CNN基础模型总结
之前被问到了CNN类基础模型的一些特性,比如1X1卷积,还有经典卷积网络发展及为什么采用此结构,结果被问住了。学习过程中其实没有做过更深层次的思考,比如为什么会选择这种架构,可不可以采用其他结构来替换,只是会用一些经典模型。到最后别人问几个为什么就不知道了。基础还是要加强呀。现在先参考别人的专栏还有论文总结一下。
参考: https://www.cnblogs.com/guoyaohua/p/8534077.html https://zhuanlan.zhihu.com/p/50754671
LeNet-5
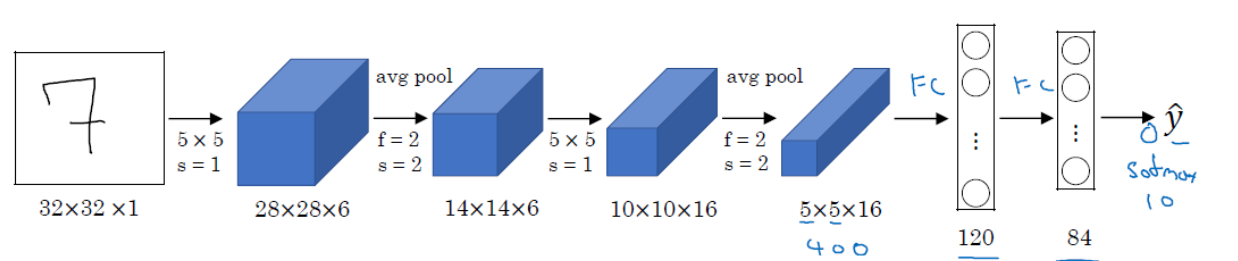
最早的卷积网络结构,引入了卷积结构提取图像特征,同时包含池化,激活函数和全连接层结构,最早用来进行手写体数字识别,准确率达到99%
AlexNet
结构如下:
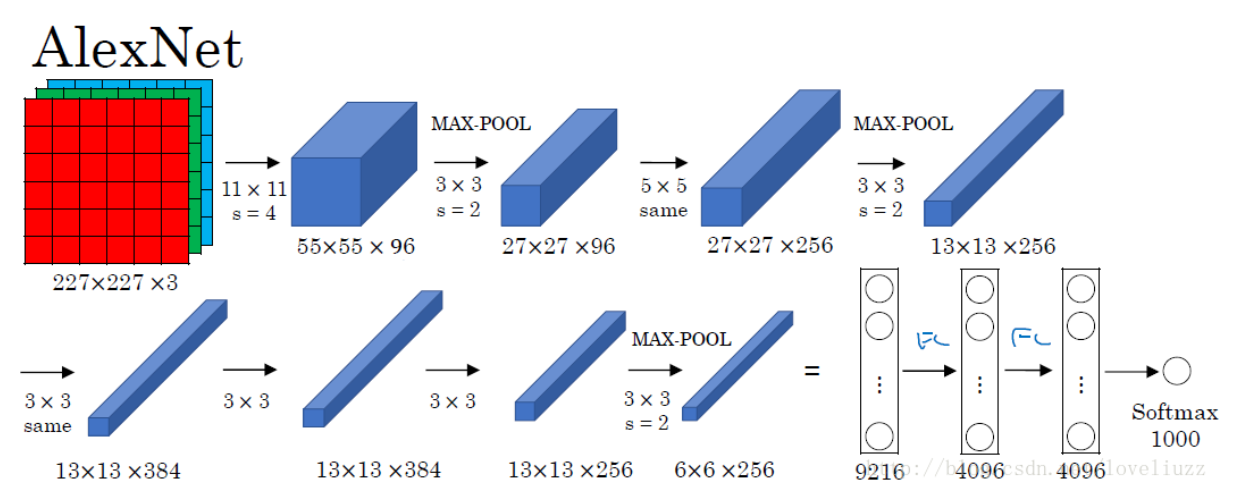
