
CDP(Cloudera Data Platform)是Cloudera 和 HortonWorks 合并后推出的新一代大数据平台 ,并正在逐步停止对原有的大数据平台 CDH 和 HDP 的维护。笔记目录:
- 一、回顾开源Hadoop生态这些年的发展
- 二、CDP 历程及简介
- 三、CDH/HDP/CDP 的产品支持策略
- 四、CDP 的不同部署形态
- 五、未来大数据架构融合的趋势
- 六、技术关注
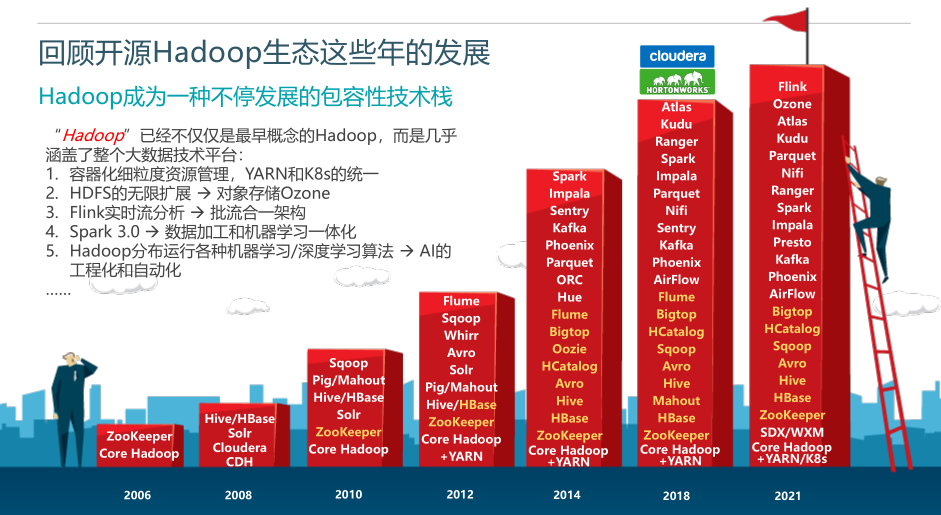
一、回顾开源Hadoop生态这些年的发展
Hadoop成为一种不停发展的包容性技术栈, “Hadoop ”已经不仅仅是最早概念的Hadoop,而是几乎涵盖了整个大数据技术平台:
- 容器化细粒度资源管理,YARN和K8s的统一
- HDFS的无限扩展 → 对象存储Ozone
- Flink实时流分析 → 批流合一架构
- Spark 3.0 → 数据加工和机器学习一体化
- Hadoop分布运行各种机器学习/深度学习算法 → AI的工程化和自动化
二、CDP 历程与简介
CDP历程:
-
2019 年 1 月: Cloudera 宣布与 Hortonworks 合并。这两家企业的强强联手,使得 Cloudera 一跃成为全球数据管理市场的佼佼者。Cloudera 的传统 AI 驱动数据管理与 Hortonworks 端到端数据管理方式相结合,创建了全球领先的下一代数据平台 CDP(Cloudera Data Platform)。Cloudera 希望为企业提供一个本身即是多云且多功能的平台,用于管理企业数据云。通过统一的平台界面,对数据进行整个生命周期管理,并提供一致的安全和治理服务。
