
2303.12789
摘要
- Instruct-NeRF2NeRF:用文本指令 3D一致地 编辑NeRF场景
- 给定 一个场景的NeRF 和 用于重建它的图像集
- 使用 扩散模型 迭代编辑该图像集
- 图像条件-扩散模型 InstructPix2Pix
- an image-conditioned diffusion model
- 同时优化底层场景
- 图像条件-扩散模型 InstructPix2Pix
- 得到反映指令编辑的优化3D场景
- 我们提出的方法能够编辑大规模的、真实世界的场景,并能够完成比以前的工作更现实的、更有针对性的编辑。
- Figure1:用指令编辑3D场景
![img]()
- 一种使用基于文本的指令对NeRF场景进行一致的三维编辑的方法。我们的方法可以完成本地和全局场景编辑。
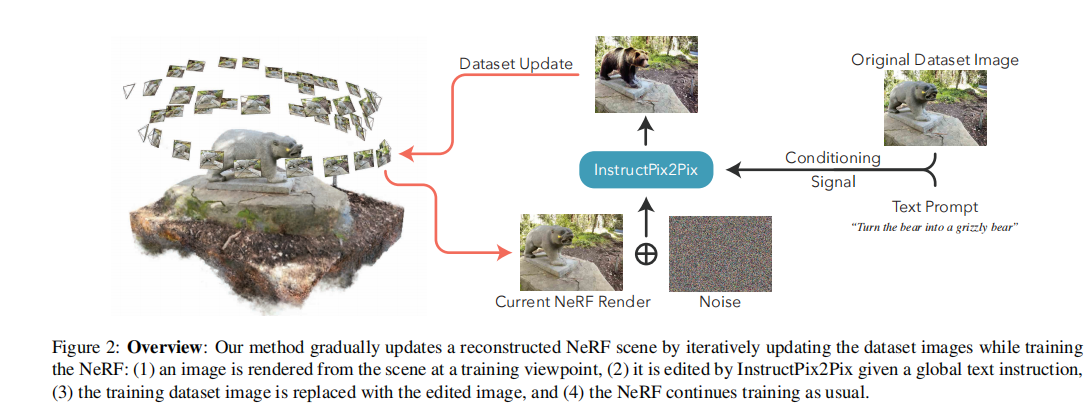
- Figure2:概览
![img]()
- 逐步更新重建的NeRF场景
- 在训练时迭代更新数据集
- 从NeRF场景渲染得到一个图像
- 用InstructPix2Pix 基于给定文本指令 编辑该图像
- 用编辑后的图像代替数据集中的图像
- 继续训练NeRF
- 在训练时迭代更新数据集

引言
-
捕捉真实世界3D场景的数字化表示很容易:
- 从不同视点获取一个场景的图像集
- 重建其相机参数
- 使用这些摆好的图片(posed images)优化(optimize)NeRF
-
创建3D资产(assets)的创作并不容易
- 传统手工方式:
- 手动雕刻、挤压和重新纹理一个给定的对象
- 与神经表征(neural representations)的出现更加相关,而神经表征通常没有明确的表面
- 进一步激发3D编辑方法的需求,尤其是像捕捉技术那样的易操作性
- 传统手工方式:
-
Instruct-NeRF2NeRF:用文字指令编辑3D
- 在一个预先捕获的3D场景上进行操作,并确保所产生的编辑3D一致
- 从2D扩散模型获取形状和外观的先验
- InstructPix2Pix:基于指令的2D图像编辑
- 对重建后的NeRF渲染得到的不同视点的各个图像的编辑会产生不一致性
- 解决方法:类似3D生成模型DreamFusion
- 底层思路:迭代数据集更新Iterative Dataset Update(Iterative DU)
- 编辑NeRF输入图片的数据集<->更新底层3D场景
- 以混合编辑后的图像
-
在各种捕获的NeRF场景上评估我们的方法
- 通过比较我们的方法的消融变体来验证我们的设计选择,以及分数蒸馏采样(SDS)损失的详细实现。
- 我们还定性地比较了我们的方法与并发的基于文本的风格化方法。
- 我们证明了我们的方法可以完成对人、对象和大规模场景的各种编辑。
相关工作
- NeRFs的物理编辑
- 一种流行的方法
- 用于生成由校准的照片捕获的 场景的 逼真新视图
- 已拓展到许多后续工作
- 由于nerf的底层表示,编辑它们仍然是一个挑战。
- 一种优化方法:在其优化过程中施加基于物理的归纳偏差,以使材料或场景照明发生变化
- 或者:还可以指定边界框,以允许方便地组合不同的对象以及空间操作和几何变形
- 最近的一项工作,ClimateNeRF从NeRF中提取了粗糙的几何形状,并使用物理仿真来应用降雪和洪水等天气变化。
- 大多数基于物理的编辑都围绕着改变重建场景的物理属性,或执行物理仿真。
- 一种流行的方法
- NeRFs的艺术风格
- 近期工作探索了NeRFs的艺术3D风格化
- 这些方法可以获得一个场景的三维一致的风格,但它们主要关注全局场景外观的变化,且通常需要一个参考图像。
- 其他工作已经探索了使用来自视觉语言模型的潜在表示,如CLIP
- EditNeRF通过操纵 从合成数据集中的对象类别学习到的 潜在代码(latent code)来探索编辑nerf。
