机器学习基础02DAY
数据的特征预处理
单个特征
(1)归一化
归一化首先在特征(维度)非常多的时候,可以防止某一维或某几维对数据影响过大,也是为了把不同来源的数据统一到一个参考区间下,这样比较起来才有意义,其次可以程序可以运行更快。 例如:一个人的身高和体重两个特征,假如体重50kg,身高175cm,由于两个单位不一样,数值大小不一样。如果比较两个人的体型差距时,那么身高的影响结果会比较大,k-临近算法会有这个距离公式。
min-max方法
常用的方法是通过对原始数据进行线性变换把数据映射到[0,1]之间,变换的函数为:
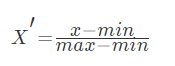
其中min是样本中最小值,max是样本中最大值,注意在数据流场景下最大值最小值是变化的,另外,最大值与最小值非常容易受异常点影响,所以这种方法鲁棒性较差,只适合传统精确小数据场景。
- min-max自定义处理
import numpy as np
def data_matrix(file_name):
"""
将文本转化为matrix
:param file_name: 文件名
:return: 数据矩阵
"""
fr = open(file_name)
array_lines = fr.readlines()
number_lines = len(array_lines)
return_mat = zeros((number_lines, 3))
# classLabelVector = []
index = 0
for line in array_lines:
line = line.strip()
list_line = line.split('\t')
return_mat[index,:] = list_line[0:3]
# if(listFromLine[-1].isdigit()):
# classLabelVector.append(int(listFromLine[-1]))
# else:
# classLabelVector.append(love_dictionary.get(listFromLine[-1]))
# index += 1
return return_mat
输出结果为
[[ 4.09200000e+04 8.32697600e+00 9.53952000e-01]
[ 1.44880000e+04 7.15346900e+00 1.67390400e+00]
[ 2.60520000e+04 1.44187100e+00 8.05124000e-01]
...,
[ 2.65750000e+04 1.06501020e+01 8.66627000e-01]
[ 4.81110000e+04 9.13452800e+00 7.28045000e-01]
[ 4.37570000e+04 7.88260100e+00 1.33244600e+00]]
我们查看数据集会发现,有的数值大到几万,有的才个位数,同样如果计算两个样本之间的距离时,其中一个影响会特别大。也就是说飞行里程数对于结算结果或者说相亲结果影响较大,但是统计的人觉得这三个特征同等重要,所以需要将数据进行这样的处理。
这样每个特征任意的范围将变成[0,1]的区间内的值,或者也可以根据需求处理到[-1,1]之间,我们再定义一个函数,进行这样的转换。
def feature_normal(data_set):
"""
特征归一化
:param data_set:
:return:
"""
# 每列最小值
min_vals = data_set.min(0)
# 每列最大值
max_vals = data_set.max(0)
ranges = max_vals - min_vals
norm_data = np.zeros(np.shape(data_set))
# 得出行数
m = data_set.shape[0]
# 矩阵相减
norm_data = data_set - np.tile(min_vals, (m,1))
# 矩阵相除
norm_data = norm_data/np.tile(ranges, (m, 1)))
return norm_data
输出结果为
[[ 0.44832535 0.39805139 0.56233353]
[ 0.15873259 0.34195467 0.98724416]
[ 0.28542943 0.06892523 0.47449629]
...,
[ 0.29115949 0.50910294 0.51079493]
[ 0.52711097 0.43665451 0.4290048 ]
[ 0.47940793 0.3768091 0.78571804]]
这样得出的结果都非常相近,这样的数据可以直接提供测试验证了
- min-max的scikit-learn处理
scikit-learn.preprocessing中的类MinMaxScaler,将数据矩阵缩放到[0,1]之间
>>> X_train = np.array([[ 1., -1., 2.],
... [ 2., 0., 0.],
... [ 0., 1., -1.]])
...