- 2019 年 9 月:Cloudera 发布了 CDP 公有云版本,主要以 PaaS 服务的形态存在,而不是传统的 package 形态。目前包括 Cloudera Data Warehouse、Cloudera Machine Learning、Cloudera Data Engineer 等服务,已在 AWS 和 Microsoft Azure 上商用。CDP 公有云版本的特色在于通过容器(Container)和编排(Kubernates)技术来实现运行时环境隔离和资源分配。
- 2019 年 11 月:Cloudera 发布了 CDP 私有云 Base 版本,融合了 CDH 和 HDP 超过 35 个以上的开源组件。CDP 私有云 Base 版本主要用于本地部署,采取传统的存储和计算耦合架构,便于原 CDH 或者 HDP 用户直接原地升级到该版本。
- 2020 年 8 月:Cloudera 推出了 CDP 私有云 Plus 版本,以红帽 OpenShift 为支撑,以 Kubernetes 支持的强大混合架构完善了企业数据云愿景,目前已发布 Cloudera Data Warehouse 和 Cloudera Machine Learning 等服务。CDP 私有云 Plus 版本和 CDP 私有云 Base 版本组合在一起使用,极大提升了企业数据管理的敏捷性、易用性以及基础架构的使用效率。
CDP简介:
CDP 可以认为是将原来的 CDH/HDP 融合在了一起,具体融合方式如下图所示,关键点是:
- 淘汰了竞争的技术
- 融合了重叠的技术
- 保留了互补的技术
- 升级了共享的技术
- 并增加了某些新功能
其中:CDH和HDP都重点涵盖了数据工程和数据仓库场景,同时CDH对AI,ML和数据科学场景有侧重,而HDP对IoT数据摄取和流场景有侧重
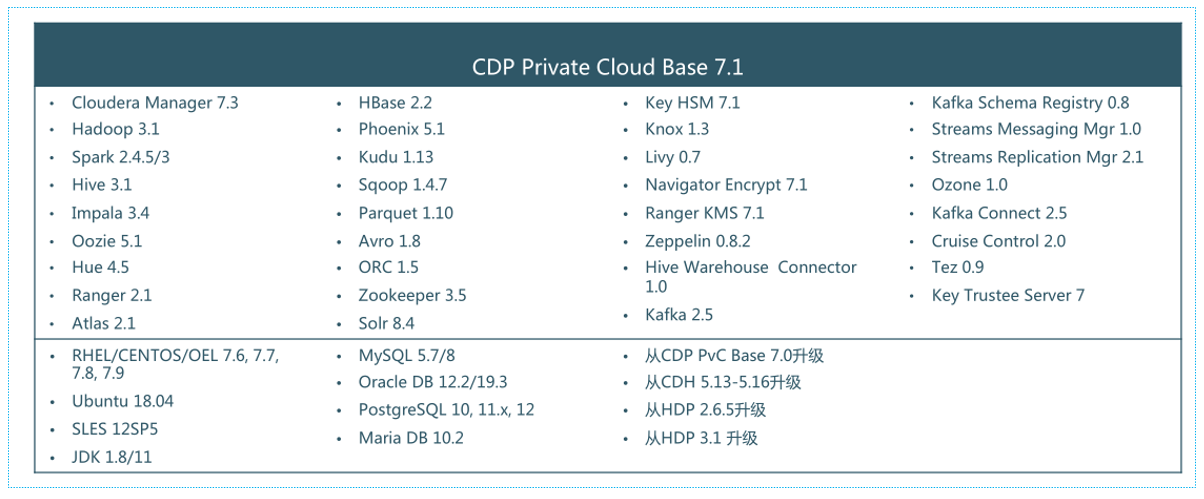
融合的具体组件列表:

随着组织在云环境中采用基于 Hadoop 的大数据部署,他们还需要企业级的安全性和治理、多种分析功能、管理工具和技术支持-所有这些需求都是 CDP 平台的一部分,下图展示了 CDP 平台的功能地图
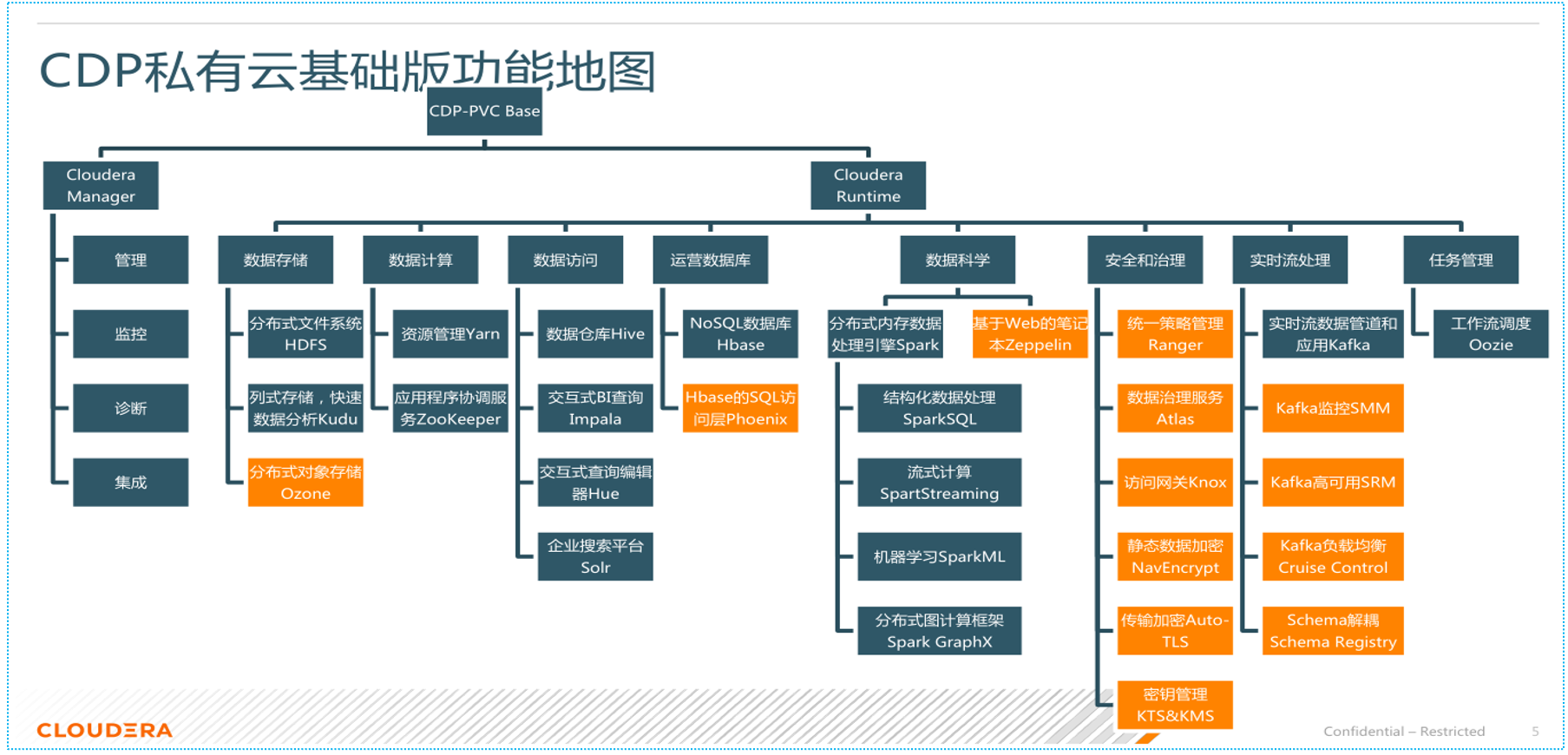
CDP组件列表
从 CDP 中删除的组件:
- Sentry:由 Ranger 替代
- Navigator:由 Altas 替代
- YARN Fair Scheduler:由 YARN Capcity Scheduler 替代
- Flume:由 Cloudera Flow Management(NiFi)替代
- Hive-on-Spark/MR:由 Hive-on-Tez 替代
- Spark 1.6:由 Spark 2.4 替代
- Navigator Optimizer:由 Workload XM 替代
- Pig:由 Hive/Spark 替代
- KeytrusteeKMS:由 RangerKMS 替代
- HSM KMS :由 Key HSM 替代
CDP基础云时间表:

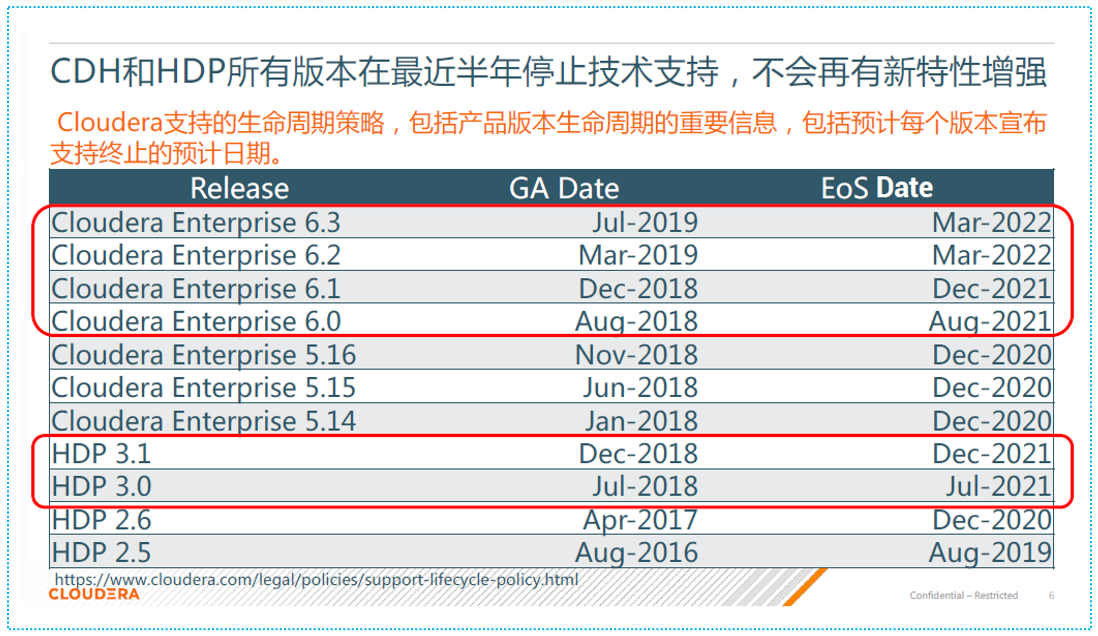