结构与LeNet比深入了很多,同时采用了relu激活函数,有效避免了梯度消失现象。堆叠卷积层,可以看到两次池化后卷积操作变多(因为尺寸逐渐变小,所以降采样采用的次数减少),同时采用Dropout来降低过拟合。
论文里是使用两个GPU跑的,所以看到网络分成了两部分,现在的话综合成 一个即可。
VGG-16

深度更深了,反复堆叠3*3卷积(小卷积)及2*2池化,论证了深度与性能关系。也有VGG-19,但是性能和VGG-16差不多。
Inception系列
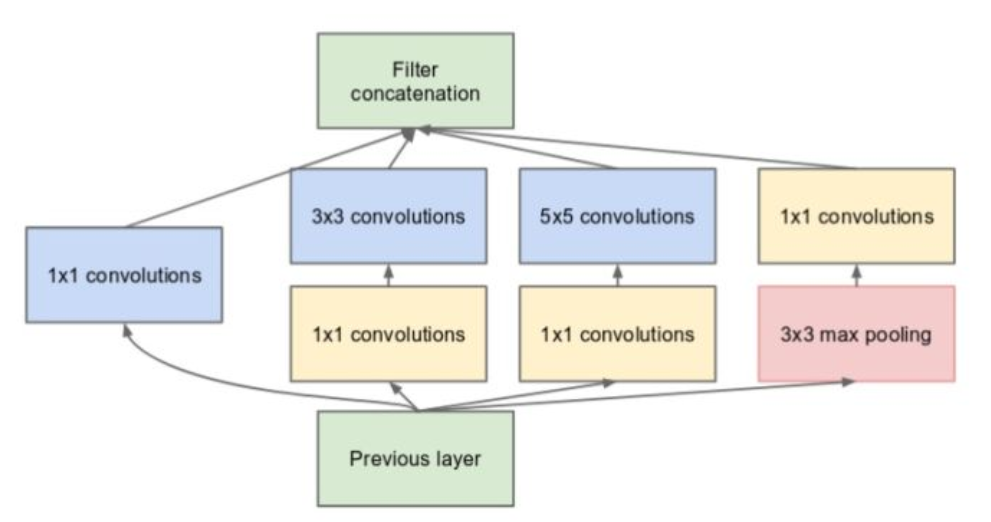
Inception 系列是google提出的,VGG-16证明一般增强模型质量手段是增加模型宽度和深度,但是同时会带来过拟合和运算量的缺点,Inception系列
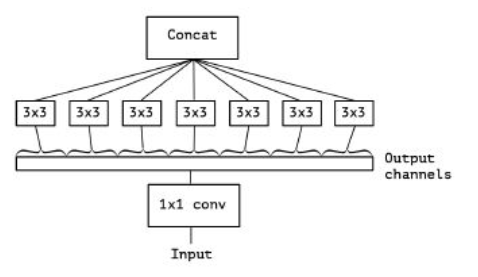
如下图所示。优点1. 采用不同的卷积核表示不同大小的感受野,最后拼接代表不同尺度的特征融合。2. 卷积核采用1*1,3*3和5*5,步长为1,padding=0,1,2,采用same卷积可以得到相同维度的特征。3. 到最后感受野逐渐增多,随着层数增加,3*3和5*5的卷积核数量也要增加。