1. 前端简介
"""
强调:前端 和 数据库 学习的时候跟python一毛钱关系都没有
也就意味着我们还有两次赶超的机会 所有人处在同一起跑线!!!
前端的学习是非常简单的 但是也很枯燥 没有太多的逻辑
数据库的学习有点难度 但是主要还是以记忆为主 大量练习肯定能掌握
ps:前端数据库学不好 完全就是因为自己不够努力 记的少了 练得少了
没有接口说 编程思维、小白!!!
"""
# 1.什么是前端 什么是后端
前端
任何与用户直接打交道的界面都可以称之为前端
eg:淘宝页面 游戏页面 操作页面
后端
不直接与用户打交道的用于执行真正业务逻辑的代码
eg:python代码 java代码 c++代码
# 2.前端的学习路径
声明:
真正的前端工程师也需要培训六个月左右 我们作为python全栈工程师只需要掌握前端最核心的知识点即可 做到能看到前端代码并且将来有能力去钻研前端即可
我们学习前端的时间不会超过七天(作为后端程序员足矣!!!)
知识脉络:
HTML CSS JavaScript jQuery(框架) Bootstrap(框架)
只要学习前端看到要学'前端三剑客'>>>:HTML CSS JavaScript
比喻说明:
HTML:网页的骨架
蜡笔小新不穿衣服 赤裸裸的(难看)
CSS:网页的样式
穿上衣服 化好妆(好看)
JavaScript:网页的动态效果
扭起来 跳起来 动起来(生动)
2. HTTP协议简介
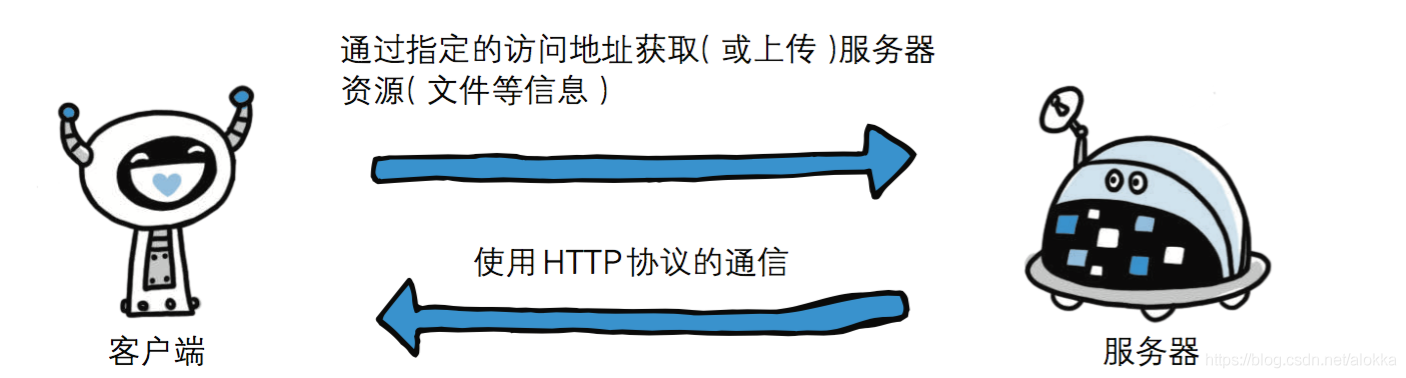
HTTP是在网络上传输HTML的协议(超文本传输协议),用于浏览器和服务器的通信。
# 可以充当客户端的有哪些?
1.自己写的python代码(TCP客户端)
2.别人写的浏览器
'''cs架构与bs架构:bs本质也是cs'''
# 问题
我们自己写的TCP服务端与浏览器之间通信了 但是浏览器不识别服务端数据
# 推导
不同的服务端数据的组织策略千差万别 但是浏览器却需要做到能够统一处理
最佳的解决措施是统一规定一个标准>>>:HTTP协议
# HTTP协议
规定了服务端与浏览器之间的数据交互格式及其他事项
"""
如果服务端遵循HTTP协议 就可以被浏览器正常访问并展示内容
如果服务端不遵循HTTP协议 浏览器就不会正常访问和展示 但是不影响服务端
如果这个应用特别火爆 那么完全可以让用户下载专属的客户端(app)
"""
![]()
3. HTTP协议特性
1.基于请求、响应
服务端永远不会主动给客户端发消息 必须是客户端先请求服务端被动响应
2.基于TCP/IP作用于应用层之上的协议
应用层协议:HTTP HTTPS FTP ...