三、CDH/HDP/CDP 的产品支持策略
目前市面上主流CDH和HDP版本的关键时间点
- HDP2.x和CDH5.x对应的是hadoop2.x
- HDP3.x和CDH6.x对应的是hadoop3.x
- 目前官方已经停止了对HDP2.x和CDH5.X的技术支持
- 官方对HDP3.x和CDH6.x的技术支持也都会停止
- 具体来讲,HDP3.x的最新版HDP3.1会在2021/12月停止技术支持
- 具体来讲,CDH6.x的最新版CDH6.3会在2022/3月停止技术支持
Cloudera 的新许可证政策
Cloudera 的新许可证政策如下图所示,其关键点是:
- Cloudera 所有产品都将开源 (至少承诺的是如此,包括原来CDH中不开源的cloudera manager等也将开源),其开源模型类似 Red Hat开源模型;
- Cloudera 所有产品的二进制文件和源代码,都需要订阅,(即不再提供社区版,只提供企业版,都需要付费,不再有免费的午餐!);
- 自2019年11月以来,访问产品的二进制文件需要订阅和 paywall credentials (即没有paywall credentials 的话,将不再能从 cloudera 官网下载 parcel/rpm 包);
- 2021年1月后,扩展的Paywall将包括平台的早期版本,包括所有版本的CDH/HDP/HDF等 (即目前所有版本的CDH/HDP/HDF/CDP,从官网下载 parcel/rpm 包,都需要有 paywall credentials);

使用遗留CDH/HDP系统的小伙伴们该何去何从?