4.先采用1*1卷积进行降维操作,之后再进行3*3或者5*5的卷积,有利于降低计算量。其实1*1卷积还可以增加非线性及跨层连接作用,以此增加模型的信息容量。可参考1*1卷积的实现方式。但主要应该是进行降维和升维。
5.最后一层引入了全局池化,作用应该是降低参数量。 整个结构还有两个附属loss,目的是防止梯度消失,增加正则性。
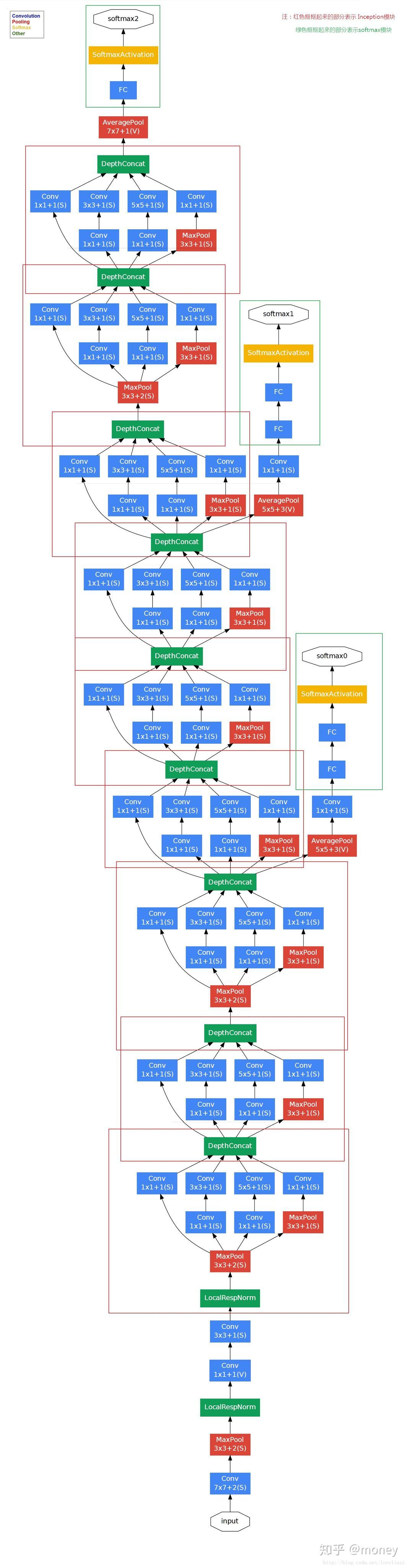
Inception V2
InceptionV2采用了BN层,避免梯度消失或爆炸。同时,它采用两个3*3的卷积核代替5*5的卷积核(步长为1),因为两种方式感受野相同,但是前一种计算量小。
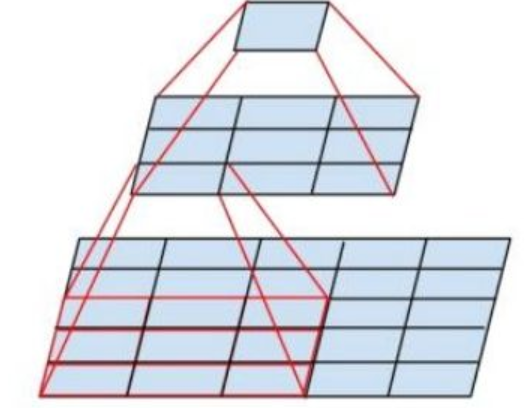
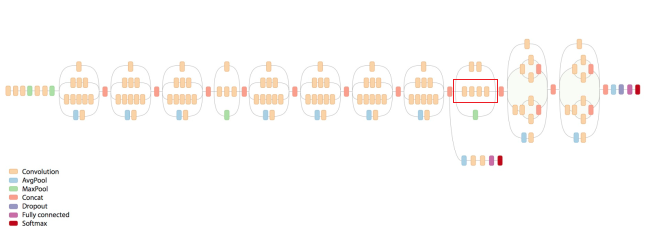
InceptionV3
提出n*n的卷积核是否可以用1*n和n*1的卷积核来代替。但实际并不好,对n处于12到20之间的卷积核才好一点。