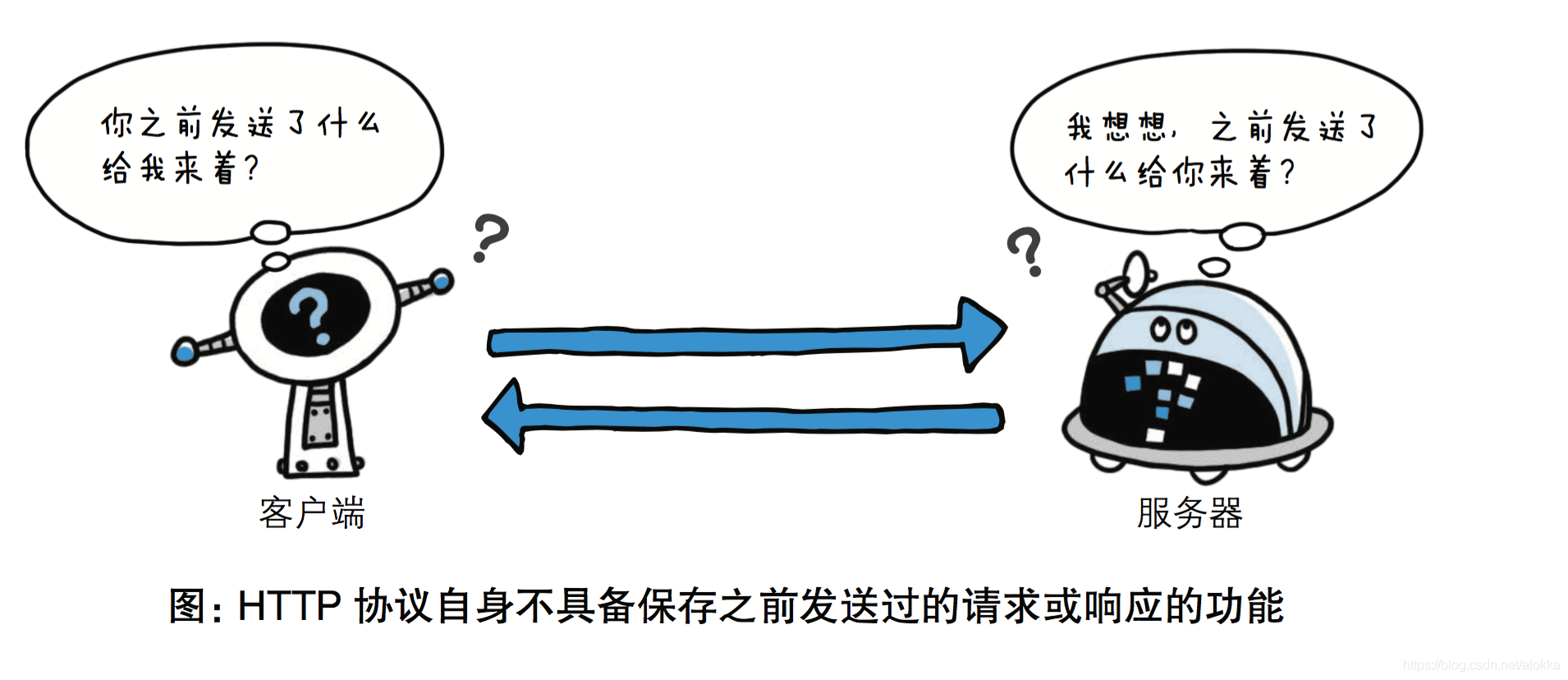
3.无状态
服务端不保存客户端状态(纵使见她千百遍 我都当她如初见)
4.短连接
不保持客户端与服务端之间的链接导通
补充:websocket(长连接) 主要用于加好友聊天等业务
![]()
4. HTTP协议的数据格式与响应码
数据格式
请求格式:客户端给服务端发送消息应该遵循的数据格式
1.请求首行(请求方法 协议版本)
2.请求头(一大堆k:v键值对)
3.\r\n(换行不能省略)
4.请求体(携带敏感数据:密码 身份照号...) 不是一直都有
响应格式:服务端给客户端发送消息应该遵循的数据格式
1.响应首行(响应状态码 协议版本)
2.响应头(一大堆k:v键值对)
3.\r\n(换行不能省略)
4.响应体(给浏览器展示给用户看的页面内容)
响应状态码
用数字来表示一串中文意思(简化理解)
1XX:服务端成功接收到了你的数据正在处理 你可以等待或者继续发送
2XX:200 OK 表示请求成功 服务端给出了响应
3XX:301\302 表示重定向(想访问A页面但是自动跳转到了B页面)
4XX:403请求不合法(权限不够) 404请求资源不存在
5XX:都是服务端错误 与客户端无关(代码bug、机房炸了...)
在工作中还会自定义状态码(因为默认的不够)
自定义状态码一般都是从10000开始
5. HTML简介
<h1>hello big baby</h1>
<a href="https://www.sogo.com">click me</a>
<img src="111.jpg"/>
# 上述语法就是HTML 用于构建网页的骨架(所有的网页都是由HTML组成)
1.存放HTML代码的文件后缀名一般都是.html
2.HTML:超文本标记语言
它没有任何的逻辑 固定搭配 """所见即所得"""
3.HTML文档结构
<html>
<head>给浏览器看的数据</head>
<body>给用户看的数据</body>
</html>
4.HTML标签的分类
1.双标签:有头有尾 内容写在中间
<h1></h1> <html></html>
2.自闭合标签:单标签
<img/> 一般有特殊功能
5.HTML注释语法
<!--单行注释-->
<!--
多行注释
-->
'''html由于标签非常的多 所以可以通过注释区分页面区域'''
补充:
# HTML文档类型
目前常用的两种文档类型是xhtml 1.0和html5
# 两种文档的区别
1、文档声明和编码声明
2、html5新增了标签元素以及元素属性
# html文档规范
xhtml制定了文档的编写规范,html5可部分遵守,也可全部遵守,看开发要求。
1、所有的标签必须小写
2、所有的属性必须用双引号括起来
3、所有标签必须闭合