概括起来,使用遗留CDH/HDP系统的小伙伴们,有以下选择:
- 继续使用原有版本的CDH/HDP:在指定日期之后,Cloudera官方不再对原有版本的CDH/HDP提供技术支持,这仅仅意味着Cloudera官方不会再对原有版本提供新特性增强,也不再对原有版本提供BUG修复,但客户原有的大数据平台仍然是能够正常提供服务的 (这点不同于星环的TDH,TDH在许可证到期之后,整个集群中的服务就不能再重启,不能在正常提供服务了)
- 考虑市面上其他供应商的大数据平台,如星环的TDH,或基于开源apache版本自行封装。不过需要注意,星环的TDH是闭源的,其一些参数跟开源的并不兼容,有 vendor lock in的风险;
- 按照Cloudera的建议,在合适的时机,升级到 CDP平台。
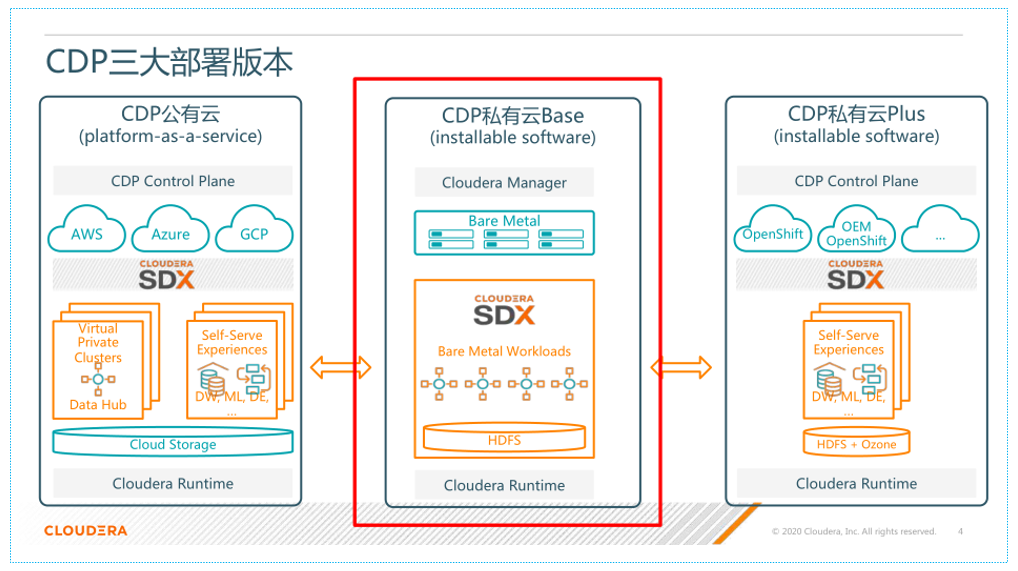
四、CDP 的不同部署形态
CDP 对应不同场景,推出了两大部署形态:
- 对应公有云场景的 CDP public cloud, 以 PaaS 形式对外提供服务,目前已经对接了三大公有云厂商 aws, gcp(google cloud platform), azure;
- 对应私有云场景和数据中心场景的 CDP private cloud, 包括 CDP private cloud base 和 CDP private cloud plus,其中前者对应的就是原来场景的 CDH 和 HDP,后者底层封装使用了 docker 和 k8s,经常被用来做计算集群;
- 以上两个版本底层对应的是同样的 cloudera runtime, 其实质就是大数据各个具体组件,如 hdfs/yarn/hive/spark 等等。