另一个改进是不再使用pooling层直接作为下采样,而是采用卷积核pooling结合的策略

整体的架构比较复杂,还是要看下专门的博客讲的详细。
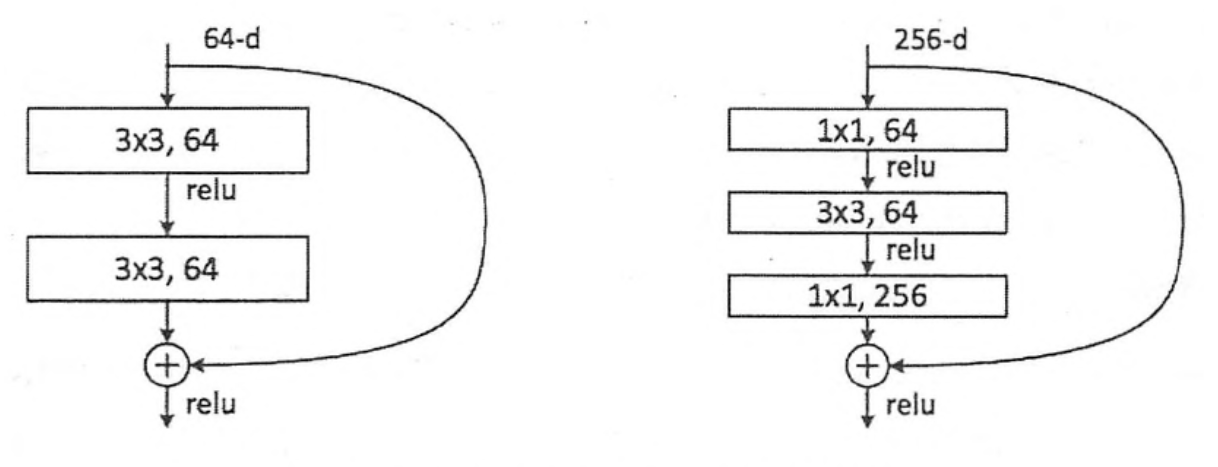
ResNet
因为InceptionV4引入了残差模块,所以先讲一下残差网络。
直连神经网络并不是深度越深性能越好,而是随着深度的加深,先变好,后退化。之前可以考虑多增加的层数学习成恒等形式,这样增加的深度就可以抵消了,但是恒等形式比较难学。所以引入残差模块,残差相对而言比较好学。如下图结构,之后随着网络加深,模型准确率逐渐提高。
Inception Resnet
分别在InceptionV1-V4引入了残差模块,结构如下

Xception
xception是对每一个通道进行卷积。即先通过1*1获得多通道信息,再使用3*3对每一个通道进行卷积,从而获得每一个通道的区域相关性,同时也借鉴了残差模块。结构如下:
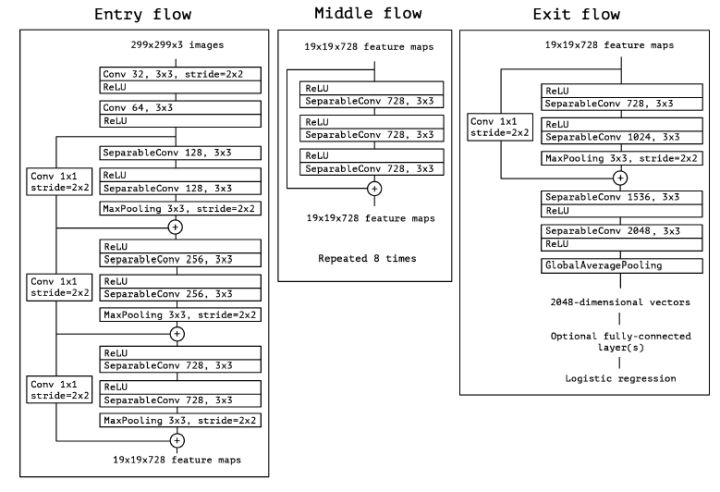
所谓的对1*1卷积后的网络每一个通道再进行3*3卷积,如下,也减少了很多参数量。