行训练和预测。
此处重点叙述下训练中需要注意的点。
- 第一步使用selective search方法是需要使用逻辑判断的,只能用CPU来完成,所以速度比较慢,之后经过改良,发展到Faster-RCNN后会摒弃掉这种方法,所以这里也不解释这种方法了。(根据色块相似,形状相似等分割)
- 首先由于带ground truth的训练数据少,所以会先用其他数据集进行监督预训练,使用的网络结构为VGG-16或者Alexnet。之后便是使用第一步产生的region proposals进行Fine-tun,先统一大小,之后输入到网络中进行训练,此时学习率会设置得比较小。优化方法为SGD,IOU大于0.5的为正类,其余为负类,不同的数据集有不同的类别,一般为21类(20+背景)。
- 使用SVM进行分类。此时IOU大于0.3的为正类,其余为负类,对每一类别分别训练一个分类器,对得到的图片进行打分,按照分数使用NMS进行筛选,之后使用脊回归对位置框进行精修。
- 非端到端预测,前面对图片进行拉伸等格式调整,大大降低了准确性。对Selective Search 出来的图片分别输入CNN网络提取特征,对每一类分别训练一个SVM分类器,导致训练成本高,流程长。此后主要对这几点进行了改进。
SSP-net
Ssp-net 主要解决一个问题,就是R-CNN中需要将产生的region proposal进行resize才能输入CNN网络进行特征提取。SSP-net提出ROI池化概念,不需要重新resize,可直接提取并产生特定维度的向量。此方法使得端到端训练成为可能。可直接在整幅图上做卷积,之后通过ROI池化对Selective Search出的图片(直接算经过网络后的坐标,然后对应到经过网络后的整幅图片具体位置,就可以提取经CNN后的物体位置)提取同样大小的特征。如下图:

先解释下何为ROI池化,对于一个图片,不管大小,都可将其分为SXS份,之后对每一份内的小方格特征进行最大池化,又称为金字塔结构。这样只剩下一个方格,这样这幅图片就会产生SXS维特征,如下图;
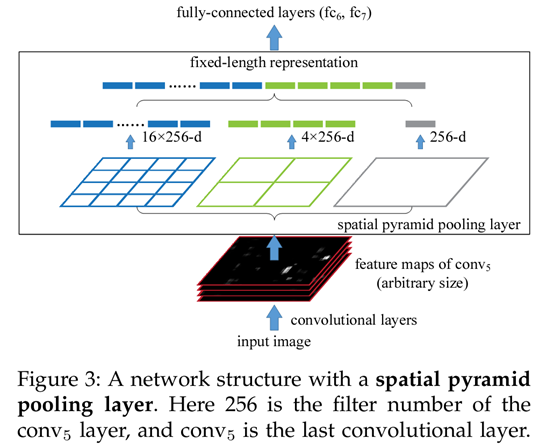
具体到SSP-net中,流程如下:
- 将图片输入CNN网络中,提取特征。注意论文采用的是多尺寸输入,每次训练一个尺寸。使用多尺寸输入的好处是使得模型泛化能力更强。.
- 使用selctive search方法产生porpose的坐标,并将其对应到通过CNN后该部分的对应坐标,之后经过ROI池化后可得同一维度的向量。
- 之后使用SVM进行类别分类和坐标回归。此部分与R-CNN一样
Fast-RCNN

Fast-RCNN吸取了SSP-net中的倒金字塔结构,加入了ROI池化层(生成7X7大小的方格),这样就不必再对产生的propose进行resize,最后分类时直接采用了CNN进行分类和预测框回归。还强调了使用SVD来优化计算。
训练流程:
- 将图片及selective search 的坐标输入预训练后的CNN网络。
- 对经过CNN处理的特征框进行ROI池化,得到HXW(7X7XC)维度的向量,并拍平(FC)
- 输出为两条线,一条使用softmax分类,求类别,另外一条使用NMS后根据类别概率分别求预测框偏差回归
感觉是整合了前两种方法,同时创新点为舍弃SVM,直接使用CNN网络进行分类和坐标框回归。真正做到端到端训练预测。
说一下损失函数定义:

其中坐标框回归函数使用L1正则,定义如下

Faster-RCNN
详细介绍下Faster-RCNN,之后会附上tensorflow版复现。
Faster-RCNN真正实现了完全端到端训练。分为两部分,一部分为RPN网络,用于产生所需的propose,此方法可使用GPU来运行,大大减少运行时间。第二部分为Fast-RCNN网络,可使用1产生的propose用于分类及预测框位置估计。引用别人做的一幅图来叙述总体流程:

RPN部分
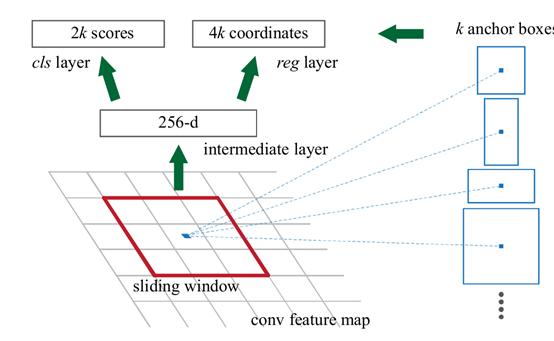
此部分吸收了yolo算法滑动窗口概念。将卷积后的图片,每个点产生若干个anchor,每个anchor分别产生两个预测结果,一个是类别预测(2类,背景或者物体),一个是预测框坐标回归预测,以此产生最终的proposes. 此分类和坐标框回归是粗分类,并不需要特别精确
Fast-RCNN部分
经过第一步产生porposesz之后,其余就和Fast-RCNN类似了,经过ROI池化层,获取特定维度的特征向量,之后进行类别预测与位置预测。
训练过程比较复杂,我没有对其进行过完整训练,引用知乎上 晓雷的一张图片,来叙述下训练过程:
1. 先训练RPN网络
2. 训练Fast-RCNN网络.这两步两种网络参数不共享。
3. 使用Fast-RCNN部分参数对RPN网络进行初始化,将两种网络共有部分参数固定,只优化RPN特有部分网络
4.将Fast-RCNN部分特有的网络加入到RPN结构中,即形成一个完整的大网络,继续训练,只训练Fast-RCNN特有的部分

引入损失函数定义:

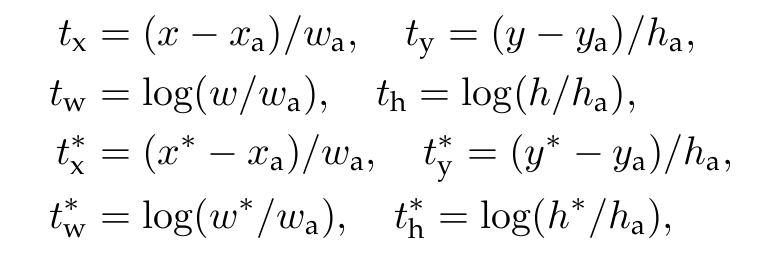
下面一篇文章会详细叙述Faster-RCNN并对其tensorflow代码进行分析

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步