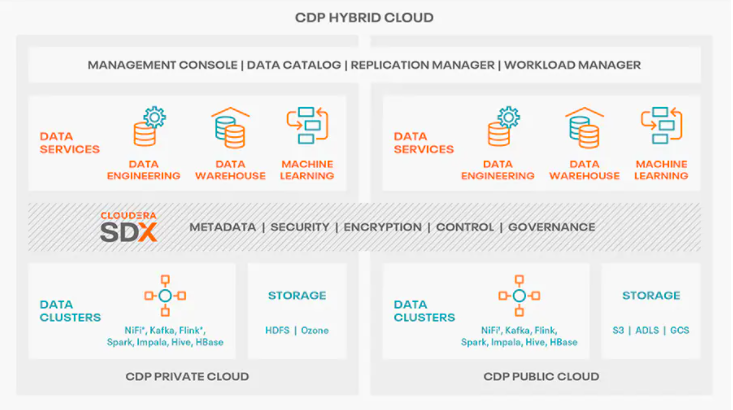
随着各行各业数字化转型的推进,当前企业的业务系统,上云是一大趋势,且上云的最终形态,是多个公有云和私有云的混合部署形态,即混合云。在次背景下,Cloudera 也整合并重磅推出了 CDP Hybrid Cloud:
CDP私有云架构图:
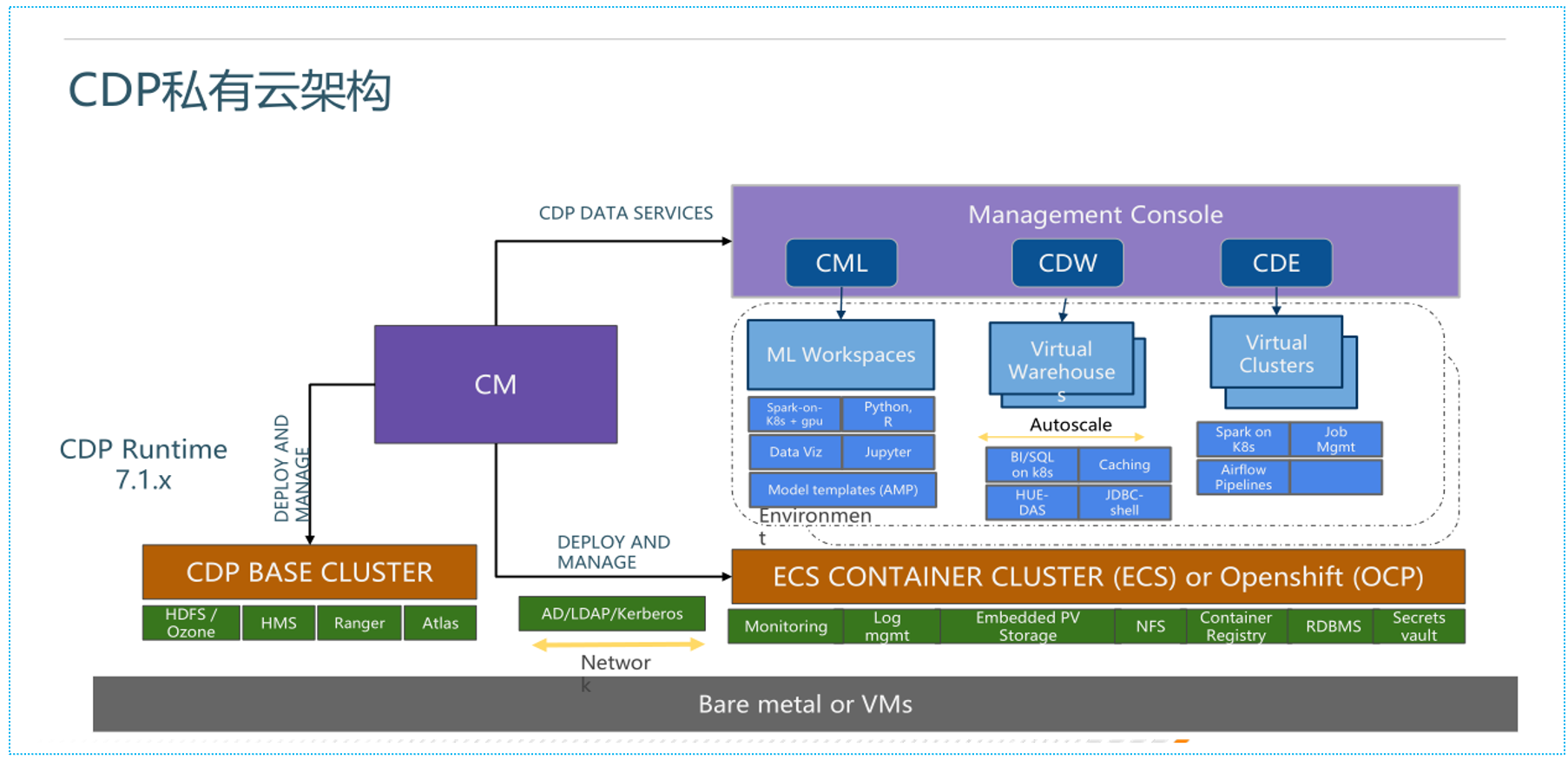
解释:
- 用户通过熟悉的CM(Cloudera Manager),使用熟悉的 parcel包,来安装和管理 CDP BASE CLUSETER, 也就是 CDP private cloud base, 就像原来安装和管理 CDH 一样;
- 用户通过熟悉的 Cloudera Manager,在需要的时候,使用 docker 镜像,在公有云上或私有云上,安装和管理一个或多个 ECS 或 OCP; ( ECS: Amazon Elastic Container Service; OCP: Red Hat OpenShift Container Platform, 两者都是基于 K8S/DOCKER的封装);
- CDP BASE CLUSETER,主要当做存储集群来使用,当不使用其计算能力时,甚至可以不安装 impala/hs2/spark等计算引擎;
- ECS 或 OCP,主要当做计算集群来使用,可以不安装也可以安装多个,当不使用其存储能力时,可以不安装 hdfs/ozone 等存储引擎;
- ECS 或 OCP,对应不同的使用场景,可以安装多个集群,比如:当然在复杂的场景下,CDP BASE CLUSETER 和 ECS/OCP,也可以是多对多的关系:
- 对应数仓场景的 CDW(cloudera datawarehouse, 其底层主要是hs2,impala,hue),
