
yolo算法笔记
Yolo算法笔记
目标检测方法yolo(You only look once),看一眼就可识别目标。与R-CNN比,有以下特点(Faster-RCNN 中RPN网络吸取了该特点):
- 速度很快
- 看到全局信息,而非R-CNN产生一个个切割的目标,由此对背景的识别效率很高
- 可从产生的有代表性的特征中学习。
流程:
以PASCAL VOC数据集为例。
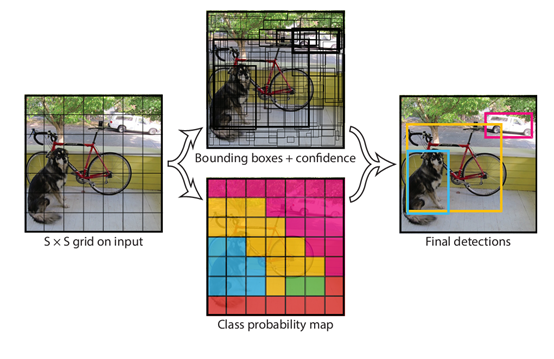
1. 输入448X448大小的图片,通过预训练的卷积网络(VGG系列等)对特征进行提取(如图),最后输出7X7大小的网络单元。
2. 每个网络单元预测2个预测框(不同长宽比),每个预测框预测该部分内包含的物体位置,分类和置信度预测。所以整体数据维度为7X7X(2*(4+1)+20 ). 其中每个预 测单元包括4个位置信息(x,y,w,h),1个置信度(与真实物体的IOU),20个类别信息为两个预测框共有。
3. 如果该物体中心在该预测框内,则包含该物体。置信度为IOU*预测框包含物体的概率,其中每个预测框的置信度与类别信息相乘,得到类别置信度。之后对所有的 预测框,根据类别置信度进行NMS。
NMS过程:对每一个类别,将类别置信度小于0.2的预测框得分设置为0,对置信度按从大到小排序,将最大的保留,之后每一个预测框计算与最大置信度预测框计算IOU,将IOU大于0.5的预测框得分设置为0。最后部分即为预测,损失函数如下(与RCNN相比略微复杂,之后的系列逐渐趋同):

训练时现在ImageNet上进行了预训练,网络使用途中网络前20个卷积层加一个平局池化和全连接层。预训练之后,加上随机初始化的4个卷积层和2个全连接层。

Yolov2/yolo9000
相对于yolov1,yolov2做了如下改进:
更好
- 设置BN层。防止梯度消失及爆炸。使数据分布更加相似,可提高训练速度及泛化性能。
- 更高精度。Yolov1使用224x224进行预训练,yolov2直接使用448x448进行预训练,之后在此基础上在进行fine-tun
