Headless的概念最初的来源与内容管理平台有关,一般是指内容管理平台中的一些应用不提供可视化界面,只是通过API方式把内容以数据的方式给前端。前端根据不同的设备类型,可以再去进行针对性地渲染和展现。
从这里,可以理解Headless实际上是把GUI部分跟数据部分进行了分离,这实际上比较符合现在技术的一种发展趋势,尤其是数据要去在不同的环境中去显示的时候。
现在回到什么是Headless BI?实际上就是把BI的数据指标层和展示层做了分离,把BI提供数据的部分以数据服务的方式提供服务,与可视化部分进行分离。
Headless BI 是由 Ankur Goyal 和 Alana Anderson 两位硅谷投资人在这篇博客中提出了 的概念
- “Headless BI:指标只需定义一次,就可以统一地在仪表盘,以及自动化工具中使用”
他们认为理想中的指标层应该通过 Headless BI 的方式来实现,需要满足以下条件:
- 无需写 SQL 就能够轻松定义指标
- 指标可以被灵活的用在 BI 可视化,下游应用系统,并通过 API 消费
- 指标支持大规模查询,从而支持大量的自动化流程,比如触发邮件通知,支撑交互式产品体验等
于是在可视化和自动化流程中间就出现了一个空缺的市场机会,需要由 Headlesss BI 来填补。

为啥要提出Headless BI?
那么为什么会提出Headless BI的概念呢?我们来看看一般的BI系统的整体的一个图:
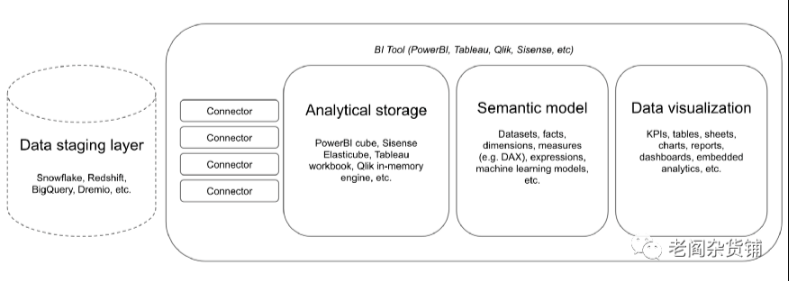
上图来自于Gooddata在介绍Headless BI的博客文章,在这个图里,有几个核心的模块:
- Data Staging Layer - 对于现在的敏捷BI系统来讲,一般数据的来源都是一个居中的云端数据仓库,用于存储客户已经整理好的数据。比如Snowflake, Redshift, BigQuery或者Dremio等等
- Analytical storage - 敏捷BI为了保证自己的处理效率,一般会有一个自己的分析存储引擎,不同的敏捷BI实现不同。有的采用预先建立多维立方体来保证多维分析效率,有的则是内存MPP架构来支持多维分析。
- Semantic Model - 由于敏捷BI都是面向KPI和报表的,因此在敏捷BI中会有一层语义模型。这个语义模型会定义数据集之间的关系,指标的加工算法和表达等等
但是,在基于云端数仓的这个时代,敏捷BI这种把几个部分耦合在一起的架构模式存在一些问题。最常见的就是如果一个企业内有多个团队,每个团队都基于数据仓库构建自己的敏捷BI,就会存在指标重复计算,而且出现KPI计算结果不一致的问题。
因为以上的原因,在现代数据技术栈中,Headless BI的需求得以产生。希望通过把语义模型层与可视化层分开,去解决前面提到的问题。
下图是Headless BI的架构设计:

在新的设计中,Semantic model这一层与数据应用层做了分离。语义建模解决面向业务的数据集的定义、事实表的定义、维度以及度量的定义,包括指标计算的逻辑等等。然后通过开放API的形式提供给数据应用使用。
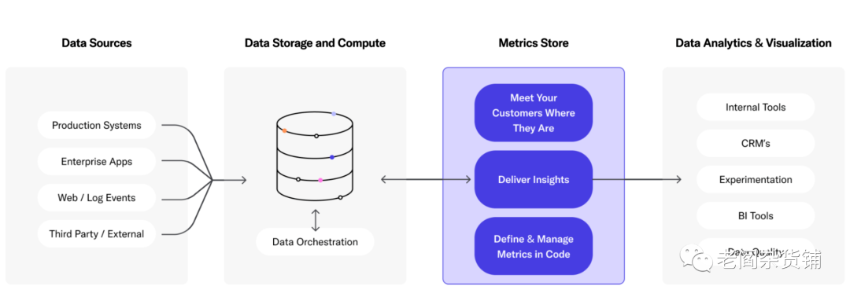
大家看到这里,可能会发现Headless BI的概念与metrics store要解决的问题是一样的. Metrics store的图如下:
参考资料