- 对应机器学习的CML (cloudera machile learning,其底层主要是 python/r/scala 的jupiter notebook),
- 对应数据工程的 CDE(cloudera data engineering,其底层主要是 spark,airflow)
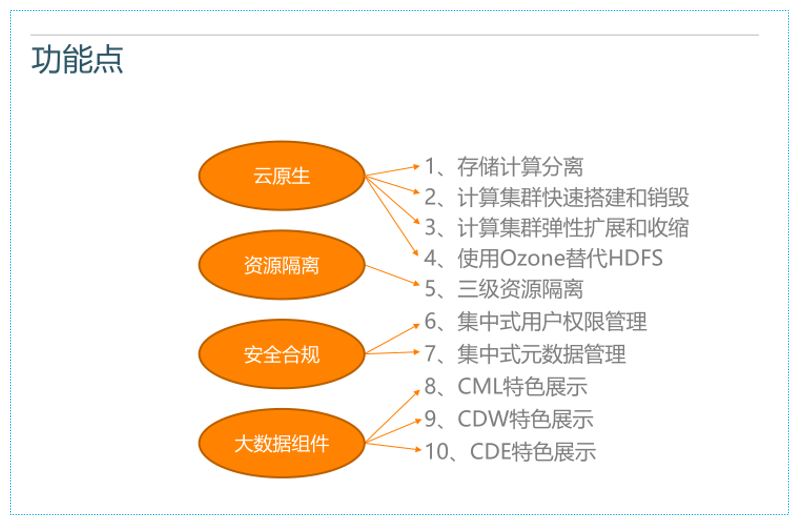
CDP Hybrid Cloud 的架构,具有以下优势和特点:
- 存储计算分离
- 计算集群快速搭建和销毁
- 计算集群弹性扩展和收缩
- 使用Ozone替代HDFS
- 集中式用户权限管理
- 集中式元数据管理
- 通过CML整合支持机器学习和人工智能
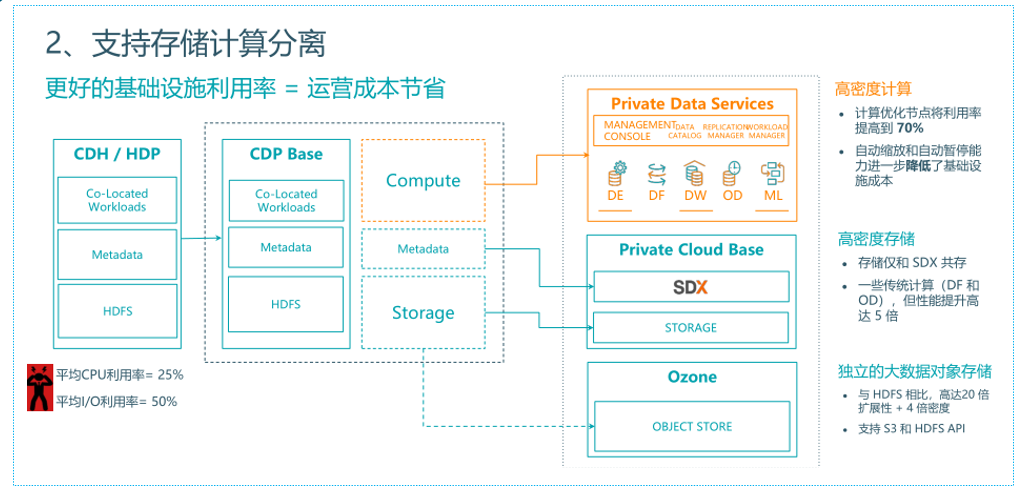
支持存储计算分离示意图:
主要场景下组件分布:

五、未来大数据架构融合的趋势
云原生、存算分离、仓湖合一、批流合一…
- 大数据和云计算进一步深度融合,大数据拥抱云计算走向云原生化
- 大数据更加青睐存储计算分离的架构
- 大数据更加青睐对象存储
- 大数据和机器学习/人工智能日益融合
- 大数据日益重视数据安全
- 大数据日益重视数据治理

Hadoop遇到的挑战
紧耦合的计算和存储架构、大规模集群的共享资源带来的最大问题是升级的复杂程度。大型的,共享式的单一集群意味着升级是一个很难点
- 物理上紧耦合的计算存储架构无法进行存储和计算模块的独立升级设计
- 通常计算框架的更新频率高于存储组件

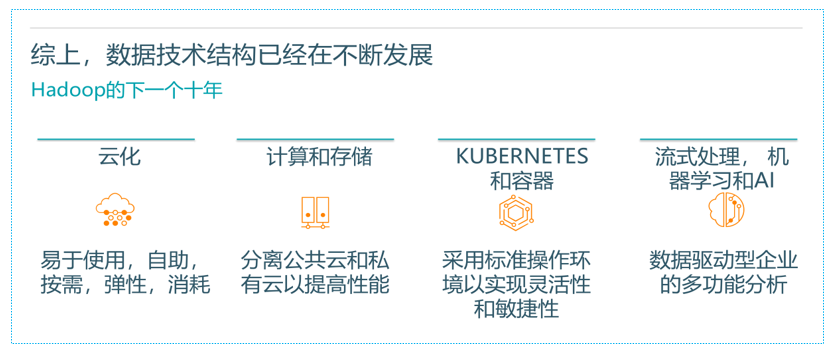
Hadoop的下一个十年
六、技术关注
1、SQL Stream Builder