- 去除FC层及最后pooling层,直接使用卷积层单元来预测,分成13x13(单数,因为发现大物体中心经常落在图片中心)。且引入anchor boxes概念, anchor boxes的数量及大小比例是通过聚类方式确定的。聚类后5为最优值
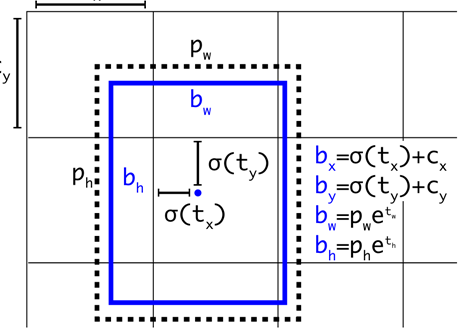
- 直接的位置预测。如下图,直接预测出边框位置。Tx等为归一化后的偏移,之后可直接算出预测框位置即Bx等(参考RCNN系列预测位置偏移)。
5 不同尺度的预训练,每隔10个epoch,输入图片尺度增加32{320,352,…608}
6 网络结构采用Fine-Grained Features,即采用不同的卷积特征层,以便提取不同精细度的特征。看源码含义为比如64*64可分为4个32*32然后叠加起来。与Faster-RCNN的跨层联结上有一点不同
更快
- 引入Darknet-19
- 分类和检测分开,分类时先使用224X224训练,之后将尺度改为448x448。之后检测时去掉网络最后一个卷积层,每个卷积层接3个3X3X1024 卷积,每个卷积接1X1卷积层。
更强
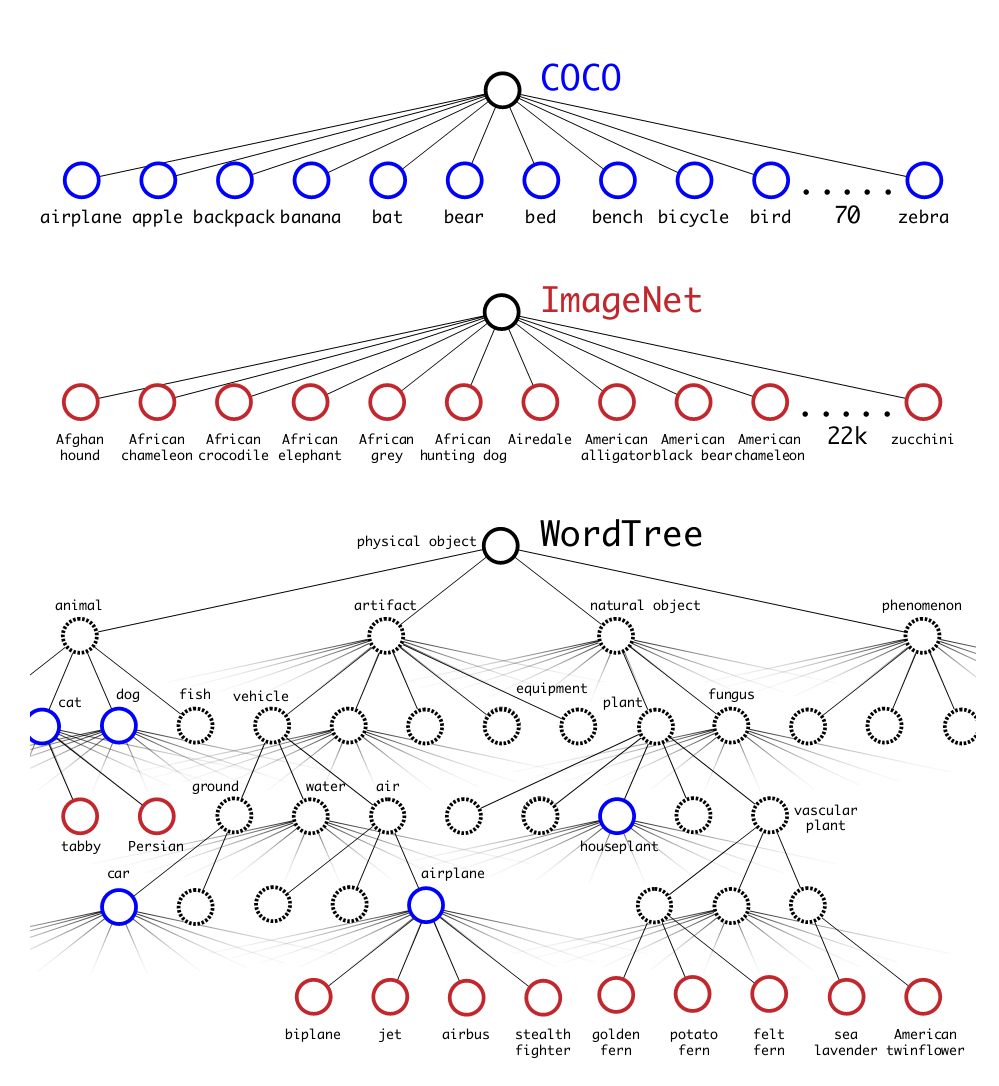
即能检测出9000个类别。对此段并不是很理解。翻译论文即采用树状结构,使用ImageNet(分类)和COCO(预测)联合训练。训练时,如果检测样本,按yolov2 loss计算误差,对分类样本,只计算分类误差。预测时,置信度为分类概率,同时会给出边界框位置寄一个树状概率图,在这个概率图中找到概率最高的路径,当达到某一阈值时停止,就用当前节点表示预测的类别。
Yolov3:
改进:
1. 引入残差网络,使用Darknet-53网络。
2. 采用3个不同尺度的卷积,yolov2是将两个尺度的特征图连接起来。yolov3为三个特征图,且做了不同处理。每个尺度的卷积图使用3个anchor。共3*3个anchor
3. 损失函数改进。类别预测由softmax改为n个sigmoid.
更像是对yolo系列算法的一个总结,整体突破不太大。下个会对yolov3的tensorflow/keras源码进行解析