4、img必须要加alt属性(对图片的描述)
# html注释:
html文档代码中可以插入注释,注释是对代码的说明和解释,注释的内容不会显示在页面上,html代码中插入注释的方法是:
<!-- 这是一段注释 -->
6. head内常见标签
# head标签内编写的标签一般都是给浏览器看的
title标签 控制网页小标题
style标签 内部支持编写css代码
link标签 引入外部css文件
script标签 内部支持编写js代码 也可以通过src属性引入外部js文件
meta标签 功能非常多
keywords:搜索引擎查询关键字
description:用于展示页面搜索结果的文本描述
"""
正常的业务逻辑 HTML CSS JS都会分不同的文件存储 用于解耦合
"""
1.id
类似于身份证号 同一个html页面上标签的id值不允许重复 用于精确查找某个标签(因为一个html页面上相同标签名的标签太多)
2.class
类似于面向对象知识 可以将多个标签归为一类 分类查找(范围查找一次性多个)
7. body内标签
7.1 html标题
"""相同的样式可能存在多种标签 区别在于语义不一样"""
1.标题系列
h1~h6(1到6级标题)
2.字体系列
<i>斜体</i>
<b>加粗</b>
<u>下划线</u>
<s>删除线</s>
3.文本段落
<p></p>
4.其他
hr 水平分割线
br 换行符
![]()
7.2 body内特殊符号
空格
> 大于号(>)
< 小于号(<)
& &符号
¥ 羊角符(¥)
© 版权
® 商标
![]()
7.3 body内块、含样式的标签
1、div标签 块元素,表示一块内容,没有具体的语义。
2、span标签 行内元素,表示一行中的一小段内容,没有具体的语义。
# 含样式和语义的标签
1、em标签 行内元素,表示语气中的强调词
2、i标签 行内元素,原本没有语义,w3c强加了语义,表示专业词汇
3、b标签 行内元素,原本没有语义,w3c强加了语义,表示文档中的关键字或者产品名
4、strong标签 行内元素,表示非常重要的内容
7.4 body内图像
<img>标签可以在网页上插入一张图片,它是独立使用的标签,通过“src”属性定义图片的地址,通过“alt”属性定义图片加载失败时显示的文字,以及对搜索引擎和盲人读屏软件的支持
# 代码示例:
<img src="images/pic.jpg" alt="对图片描述" />
#绝对路径和相对路径
像网页上插入图片这种外部文件,需要定义文件的引用地址,引用外部文件还包括引用外部样式表,javascript等等,引用地址分为绝对地址和相对地址。
绝对地址:相对于磁盘的位置去定位文件的地址
相对地址:相对于引用文件本身去定位被引用的文件地址
7.5 body内链接
a