>>> min_max_scaler = preprocessing.MinMaxScaler()
>>> X_train_minmax = min_max_scaler.fit_transform(X_train)
>>> X_train_minmax
array([[ 0.5 , 0. , 1. ],
[ 1. , 0.5 , 0.33333333],
[ 0. , 1. , 0. ]])
(3)标准化
常用的方法是z-score标准化,经过处理后的数据均值为0,标准差为1,处理方法是:
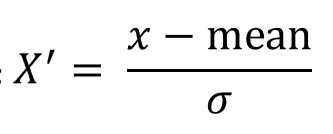
作用于每一列,mean为平均值,σ为标准差(考量数据的稳定性)

它们可以通过现有的样本进行估计,在已有的样本足够多的情况下比较稳定,适合嘈杂的数据场景
sklearn中提供了StandardScalar类实现列标准化:
In [2]: import numpy as np
In [3]: X_train = np.array([[ 1., -1., 2.],[ 2., 0., 0.],[ 0., 1., -1.]])
In [4]: from sklearn.preprocessing import StandardScaler
In [5]: std = StandardScaler()
In [6]: X_train_std = std.fit_transform(X_train)
In [7]: X_train_std
Out[7]:
array([[ 0. , -1.22474487, 1.33630621],
[ 1.22474487, 0. , -0.26726124],
[-1.22474487, 1.22474487, -1.06904497]])
(3)缺失值
由于各种原因,许多现实世界的数据集包含缺少的值,通常编码为空白,NaN或其他占位符。然而,这样的数据集与scikit的分类器不兼容,它们假设数组中的所有值都是数字,并且都具有和保持含义。使用不完整数据集的基本策略是丢弃包含缺失值的整个行和/或列。然而,这是以丢失可能是有价值的数据(即使不完整)的代价。更好的策略是估算缺失值,即从已知部分的数据中推断它们。
(1)填充缺失值 使用sklearn.impute中的SimpleImputerr类进行数据的填充
#导入imputer
from sklearn.impute import SimpleImputer
import numpy as np
data = [[1, 2, np.nan], [4, np.nan, 6], [7, 8, 9]]
#实例化
imp = SimpleImputer(missing_values=np.nan, strategy="mean")
#数据填充
result = imp.fit_transform(data)
result
#结果
array([[1. , 2. , 7.5],
[4. , 5. , 6. ],
[7. , 8. , 9. ]])
数据预处理
归一化处理
In [ ]:
# MinMaxScaler导入包
from sklearn.preprocessing import MinMaxScaler
data = [[90, 2, 10, 40],
[60, 4, 15, 45],
[75, 3, 13, 46]]
# 实例化 feature_range默认(0,1)
mms = MinMaxScaler(feature_range=(0,1))
#归一化处理
rusult = mms.fit_transform(data)
rusult
Out[ ]:
array([[1. , 0. , 0. , 0. ],
[0. , 1. , 1. , 0.83333333],
[0.5 , 0.5 , 0.6 , 1. ]])
标准化处理
In [ ]:
#导入StandardScaler包
from sklearn.preprocessing import StandardScaler
data = [[ 1., -1., 3.],
[ 2., 4., 2.],
[ 4., 6., -1.]]
#实例化
sds = StandardScaler()
#标准化处理
result = sds.fit_transform(data)
result
Out[ ]:
array([[-1.06904497, -1.35873244, 0.98058068],
[-0.26726124, 0.33968311, 0.39223227],
[ 1.33630621, 1.01904933, -1.37281295]])
In [ ]:
# 查看原始数据中每个特征的平均值
sds.mean_
Out[ ]:
array([2.33333333, 3. , 1.33333333])
In [ ]:
#查看原始数据每列特征的方差
sds.var_
Out[ ]:
array([1.55555556, 8.66666667, 2.88888889])
缺失值处理
In [ ]:
#导入imputer
from sklearn.impute import SimpleImputer
import numpy as np
data = [[1, 2, np.nan], [4, np.nan, 6], [7, 8, 9]]
#实例化
imp = SimpleImputer(missing_values=np.nan, strategy="mean")
#数据填充
result = imp.fit_transform(data)
result
Out[ ]:
array([[1. , 2. , 7.5],
[4. , 5. , 6. ],
[7. , 8. , 9. ]])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号