- 为了增加可用性(以及在其他3D领域如网格(mesh)中探索的那样),ClipNeRF 和NeRF-Art通过鼓励场景的CLIP嵌入和短文本提示(prompt)之间的相似性来扩展这一工作。
- 这些基于clip的方法的一个局限性是它们无法合并本地化编辑。
- 蒸馏特征场(Distilled Feature Fields)和神经特征融合场(Neural Feature Fusion Fields)等方法 将从预先训练过的模型如LSeg和DINO中的二维特征提取到辐射场(radiance fields)中,从而确定区域。
- 这些方法允许本地化的 CLIP-引导 的编辑,3D空间转换,或由语言/参考图像指定的本地化的场景删除
- 在本项工作中,我们提供了一种互补的方法 基于直观的、纯基于语言的编辑指令 来编辑3D场景。
- 虽然mask可以实现特定的局部更改,但指令编辑提供了直观的高级指令,可以对单个对象或整个场景的外观或几何形状进行更灵活和更全面的更改。
- 我们利用最近基于指令的2D image-conditioned 扩散模型[2],实现了无mask的指令编辑,从而产生了一个纯基于语言的界面接口,实现了更直观、更内容感知的3D编辑。
- 近期工作探索了NeRFs的艺术3D风格化
- 生成3D内容
- 预先训练的大规模模型的最新进展使从头生成3D内容的领域得以快速进展,无论是通过像CLIP [14,16]等视觉语言模型优化辐射场,还是通过文本条件扩散模型[34,36,35],如梦想融合[32]及其后续[47,19,23]。虽然这些方法可以从任意的文本提示中生成3D模型,但它们缺乏
- 对合成输出的细粒度控制
- 推广到场景的能力(即,在空间中孤立的单个物体之外的任何东西),以及
- 现实中的任何基础,产生完全合成的创作。
- 同时进行的工作,如真实融合[21]和稀融合[54]通过提供一个或几个输入图像来探索接地,其中看不见的部分产生幻觉。在所有这些方法中,一个核心的挑战是将一个二维扩散模型的不一致的输出整合到一个一致的三维场景中。在这项工作中,我们不是创建新的内容,而是专注于使用2D扩散先验来编辑完全观察到的场景的真实捕获的nerf。编辑现有的NeRF场景(而不是从头开始生成3D内容)的一个优点是,根据定义,捕获的图像是3D一致的,这表明生成的图像自然应该更加一致。这也有助于避免某些导致无条件3D内容生成方法[32,47,19]中常见的卡通外观的设计决策。
- 预先训练的大规模模型的最新进展使从头生成3D内容的领域得以快速进展,无论是通过像CLIP [14,16]等视觉语言模型优化辐射场,还是通过文本条件扩散模型[34,36,35],如梦想融合[32]及其后续[47,19,23]。虽然这些方法可以从任意的文本提示中生成3D模型,但它们缺乏
- 作为编辑界面的指令
- 随着像GPT [3]和ChatGPT [28]这样的大语言模型(llm)的兴起,自然语言正在成为下一个用于指定复杂任务的“编程语言”。llm允许通过使用语言,特别是指令[30],将一系列低级规范抽象为一个直观和用户友好的界面。指令pix2Pix[2]演示了指令在2D图像任务中的有效性,以及其他领域的其他工作,如机器人导航[11]。我们提出了第一个在三维编辑领域演示教学编辑的工作。考虑到基本任务,即3D模型编辑的困难,这一点尤其重要,而这通常需要专门的工具和多年的经验。通过使用自然语言指令,即使是新手用户,也可以在没有额外的工具或专业知识的情况下获得高质量的结果。
方法
-
概况
- 输入:
- 将一个重建的NeRF场景及其相应的源数据作为输入:
- 一组捕获的图像
- 它们相应的相机姿态
- 相机校准(通常来自一个结构来自运动(structure-from-motion)的系统,如COLMAP)。
- 此外,我们的方法以一个自然语言的编辑指令作为输入,例如,“把他变成艾伯特·爱因斯坦”。
- 将一个重建的NeRF场景及其相应的源数据作为输入:
- 作为输出,我们的方法根据所提供的编辑指令生成:
- 编辑后的NeRF
- 编辑后的输入图像。
- 我们的方法:
- 在扩散模型的帮助下迭代地更新已捕获的视点上的图像
- 我们的工作建立在图像编辑扩散模型的最新进展,特别是InstructPix2Pix。
- 它提出了一个图像和文本条件扩散模型,被训练用来基于人类提供的指令编辑自然图像。
- 然后用标准的NeRF训练(standard NeRF training)来整合这些3D编辑
- 在扩散模型的帮助下迭代地更新已捕获的视点上的图像
- 输入:
-
背景
- 神经辐射场NeRFs
- 用于重建和渲染3D场景的 小型的(compact)、便利的表示方法
- 由场中的样本点(sample)通过3D位置\((x,y,z)\)和观察方向\((\theta,\phi)\)进行参数化(parameterized)
- 场中的样本点被处理后得到颜色和密度\((\mathbf{c},\sigma)\),在一条射线上积分即可得到一个2D像素点颜色
- NeRF通过一组被捕获的图片及其对应的相机参数进行优化
- 相机参数包括校准(calibration)与外部姿态/方向(exrinsic pos/orientation)
- 这些相机参数用于提取每像素的世界空间射线参数化法(per-pixel world-space ray parameterization)
- 这些参数化法描述每个图像的每个像素点的相机射线\(\mathbf{r}(t)=\mathbf{o}+t\mathbf{d}\)的3D中心\(\mathbf{o}\)和方向\(\mathbf{d}\)
- 这些相机射线及其对应的图片像素颜色被用于优化NeRF
- 训练NeRF的典型过程
- 选择射线\(r\)的一个子集,渲染得到ReRF在这条射线上的颜色估计\(\hat{C}(r)\)
- 相对于被捕获照片的该像素颜色\(C(r)\)计算损失函数\(\mathcal{L}(C(r),\hat{C}(r))\)
- 在实际应用中
- 为了实现可靠的优化,我们从不同的视点中随机选择射线,以确保重建场景对象的三维位置得到足够好的约束。
- 要渲染一个新视点,对这个新图像的每个像素点采样一个射线,然后在场中进行积分得到该像素点的颜色\(\hat{C}(r)\)。最后将颜色\(\hat{C}(r)\)排列成2D帧即可得到图像。
- InstructPix2Pix
- 去噪扩散模型(denoising diffusion model)是生成模型(generative model),通过学习逐步将一个噪声样本转化为一个有模型的数据分布(modelled data distribution)
- InstructPix2Pix是一种基于扩散的方法,专门用于图像编辑
- 以RGB图像\(c_I\)和文本编辑指令\(c_T\)作为条件
- 以噪声图像/纯噪声作为输入
- 目的是产生编辑后的图像\(z_0\)的估计(\(z_0\)是\(c_I\)服从指令\(c_T\)的编辑后的图像)
- 形式化的,扩散模型预测了输入的噪声图像\(z_t\)中的噪声量,使用去噪的U-net \(\epsilon_\theta\): \(\hat{\epsilon}=\epsilon_\theta(z_t;t,c_I,c_T)\)
- 这种噪声预测可用于推导编辑后的图像的估计\(\hat{z}_0\)
- 神经辐射场NeRFs
- 对原理有了大概了解,我的实现思路是:
- 用训练好的NeRF在若干随机视点上渲染得到图片及其相机参数
- 用 instructPix2Pix +文本指令 编辑图片
- stable-diffusion+Unet能否替代instructPix2Pix?
- 是否需要dreambooth?看看效果。
- 用编辑后的图片重新去优化NeRF
- 只尝试过渲染,没有尝试过训练一个NeRF,还需要去找开源项目进行学习

 浙公网安备 33010602011771号
浙公网安备 33010602011771号