- Cloudera Streaming Analytics提供SQL Stream Builder(SSB)作为服务,以使用Streaming SQL创建对数据流的连续查询。
- SSB 是用于使用SQL创建有状态流处理作业的综合界面。通过使用SQL,您可以简单、轻松地声明对数据流进行过滤、聚合、路由和变异的表达式。SSB是作业管理界面,用于在流上编写和执行Continuous SQL,以及为结果创建持久的数据API。
- SSB以交互方式运行,您可以在其中快速查看查询结果并迭代SQL语法。执行的SQL查询在Flink群集上作为作业运行,对无限的数据流进行操作,直到被取消。由于每个SQL查询都是Flink作业,因此您可以在SSB内创作,启动和监视流处理作业。
- 仅使用 SQL 实现实时数据访问的大众化;运行在Apache Flink上;解放对 Kafka 和 Flink 中数据的访问;不需要 Java 和 Scala 专家
2、Apache Ozone
- Ozone 是一个分布式键值对象存储,可提供传统 HDFS 20 倍的可扩展性
- 将存储节点配置增加 350%,将存储成本和每 TB 成本降低 50%
- Ozone 专为大数据工作负载而设计和优化,可提供现代对象存储的规模
- 对支持云原生架构的 S3 API 的原生支持。
3、Sentry VS Ranger
4、Flume VS NiFi
参考资料
- https://pan.baidu.com/s/1xiTVxtaZrBEzDGSgrmYPGQ
- https://mp.weixin.qq.com/s/0giCdtvpaxgk2OI1Fp-_tw
- https://blog.csdn.net/MichaelLi916/article/details/119922144