href 点击跳转到位置
可以写网址
<a href='网址'></a>
也可以写标签id值
<a href='页面上某个标签id值'></a>
target 控制是否当前页跳转
默认_self当前页
设置_blank新建页
7.6 body内无序列表
在网页上定义一个无编号的内容列表可以用<ul>、<li>配合使用来实现
# 代码示例:
<ul>
<li>列表文字一</li>
<li>列表文字二</li>
<li>列表文字三</li>
</ul>
'''在网页上生成的列表,每条项目上会有一个小图标,这个小图标在不同浏览器上显示效果不同,所以一般会用样式去掉默认的小图标,如果需要图标,可以用样式自定义图标,从而达到在不同浏览器上显示的效果相同,实际开发中一般用这种列表'''
![]()
7.7 body内表格
# table常用标签
1、table标签:声明一个表格
2、tr标签:定义表格中的一行
3、td和th标签:定义一行中的一个单元格,td代表普通单元格,th表示表头单元格
# table常用属性:
1、border 定义表格的边框
2、cellpadding 定义单元格内内容与边框的距离
3、cellspacing 定义单元格与单元格之间的距离
4、align 设置单元格中内容的水平对齐方式,设置值有:left | center | right
5、valign 设置单元格中内容的垂直对齐方式 top | middle | bottom
6、colspan 设置单元格水平合并
7、rowspan 设置单元格垂直合并
# 传统布局:
传统的布局方式就是使用table来做整体页面的布局,布局的技巧归纳为如下几点:
1、定义表格宽高,将border、cellpadding、cellspacing全部设置为0
2、单元格里面嵌套表格
3、单元格中的元素和嵌套的表格用al ign和valign设置对齐方式
4、通过属性或者css样式设置单元格中元素的样式
代码示例
<table >
<thead>
<tr> <!--tr表示一行-->
<th>编号</th> <!--th加粗文本-->
<th>姓名</th>
<th>年龄</th>
</tr>
</thead> <!--表头字段-->
<tbody>
<tr>
<td>1</td> <!--td普通文本-->
<td>jason</td>
<td>18</td>
</tr>
<tr>
<td>2</td>
<td>Tom</td>
<td>20</td>
</tr>
<tr>
<td>3</td>
<td>aili</td>
<td>30</td>
</tr>
</tbody> <!--表单数据-->
</table>
![]()





 浙公网安备 33010602011771号
浙公网安备 33010602011771号