干货:RAG(检索增强生成)VS Fine-Tuning(微调)
From:头条文章
共同点:
RAG(检索增强生成)和Fine-Tuning(微调)作为自然语言处理(NLP)技术,尽管在实现方法和应用场景上有所不同,但它们也存在一些共同点:
基于预训练模型:
两者都依赖于预训练的语言模型作为基础。RAG利用预训练模型来生成基于检索信息的答案,而Fine-Tuning则直接在预训练模型上进行额外训练,以适应特定任务。
目的是增强模型性能:
无论是通过检索增强生成还是通过微调,两种技术的主要目标都是提高模型在特定任务上的表现,包括提高准确度、生成的质量或适应性。
数据驱动:
RAG和Fine-Tuning都是数据驱动的方法,它们通过学习从大量数据中提取的模式来改进模型的输出。RAG通过检索相关信息来增强生成内容的相关性和准确性,而Fine-Tuning则通过特定任务的训练数据来调整模型参数,使模型更好地适应该任务。
提高模型的适用性:
通过引入额外信息(RAG的检索内容)或调整模型以适应特定任务(Fine-Tuning),这两种方法都旨在提高模型对新领域或特定任务的适用性。
利用大规模文本数据:
RAG和Fine-Tuning都能够利用互联网或其他来源上的大规模文本数据,无论是通过检索过程中使用的知识库,还是通过用于微调的特定任务数据集。
综上所述,尽管RAG和Fine-Tuning在技术实现上有所区别,它们共享的核心理念是基于预训练模型来进一步提升模型对特定任务的处理能力,通过数据驱动的方式来增强模型性能和适应性。
不同点:
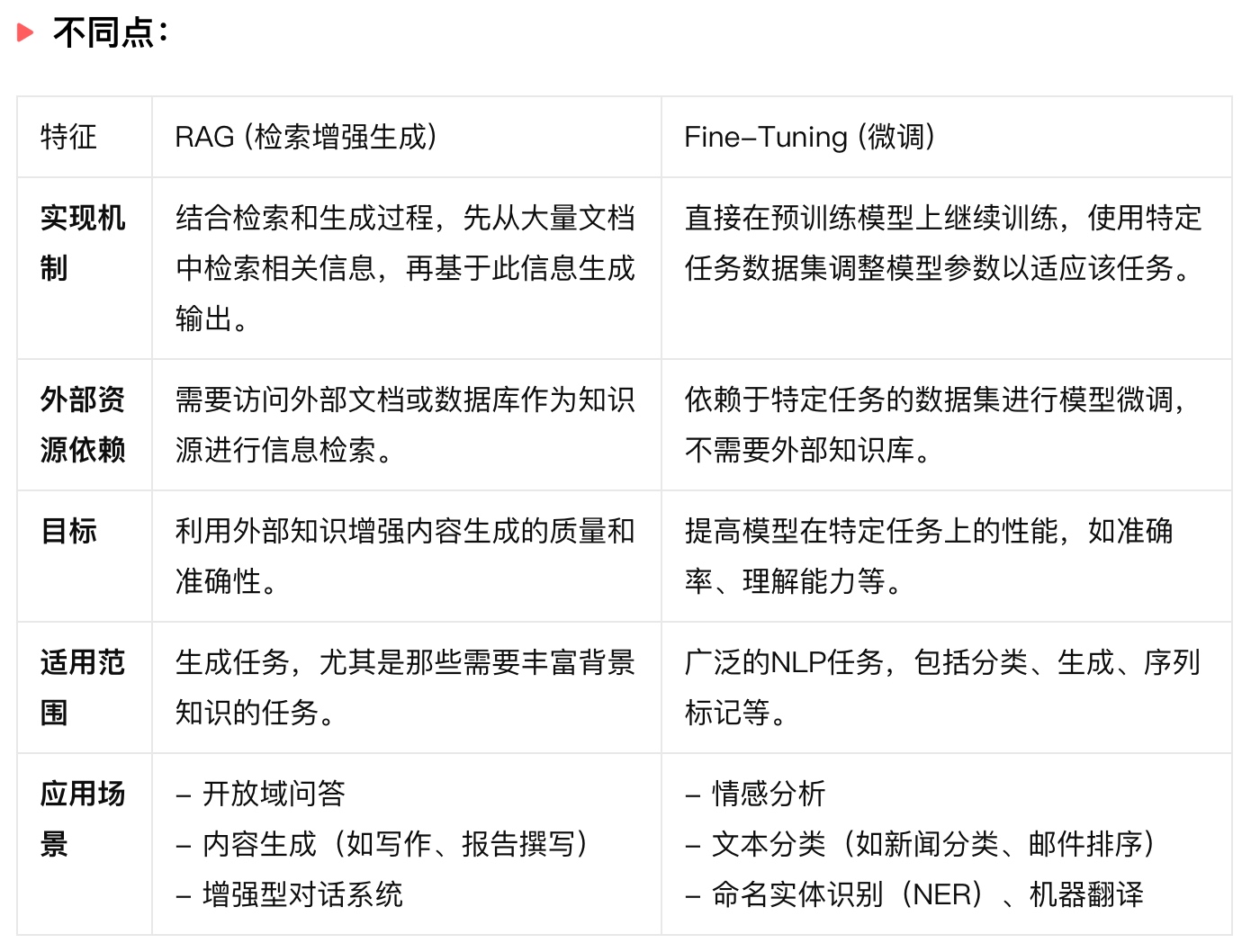
| 特征 | RAG (检索增强生成) | Fine-Tuning (微调) |
|---|---|---|
| 实现机制 | 结合检索和生成过程,先从大量文档中检索相关信息,再基于此信息生成输出。 | 直接在预训练模型上继续训练,使用特定任务数据集调整模型参数以适应该任务。 |
| 外部资源依赖 | 需要访问外部文档或数据库作为知识源进行信息检索。 | 依赖于特定任务的数据集进行模型微调,不需要外部知识库。 |
| 目标 | 利用外部知识增强内容生成的质量和准确性。 | 提高模型在特定任务上的性能,如准确率、理解能力等。 |
| 适用范围 | 生成任务,尤其是那些需要丰富背景知识的任务。 | 广泛的NLP任务,包括分类、生成、序列标记等。 |
| 应用场景 | - 开放域问答 - 内容生成(如写作、报告撰写) - 增强型对话系统 |
- 情感分析 - 文本分类(如新闻分类、邮件排序) - 命名实体识别(NER)、机器翻译 |
通过比较,我们可以看到RAG和Fine-Tuning在实现机制、依赖的外部资源、目标和适用范围上存在显著差异。这些差异导致了它们在实际应用中各自有更适合的场景。选择哪一种技术取决于特定任务的需求、所需的知识范围、以及数据的可用性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号